


一个简单的基于内容的推荐算法
最近闲下来又开始继续折腾推荐系统了,声明一下,本文只是介绍一下最基础的基于内容的推荐系统(Content-based recommender system)的工作原理,其实基于内容的推荐系统也分三六九等Orz,这里只是简单的较少一下最原始的、最基本的工作流程。
基于内容的推荐算法思路很简单,它的原理大概分为3步:
1、为每个物品(Item)构建一个物品的属性资料(Item Profile)
2、为每个用户(User)构建一个用户的喜好资料(User Profile)
3、计算用户喜好资料与物品属性资料的相似度,相似度高意味着用户可能喜欢这个物品,相似度低往往意味着用户不喜欢这个物品。
选择一个想要推荐的用户“U”,针对用户U遍历一遍物品集合,计算出每个物品与用户U的相似度,选出相似度最高的k个物品,将他们推荐给用户U——大功告成!
下面将详细介绍一下Item Profiles和User Profiles。
1、Item Profiles
说到基于内容的推荐系统,就不得不提到“Item Profiles”,它是整个系统中最关键的内容之一,这里的“Item”是指被推荐的物品,而“Item Profiles”是指被推荐物品的详细属性。
什么是“Item”?:举例来讲对,于一个电影推荐系统来讲,它的目标就是向用户推荐他们可能喜欢的电影,这其中:电影就相当于“Item”;
什么是“Item Profiles”?演员名单、导演名单、影片类型、时长、上映日期、票房等等,这些电影的属性就是所谓“Item Profiles”了。
2、Representing Item Profiles
还是拿电影推荐系统来举例吧,为了简单起见,我们假设“Item Profiles”中只包含演员名单。这样一来,《黑客帝国》的Item Profiles就可以这样表示了:{基努·里维斯、劳伦斯·菲什伯恩、凯莉·安·摩丝、雨果·维}(为了方便,我们假设《黑客帝国》中只有这4位演员)。然而这种自然描述的Item Profiles不能直接用在代码里啊,我们需要的是干货!所以还要把自然描述的Item Profiles映射成程序能够读懂的数据结构,所以需要进行一个映射——将自然语言描述的Item Profiles转换成0,1矩阵,方法是这样的:
2.1、首先构造一个1xn维的矩阵,n表示全球主要的影星数量。初始化这个1xn维的矩阵,将所有元素设置为0,这样我们就会得到一个类似这样子的行向量:[0,0,0,0,0,0,............................,0] ,其中一共有n个0。
2.2、做一个假设:我们假设这个行向量的第0个元素代表成龙、第1个元素代表基努·里维斯、第2个元素代表劳伦斯·菲什伯恩、第3个元素代表汤姆克鲁斯、第4、5个元素分别代表凯莉·安·摩丝和雨果·维、剩下的代表谁无所谓了,由他去吧!
2.3、将自然语言描述的Item Profiles映射到这个1xn维的矩阵中,映射的方法很直观,如果影片M中有演员A1,A2和A3,那么M的行向量中,A1、A2、A3对应的元素分别置为1,表示影片M中出现的演员有A1、A2、A3。
举例来讲,按照第2步中的假设的话,那么影片《黑客帝国》的0,1矩阵就是[0,1,1,0,1,1,0,0,0,0,0,0...............,0]。不难看出,由于矩阵的第0个元素代表成龙,而成龙并不是《黑客帝国》中的演员,所以矩阵中第0个元素是0,表示成龙不是《黑客帝国》中的演员;同样的,由于矩阵的第1个元素代表基努·里维斯,而基努·里维斯是《黑客帝国》中的演员,所以矩阵中第1个元素是1,表示基努·里维斯是《黑客帝国》中的演员。同理,矩阵中第2,4,5个元素是1,分别表示劳伦斯·菲什伯恩、凯莉·安·摩丝、雨果·维是《黑客帝国》中的演员。剩下的元素就都是0了。
3、User Profiles
到目前为止,我们已经为Item进行建模了,模型就是“Item Profiles”,也就是那个1xn维的0,1矩阵。但是这还不够,我们还需要为用户进行建模,所谓的对用户建模,就是构造“User Profiles”,而这个“User Profiles”就相当于用户的偏好。在电影推荐系统这个例子中,用户U的偏好可以表示为对各个演员的喜好程度,举例来讲:
假设我们有一个评分矩阵,其中包含2个用户和3个电影:
| 用户\电影 | 《尖峰时刻》 | 《红番区》 | 《黑客帝国》 |
| Alice | 4 | 5 | 3 |
| Bob | 1 | 4 |
矩阵的含义是:
用户Alice对《尖峰时刻》 《红番区》 《黑客帝国》的评分分别为4、5、3分(满分5分)
用户Bob对 《尖峰时刻》 《红番区》 《黑客帝国》的评分分别为1、1、4分(满分5分,空白的表格表示Bob尚未对该电影打分)
经过分析,可以发现Alice相对来讲更喜欢《尖峰时刻》和《红番区》,而成龙是这两部电影的共同点,由此我们很自然的猜想到:Alice可能喜欢成龙的电影!利用这一个消息,就可以开始为Alice构建她的“User Profiles”了,方法如下:
3.1、算出Alice所有打分的平均分,在这个例子中Alice的平均分Avg =(4+5+3)/2 = 4
3.2、利用公式: 算出Alice对成龙的喜好程度。其中Xi是所有涉及到成龙的、而且是Alice评过分的电影,Avg就是3.1中算出来的平均分,n就是所有涉及到成龙的、而且是Alice评过分的电影的数量。在这个例子中公式应该等于((4 - 4) + (5 - 4)) / 2 = 0.5,也就是说,Alice对成龙的喜好程度可以用0.5这个数值来反应。
算出Alice对成龙的喜好程度。其中Xi是所有涉及到成龙的、而且是Alice评过分的电影,Avg就是3.1中算出来的平均分,n就是所有涉及到成龙的、而且是Alice评过分的电影的数量。在这个例子中公式应该等于((4 - 4) + (5 - 4)) / 2 = 0.5,也就是说,Alice对成龙的喜好程度可以用0.5这个数值来反应。
3.3、类似于Item Profiles,User Profiles也用到了一个1xn维的矩阵,与Item Profiles的矩阵不同的是,User Profiles中矩阵的元素不再是0,1,而是由3.2计算得来的对每个演员的喜好程度,所以最终Alice的矩阵可以表示为[0.5,x,y,z,...........xx,oo],回想一下,在2.2中我们已经做出了假设:矩阵的第0个元素代表成龙,所以这里的第0个元素是0.5,表示Alice对成龙的喜好程度是0.5。同理,可以算出Alice对其他演员的喜好程度。
4、计算推荐依据
利用余弦相似度的公式来计算给定的User “U”和给定的Item “I”之间的距离。余弦相似度的值越大说明U越有可能喜欢I。
余弦相似度的具体计算方法如下:
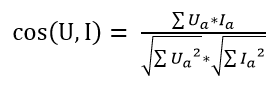
在电影推荐系统的例子中:
Ua表示,用户U对演员a的喜好值(即User Profiles矩阵中,演员a对应的值)
Ia表示,电影I是否包含演员a(即Item Profiles矩阵中,演员a对应的值)
5、开始推荐!
我们可以按照4中介绍的方法来遍历整个影片库,计算Alice与每个电影的相似度,选择相似度最高的前k个电影,推荐给Alice,大功告成!

