
试用Face++ 人脸识别API demo
Face++提供API和SDK试用,注册后有一星期的使用时长,注册不需要身份证照片,手机注册即可,SDK付费,不过用法好像跟API差不多
参考博客:
廖雪峰的官方网站:内置模块:urllib 第三方模块:requests
Face++ Detect API: 文档(重要) API演示
返回值是Json文件,照着文档解字典即可得到数据,rectangle和landmark使用使用PIL包的函数进行绘制
# -*- coding: utf-8 -*- import urllib.request import urllib.error import matplotlib.pyplot as plt import time import json from skimage import io import numpy as np from PIL import Image, ImageDraw http_url = 'https://api-cn.faceplusplus.com/facepp/v3/detect' key = "740HGdE-kYbuHiv5K7bz0Sy4v2oUcT1m" secret = "t8ctrIbKdhUpmkR_sp5fAxEETTbDrP9N" filepath = r"C:\Users\xiexj\Desktop\test.jpg" boundary = '----------%s' % hex(int(time.time() * 1000)) data = [] data.append('--%s' % boundary) data.append('Content-Disposition: form-data; name="%s"\r\n' % 'api_key') data.append(key) data.append('--%s' % boundary) data.append('Content-Disposition: form-data; name="%s"\r\n' % 'api_secret') data.append(secret) data.append('--%s' % boundary) fr = open(filepath, 'rb') data.append('Content-Disposition: form-data; name="%s"; filename=" "' % 'image_file') data.append('Content-Type: %s\r\n' % 'application/octet-stream') data.append(fr.read()) fr.close() data.append('--%s' % boundary) data.append('Content-Disposition: form-data; name="%s"\r\n' % 'return_landmark') data.append('2') data.append('--%s' % boundary) data.append('Content-Disposition: form-data; name="%s"\r\n' % 'return_attributes') data.append( "gender,age,smiling,headpose,facequality,blur,eyestatus,emotion,ethnicity,beauty,mouthstatus,eyegaze,skinstatus") data.append('--%s--\r\n' % boundary) for i, d in enumerate(data): if isinstance(d, str): data[i] = d.encode('utf-8') # change to byte type http_body = b'\r\n'.join(data) # build http request req = urllib.request.Request(url=http_url, data=http_body) # header req.add_header('Content-Type', 'multipart/form-data; boundary=%s' % boundary) try: # post data to server resp = urllib.request.urlopen(req, timeout=5) # get response qrcont = resp.read() # if you want to load as json, you should decode first, # for example: json.loads(qrcont.decode('utf-8')) # print(qrcont.decode('utf-8')) dic = json.loads(qrcont.decode('utf-8')) # print(dic) print(type(dic)) faces_data = dic['faces'] faces_data = faces_data[0] print(faces_data.get('face_token')) print(faces_data.get('face_rectangle')) dictFace = faces_data.get('face_rectangle') left = dictFace['left'] top = dictFace['top'] height = dictFace['height'] width = dictFace['width'] # landmark dictLandmark = faces_data.get('landmark') img = Image.open(filepath) print(type(img)) img1 = np.array(img) draw = ImageDraw.Draw(img) draw.line([(left, top), (left + width, top), (left + width, top + height), (left, top + width), (left, top)], 'red') new_img = img1[top:(top + height), left:(left + width)] io.imsave(r"C:\Users\xiexj\Desktop\res.jpg", new_img) for i in dictLandmark: top = dictLandmark[i]['y'] left = dictLandmark[i]['x'] draw.line([(left, top), (left + 1, top), (left + 1, top + 1), (left, top + 1), (left, top)], 'blue') img.show() # attributes dictAttributes = faces_data.get('attributes') print("gender: %s" % dictAttributes.get("gender").get("value")) print("age: %s" % dictAttributes.get("age").get("value")) print("glass: %s" % dictAttributes.get("glass").get("value")) print("ethnicity: %s" % dictAttributes.get("ethnicity").get("value")) print("beauty_male: %s" % dictAttributes["beauty"]["male_score"]) print("beauty_female: %s" % dictAttributes["beauty"]["female_score"]) except urllib.error.HTTPError as e: print(e.read().decode('utf-8'))
挑一段核心代码(加上了输出):
for i, d in enumerate(data): if isinstance(d, str): data[i] = d.encode('utf-8') # change to byte type http_body = b'\r\n'.join(data) for i in range(len(data)): print(data[i]) print("??????????????????????????????????????????????????") print(type(http_body)) print(http_body) # build http request req = urllib.request.Request(url=http_url, data=http_body) # header req.add_header('Content-Type', 'multipart/form-data; boundary=%s' % boundary)
输出:

不清楚为什么要加上这些boundary,但注释掉报错:{"error_message":"MISSING_ARGUMENTS: api_secret"}
可以看到要进行url请求的 http_body 为ascii编码格式
返回值(106个关键点):

D:\Anaconda\python.exe D:/code/face++/test.py <class 'dict'> 354026ba716d35a2f3acc8ccd74c512b {'width': 77, 'top': 48, 'left': 149, 'height': 77} <class 'PIL.JpegImagePlugin.JpegImageFile'> gender: Male age: 58 glass: None ethnicity: WHITE beauty_male: 29.189 beauty_female: 41.781 Process finished with exit code 0
本亮大叔的实际年龄55,预测值58,人种预测是白色,颜值是29分......还是有点扯
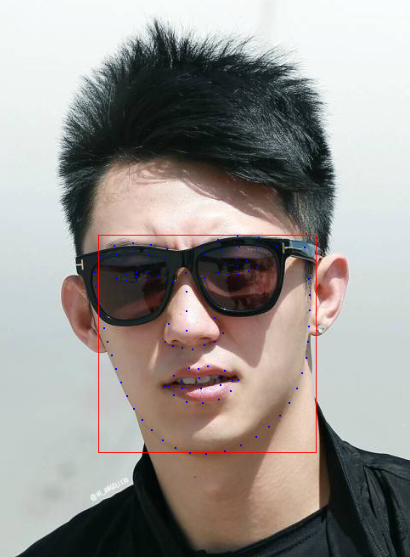
D:\Anaconda\python.exe D:/code/face++/test.py <class 'dict'> 6445cf79037f4b82a962badf796fee21 {'width': 256, 'top': 335, 'left': 202, 'height': 256} <class 'PIL.JpegImagePlugin.JpegImageFile'> gender: Male age: 25 glass: Dark ethnicity: INDIA beauty_male: 87.41 beauty_female: 88.369 Process finished with exit code 0
黄景瑜实际年龄27,预测年龄25,戴眼镜,印度人种?颜值87分......
旷世的API还提供了很多有意思的检测,我没有都提取出来
我这里使用的是Detect API,这个API基本包括了人脸识别的检测属性,比较全,另外还有人脸识别,证件识别,图像识别




 浙公网安备 33010602011771号
浙公网安备 33010602011771号