1、推荐系统简介
个性化推荐是根据用户的兴趣特点和购买行为,向用户推荐用户感兴趣的信息和商品。
推荐系统主要处理的有两类内容:一个是User,一个是Item。系统的目标也很明确,就是向User推荐Item。
应用了推荐系统的例子有很多,比如:知名的电商:Amazon,全球有名的在线影片租赁商:Netflix,国内的新闻应用:今日头条。
2、推荐系统分类
2.1基于内容的推荐(Content-based Recommendation)
基于内容的推荐系统的核心思想是挖掘被推荐对象的信息。基于内容的推荐算法的前提假设是:如果用户喜欢物品a,那么用户也应该会喜欢与a类似的物品。由于笔者的目的是侧重于介绍协同过滤推荐算法,所以对基于内容的推荐算法举个简单的例子一带而过:
假设一首歌有:名称、歌手、风格、作曲人这4个属性。如果用户Alice对Michael 的歌曲Beat It评分很高,那么系统会分析Beat It这首歌的属性,随后系统就可能会向Alice推荐Michael的歌曲Dangerous,因为Dangerous与Beat It有很多共同之处:歌手都是Michael,风格都是摇滚。
总的来讲,基于内容的推荐,利用的是被推荐对象自身的属性信息,利用这些信息来聚类,例如将众多的歌曲按风格聚类,得到蓝调风格的歌曲集合、摇滚风格的集合、田园风格的集合等等,当用户表示喜欢某一首歌曲时,系统会分析这个歌曲属于哪个风格,如果这个歌曲属于摇滚风格,那么系统就会从摇滚风格的集合中挑选出一些歌曲,将其推荐给用户。当然,这只是一种思路,实际的基于内容的推荐比我描述的要更复杂更详细,有兴趣的朋友可以深入研究一下,我以后有空也会把基于内容的推荐算法做一个详细介绍。
2.2协同过滤推荐 (Collaborative Filtering Recommendation)
协同过滤算法是推荐系统中应用最为广泛和成功的算法。协同过滤推荐算法的前提假设是:如果用户a与用户b均对一系列相同的物品表示喜欢,那么a极有可能也喜欢b用户喜欢的其他物品。在协同过滤推荐的过程中:用户首先为每个项目进行评价打分,通过计算不同用户评分之间的相似程度,可以找到最近邻居,根据最近邻居的评价,产生推荐——这是协同过滤算法的主要思想。 举例来讲,假设在音乐推荐系统中,一共有4个用户,7个音乐,每个用户对每个音乐的评价矩阵如下:
| |
All About That Bass |
Shake It Off |
Black Widow |
Habits |
Bang Bang |
Don't Tell 'Em |
Animals |
| Alice |
4 |
|
|
5 |
1 |
|
|
| Bob |
5 |
5 |
4 |
4 |
2 |
|
|
| John |
2 |
|
|
1 |
5 |
4 |
|
| David |
|
3 |
|
|
|
|
3 |
注:总分为5分,空项表示该用户没有听过该音乐因此尚且没有做出过评价。
此时要为用户Alice推荐一些她可能喜欢的音乐步骤如下:
1.寻找与Alice“品味”最接近的用户
自然描述:
这里的“品味”相近反应到数字上就是打分接近。比如表中,Alice对All About That Bass和Habits这两首歌有着极高的评价(分别为4分和5分),但是不喜欢Bang Bang;通过观察不难发现Bob对All About That Bass和Habits也表示相当的喜欢(分别为5分和4分),但对Bang Bang评价较低(仅为2分)。因此不难发现,实际上Alice和Bob的品味是较为接近的,Bob就是Alice的最近邻用户
数学模型:
当然,当用户多起来的时候,我们不可能用肉眼找到Alice的邻居用户,所以要建立数学模型让算法自动寻找Alice的邻居用户。实际上有很多的方法来衡量两个用户的“品味”是否相近。如果把上面表格中的每一行看作是一个向量,这个向量就用来表示用户喜好,那么就可以用多种方法来衡量两个用户喜好的相似度,如余弦相似度、皮尔逊相似度等,在这里只简单介绍一种:
余弦相似度:
其中Cos(u1,u2)就表示用户u1与用户u2的相似度;
R就是评价矩阵,Ru1,y表示用户u1对音乐y的评分,Ru2,y表示用户u2对音乐y的评分;
分子中的y表示用户u1与用户u2评价过的音乐的交集;
分母中的y则表示用户u1与u2各自的评分集合;
2.利用Alice的最近邻用户预测Alice的打分值
我们可以遍历所有用户,Alice与每个人都计算出一个相似度,随后对相似度进行排序,选择前10个相似度最高的用户作为Alice的最近邻用户。用这10个最近邻用户的评分数据来给Alice进行推荐,在介绍推荐算法之前,首先要提一下这个公式:
其中,Predict(u,i)就表示用户u对音乐i的打分预测值;
U就是用户u的最近邻用户集合;
R就是评价矩阵;
3.向Alice推荐音乐!
将第二步得到的一些Alice从未听过的音乐的预测分值进行排序,选择前10个分值最高的音乐推荐给Alice,大功告成!
由于是初次结束推荐算法,所以文中难免有错误,欢迎大家指正~我也会再抽时间更新一些关于推荐算法的文章~

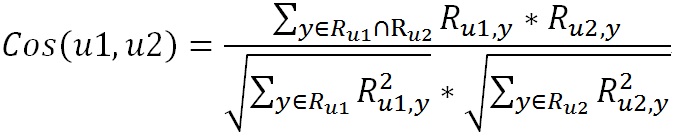
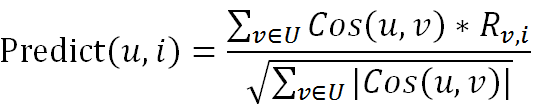

 浙公网安备 33010602011771号
浙公网安备 33010602011771号