
DOM(Document Object Model),“文档对象模型”早期是为了解决不用浏览器间数据兼容问题提出的解决方案,现在已经是W3C组织推荐的处理可扩展标志语言的标准编程接口。
W3C DOM 被分为 3 个不同的部分/级别(parts / levels):
- 核心 DOM:用于任何结构化文档
- XML DOM:用于 XML 文档的标准模型
- HTML DOM:用于 HTML 文档的标准模型
XML DOM 是:
- 用于 XML 的标准对象模型
- 用于 XML 的标准编程接口
- 中立于平台和语言
- W3C 的标准
SUN公司的JAXP(Java API for XML Processing)提供了对dom的支持;
其解析步骤为:
- 创建 DOM 解析器的工厂
- 得到 DOM 解析器对象。
对整个XML文档进行操作
<?xml version="1.0" encoding="UTF-8"?> <!-- <!DOCTYPE books SYSTEM "books.dtd"> --> <books> <book> <author>joy</author> <title>java core</title> <price>100</price> </book> <book> <author>joy1</author> <title>Thinking in java</title> <price>100</price> </book> <book> <comment author="joy" id="S001" language="Chinese" price="20" title="Java"/> <comment author="joy" id="S002" language="Chinese" price="20" title="Thinking in Java"/> </book> </books>
package com.sy; import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerConfigurationException; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.TransformerFactoryConfigurationError; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.xml.sax.SAXException; public class first { private static void findElement() throws ParserConfigurationException, SAXException, IOException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(new File("books.xml")); NodeList list = doc.getElementsByTagName("title"); Node node = list.item(1); System.out.println(node.getTextContent()); } // 获取属性内容 private static void getAttribute() throws ParserConfigurationException, SAXException, IOException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(new File("books.xml")); Element node = (Element) doc.getElementsByTagName("comment").item(1); System.out.println(node.getAttribute("title")); } // 使用递归遍历xml文档 private static void loopNode() throws ParserConfigurationException, SAXException, IOException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(new File("books.xml")); loop(doc); } private static void loop(Node doc) { NodeList list = doc.getChildNodes(); for (int i = 0; i < list.getLength(); i++) { Node node = list.item(i); System.out.println(node.getNodeName()); loop(node); } } // 添加节点,内容,属性 private static void createElement() throws ParserConfigurationException, SAXException, IOException, TransformerFactoryConfigurationError, TransformerConfigurationException, TransformerException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(new File("books.xml")); // 创建结点 Element e = doc.createElement("language"); // 添加内容 e.setTextContent("Chinese"); // 添加属性 e.setAttribute("aa", "xxx"); // 获取父节点,并append新创建的结点 doc.getElementsByTagName("book").item(1).appendChild(e); // 使用Transformer将内存中更新过的xml文档写入实际的xml文档中 TransformerFactory tfactory = TransformerFactory.newInstance(); Transformer tf = tfactory.newTransformer(); tf.transform(new DOMSource(doc), new StreamResult(new File("books.xml"))); } // 注意:DOM的解析方式为将整个xml文档都加载入内存,因此对文档节点的添加、删除和修改操作都是只针对内存中的document对象,因此还需要使用Transformer类将修改真正写入到xml文件中! // 删除节点 private static void deleteElement() throws ParserConfigurationException, SAXException, IOException, TransformerFactoryConfigurationError, TransformerConfigurationException, TransformerException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(new File("books.xml")); // 得到待删除的结点 Element e = (Element) doc.getElementsByTagName("language").item(0); // 获取结点的父节点,然后删除该子结点 e.getParentNode().removeChild(e); // 使用Transformer将内存中更新过的xml文档写入实际的xml文档中 TransformerFactory tfactory = TransformerFactory.newInstance(); Transformer tf = tfactory.newTransformer(); tf.transform(new DOMSource(doc), new StreamResult(new File("books.xml"))); } public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException, TransformerConfigurationException, TransformerFactoryConfigurationError, TransformerException { // findElement(); // getAttribute(); // loopNode() ; // createElement(); deleteElement(); } }
代码解读
这个类内含七个函数(包括五个自定义功能函数,一个递归函数体,一个main函数)
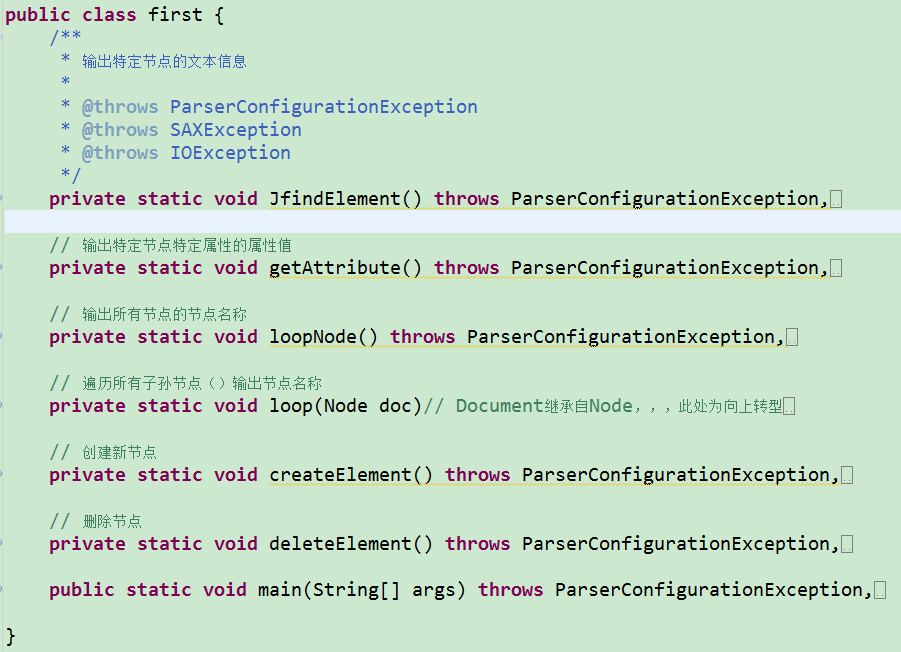
五个功能函数:
JfindElement():发现节点(输出特定节点的文本内容)
private static void JfindElement() throws ParserConfigurationException, SAXException, IOException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();// ???? DocumentBuilder builder = factory.newDocumentBuilder();// ???? Document doc = builder.parse(new File("./WebRoot/xml/t6.xml"));// 获取页面 NodeList list = doc.getElementsByTagName("title");// 获取tittle节点 System.out.println(list.getLength());// 输出title节点长度 Node node = list.item(1);// 第二个节点 System.out.println(node.getTextContent());// 输出第二个节点的文本信息 }
getAttribute():获得属性值(输出特定节点的属性值)
private static void getAttribute() throws ParserConfigurationException, SAXException, IOException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(new File("./WebRoot/xml/t6.xml")); Element node = (Element) doc.getElementsByTagName("comment").item(1);// 获取comment节点集合 System.out.println(node.getAttribute("title"));// 输出node节点的tittle属性的值 }
loop(Node doc):递归主函数体
private static void loop(Node doc)// Document继承自Node,,,此处为向上转型 { NodeList list = doc.getChildNodes();// 获取孩子节点的集合 // 便利孩子节点集合 // 输出每个节点的标签名 // 递归调用,输出每一层的子节点 for (int i = 0; i < list.getLength(); i++) { Node node = list.item(i); System.out.println(node.getNodeName()); loop(node); } }
loopNode()递归输出所有节点
// 输出所有节点的节点名称 private static void loopNode() throws ParserConfigurationException, SAXException, IOException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(new File("./WebRoot/xml/t6.xml")); loop(doc);// 函数调用输出doc所有子孙节点 }
createElement():
创建新节点
把新节点添加到父节点后面
更新文档(把修改后的xml文档同步到本地)
private static void createElement() throws ParserConfigurationException, SAXException, IOException, TransformerFactoryConfigurationError, TransformerConfigurationException, TransformerException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse("./WebRoot/xml/t6.xml"); // 创建结点 Element e = doc.createElement("language"); // 为新创建的节点添加内容 e.setTextContent("Chinese"); // 为新创建的节点添加属性 e.setAttribute("aa", "xxx"); // 为新创建的节点获取父节点,并append新创建的结点 doc.getElementsByTagName("books").item(1).appendChild(e); // 使用Transformer将内存中更新过的xml文档写入实际的xml文档中 TransformerFactory tfactory = TransformerFactory.newInstance(); Transformer tf = tfactory.newTransformer(); tf.transform(new DOMSource(doc), new StreamResult(new File( "./WebRoot/xml/t6.xml"))); }
deleteElement():删除节点
找到他的父节点
父节点删除要删除的节点
更新文档(把修改后的xml文档同步到本地)
private static void deleteElement() throws ParserConfigurationException, SAXException, IOException, TransformerFactoryConfigurationError, TransformerConfigurationException, TransformerException { DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); DocumentBuilder builder = factory.newDocumentBuilder(); Document doc = builder.parse(new File("./WebRoot/xml/t6.xml")); // 得到待删除的结点 Element e = (Element) doc.getElementsByTagName("language").item(0); // 获取结点的父节点,然后删除该子结点 e.getParentNode().removeChild(e); // 使用Transformer将内存中更新过的xml文档写入实际的xml文档中 TransformerFactory tfactory = TransformerFactory.newInstance(); Transformer tf = tfactory.newTransformer(); tf.transform(new DOMSource(doc), new StreamResult(new File( "./WebRoot/xml/t6.xml"))); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号