


代码随想录之滑动窗口、螺旋矩阵、区间和、开发商土地;Java之数据结构、集合源码、File类和Io流以及网络编程(11.22)
代码随想录
滑动窗口
1、如果给两个字符串s和t,判断t是否为s的子串或是否s包含t的排列,用t的长度固定滑动窗口的大小,初始化将s的前t.length()个长度的字符情况存储在int数组中,int数组的大小由字符串中字符的类型决定,最大为ascii表的长度,为128。
每次循环滑动窗口向前移一位,即left++,right++,移完之后和存储t字符串情况的数组进行比较,Arrays.equal(int[] a,int[] b)。
438. 找到字符串中所有字母异位词 - 力扣(LeetCode)
2、对于找不重复的最长子串,可以用int[]数组是否大于1来判断,大于1时则right指向的字符子串中已经包含,此时先将left指向的字符移出,然后再left++(而不是直接移到right的位置×!!)。
例:3. 无重复字符的最长子串 - 力扣(LeetCode)
具体代码
public int lengthOfLongestSubstring(String s) {
int left=0;
int right=0;
int count=0;
int[] curr=new int[128];
while (right<s.length()){
if (curr[s.charAt(right)]<1){
curr[s.charAt(right)]++;
right++;
} else if (curr[s.charAt(right)]>=1) {
curr[s.charAt(left)]--;
left++;
}
count= count>right-left?count:right-left;
}
return count;
}
螺旋矩阵
当输入的矩阵并不一定行数列数相等时,要考虑到四种不同的情况,分别是:
-
- 行数为1行或者列数为1列 直接从左往右 或者从上往下遍历
- 行数(列数)为2的倍数且行数≤列数(列数≤行数) 遍历完整个循环之后 就可以结束 不需要后续操作
- 行数=列数,且为奇数时 只需要在循环结束后再遍历一下当前最中心的值
- 行数(列数)为奇数且行数<列数(列数<行数) 在循环结束之后再继续遍历(列数-行数+1)个中心列元素或者是再继续遍历(行数-列数+1)个中心行元素
螺旋矩阵代码
public List<Integer> spiralOrder(int[][] matrix) {
int row=matrix.length;//行数
int column=matrix[0].length;//列数
ArrayList<Integer> list = new ArrayList<>();
int x=0;//矩阵的行位置
int y=0;//矩阵列位置
int loop=1;//循环的次数
int offset=1;//遍历的长度 每次循环一遍右边界减一
int i=0,j=0;
//针对一行或者一列的情况
if (column==1 ){
while (x<row)
{
list.add(matrix[x++][0]);
}
}else if (row==1){
while (y<column){
list.add(matrix[0][y++]);
}
}
//循环主体
while (loop<=Math.min(row/2,column/2)){
for (j=y;j<column-offset;j++){
list.add(matrix[x][j]);
}
for (i = x;i < row-offset; i++) {
list.add(matrix[i][j]);
}
for (;j>y;j--){//注意:j是大于y而不是大于0
list.add(matrix[i][j]);
}
for (;i>x;i--){//注意:i是大于x而不是大于0
list.add(matrix[i][j]);
}
loop++;//循环次数++
x++;//行位置往里移动一位
y++;//列位置往下移动一位
offset++;//行和列中不需要遍历的个数+1
}
//如果存在列的个数是2的倍数且行数>=列数时,循环完正好结束,没有里层剩余,列和行反过来一样
if ((column%2==0 && column<row) ||(row%2==0 && column>row)){
return list;
}
//当里层有剩余时
i=x;
j=y;
if ( i<column && j<row){ //因为上面while大循环中最后x++,y++ 所以需要进行一下判断
if (row==column && row%2==1){//如果行数和列数相等且为奇数,那么只剩最中间一个没有遍历
list.add(matrix[i][j]);
} else if (row>column) {//如果行数>列数 且列数是奇数 那么中间有有一小列元素没有遍历
while (i-j <=row-column){//没有遍历的个数是行数-列数+1
list.add(matrix[i++][j]);
}
}else if (row<column){//行数列数反过来 同上
while (j-i <=column-row){
list.add(matrix[i][j++]);
}
}
}
return list;
}区间和
直接每次输入区间后,都需要遍历一次区间中的数据,因此时间消耗为0(m*n) m表示输入区间的次数,n为数组的元素个数
解决方法:使用前缀和,将前i个元素之和存储在一个数组中,每次输入区间之后,直接用末位置的和➖(初位置-1)的和,当初位置为0时区间和就为末位置之和。
区间和代码
import java.util.*;
public class Main{
public static void main (String[] args) {
Scanner scan= new Scanner(System.in);
int arrLength=scan.nextInt();
int[] Array=new int[arrLength];
int[] p=new int[arrLength];
int i=0;
Array[i]=scan.nextInt();
p[i]=Array[0];
for(i=1;i<arrLength;i++){
Array[i]=scan.nextInt();
p[i]=p[i-1]+Array[i];
}
while(scan.hasNextInt()){
int a=scan.nextInt();
int b=scan.nextInt();
if (a==0){
System.out.println(p[b]);
}else{
System.out.println(p[b]-p[a-1]);
}
}
scan.close();
}
}开发商购买土地
其核心在于,划分要么横着一刀,要么竖着一刀,且只能是一刀。
思路:先验证横着一刀得到两个区域差的最小值:遍历每一行,在每行最后一个位置加入后计算区域差,sum-count-count,其中(sum-count)表示此一刀下面的区域,count表示一刀上面的区域,用abs(下面的区域和➖上面区域和)则表示区域差;同理再试竖着的一刀。
前缀和和优化暴力求解都是o(m*n)
暴力求解代码
public class Main{
public static void main (String[] args) {
Scanner scanner=new Scanner(System.in);
int n=scanner.nextInt();
int m=scanner.nextInt();
int[][] vec=new int[n][m];
int sum=0;
int result=Integer.MAX_VALUE;
for (int i=0;i<n ;i++ ){
for (int j=0;j<m ;j++ ){
vec[i][j]=scanner.nextInt();
sum+=vec[i][j];
}
}
int count=0;
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
count+=vec[i][j];
if (j==m-1){
result=Math.min(result,Math.abs(sum-count-count));
}
}
}
count=0;
for(int j=0;j<m;j++){
for(int i=0;i<n;i++){
count+=vec[i][j];
if(i==n-1){
result=Math.min(result,Math.abs(sum-count-count));
}
}
}
System.out.println(result);
scanner.close();
}
}数组基础总结
数组的元素是不能删除的,只能覆盖!!
二维数组在内存中并不是连续的,其实质是一维数组的一维数组,即对象中存储着一个一维数组的地址,这个一维数组中存储着每行数组的起始地址。
Java基础学习
数据结构
1、在底层真实存在的数据结构:数组、链表
抽象数据类型:树、栈、队列(使用数组或者是链表来构建)
集合源码
ArrayList
1、ArrayList的特点
- 实现了List接口,存储有序的,可重复的一个一个的数据
- 底层使用object[]数组存储
- 线程不安全
2、ArrayList源码解析
jdk7版本:
//底层会初始化数组,数组的长度为10,object[] elementDate=new object[10];
ArrayList arr=new ArrayList<>();
arr.add("AA");//elementDate[0]="AA";
arr.add("BB");//elementDate[1]="BB";
//一旦size>length,length变为原来的1.5倍,并将原ArrayList复制到扩容的ArrayListjdk8版本:
//底层不会初始化数组,数组的长度为0,object[] elementDate=new Object[]{};
ArrayList arr=new ArrayList<>();
arr.add("AA");//首次添加元素时,会初始化数组elementData=new Object[10];elementData[0]="AA";
arr.add("BB");//elementDate[1]="BB";
//一旦size>length,length变为原来的1.5倍,并将原ArrayList复制到扩容的ArrayList
3、在选择ArrayList时,有两种初始化方法: new ArrayList();//底层创建长度为10的数组
new ArrayList(int capacity); //底层创建指定capacity长度的数组
Vector
1、Vector的特点
- 实现了List接口,存储有序的,可重复的数据
- 底层使用Object[]数组存储
- 线程安全
2、Vector源码解析
Vector v=new Vector();//底层初始化数组,长度为10 Object[] elementData=new Object[10]
v.add("AA");//elementData[0]="AA";
v.add("BB");//elementData[1]="BB";
//当添加第11个元素时,需要扩容,默认扩容为原来的2倍
LinkedList
1、LinkedList的特点
- 实现了List接口,存储有序的,可重复的数据
- 底层使用双向链表存储
- 线程不安全
2、LinkedList源码解析
LinkedList<String> list=new LinkedList<>();//因为底层不是数组结构,不需要初始化分配数组空间
list.add("AA");//将AA封装到一个Node对象1中,list对象的属性first、last都指向此Node对象1
list.add("BB");//将BB封装到一个Node对象2中,与对象1构成一个双向链表,此时last指向Node2对象
//由于LinkedList使用的是双向链表,不考虑扩容的问题private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
HashMap⭐
1、HashMap特点
- 实现Map接口,存储一对一对的数据,可以添加null的key值和value值
- 底层使用数组+单向链表+红黑树(jdk8版本之后),jdk7版本没有使用红黑树
- 线程不安全,效率高的
2、HashMap源码解析
- JDK7
//创建对象的过程中,底层初始化数组Entry[] table=new Entry[16]
HashMap<String,Integer> map=new HashMap<>();
map.put("AA",78);//将AA和78封装到一个Entry对象中,考虑将此对象添加到table数组中
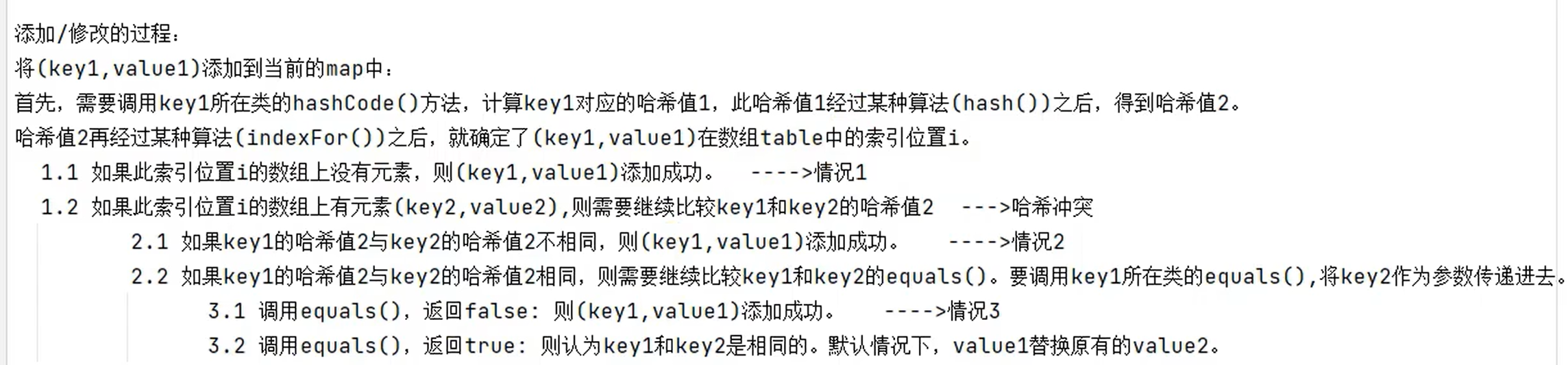
情况1:将(key1,value1)存放到数组的索引i的位置
情况2,情况3:使用单向链表的头插法,将(key1,value1)放在数组中,并指向(key2,value2)
满足下列条件,会考虑扩容,一般扩容为table.legth的2倍
(size>=threshold) && (null !=table[i]) threshold=数组的长度*加载因子(默认为0.75),
加载因子过大,增加元素的数目较大时才会扩容,节省扩容所需的时间,但后期查找和删除比较麻烦
加载因子过小,没添加几个元素就开始扩容,浪费空间
HashMap有无参构造器,也有有参构造器,其中无参构造器默认capacity为16,LOAD_FACTOR为0.75,也可以直接调用有参构造器,手动输入上面两个参数的值,其中就算手动输入的capacity不是2的倍数,经过构造器之后,也会构建大小为2的倍数的capacity
HashMap允许添加key为null的值,将此(key,value)存放到table索引0的位置,如果索引为0的位置已经有元素了且遍历该位置的链表不为null,则将null用头插法放入HashMap数组中,若索引为0的key也为null或链表中有key为null,则将新的value赋给旧的value值
详细可看:JDK7中HashMap的源码 视频171集33:49
- JDK8(以jdk1.8.0_271为例)
① 在jdk8中,当我们创建了HashMap实例以后,底层并没有初始化table数组。当首次添加(key,value)时,进行判断,如果发现table尚未初始化,则对数组进行初始化。
② 在jdk8中,HashMap底层定义了Node内部类,替换jdk7中的Entry内部类。意味着,我们创建的数组是Node[]
③ 在jdk8中,如果当前的(key,value)经过一系列判断之后,可以添加到当前的数组角标i中。如果此时角标i位置上有元素。在jdk7中是将新的(key,value)指向已有的旧的元素(头插法),而在jdk8中是旧的元素指向新的 (key,value)元素(尾插法)。 "七上八下"
④ jdk7:数组+单向链表 ;jk8:数组+单向链表 + 红黑树
3、单链表和红黑树转换时机
- 使用单向链表变为红黑树:如果数组索引i位置上的元素的个数达到8,并且数组的长度达到64时,我们就将此索引i位置上的多个元素改为使用红黑树的结构进行存储。(为什么修改呢?因为红黑树进行put()/get()/remove()操作的时间复杂度为O(logn),比单向链表的时间复杂度O(n)的好,性能更高。)
- 使用红黑树变为单向链表:当使用红黑树的索引i位置上的元素的个数低于6的时候,就会将红黑树结构退化为单向链表。
属性/字段:
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认的初始容量 16
static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量 1 << 30
static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认加载因子
static final int TREEIFY_THRESHOLD = 8; //默认树化阈值8,当链表的长度达到这个值后,要考虑树化
static final int UNTREEIFY_THRESHOLD = 6;//默认反树化阈值6,当树中结点的个数达到此阈值后,要考虑变为链表
//当单个的链表的结点个数达到8,并且table的长度达到64,才会树化。
//当单个的链表的结点个数达到8,但是table的长度未达到64,会先扩容(比JDK7多的一种扩容情况)
static final int MIN_TREEIFY_CAPACITY = 64; //最小树化容量64
transient Node<K,V>[] table; //数组
transient int size; //记录有效映射关系的对数,也是Entry对象的个数
int threshold; //阈值,当size达到阈值时,考虑扩容
final float loadFactor; //加载因子,影响扩容的频率
LinkedHashMap
1、LinkedHashMap与HashMap的关系
LinkedHashMap是HashMap的子类
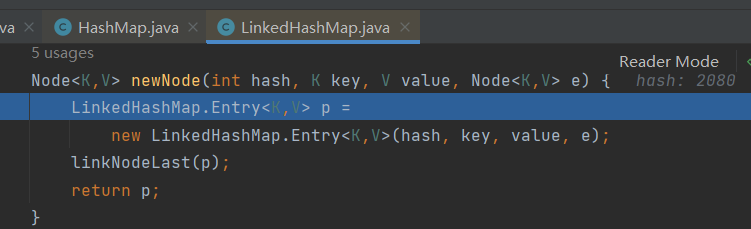
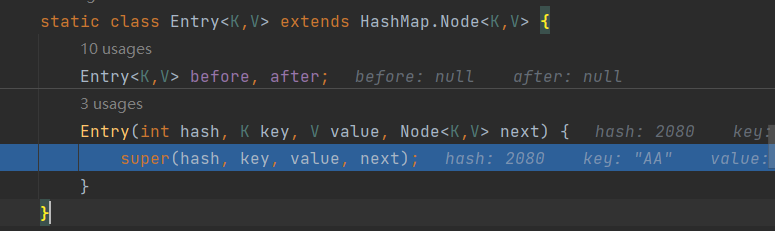
LinkedHashMap在HashMap数组+单向链表+红黑树的基础上,又增加了一对双向链表(Entry类继承了HashMap的Node,并添加before和after作为双向指针),记录添加的(key,value)先后顺序
2、LinkedHashMap的put()方法使用了HashMap的put方法,但重写了put方法中的NewNode()方法;
HashSet和LinkedHashSet
HashSet和LinkedHashSet的底层分别是HashMap和LinkedHashMap,添加元素相当于添加key,其中key都指向同一个value,为new Object()
当对HashSet中已经存在的元素进行修改,并使用remove()方法对最新数据进行移除时,并不会删除掉该元素,因为hash值发生改变,现set中存储的却是原hash值。
添加时,不论是新的元素还是旧元素都可以添加成功。
面试⭐:
1、ArrayList相当于对数组的常见操作的封装,对外暴露增删改查插的操作方法
2、HashMap初始值为16(查看源码),临界值是12(threshold ,使用数组的长度*加载因子)
3、HashMap为什么是2的次方?看底层代码,方便计算在数组中存放角标的位置,需要和数组的length-1进行与运算,length必须为2的n次方
4、HashMap计算索引值,在1.7使用Indexfor()方法,在1.8中进行&运算
5、哈希冲突:
 解决方法:头插法、尾插法、红黑树、比较equals
解决方法:头插法、尾插法、红黑树、比较equals
6、HashMap退化是因为红黑树占用空间大,TreeNode要占据两倍的普通Node的空间
7、hashCode()与equals()生成算法、方法怎么重写?进行equals()判断使用的属性,通常也都会参与到hashCode()的计算中
IDEA自动生成hashCode()自动使用相关算法
File类和IO流
1、流的基础操作
输入流 输出流
字节流: InputStream OutputStream
字符流: Reader Writer
2、字符和字节的关系 字符流和字节流是两个单位
一个char是两个byte 一个byte占8bit=>一个字符占两个字节 一个字节8比特(二进制数)
3、new FileReader(char cbuffer);该方法会返回每次读到的字符个数 且读到的字符会存在cbuffer中,循环输出时,必须要小于返回的字符个数len,因为后面循环读到的字符会覆盖前面循环读到的字符,一但后续长度不够上一轮结果有部分会保存下来。
4、try-catch执行完后还会继续往下执行,使用finally是避免catch抛出异常,后面的语句没有执行。
当try中由语句抛出异常,该语句后面的部分将不会继续执行。
节点流(FileReader FileWriter FileInputStream FileOutputStream)
1、读写字符流数据都有一定的步骤,且关闭数据流必须要放在try-catch-finally的finally中,确保即使执行过程中出错,也会关闭数据流,而当数据输入输出数据流为空时,则不需要进行关闭。
一定要关闭流资源,为了避免内存泄漏(数据已经使用完,但gc并不会回收)
public void test4(){
//1.创建File类的对象
File srcFile=new File("hello.txt");
File destFile=new File("hello_copy.txt");
//2.创建输入输出流
FileReader fr = null;
FileWriter fw= null;
try {
fr = new FileReader(srcFile);
fw = new FileWriter(destFile);
//3.数据的读入和写出的过程
char[] cbuffer=new char[5];
int len;
while ((len=fr.read(cbuffer))!=-1){
fw.write(cbuffer,0,len);
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
//4.关闭流资源
try {
if (fw!=null)
fw.close();
} catch (IOException e) {
e.printStackTrace();
}
try {
if (fr!=null)
fr.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
2、除了文本文件以外,其它类型的文件使用字节流,和字符流的基础操作一样,除了方法里面的参数变成byte类型,如:read(byte[] buffer)和write(byte[] buffer,0,len)
3、IDEA中默认UTF-8存储,汉字默认为3个字节,其它为1个字节,当使用字节流读取复制到另一个文件时,复制成功,而如果是读出来是到控制台,如果正好中间断开中文,则会报乱码。
4、对于字符流,只能用来处理文本文件,不能用来处理非文本文件。
对于字节流,通常是用来处理非文本文件,但是如果涉及到文本文件的复制可以使用字节流
文本文件:.txt .java .c .py等各种编程语言文件
非文本文件:.doc等支持图片的
处理流
缓冲流
1、使用缓冲流 BufferInputStream BufferOutPutStream 提高文件读写的效率 默认缓冲区大小8*1024 即8kb
缓冲流的操作是先统一写到内存缓冲区里,在关闭资源时再统一写入到文件,以此提高效率,所以文件的最后如果没有关闭,则会缺失数据,此时可以用.flush()方法做到每用缓冲流写一次都会刷新数据
节点流不关闭也不会缺失数据,因为每调用一次wirite()方法都写入到文件.
转换流
1、字节流-》字符流 解码 InputStreamReader 字符流-》字节流 编码 OutputStreamWrite
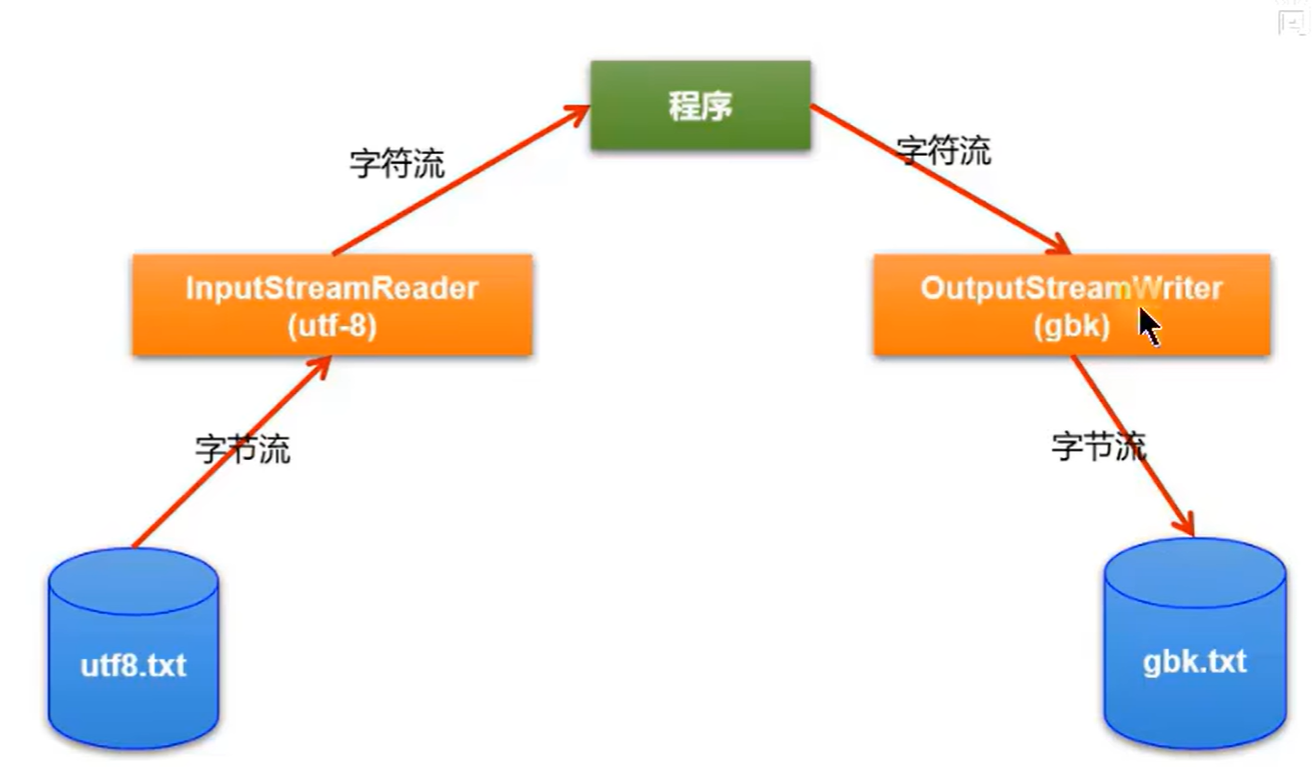
2、解码时使用的字符集必须与当初编码使用的字符集兼容;如果文件编码使用的GBK,解码是UTF-8,但文件中只有abc等英文字符,此情况不会出现乱码,因为GBK和UTF-都向下兼容了ASCII。ASCII包括英文字母,数字和一些符号总共是128个,占7位,用一个字节表示
FileInputStream fis=new FileInputStream(file1);
FileOutputStream fos=new FileOutputStream(file2);
//对应的解码,必须与原字符集相同
InputStreamReader isr=new InputStreamReader(fis,"gbk");
OutputStreamWriter osw=new OutputStreamWriter(fos,"utf8");
byte[] buffer=new byte[5];
int len;
while ((len=bis.read(buffer))!=-1){
bos.write(buffer,0,len);
}
3、在存储的文件中的字符

数据流和对象流
1、对象的序列化机制

序列化过程:写出到磁盘或通过网络传输出去的过程,使用ObjectOutputStream流实现。
反序列化过程:将文件中的数据或网络传输过来的数据还原为内存中的Java对象,使用ObjectInputStream流实现。
2、流程
- 创建File对象
- File对象作为参数,创建节点流
- 节点流对象作为参数,创建对象流,调用对象流的readObject()和writeObject()方法完成对对象流的输入和输出
- 关闭最外层对象流
//数据流写到磁盘
@Test
public void test1() throws IOException {
File file=new File("object.dat");
ObjectOutputStream oos=new ObjectOutputStream(new FileOutputStream(file));
Person p=new Person("enheng",12);
oos.writeObject(p);
oos.flush();
oos.close();
}
//从磁盘写到内存
@Test
public void test2() throws IOException, ClassNotFoundException {
File file=new File("object.dat");
ObjectInputStream ois=new ObjectInputStream(new FileInputStream(file));
Person p=(Person) ois.readObject();
System.out.println(p);
ois.close();
}
3、自定义类要实现序列化机制,要满足
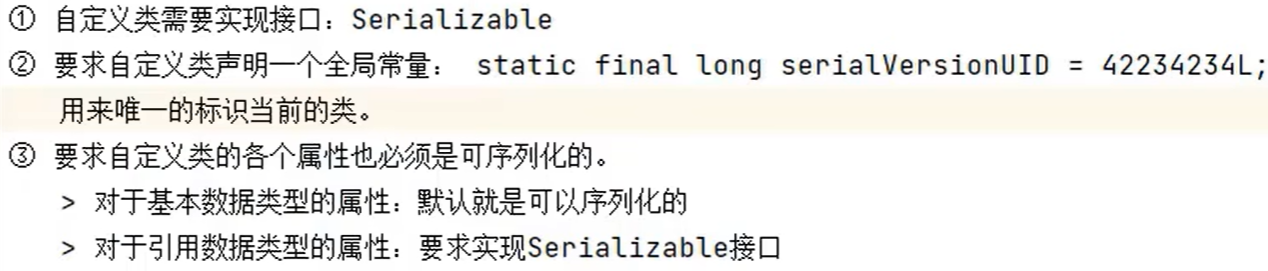
类中的属性如果声明为transient或static,则不会保存在磁盘文件上,输出结果为默认值null或0
进程与进程之间通信,客户端与客户端之间进行通信,都需要对象是可序列化的。
网络编程
InetAddress

InetAddress类没有明显的构造函数,上面两个方法为工厂方法,即一个类中的静态方法返回该类的一个实例。
InetAddress inet1= InetAddress.getByName("192.168.23.21");
System.out.println(inet1);
InetAddress inet2=InetAddress.getByName("www.atguigu.com");
System.out.println(inet2);
TCP和UDP
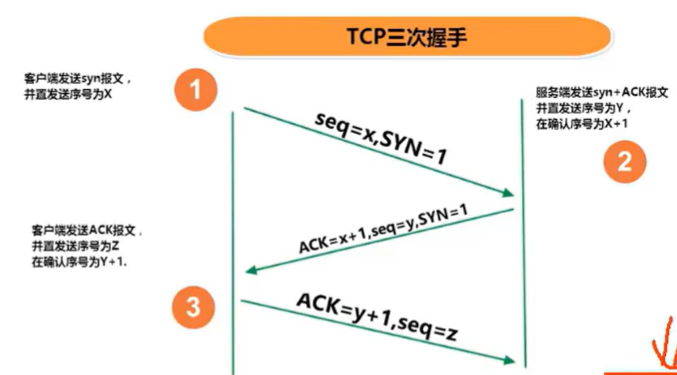
1、TCP的三次握手
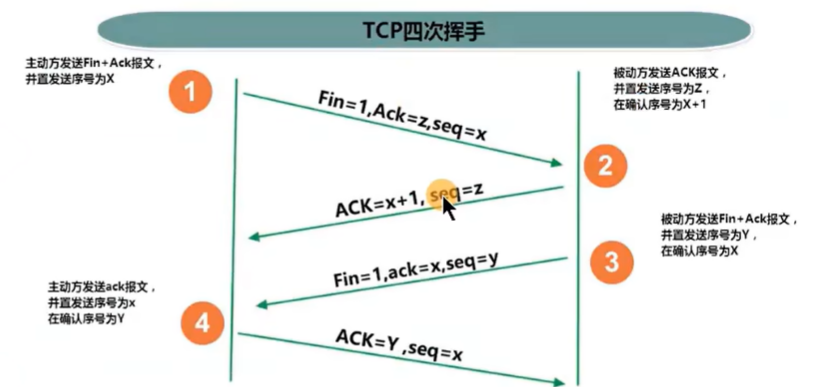
2、四次挥手
3、Socket是Ip地址+端口号
文件通过TCP从客户端传到服务器
package com.atguigu02.tcpudp;
import org.junit.Test;
import java.io.*;
import java.net.InetAddress;
import java.net.ServerSocket;
import java.net.Socket;
/**
* className:TCPTEst
* Description:
*
* @Author 董雅洁
* @Create 2024/11/22 15:07
* @Version 1.0
*/
public class TCPTest {
@Test
//客户端 发送文件给服务器端
public void client() throws IOException {
Socket socket = null;
FileInputStream fis= null;//从磁盘读到内存 用InputStram
OutputStream os = null;
try {
//1.创建Socket
InetAddress inetAddress = InetAddress.getByName("127.0.0.1");
int port=9090;
socket = new Socket(inetAddress, port);
//2.创建File实例、FileInputStream的实例
File file=new File("1.png");
fis = new FileInputStream(file);
//3.通过Socket,获取输出流
os = socket.getOutputStream();
//4.读写数据
byte[] buffer=new byte[1024];
int len;
while ((len=fis.read(buffer))!=-1){
os.write(buffer,0,len);
}
System.out.println("数据发送完毕");
} catch (IOException e) {
e.printStackTrace();
} finally {
if (os!=null){
os.close();
}
if (fis!=null){
fis.close();
}
if (socket!=null){
socket.close();
}
}
}
//服务器端 接受客户端发来的文件
@Test
public void server() throws IOException {
//1.创建ServerSocket
int port=9090;
ServerSocket serverSocket = new ServerSocket(port);
//2.调用accept() 接收客户端的Socket
Socket socket = serverSocket.accept();
System.out.println("服务器已开启");
//3.通过Socket获取一个输入流
InputStream is = socket.getInputStream();
//4.创建File类的实例 FileOutputStream的实例
File file=new File("1_copy.png");
FileOutputStream fos=new FileOutputStream(file);
byte[] buffer=new byte[1024];//当内容为中文时,使用一般方式可能会乱码
//ByteArrayOutputStream bos=new ByteArrayOutputStream();
int len;
while ((len=is.read(buffer))!=-1){
fos.write(buffer,0,len);
}
fos.close();
is.close();
socket.close();
serverSocket.close();
}
}
