
Python爬虫+第三方库requests获取网页
安装库
使用国内镜像安装第三方库requests。
pip install requests -i https://mirrors.aliyun.com/pypi/simple/
测试库是否可用
import requests
response = requests.get("http://www.baidu.com")
print(response.text)
模拟浏览器方式访问网页
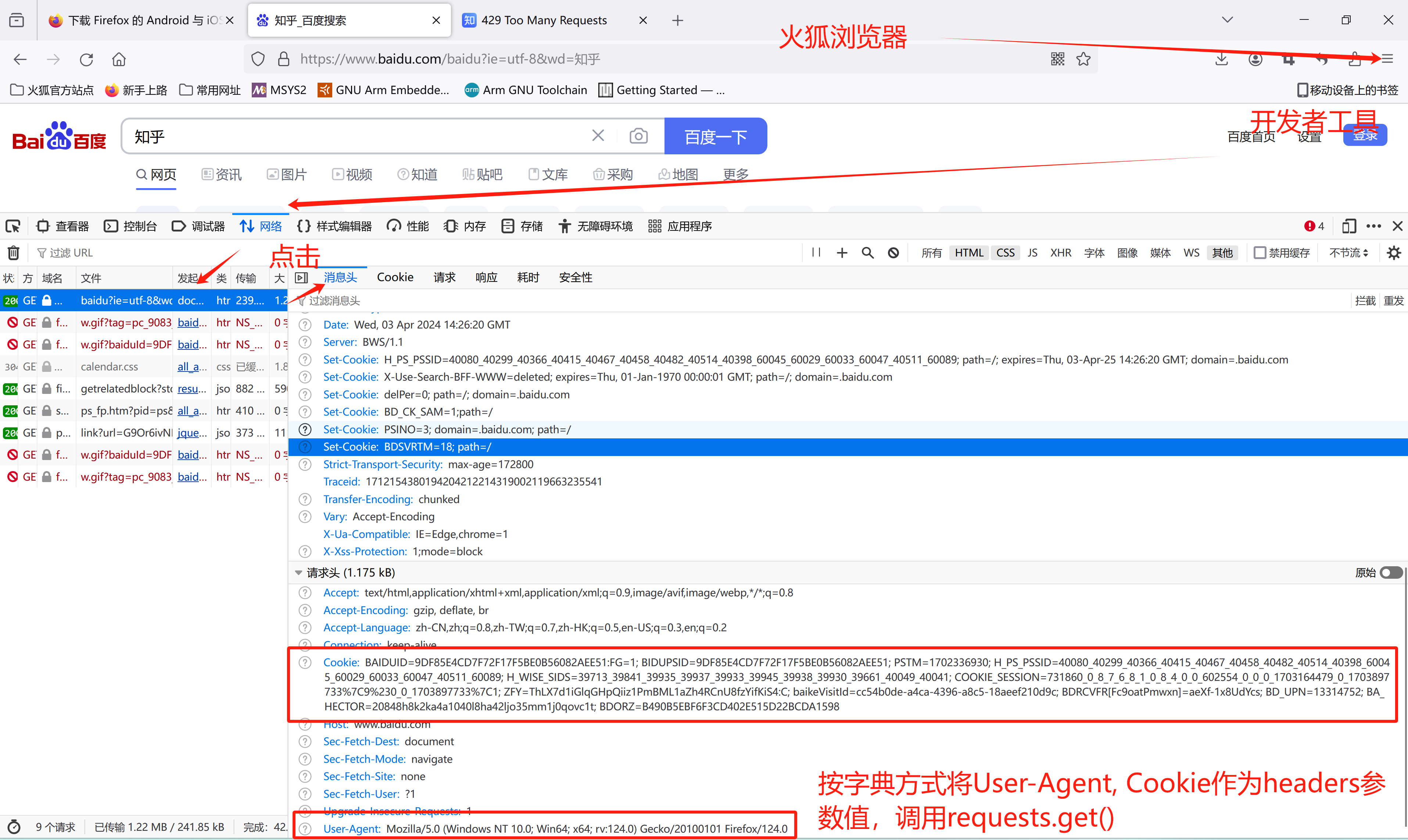
问题:更多网站只允许客户通过浏览器访问网页,拒绝客户使用程序访问网页。可以通过 带头部参数的网页请求,模拟浏览器访问网页。
import requests
myHeaders ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0' }
url ="https://www.zhihu.com"
r = requests.get(url,headers = myHeaders)
r.encoding = 'utf-8'
print(r.text)
如何获取 User-Agent 的值,参照下图:
模拟浏览器方式抓取网页并保存为文本文件
import requests
url_0 ="http://www.baidu.com"
url_1 ="https://www.njtech.edu.cn/" #南京工业大学
url_2 ="https://zgdypf.zgdypw.cn/" #中国电影票房
url_3 ="https://www.cnur.com/" #中国大学排名
url_4 ="https://www.wenxue88.com/index.html" #文学名著
url_5 ="https://www.duocaiwu.com/" #文学名著 多彩屋文学
#response = requests.get(url_3) #爬取指定网址网页
myHeaders ={ 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:124.0) Gecko/20100101 Firefox/124.0' }
response = requests.get(url_5,headers = myHeaders) #爬取指定网址网页
response.encoding ="utf-8" #指定编码方式,解决中文显示为乱码问题。
print(response.text)# 打印网页文本文件
with open("test.html","w",encoding="utf-8") as file:
file.write(response.text)# 保存为html文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号