
排序与查找
第十一章 排序与查找
- 算法的概念
算法(Algorithm)是将一组输入转化成一组输出的一系列步骤,其中每个步骤必须能在有限时间内完成。例如,将一组数按从小到大排序,输入是一组原始数据,输出是排序之后的数据,计算步骤包括比较、移动数据等操作。
算法是用来解决一类计算问题的,注意是一类问题,而不是一个特定的问题。由于算法是用来解决一类问题的,它必须能够正确地解决这一类问题中的任何一个实例,这个算法才是正确的。不正确的算法有两种可能,一是对于该问题的某些输入,该算法会无限计算下去,不会终止,二是对于该问题的某些输入,该算法终止时输出的是错误的结果。有时候不正确的算法也是有用的,如果对于某个问题寻求正确的算法很困难,而某个不正确的算法可以在有限的时间内终止,并且能把误差控制在一定范围内,那么这样的算法也是有实际意义的。例如有时候寻找最优解的开销很大,往往会选择能给出次优解的算法。
2.插入排序
编程对于一个数组进行插入排序,要将插入点之后的数据往后移动一个单元。排序算法如下:

为了更清楚地观察排序过程,我们在每次循环开头插入了打印语句,在排序结束后也插入了打印语句。运行结果是:

如何严格证明这个算法是正确的?换句话说,只要反复执行该算法的for循环体,执行LEN-1次,就一定能把数组a排好序,而不管数组a的原始数据是什么,如何证明这一点呢?我们可以借助Loop Invariant的概念和数学归纳法来理解循环结构的算法,假如某个判断条件满足以下三条准则,它就称为Loop Invariant:
- 第一次执行循环体之前该判断条件为真
- 如果“第N-1次循环之后(或者说第N次循环之前)该判断条件为真”这个前提可以成立,那么就有办法证明第N次循环之后该判断条件仍为真
- 如果在所有循环结束后该判断条件为真,那么就有办法证明该算法正确地解决了问题
只要我们找到了这个Loop Invariant,就可以证明一个循环结构的算法是正确的。上面插入排序算法的Loop Invariant是这样的判断条件:第j次循环之前,子序列a[0..j-1]是排好序的。在上面的打印结果中,我把子序列a[0..j-1]加粗表示。下面我们验证以下Loop Invariant的三条准则:
- 第一次执行循环之前,j=1,子序列a[0..j-1]只有一个元素a[0],只有一个元素的序列显然是排好序的。
- 第j次循环之前,如果“子序列a[0..j-1]是排好序的”这个前提成立,现在要把key=a[j]插进去,按照该算法的步骤,把a[j-1]、a[j-2]、a[j-3]等等比key大的元素都依次往后移一个,直到找到合适的为止给key插入,就能证明循环结束时子序列a[0..j]是排好序的。
- 当循环结束时,j=LEN,如果“子序列a[0..j-1]是排好序的”这个前提成立,那就是说a[0..LEN-1]是排好序的,也就是说整个数组a的LEN个元素都排好序了。
可见,有了这三条,就可以用数学归纳法证明这个循环是正确的。
3.算法的时间复杂度分析
解决同一个问题可以有很多种算法,比较评价算法的好坏,一个重要的标准就是算法的时间复杂度。现在研究一下插入排序算法的执行时间,按照习惯,输入长度LEN以下用n表示。假设循环中各条语句的执行时间分别是c1、c2、c3、c4、c5这样五个常数:

显然外层for循环执行次数是n-1次,假设内层的while循环执行m次,则总的执行时间粗略估计是(n-1)*(c1+c2+c5+m*(c3+c4))。当然,for和while后面()括号中的赋值和判断也需要时间,而我没有设一个常数来表示,这不影响我们的粗略估计。
这里有一个问题,m不是个常数,也不取决于输入长度n,而是取决于具体的输入数据。在最好的情况下,数组a的原始数据已经排好序了,while循环一次也不执行,总的执行时间是(c1+c2+c5)*n-(c1+c2+c5),可以表示成an+b的形式,是n的线性函数(Linear Function)。那么在最坏情况(Worst Case)下又如何呢?所谓最坏情况是指数组a的原始数据正好是从大到小排好序的,把上式中的m替换掉算一下执行时间是多少。
数组a的原始数据属于最好和最坏情况都比较少见,如果原始数据是随机的,可称为平均情况(Average Case)。如果原始数据是随机的,那么每次循环将已排序的子序列a[1..j-1]与新插入的元素key相比较,子序列中平均都有一半的元素比key大而另一半比key小,你可把上式中的m替换掉算一下执行时间是多少。最后的结论是:在最坏情况和平均情况下,总的执行时间都可以表示成的形式,是n的二次函数(Quadratic Function)。
在分析算法的时间复杂度时,我们更关心最坏的情况而不是最好情况,理由如下:
- 最坏情况给出了算法执行时间的上界,我们可以确信,无论给什么输入,算法的执行时间不会超过这个上界,为比较和分析提供了遍历。
- 对于某些算法,最坏的情况是最常发生的情况,例如在数据库中查找某个信息的算法,最坏情况就是数据库中根本不存在该信息,都找遍了也没有,而某些应用场合经常要查找一个信息在数据库中存在不存在。
- 虽然最坏情况是一种悲观估计,但是对于很多问题,平均情况和最坏情况的时间复杂度差不多,比如插入排序这个例子,平均情况和最坏情况的时间复杂度都是输入长度n的二次函数。
比较两个多项式和的值(n取正整数)可以得出结论:n的最高次指数是最主要的决定因素,常数项、低次幂项和系数都是次要的。比如100n+1和,虽然后者的系数小,当n较小时前者的值较大,但是当n>100时,后者的值就远远大于前者了。如果同一个问题可以用两种算法解决,其中一种算法的时间复杂度为线性函数,另一种算法的时间复杂度为二次函数,当问题的输入长度n足够大时,前者明显优于后者。因此。因此我们可以用一种更粗略的方式表示算法的时间复杂度,把系数和低次幂项都省去,线性函数记作,二次函数记作。表示和g(n)同一量级的一类函数,例如所有的二次函数f(n)都和g(n)=属于同一量级,都可以用来表示,甚至有些不是二次函数的也和属于同一量级,例如。“同一量级”这个概念可以用下图来说明(该图出自[算法导论]):
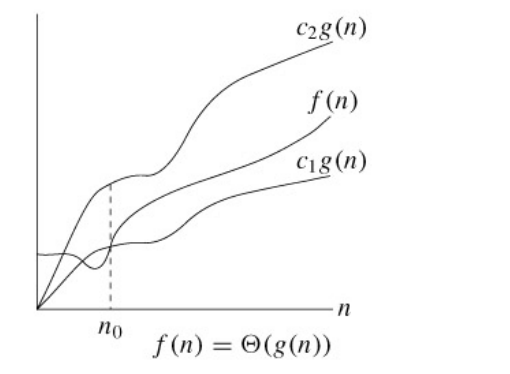
如果可以找到两个正的常数和,使得n足够大的时候(也就是的时候)f(n)总是夹在和之间,就是说f(n)和g(n)是同一量级的,f(n)就可以用来表示。以二次函数为例,比如,要证明它是属于这个集合的,我们必须确定、和,这些常数不随n而改变,并且当以后,总是成立的。为此我们从不定式的每一边都除以,得到。见下图:
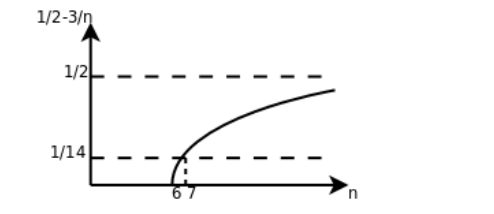
这样就很容易看出来,无论n取多少,该函数一定小于1/2,因此=1/2,当n=6时函数值为0,n>6时该函数都大于0,可以取=7,=1/14,这样当时都有1/2-3/n。通过这个证明过程可以得出结论,当n足够大时任何都夹在和之间,相对于项来说bn+c的影响可以忽略,a可以通过选取合适的、来补偿。
几种常见的时间复杂度函数按数量级从小到大的顺序依次是:

其中,lgn通常表示以10为底n的对数,但是对于-notation来说,和并无区别,在算法分析中lgn通常表示以2为底n的对数。
除了-notation之外,表示算法的时间复杂度常用的还有一种Big-O notation。我们知道插入排序在最坏的情况和平均情况下时间复杂度是,在最好的情况下是,数量级比要小,那么总结起来在各种情况下插入排序的时间复杂度是。的含义和“等于”类似,而大大O的含义和“小于等于”类似。
4.归并排序
插入排序算法采取增量式(Incremental)的策略解决问题,每次添一个元素到已排序的子序列中,逐渐将整个数组排序完毕,它的时间复杂度是。下面介绍另一个典型的排序算法——归并排序,它采取分而治之(Divide-and-Conquer)的策略,时间复杂度是,优于插入排序算法。归并排序的步骤如下:
1) Divide:把长度为n的输入序列分成两个长度为n/2的子序列。
2) Conquer:对这两个子序列分别采用归并排序。
3) Combine:将两个排序好的子序列合并成一个最终的排序序列。
在描述归并排序的步骤时又调用了归并排序本身,可见这是一个递归的过程。
归并排序:
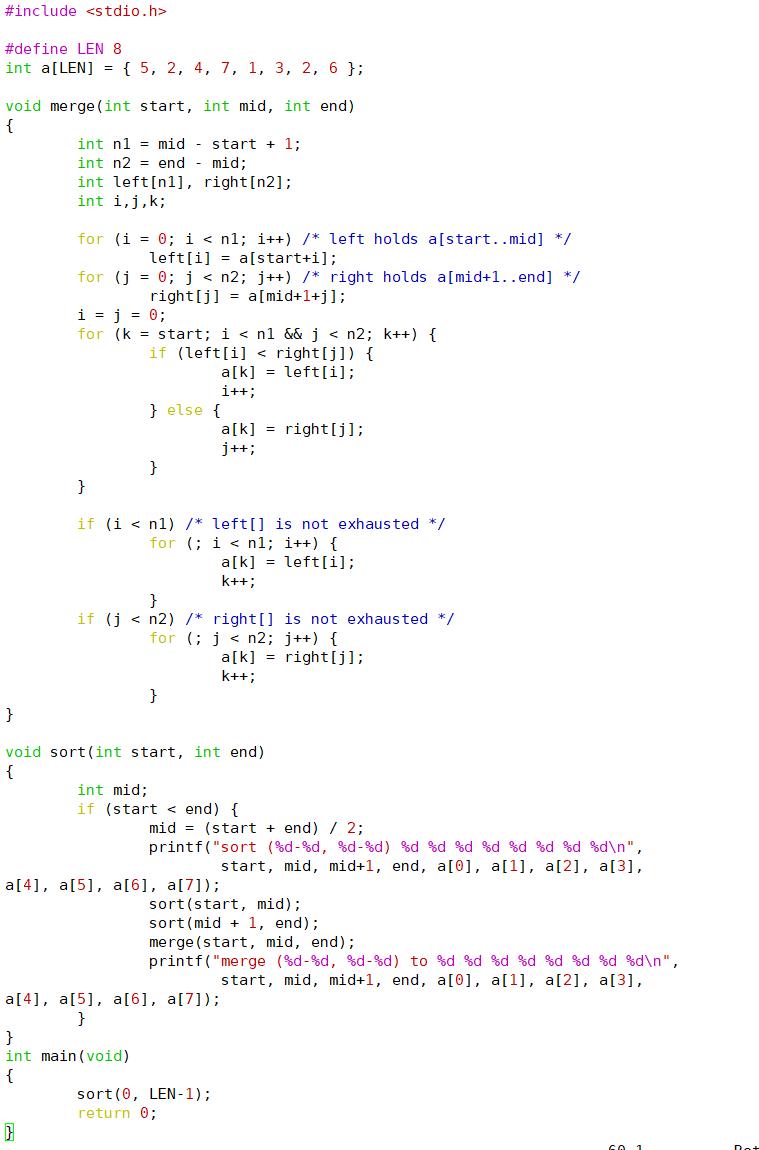
执行结果是:

Sort函数把a[start..end]平均分成两个子序列,分别是a[start..mid]和a[mid+1..end],对这两个子序列分别递归调用sort函数进行排序,然后调用merge函数将排好序的两个子序列合并起来,由于两个子序列都已经排好序了,合并的过程很简单,每次循环取两个子序列中最小的元素进行比较,将较小的元素取出放到最终的排序序列中,如果其中一个子序列的元素已取完,就把另一个子序列剩下的元素都放到最终的排序序列中。为了便于理解程序,我在sort函数开头和结尾插了打印语句,可以看出调用过程是这样的:
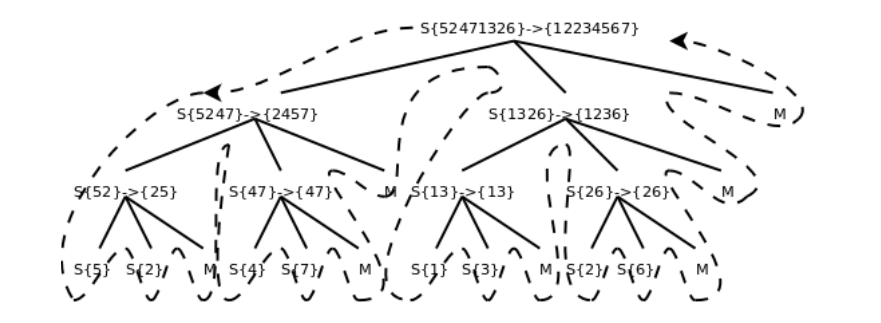
图中S表示sort函数,M表示merge函数,整个控制流程沿虚线所示的方向调用和返回。由于sort函数递归调用了自己两次,所以各函数之间调用关系呈树状结构。画这个图只是为了更清楚地展现归并排序的过程,读者在理解递归函数时一定不要全部展开来看,而是要抓住Base Case和递推关系来理解。
归并排序是比插入排序更好的算法,虽然merge函数的步骤较多,引入了较大的常数、系数和低次项,但是对于较大的输入长度n,这些都不是主要因素,归并排序是,插入排序的平均情况是,这就决定了归并排序是更快的算法。
5.线性查找
有些问题可以用的算法来解决。例如写一个indexof函数,从任意输入字符串中找出某个字母的位置并返回这个位置,如果找不到就返回-1:
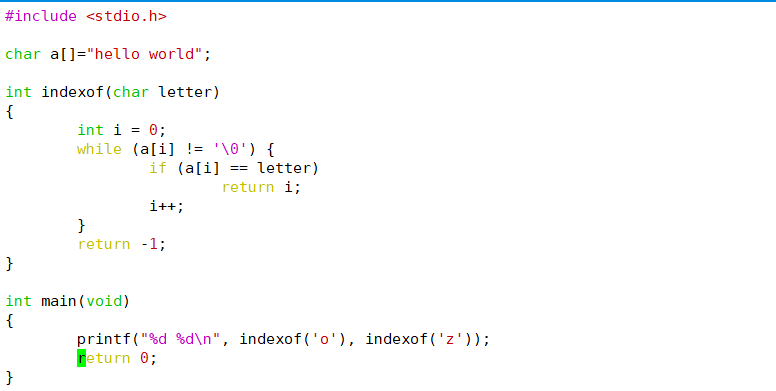
6.折半查找
“每次将搜索范围缩小一半”的思想称为折半查找(Binary Search)。

从普遍意义上说,调用者(Caller)和被调用者(或者叫函数的实现者,Callee)之间订立一个契约(Contract),在调用函数之前,Caller需要对Callee尽到某些义务,比如确保a是排好序的,确保a[start..end]都是有效的数组元素而没有访问越界,这称为Precondition,然后在Callee中对一些Invariant进行维护(Maintenance),这些Invariant保证了Callee在结束时能够对Caller尽到某些义务,比如确保“如果number在数组a中存在,一定能找出来并返回它的位置,如果number在数组a中不存在,一定能返回-1”,这称为Post condition。如果每个函数的文档都非常清楚地记录了Precondition、Maintenance和Postcondition是什么,那么每个函数都可以独立地编写和测试,整个系统就会易于维护。
测试一个函数是否正确需要把Precondition、Maintenance和Postcondition这三方面都测试到,比如binarysearch这个函数,即使写的非常正确,既维护了Invariant也保证了Postcondition,如果调用它的Caller没有保证Precondition,最后的结果也还是错的。我们编写两个测试用的Predicate函数,然后把相关的测试插入到binary search函数中:

Assert是头文件assert.h中的一个宏定义,执行到assert(is_sorted())这句时,如果is_sorted()返回值为真,则当什么事都没发生过,继续往下执行,如果is_sorted()返回值为假(例如把数组的排列顺序改一改),则报错退出程序:
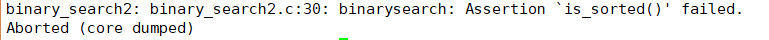
在代码中适当的地方使用断言(Assertion)可以有效地帮助我们测试程序。
测试代码只在开发和调试时有用,如果已经发布(Release)的软件还要运行这些测试代码就会严重影响性能了,所以C语言规定,如果在包含assert.h之前定义一个NDEBUG宏(表示NoDebug),就可以禁用assert.h中的assert宏定义,代码中的assert就不起任何作用了:

还有另一种办法,不必修改源文件,直接在编译时加上选项-DNDEBUG,相当于在文件开头定义NDEBUG宏。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号