
Tensorflow 搭建自己的神经网络(四)
- tf.nn.rnn_cell.BasicLSTMCell(n_hidden, forget_bias=1.0, state_is_tuple=True):
n_hidden表示神经元的个数,
forget_bias就是LSTM们的忘记系数,如果等于1,就是不会忘记任何信息。如果等于0,就都忘记。
state_is_tuple默认就是True,官方建议用True,就是表示返回的状态用一个元祖表示。
这个里面存在一个状态初始化函数,就是zero_state(batch_size,dtype)两个参数。batch_size就是输入样本批次的数目,dtype就是数据类型。
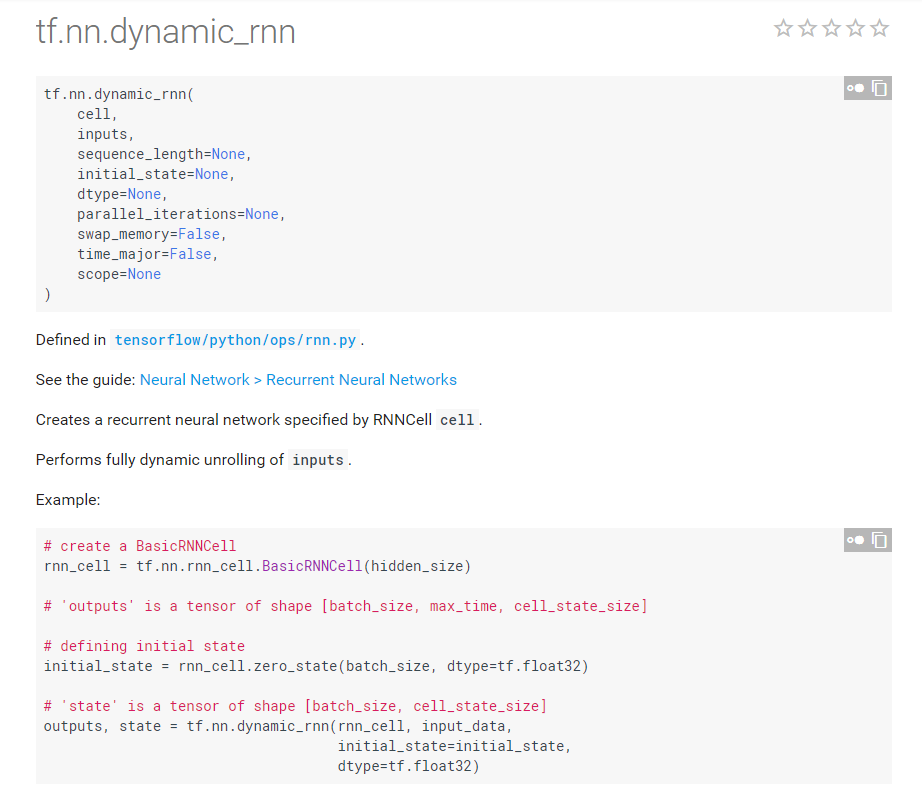
- tf.nn.dynamic_rnn(cell,inputs,sequence_length=None, initial_state=None,dtype=None, parallel_iterations=None,swap_memory=False, time_major=False, scope=None)
对于单个 RNNCell ,使用call 函数进行运算时,只在序列时间上前进了一步 ,如使用 x1、 ho 得到此h1,通过 x2 、h1 得到 h2 等 。
如果序列长度为n,要调用n次call函数,比较麻烦。对此提供了一个tf.nn.dynamic_mn函数,使用该函数相当于调用了n次call函数。通过{ho, x1 , x2,…,xn} 直接得到{h1 , h2,…,hn} 。
具体来说,设输入数据inputs格式为(batch_size, time_steps, input_size),其中batch_size表示batch的大小。time_steps序列长度,input_size输入数据单个序列单个时间维度上固有的长度。
得到的outputs是time_steps步里所有的输出。它的形状为(batch_size, time_steps, cell.output_size)。state 是最后一步的隐状态,形状为(batch_size, cell . state_size) 。
RNN_classification
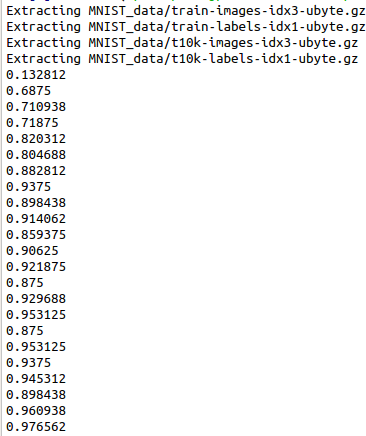
#!/usr/bin/env python2 # -*- coding: utf-8 -*- """ Created on Tue Apr 9 20:36:38 2019 @author: xiexj """ import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_data.read_data_sets('MNIST_data', one_hot=True) tf.reset_default_graph() #hyperparameters lr = 0.001 training_iters = 100000 batch_size = 128 n_inputs = 28 n_steps = 28 n_hidden_units = 128 n_classes = 10 #tf Graph input x = tf.placeholder(tf.float32, [None, n_steps, n_inputs]) y = tf.placeholder(tf.float32, [None, n_classes]) #Define weights weights = { 'in':tf.Variable(tf.random_normal([n_inputs, n_hidden_units])), 'out':tf.Variable(tf.random_normal([n_hidden_units, n_classes])) } biases = { 'in':tf.Variable(tf.constant(0.1, shape=[n_hidden_units, ])), 'out':tf.Variable(tf.constant(0.1, shape=[n_classes, ])) } def RNN(X, weights, biases): #hidden layer for input to cell X = tf.reshape(X, [-1,n_inputs]) X_in = tf.matmul(X, weights['in'])+biases['in'] X_in = tf.reshape(X_in, [-1, n_steps, n_hidden_units]) #cell lstm = tf.contrib.rnn.BasicLSTMCell(n_hidden_units, forget_bias=1.0, state_is_tuple=True) init_state = lstm.zero_state(batch_size, dtype=tf.float32) outputs, final_state = tf.nn.dynamic_rnn(lstm, X_in, initial_state=init_state, time_major=False) #hidden layer for outputs and final results results = tf.matmul(final_state[1],weights['out']) + biases['out'] ### outputs = tf.unstack(tf.transpose(outputs, [1,0,2])) ### results = tf.matmul(outputs[-1], weights['out']) + biases['out'] # shape = (128, 10) # t_o = tf.convert_to_tensor(outputs,tf.float32) #128 28 128 # t_f = tf.convert_to_tensor(final_state,tf.float32) #2 128 128 # print(t_o[-1].get_shape().as_list(),t_f[0].get_shape().as_list(),t_f[1].get_shape().as_list()) return results pred = RNN(x, weights, biases) cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred,labels=y)) train_op = tf.train.AdamOptimizer(lr).minimize(cost) correct_pred = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) init = tf.global_variables_initializer() with tf.Session() as sess: sess.run(init) step = 0 while step*batch_size<training_iters: batch_xs, batch_ys = mnist.train.next_batch(batch_size) batch_xs = batch_xs.reshape([batch_size, n_steps, n_inputs]) sess.run(train_op, feed_dict = {x:batch_xs, y:batch_ys}) if step%20 == 0: print(sess.run(accuracy, feed_dict={x:batch_xs,y:batch_ys})) step+=1

 浙公网安备 33010602011771号
浙公网安备 33010602011771号