比特币源码分析--深入理解区块链16.Base58编码和解码
Base58是比特币中使用的一种独特编码方式,它主要用于比特币的钱包地址,在前面文章已经介绍过如何通过椭圆曲线方程算法,通过私钥来生成相应的公钥,钱包地址就是通过公钥计算得来,在后面的章节中将详细介绍如何通过公钥生成钱包地址。由于钱包地址在编码时使用了Base58编码方式,因此本章主要介绍Base58编码和解码的算法。
在比特币的区块浏览器中,我们常常可以看到类似下面这样的地址:
bc1qnsnqdhr2de0lq7fsca79uq5me38a7arwv5t9u2
my5fH6MBbGqSwmPWvphm94QTTHdSpCBte1
上面就是比特币中钱包地址的样式,它们是采用Base58编码后的字符串。Base58顾名思义最多只有58个字符。如我们常用的字符0~9,A~Z, a~z共10+26+26=62个。由于数字0和大写字母O,大写字母I和小写字母l相似,容易引起混淆,所以Base58字符内容其实就是在62个字符中排除了这4个字符后剩下的。它按下面的顺序排列,序号从0~57:
"123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz"
Base58编码符号表
Base58字符串按照顺序放在一个表格里如下所示:
|
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
编码 |
字符 |
|||
|
0 |
1 |
16 |
H |
32 |
Z |
48 |
q |
|||
|
1 |
2 |
17 |
J |
33 |
a |
49 |
r |
|||
|
2 |
3 |
18 |
K |
34 |
b |
50 |
s |
|||
|
3 |
4 |
19 |
L |
35 |
c |
51 |
t |
|||
|
4 |
5 |
20 |
M |
36 |
d |
52 |
u |
|||
|
5 |
6 |
21 |
N |
37 |
e |
53 |
v |
|||
|
6 |
7 |
22 |
P |
38 |
f |
54 |
w |
|||
|
7 |
8 |
23 |
Q |
39 |
g |
55 |
x |
|||
|
8 |
9 |
24 |
R |
40 |
h |
56 |
y |
|||
|
9 |
A |
25 |
S |
41 |
i |
57 |
z |
|||
|
10 |
B |
26 |
T |
42 |
j |
|||||
|
11 |
C |
27 |
U |
43 |
k |
|||||
|
12 |
D |
28 |
V |
44 |
m |
|||||
|
13 |
E |
29 |
W |
45 |
n |
|||||
|
14 |
F |
30 |
X |
46 |
o |
|||||
|
15 |
G |
31 |
Y |
47 |
p |
编码从0~57共58个编码。因此要将数据进行Base58编码,首先应该计算数据的编码,然后根据编码查找对应的字符,最后得出的字符串就是Base58编码的结果。
编码从0~57共58个编码。因此要将数据进行Base58编码,首先应该计算数据的编码,然后根据编码查找对应的字符,最后得出的字符串就是Base58编码的结果。
设计Base58主要的目的
- 避免混淆。
- 在某些字体下,数字0和字母大写O,以及字母大写I和字母小写l会非常相似。
- 不使用"+"和"/"的原因是非字母或数字的字符串作为账号较难被接受。
- 没有标点符号,通常不会被从中间分行。
- 大部分的软件支持双击选择整个字符串。
避免混淆,易于阅读和方便计算机使用是其设计的主要目的。因此在需要使用字符串标记身份或唯一识别码的应用场合,使用base58不失为一个好的选择。
Base58编码算法
计算机中所有数据均可以使用字节(byte)来表示,一个字节长度为8个二进制位,因此计算机中最基本的字节码最多个,编码从0~255,常用的ASCII表就列出了编码对应的字符。因此一个ASCII字节可用8位二制来表示可写成:
,而Base58最多可用
位表示,因此经过Base58编码后的长度是原始数据长度的
倍。
Base58编码的基本思想将常用的字节码(256进制)转换成Base58,相当于将256进制转换成58进制。但不能直接将256进制转换为58进制,中间必须通过10进制中转,相当于
256进制转10进制,10进制转58进制。
它们的转换算法同样可以按照二进制到10进制转换思想来进行。
我们先重温一下十进制与二进制的转换
二进制转换为十进制:
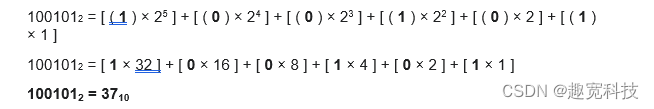
依照该规则,将256进制转换为10进制,是以256作为底数进行的。
十进制转换为二进制:
整数部分,把十进制转成二进制一直分解至商数为0。读余数从下读到上,即是二进制位的整数部分数字。
将59.25(10) 转成二进制:
整数部分:
59 ÷ 2 = 29 ... 1
29 ÷ 2 = 14 ... 1
14 ÷ 2 = 7 ... 0
7 ÷ 2 = 3 ... 1
3 ÷ 2 = 1 ... 1
1 ÷ 2 = 0 ... 1
小数部分,则用其乘2,取其整数部分的结果,再用计算后的小数部分依此重复计算,算到小数部分全为0为止,之后读所有计算后整数部分的数字,从上读到下。
小数部分:
0.25 × 2 = 0.5
0.50 × 2 = 1.0
所以:
而十进制转换为58进制,被除数就是58。
base58的编码过程是:
- 将要转换的数据转换为字节数组
- 计算前置字节码是0的个数,因为0没必要参与转换,其结果是0。
- 将256进制转换为10进制
- 将10进制转换为58进制。
- 得到一个58进制的数组,将第二步0的个数添加到该数组末尾。n个0就添加n个0到数组末尾。
- 反转整个数组。
- 查表,将base58编码转换成字符。
这里的第3步如果转换的字节数组很长,那么以256为底数的指数将会非常庞大,需要使用大数,但实际上可以优化算法,没必要一次性将整个原始数组全部转换为10进制后才转换为58进制,可采取逐个转换为58机制的策略来进行,这样可以避免使用大整数,从而提高运算效率。
我们将“Abc”转换为base58为例说明运算过程:
|
字符 |
ASCII码 |
||
|
A |
65 |
|
4259840 |
|
b |
98 |
|
25088 |
|
c |
99 |
|
99 |
|
4285027 |
|
计算 |
商 |
余数 |
|
|
73879 |
45 |
|
|
1273 |
45 |
|
|
21 |
55 |
|
|
0 |
21 |
所以最后结果是21, 55, 45, 45,查表得base58编码:Nxnn
Bitcoin中算法是这样的:
std::string EncodeBase58(Span<const unsigned char> input)
{// Skip & count leading zeroes.int zeroes = 0;int length = 0;while (input.size() > 0 && input[0] == 0) {input = input.subspan(1);zeroes++;}// Allocate enough space in big-endian base58 representation.int size = input.size() * 138 / 100 + 1; // log(256) / log(58), rounded up.std::vector<unsigned char> b58(size);// Process the bytes.while (input.size() > 0) {int carry = input[0];int i = 0;// Apply "b58 = b58 * 256 + ch".for (std::vector<unsigned char>::reverse_iterator it = b58.rbegin(); (carry != 0 || i < length) && (it != b58.rend()); it++, i++) {carry += 256 * (*it);*it = carry % 58;carry /= 58;}assert(carry == 0);length = i;input = input.subspan(1);}// Skip leading zeroes in base58 result.std::vector<unsigned char>::iterator it = b58.begin() + (size - length);while (it != b58.end() && *it == 0)it++;// Translate the result into a string.std::string str;str.reserve(zeroes + (b58.end() - it));str.assign(zeroes, '1');while (it != b58.end())str += pszBase58[*(it++)];return str;
}
在上面得代码中,我们可以看到给base58容器分配的大小是138/100+1,这个数字也是base58编码后是原的大小的1.37倍左右。另外在转换为10进制的过程中,并没有一次性计算所有的字节的和,而是采取边计算10进制,边计算58进制的过程。
Base58解码算法
Base58解码是编码的逆运算过程:
- 首先获得base58字符对应的编码
- 通过编码计算其10进制
- 将10进制转换为256进制。
在根据base58字符串获得其编码的过程中,如果使用查表遍历算法话,时间复杂度最高是,可以不通过查表来完成:建立一个大小是256数组,里面对应的是base58字符串的编码,数组序号就是字符的ASCII编码,比如z的ASCII码是112,那么数组序号112的内容就是z的base编码57。这样可以每个base58字符运算一次就能找到其编码。
继续上面的例子,将“Nxnn”解码,过程是:
|
字符 |
Base58 |
||
|
N |
21 |
|
4097352 |
|
x |
55 |
|
185020 |
|
n |
45 |
|
2610 |
|
n |
45 |
|
45 |
|
4285027 |
|
计算 |
商 |
余数 |
|
|
16738 |
99 |
|
|
65 |
98 |
|
|
0 |
65 |
其256进制的结果是65, 98, 99, 查ASCII表得:Abc。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号