
tencent_2.3_shallow_neural_networks
课程地址:https://cloud.tencent.com/developer/labs/lab/10298/console
数据准备
wget https://devlab-1251520893.cos.ap-guangzhou.myqcloud.com/t10k-images-idx3-ubyte.gz wget https://devlab-1251520893.cos.ap-guangzhou.myqcloud.com/t10k-labels-idx1-ubyte.gz wget https://devlab-1251520893.cos.ap-guangzhou.myqcloud.com/train-images-idx3-ubyte.gz wget https://devlab-1251520893.cos.ap-guangzhou.myqcloud.com/train-labels-idx1-ubyte.gz

import numpy as np import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data def add_layer(inputs, in_size, out_size, activation_function=None): W = tf.Variable(tf.random_normal([in_size, out_size])) b = tf.Variable(tf.zeros([1, out_size]) + 0.01) Z = tf.matmul(inputs, W) + b if activation_function is None: outputs = Z else: outputs = activation_function(Z) return outputs if __name__ == "__main__": MNIST = input_data.read_data_sets("./", one_hot=True) learning_rate = 0.05 batch_size = 128 n_epochs = 10 X = tf.placeholder(tf.float32, [batch_size, 784]) Y = tf.placeholder(tf.float32, [batch_size, 10]) l1 = add_layer(X, 784, 1000, activation_function=tf.nn.relu) prediction = add_layer(l1, 1000, 10, activation_function=None) entropy = tf.nn.softmax_cross_entropy_with_logits(labels=Y, logits=prediction) loss = tf.reduce_mean(entropy) optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss) init = tf.initialize_all_variables() with tf.Session() as sess: sess.run(init) n_batches = int(MNIST.train.num_examples/batch_size) for i in range(n_epochs): for j in range(n_batches): X_batch, Y_batch = MNIST.train.next_batch(batch_size) _, loss_ = sess.run([optimizer, loss], feed_dict={X: X_batch, Y: Y_batch}) if j == 0: print "Loss of epochs[{0}] batch[{1}]: {2}".format(i, j, loss_) # test the model n_batches = int(MNIST.test.num_examples/batch_size) total_correct_preds = 0 for i in range(n_batches): X_batch, Y_batch = MNIST.test.next_batch(batch_size) preds = sess.run(prediction, feed_dict={X: X_batch, Y: Y_batch}) correct_preds = tf.equal(tf.argmax(preds, 1), tf.argmax(Y_batch, 1)) accuracy = tf.reduce_sum(tf.cast(correct_preds, tf.float32)) total_correct_preds += sess.run(accuracy) print "Accuracy {0}".format(total_correct_preds/MNIST.test.num_examples)
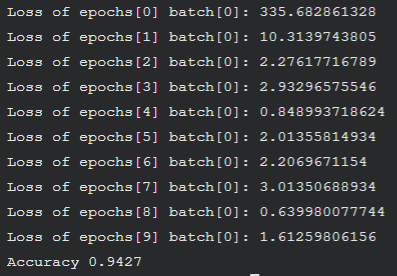
我尝试修改learning_rate和weights的标准差:
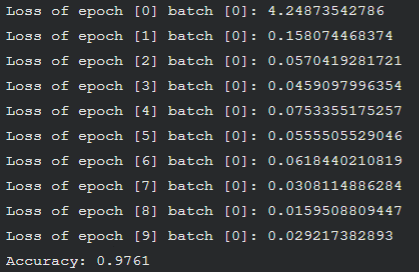
w = tf.Variable(tf.random_normal(shape=[in_size, out_size], stddev=0.1)) ... learning_rate=0.2
收敛明显加快:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号