

多线程、多进程、协程、缓存(memcache、redis)
本节内容:

线程:
a:基本的使用:
创建线程:
1:方法
1 import threading 2 3 def f1(x): 4 print(x) 5 6 7 if __name__=='__main__': 8 t=threading.Thread(target=f1,args=(1,)) 9 t.start()
t=threading.Thread(target=f1,args=(1,))创建线程,target=动作(执行什么,需要是可被调用的函数)args参数元组,要求参数最后加个逗号。
当我们创建一个线程时候,t.start()之后,线程已经准备就绪等待cpu调度。
cpu通过触发threading.Thread类中的run方法来调用我们传入的target 函数。通过debug断点调试可以看到如下:

在看下run方法。

所以我们可以自定义咱们自己的run方法,来被cpu调度。
2:方法
1 import threading 2 3 4 class myclass(threading.Thread): 5 6 def __init__(self,x): 7 super().__init__() 8 self.x=x 9 10 def run(self): 11 print(self.x) 12 13 14 15 16 if __name__=='__main__': 17 obj=myclass(1) 18 obj.start()
通过我们自定义run方法来覆盖父类中的run方法。
并通过start方法 来让cpu调度我们的线程obj。
如上2个方法的本质是相同的。都是cpu的调度run方法实现。
对比1和2方法,1方法是我们常用的。不推荐第二种方法。
b:队列 queue
1 import queue 2 3 q=queue.Queue()##先进先出的队列 4 q.put(11)#往队列里放数据。 5 q.put(12) 6 q.put(13) 7 print(q.qsize())#队列的长度 8 print(q.get())#队列取数据。 9 print(q.qsize()) 10 11 3 12 11 13 2
1 import queue 2 3 q=queue.Queue(2)##先进先出的队列,可以设置队列的长度,默认是没限制。 4 q.put(11)#往队列里放数据。 5 q.put(12) 6 print(q.qsize()) 7 q.put(13,timeout=2)#当队列的数据满了之后,在往里放数据会阻塞,等待队列长度改变。可以设置超时间。超时时间之后,队列的长度没改变,会报错。 8 print(q.qsize())#队列的长度 9 print(q.get())#队列取数据。 10 print(q.qsize()) 11 2 12 Traceback (most recent call last): 13 File "C:/Users/Administrator/PycharmProjects/S12/day11/s3.py", line 7, in <module> 14 q.put(13,timeout=2)#当队列的数据满了之后,在往里放数据会阻塞,等待队列长度改变。可以设置超时间。 15 File "E:\python3.6\lib\queue.py", line 141, in put 16 raise Full 17 queue.Full
也可以设置放数据不阻塞。参数问block=False 默认该参数是True
1 import queue 2 3 q=queue.Queue(2)##先进先出的队列,可以设置队列的长度,默认是没限制。 4 q.put(11)#往队列里放数据。 5 q.put(12) 6 print(q.qsize()) 7 q.put(111,block=False)##设置队列不阻塞。 8 print(q.qsize())#队列的长度
get同样也有这些方法。超时、是否阻塞。
1 import queue 2 3 q=queue.Queue(2)##先进先出的队列,可以设置队列的长度,默认是没限制。 4 q.put(11)#往队列里放数据。 5 q.put(12) 6 print(q.get()) 7 print(q.get())#队列取数据。如果队列为空的时候获取数据的话,会阻塞。和get方法一样也可以设置超时间、是否阻塞。 8 print(q.get(timeout=2)) 9 print(q.qsize()) 10 11 11 12 12 Traceback (most recent call last): 13 File "C:/Users/Administrator/PycharmProjects/S12/day11/s4.py", line 8, in <module> 14 print(q.get(timeout=2)) 15 File "E:\python3.6\lib\queue.py", line 172, in get 16 raise Empty 17 queue.Empty
1 import queue 2 3 q=queue.Queue(2)##先进先出的队列,可以设置队列的长度,默认是没限制。 4 q.put(11)#往队列里放数据。 5 q.put(12) 6 print(q.get()) 7 print(q.get())#队列取数据。如果队列为空的时候获取数据的话,会阻塞。和get方法一样也可以设置超时间、是否阻塞。 8 print(q.get(block=False)) 9 print(q.qsize())
其他方法:join和task_done组合使用。
1 import queue 2 q=queue.Queue(2) 3 q.put(1) 4 q.task_done()# 需要在每次取数据的时候告诉队列,这个数据已经完成了。是每次。这样join就不会阻塞了。 5 q.put(2) 6 q.task_done() 7 q.join()##当队列中有任务的时候,没做处理。该方法会阻塞,知道队列里的任务完成。可以配合task_done方法使用
需要注意:每次取数据需要使用task_done方法来告诉队列这个数据已经完成。

qsize,查看当前队列的长度。
get_nowait()实际上调用get(bliock=Flase)
put_nowait()也是调用put(block=Flase)
full()该方法表示检查当前队列是否满,返回是布尔值。
empty()该方法检查当前队列是否空,返回是布尔值。
1 import queue 2 q=queue.Queue(2)#构造方法中maxsize表示队列最大的长度。 3 q.put(11) 4 q.put(12) 5 print(q.qsize())## 查看当前队列长度。 6 print(q.empty()) 7 print(q.full()) 8 2 9 False 10 True
如上的队列是进程在内存里的队列,在python退出的时候队列也清空。
其他队列:如下队列都是queue的基础上操作的,继承queue这个类(除双向队列)。

先进后出队列:
1 import queue 2 3 q=queue.LifoQueue()##先进后出队列。first in last out 4 q.put(11) 5 q.put(2) 6 q.put(3) 7 print(q.get())
优先级队列,包含2个参数一个数据,一个是权重值。
1 import queue 2 q=queue.PriorityQueue()##权重优先队列,权重值越大,优先级越低。如果权重值一样,取第一个值。 3 q.put((11,5)) 4 q.put((11,3)) 5 q.put((12,3)) 6 q.put((11,4)) 7 print(q.get()) 8 (11, 3)
双向队列:可以在队列的两边进行数据的输入和输出。
1 import queue 2 q=queue.deque()#双向队列,可以在2边进行取数据和放数据。很多方法和列表类似。 3 q.append(11) 4 q.appendleft(12) 5 print(q.pop()) 6 print(q.popleft())
c:消费者和生产者模型:
主要解决了什么?
1:解决程序的阻塞问题。变相提高程序的处理效率和并发。
2:降低程序之间的解耦性。在修改任意一方的程序的时候,减少彼此的影响。
通过什么来实现?
可以通过消息队列,来实现中间的转换过程。
比如一个网站,在客户端同时有大并发的请求时候,可以通过应用程序来获取客户端的请求,并把请求放在消息队列中(这个操作很短,不容易出现阻塞情况。),此时客户端的请求,断开,应用程序把客户端的自动转发到另一个查询页面,这个页面
自动刷新,客户端请求的结果。后端程序在从消息队列中获取客户端的请求,进行处理,并更新数据库信息。当数据库更新成功之后,客户端查询就会显示结果。
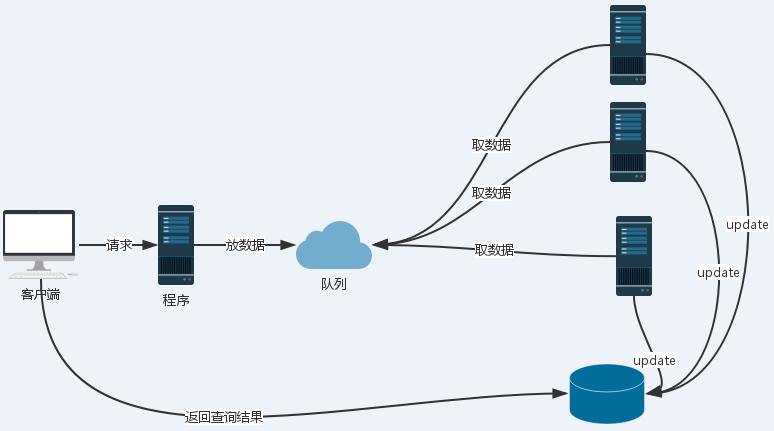
好处:
1:降低了程序之间的耦合。
2:一个web请求,到达服务器之后,有后台程序进行处理。如果处理的时间过长,那么这个进程会被挂起,应用服务器会维护这个进程。如果大并发的请求,那么服务端会挂起较多进程,那么服务器会较多的资源浪费,而服务器也会出现hang死或者无效的请求,
因为一个sokcet维护的等待队列是有限,nginx的最大连接也是有限的。而这个模型很好的解决这个问题,他把客户端请求和后台程序处理请求分开。如果客户端请求过多,消息积压,后端可以提高服务器的数量来提高并发,而且这个后台应用程序不会维护客户端连接,
后台程序直接进行有效的请求处理,然后更新数据库,用户只需要查询数据库来验证自己的请求。
1 import queue 2 import threading 3 import time 4 q=queue.Queue(20) 5 def productor(j): 6 while True: 7 print('the server %s deal request'%j,q.get())#队列获取消息。 8 time.sleep(4) 9 10 def consumer(i): 11 q.put(' client NO:%s request'%i)#往队列中放消息。 12 13 14 for i in range(3):#后台3个程序在处理这个请求。 15 t=threading.Thread(target=productor,args=(i,)) 16 t.start() 17 for j in range(40): 18 t=threading.Thread(target=consumer,args=(j,))##40个客户端请求。 19 t.start() 20 21 22 the server 0 deal request client NO:0 request 23 the server 1 deal request client NO:1 request 24 the server 2 deal request client NO:2 request 25 the server 1 deal request client NO:3 request 26 the server 0 deal request client NO:4 request 27 the server 2 deal request client NO:5 request 28 ......
d:线程锁:
线程是程序运行的最小单位,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流最小单元。一个标准线程是由线程ID,当前指令指针(pc),寄存器集合和堆栈组合,另外线程是进程的一个实体,是被系统独立调度和分派的基本单位。
线程不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个进程的其他线程共享所拥有的全部资源。一个线程可以创建和撤销另一个线程,同一个进程中的多个线程可以并发执行。由于线程之间的互相制约,致使线程在运行中呈现出间断性。
线程也有就绪、阻塞和运行的三种基本状态。就绪状态是指线程具备运行的所有条件,逻辑上可以运行,等待处理。运行状态是指线程占有cpu正在运行,阻塞状态是指线程在等待一个事件(如某个信号量),逻辑上不可执行。每个程序至少有一个线程,称为主线程。
在单个程序中同时运行多个线程完成不同工作,称为多线程。
基于线程和他的同一个进程所属的其他的线程共享资源,所以会出现以下情况:在多个线程共同对同一个数据进行修改的时候,会出现数据的不一致。
1 import threading 2 import time 3 x=10 4 def f1(): 5 6 global x 7 x -= 1 8 time.sleep(2) 9 print(x) 10 11 for i in range(10): 12 t=threading.Thread(target=f1) 13 t.start() 14 15 0 16 0 17 0 18 .......
a:如上所示当多个线程对同一份数据进行修改的话,会出现数据混乱,并不是我们想要的数据。
避免多个线程对同一份数据同一时间进行修改,出现了互斥锁。
互斥锁:当一个线程在对数据进行修改的时候,如果加上互斥锁,只有当前线程执行的“动作”结束之后,下一个线程才可以进行相应的动作。
如下是只允许一个线程加锁和解锁。
1 import threading 2 import time 3 x=10 4 q=threading.RLock() 5 def f1(): 6 7 global x 8 q.acquire()#加锁。递归锁 9 x -= 1 10 time.sleep(2) 11 q.release()#解锁。 12 13 print(x) 14 15 for i in range(10): 16 t=threading.Thread(target=f1) 17 t.start() 18 9 19 8 20 7 21 6 22 5 23 4 24 3 25 2 26 1 27 0
互斥锁有一次性锁和递归锁(可以锁多次)。上面用的是递归锁,可以锁多层。我们一般用递归锁。如下是一次性锁。
1 import threading 2 import time 3 x=10 4 q=threading.Lock()#一次性锁。 5 def f1(l): 6 7 global x 8 l.acquire()#上锁。 9 x -= 1 10 time.sleep(2) 11 l.release()#开锁。 12 13 print(x) 14 15 for i in range(10): 16 t=threading.Thread(target=f1,args=(q,)) 17 t.start()

b:信号量:同一时间允许多个线程执行同一个动作。而不是上面的只允许单个线程同一时间执行同一个动作。
1 import threading 2 import time 3 x=10 4 q=threading.Semaphore(3)# 信号量,同一时间允许多少个线程执行相应的动作。 5 def f1(l,i): 6 7 global x 8 l.acquire()#上锁。 9 x -= 1 10 time.sleep(2) 11 l.release()#开锁。 12 13 print(x,'NO %s thread'%i) 14 15 for i in range(10): 16 t=threading.Thread(target=f1,args=(q,i)) 17 t.start() 18 7 NO 0 thread 19 7 NO 2 thread 20 7 NO 1 thread 21 4 NO 4 thread 22 4 NO 3 thread 23 4 NO 5 thread 24 1 NO 6 thread 25 1 NO 8 thread 26 1 NO 7 thread 27 0 NO 9 thread
c:EVENT(事件):该事件是针对全部线程的动作,不是上面的单个或者多个。类似于红绿灯。红灯都不放行、绿灯都放行。
python线程的事件用于主线程控制其他线程执行,事件主要提供了三个方法:set wait clear。
事件处理机制:实际上python内部维护了一个全局的"flag",如果flag值为Flase(红灯)(默认是Flase),当执行到even.wait()时候,线程会阻塞。反之如果为True(绿灯)时候,event.wait()方法不会阻塞。
event.wait():检查全局flag值。如果是False,阻塞全部线程。反之放行。
event.clear()主动设置成全局变量为False.默认 值是False
event.set()主动设置全局变量为True。
1 import threading 2 import time 3 x=10 4 e=threading.Event()# 事件,同一时间阻塞所有线程或者同一时间放行所有线程。 5 def f1(l,i): 6 7 global x 8 l.wait()#检查全局flag值。 9 x -= 1 10 11 12 print(x,'NO %s thread'%i) 13 14 for i in range(10): 15 t=threading.Thread(target=f1,args=(e,i)) 16 t.start() 17 e.clear()#设置全局标志:flag=Flase 默认值是False。 18 if __name__=='__main__': 19 inp=input(">") 20 if inp=='1': 21 e.set()##将全局标志:flag设置为True
d:Contidition 当满足一定条件时候,放行几个线程。
import threading
con=threading.Condition()#初始化一个Condition实例。
def func(c,i):
print(i)
c.acquire()
c.wait()
print(i+100)
c.release()
for i in range(10):
t=threading.Thread(target=func,args=(con,i))
t.start()
if __name__=="__main__":
while True:
inp=input('>>')
if inp=='q':
break
con.acquire()##固定语法,如果执行notify必须有acquire和release。
con.notify(int(inp))##表示满足inp不等于q的条件,放行几个线程。
con.release()
0
1
2
3
4
5
6
7
8
9
>>1
>>100
2
>>101
102
上面:
con.acquire()
con.notify()
con.release()
为固定用法,表示用户输入为数字的时候,通过notify方法通知程序放行几个线程。
也可以根据函数的返回的布尔值来判断是否放行线程如下,每次只放行一个线程:
1 import threading
2 con=threading.Condition()#初始化一个Condition实例。
3
4 def m():
5 inp=input('>')
6 if inp=='1':
7 return True
8 else:
9 return False
10 def func(c,i):
11 print(i)
12 c.acquire()
13 c.wait_for(m)##wait_for()1:可被调用的方法而且需要返回值是布尔型。如果返回为真放行一个线程。反之不放行。
14 print(i+100)
15 c.release()
16
17
18
19 for i in range(10):
20 t=threading.Thread(target=func,args=(con,i))
21 t.start()
e:计数器,表示超时之后开始执行。
1 import threading
2
3 def func():
4 print(100)
5
6
7 t=threading.Timer(2,func)##2表示多久之后执行,func为可执行函数。
8 t.start()
e:线程池:
1:线程的复用,而不是重新创建一个线程。如果任务过多,重复的创建新的线程,上下文的开销(维护线程的开销)较多,资源浪费。
2:当线程池里的线程取完,下一次任务需要等待线程执行完,在执行。
如下是简单版本的多线程:
1 import threading 2 import queue 3 import time 4 5 class Thread_Poll: 6 q=queue.Queue()##定义队列。 7 def __init__(self,maxsize): 8 self.maxsize=maxsize#定义线程池队列的大小。 9 10 def put_thread(self):#往线程池里放线程类。 11 for i in range(self.maxsize): 12 Thread_Poll.q.put(threading.Thread) 13 14 def get_thread(self):#返回一个线程类。 15 return Thread_Poll.q.get() 16 17 18 def task(i):#执行的任务。 19 print(i) 20 time.sleep(2) 21 Thread_Poll.q.put(threading.Thread)#完成任务,需要补充线程池的线程。 22 23 24 25 if __name__=="__main__": 26 obj=Thread_Poll(5) 27 obj.put_thread() 28 for i in range(30):#执行任务。 29 t=obj.get_thread()(target=task,args=(i,)) 30 t.start()
更新的第二版:
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # Author:Alex Li 4 import queue 5 import threading 6 import contextlib 7 import time 8 9 StopEvent = object()#赋值。当任务等于他的时候,表示任务执行完毕。 10 11 class ThreadPool(object): 12 13 def __init__(self, max_num, max_task_num = None): 14 if max_task_num:#任务数。 15 self.q = queue.Queue(max_task_num)#创建队列,队列的长度为任务数。 16 else: 17 self.q = queue.Queue()#如果没有传入,创建一个没有限制的队列。 18 self.max_num = max_num#线程的最大数。 19 self.cancel = False#取消线程执行 20 self.terminal = False#取消线程执行。 21 self.generate_list = []#保存正在执行任务线程对象的列表。 22 self.free_list = []#保存空余线程的列表。 23 24 def run(self, func, args, callback=None): 25 """ 26 线程池执行一个任务 27 :param func: 任务函数 28 :param args: 任务函数所需参数 29 :param callback: 任务执行失败或成功后执行的回调函数,回调函数有两个参数1、任务函数执行状态;2、任务函数返回值(默认为None,即:不执行回调函数) 30 :return: 如果线程池已经终止,则返回True否则None 31 """ 32 if self.cancel:#如果cancel=True表示任务执行完。 33 return 34 if len(self.free_list) == 0 and len(self.generate_list) < self.max_num:#当没有空闲线程和正在运行的线程数量小于总线程大小。 35 self.generate_thread()#执行创建线程的方法。 36 w = (func, args, callback,)#创建一个元组。func任务函数、args表示任务函数参数。callback任务执行完回调函数(任务执行状态successful还是fail以及任务函数的返回值)。 37 self.q.put(w)#往队列里添加任务。 38 39 def generate_thread(self): 40 """ 41 创建一个线程,并执行相应的call方法。 42 """ 43 t = threading.Thread(target=self.call) 44 t.start() 45 46 def call(self): 47 """ 48 循环去获取任务函数并执行任务函数 49 """ 50 current_thread = threading.currentThread#获取当前的线程。 51 self.generate_list.append(current_thread)#把当前的线程放在列表中。 52 53 event = self.q.get()#获取任务。 54 while event != StopEvent:#任务不为空即:任务不等StopEvent。 55 56 func, arguments, callback = event#赋值。 57 try: 58 result = func(*arguments)#执行任务函数。 59 success = True#执行完,赋值表示执行成功。 60 except Exception as e:#报错,表示任务执行失败。 61 success = False 62 result = None 63 64 if callback is not None:#任务回调函数不为空。 65 try: 66 callback(success, result)#执行回调函数,参数为任务状态以及任务结果。 67 except Exception as e:#执行回调函数报错的情况处理。 68 pass 69 70 with self.worker_state(self.free_list, current_thread): 71 print(self.terminal) 72 if self.terminal: 73 event = StopEvent 74 else: 75 event = self.q.get() 76 else: 77 78 self.generate_list.remove(current_thread) 79 80 def close(self): 81 """ 82 执行完所有的任务后,所有线程停止 83 """ 84 self.cancel = True 85 full_size = len(self.generate_list) 86 while full_size: 87 self.q.put(StopEvent) 88 full_size -= 1 89 90 def terminate(self): 91 """ 92 无论是否还有任务,终止线程 93 """ 94 self.terminal = True 95 96 while self.generate_list: 97 self.q.put(StopEvent) 98 99 self.q.empty() 100 101 @contextlib.contextmanager 102 def worker_state(self, state_list, worker_thread): 103 """ 104 用于记录线程中正在等待的线程数 105 """ 106 state_list.append(worker_thread) 107 try: 108 yield 109 finally: 110 state_list.remove(worker_thread) 111 112 pool = ThreadPool(5) 113 114 def callback(status, result): 115 # status, execute action status 116 # result, execute action return value 117 pass 118 119 def action(i): 120 print(i) 121 122 for i in range(300): 123 ret = pool.run(action, (i,), callback) 124 125 # time.sleep(5) 126 # print(len(pool.generate_list), len(pool.free_list)) 127 # print(len(pool.generate_list), len(pool.free_list))
更新第三版:
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 # Author:evil_liu 4 import queue 5 import threading 6 import contextlib 7 import time 8 9 StopEvent = object()#赋值。当任务等于他的时候,表示任务执行完毕。 10 RES_LIST=[] 11 class ThreadPool(): 12 count=0 13 lock=threading.RLock()#线程锁 14 def __init__(self, max_num, max_task_num): 15 self.max_task_num=max_task_num# 任务计数。 16 if max_task_num:#任务数。 17 self.q = queue.Queue(max_task_num)#创建队列,队列的长度为任务数。 18 else: 19 self.q = queue.Queue()#如果没有传入,创建一个没有限制的队列。 20 self.req=queue.Queue(max_task_num)##结果队列。 21 self.max_num = max_num#线程的最大数。 22 self.cancel = False#取消线程执行 23 self.terminal = False#取消线程执行。 24 self.generate_list = []#保存正在执行任务线程对象的列表。 25 self.free_list = []#保存空余线程的列表。 26 27 def run(self, func, args, callback=None): 28 """ 29 线程池执行一个任务 30 :param func: 任务函数 31 :param args: 任务函数所需参数 32 :param callback: 任务执行失败或成功后执行的回调函数,回调函数有两个参数1、任务函数执行状态;2、任务函数返回值(默认为None,即:不执行回调函数) 33 :return: 如果线程池已经终止,则返回True否则None 34 """ 35 if self.cancel:#如果cancel=True表示任务执行完。 36 return 37 if len(self.generate_list) < self.max_num:#当没有空闲线程和正在运行的线程数量小于总线程大小。 38 self.generate_thread()#执行创建线程的方法。 39 w = (func, args, callback,)#创建一个元组。func任务函数、args表示任务函数参数。callback任务执行完回调函数(任务执行状态successful还是fail以及任务函数的返回值)。 40 self.q.put(w)#往队列里添加任务。 41 42 def generate_thread(self): 43 """ 44 创建一个线程,并执行相应的call方法。 45 """ 46 t = threading.Thread(target=self.call) 47 t.start() 48 49 def call(self): 50 """ 51 循环去获取任务函数并执行任务函数 52 """ 53 current_thread = threading.currentThread#获取当前的线程。 54 self.generate_list.append(current_thread)#把当前的线程放在列表中。 55 56 event = self.q.get()#获取任务。 57 while event != StopEvent:#任务不为空即:任务不等StopEvent。 58 59 func, arguments, callback = event#赋值。 60 # if ThreadPool.count <= self.max_task_num: 61 try: 62 result = func(*arguments)#执行任务函数。 63 success = True#执行完,赋值表示执行成功。 64 except Exception as e:#报错,表示任务执行失败。 65 success = False 66 result = None 67 if callback is not None:#任务回调函数不为空。 68 try: 69 callback(success, result)#执行回调函数,参数为任务状态以及任务结果。 70 except Exception as e:#执行回调函数报错的情况处理。 71 pass 72 73 try: 74 event = self.q.get(timeout=2)#获取数据超时。超时之后表示任务执行完成。 75 except queue.Empty as e: 76 self.generate_list.remove(threading.currentThread)##释放线程 77 break 78 def close(self): 79 """ 80 执行完所有的任务后, 81 """ 82 self.cancel = True 83 full_size = self.max_num 84 while full_size: 85 self.q.put(StopEvent) 86 full_size -= 1 87 88 pool = ThreadPool(5,10) 89 # lock_1=threading.RLock() 90 def callback(status, result): 91 pass 92 93 def action(i): 94 print("Now mssion is %s"%i) 95 time.sleep(2) 96 return True 97 98 for i in range(10): 99 ret = pool.run(action, (i,), callback) 100 time.sleep(10) 101 print(len(pool.generate_list))
终极版:
1 #!/bin/env python 2 #author:evil_liu 3 #date:2016-7-21 4 #description: thread pool 5 6 import threading 7 import time 8 import queue 9 10 class Thread_Poll: 11 ''' 12 功能:该类主要实现多线程,以及线程复用。 13 ''' 14 def __init__(self,task_num,max_size): 15 ''' 16 功能:该函数是初始化线程池对象。 17 :param task_num: 任务数量。 18 :param max_size: 线程数量。 19 :return:无。 20 ''' 21 self.task_num=task_num 22 self.max_size=max_size 23 self.q=queue.Queue(task_num)#设置任务队列的。 24 self.thread_list=[] 25 self.res_q=queue.Queue()#设置结果队列。 26 27 def run(self,func,i,call_back=None): 28 ''' 29 功能:该函数是线程池运行主函数。 30 :param func: 传入任务主函数。 31 :param *args: 任务函数参数,需要是元组形式。 32 :param call_back: 回调函数。 33 :return: 无。 34 ''' 35 if len(self.thread_list)<self.max_size:#如果目前线程数小于我们定义的线程的个数,进行创建。 36 self.creat_thread() 37 misson=(func,i,call_back)#往任务队列放任务。 38 self.q.put(misson) 39 40 def creat_thread(self): 41 ''' 42 功能:该函数主要是创建线程,并调用call方法。 43 :return: 无。 44 ''' 45 t=threading.Thread(target=self.call) 46 t.start() 47 48 def call(self): 49 ''' 50 功能:该函数是线程循环执行任务函数。 51 :return: 无。 52 ''' 53 cur_thread=threading.currentThread 54 self.thread_list.append(cur_thread) 55 event=self.q.get() 56 while True: 57 func,args,cal_ba=event#获取任务函数。 58 try: 59 res=func(*args)#执行任务函数。注意参数形式是元组形式。 60 flag="OK" 61 except Exception as e: 62 print(e) 63 res=False 64 flag="fail" 65 # print(flag) 66 self.res(res,flag)#调用回调函数,将执行结果返回到队列中。 67 try: 68 event=self.q.get(timeout=2)#如果任务队列为空,获取任务超时2s超过2s线程停止执行任务,并退出。 69 except Exception: 70 self.thread_list.remove(cur_thread) 71 break 72 def res(self,res,status): 73 ''' 74 功能:该方法主要是将执行结果方法队列中。 75 :param res: 任务函数的执行结果。 76 :param status: 执行任务函数的结果,成功还是失败。 77 :return: 无。 78 ''' 79 da_res=(res,status) 80 self.res_q.put(da_res) 81 82 def task(x,y): 83 ''' 84 功能:该函数主要需要执行函数。 85 :param x: 参数。 86 :return: 返回值1,表示执行成功。 87 ''' 88 print(x) 89 return x+y 90 def wri_fil(x): 91 ''' 92 功能:该函数主要讲结果队列中的结果写入文件中。 93 :param x: 任务长度。 94 :return: 无。 95 ''' 96 while True:#将执行结果,从队列中获取结果并将结果写入文件中。 97 time.sleep(1) 98 if pool.res_q.qsize()==x:#当队列当前的长度等于任务执行次数,表示任务执行完成。 99 with open('1.txt','w') as f1: 100 for i in range(pool.res_q.qsize()): 101 try: 102 data=pool.res_q.get(timeout=2) 103 f1.write('mission result:%s,status:%s\n'%data) 104 except Exception: 105 break 106 break 107 else: 108 continue 109 if __name__ == '__main__': 110 pool=Thread_Poll(10,5)#初始化线程池对象。 111 for i in range(10):#循环任务。 112 pool.run(task,(1,2)) 113 wri_fil(10)
以上版本在window pycharm运行有时候出现程序hang住无法结束。但是linux测试没有这个问题。
f:进程:
执行脚本的时候,别在window下创建多进程,因为python是调用os.fork创建,而window不支持,想执行需要用:if __name__=="__main__".
a:多进程的创建:
1 import multiprocessing 2 3 def test(x): 4 print(x) 5 6 7 if __name__ == '__main__': 8 p=multiprocessing.Process(target=test,args=(1,)) 9 p.start()
1 import multiprocessing 2 import time 3 def test(x): 4 time.sleep(9) 5 print(x) 6 7 8 if __name__ == '__main__': 9 for i in range(2): 10 p=multiprocessing.Process(target=test,args=(i,)) 11 p.start() 12 p.join(6)#这个参数的意思是:进程在这等待6秒,6秒之后就往下执行代码,后面的代码执行完,不终止。等待子进程执行完。不加该参数默认会等待进程执行完。 13 print('ok')
daemon=True表示进程不等待子进程执行完。结束程序。
1 import multiprocessing 2 import time 3 def test(x): 4 time.sleep(9) 5 print(x) 6 7 8 if __name__ == '__main__': 9 for i in range(2): 10 p=multiprocessing.Process(target=test,args=(i,)) 11 p.daemon = True##注意位置,在start之前。 12 p.start() 13 print('ok')
b:进程之间的数据共享:
进程之间数据不共享,单独维护一个块系统资源(内存空间.....)来维护自己的数据资源。
1 import multiprocessing 2 LI=[] 3 def test(x,li): 4 li.append(x) 5 print(li) 6 7 8 if __name__ == '__main__': 9 for i in range(2): 10 p=multiprocessing.Process(target=test,args=(i,LI)) 11 p.start() 12 [0] 13 [1]
数据共享可以用如下:Queue方法可以构造特殊的数据,该方法包含put、get等。
1 import multiprocessing 2 from multiprocessing.queues import Queue 3 li=Queue(20,ctx=multiprocessing) 4 def test(y,x): 5 y.put(x) 6 print(y.qsize()) 7 8 9 if __name__ == '__main__': 10 for i in range(4): 11 p=multiprocessing.Process(target=test,args=(li,i)) 12 p.start() 13 1 14 2 15 3 16 4
c:Array() 数组的方法。来构建进程共享数据:不常用。
1)数组需要指定类型。
1 'c': ctypes.c_char, 'u': ctypes.c_wchar, 2 'b': ctypes.c_byte, 'B': ctypes.c_ubyte, 3 'h': ctypes.c_short, 'H': ctypes.c_ushort, 4 'i': ctypes.c_int, 'I': ctypes.c_uint, 5 'l': ctypes.c_long, 'L': ctypes.c_ulong, 6 'f': ctypes.c_float, 'd': ctypes.c_double 7 8 类型对应表
2)数组需要指定长度。
1 import multiprocessing 2 3 4 def test(x,y): 5 x[y]=y+100 6 for i in x: 7 print(i) 8 print("------------------") 9 10 li=multiprocessing.Array('i',4) 11 if __name__ == '__main__': 12 for i in range(4): 13 p=multiprocessing.Process(target=test,args=(li,i)) 14 p.start()
在大多数语言中:数组类型的数据,在内存中是连续的一块内存,需要指定数据的大小、类型(类型的不同的占有的位置大小也不一样,需要提前指定。)python 的列表,具有可扩展、伸缩。在内存中的数据块地址是不连续的。是因为在内存中,内存数据块是通过链表的形式进行查看。
就是说一个数据记录上个数据的内存地址和下个数据的内存地址。这样的方式进行查找。
常用的方式:用multiprocessing模块的Manger()方法,使用字典形式的进行数据更改,没有数据类型的限制。
1 import multiprocessing 2 3 4 def test(x,y): 5 x[y]=y+100 6 for i in x.items(): 7 print(i) 8 print("------------------") 9 obj=multiprocessing.Manager() 10 t=obj.dict() 11 # li=multiprocessing.Array('i',4) 12 if __name__ == '__main__': 13 for i in range(4): 14 p=multiprocessing.Process(target=test,args=(t,i)) 15 p.start() 16 p.join()##注意:需要加join等待子进程执行完。因为修改的是主进程的数据,主进程需要和子进程进行socket链接。如果不等子进程执行完,就执行子进程。会导致主进城和子进程通讯出现问题。 17 (0, 100) 18 ------------------ 19 (0, 100) 20 (1, 101) 21 ------------------ 22 (0, 100) 23 (1, 101) 24 (2, 102) 25 ------------------ 26 (0, 100) 27 (1, 101) 28 (2, 102) 29 (3, 103) 30 ------------------
c:进程锁。
当进程的数据进行共享的时候,多个进程操作共享数据之后,获得数据的结果会出现混乱。
1 import multiprocessing 2 import time 3 LOCK=multiprocessing.Lock() 4 def test(x,l): 5 x[0]-=1 6 time.sleep(3) 7 print(x[0]) 8 obj=multiprocessing.Manager() 9 t=obj.dict() 10 if __name__ == '__main__': 11 t[0]=4 12 for i in range(4): 13 p=multiprocessing.Process(target=test,args=(t,LOCK)) 14 p.start() 15 p.join()#####################注意join位置。 16 0 17 0 18 0 19 0
1 import multiprocessing 2 import time 3 LOCK=multiprocessing.Lock() 4 def test(x,l): 5 x[0]-=1 6 time.sleep(3) 7 print(x[0]) 8 obj=multiprocessing.Manager() 9 t=obj.dict() 10 if __name__ == '__main__': 11 t[0]=4 12 for i in range(4): 13 p=multiprocessing.Process(target=test,args=(t,LOCK)) 14 p.start() 15 p.join()####################这个位置就是逐个执行。 16 3 17 2 18 1
加锁:同样进程也有进程普通锁、递归锁、event、condition等。和线程使用的方式类同!
1 import multiprocessing 2 import time 3 LOCK=multiprocessing.Lock() 4 def test(x,l): 5 x[0]-=1 6 time.sleep(3) 7 print(x[0]) 8 obj=multiprocessing.Manager() 9 t=obj.dict() 10 if __name__ == '__main__': 11 t[0]=4 12 for i in range(4): 13 p=multiprocessing.Process(target=test,args=(t,LOCK)) 14 p.start() 15 p.join() 16 3 17 2 18 1 19 0
1 import multiprocessing 2 import time 3 LOCK=multiprocessing.Semaphore(2)##信号量。 4 5 def test(x,l): 6 LOCK.acquire() 7 x[0]+=100 8 time.sleep(2) 9 l.release() 10 print(x[0]) 11 obj=multiprocessing.Manager() 12 t=obj.dict() 13 t[0]=4 14 if __name__ == '__main__': 15 for i in range(4): 16 p=multiprocessing.Process(target=test,args=(t,LOCK)) 17 p.start() 18 p.join() 19 104 20 104 21 304 22 304
event:
1 import multiprocessing 2 e=multiprocessing.Event() 3 4 def test(x,l): 5 x[0]+=100 6 l.wait() 7 print(x[0]) 8 obj=multiprocessing.Manager() 9 t=obj.dict() 10 t[0]=4 11 for i in range(4): 12 p=multiprocessing.Process(target=test,args=(t,e)) 13 p.start() 14 if __name__ == '__main__': 15 inp=input(">") 16 if inp=='1': 17 e.set() 18 >1 19 404 20 404 21 404 22 404
conditon()
1 import multiprocessing 2 e=multiprocessing.Condition() 3 4 def test(x,l): 5 l.acquire() 6 l.wait() 7 x[0]+=100 8 print(x[0]) 9 l.release() 10 obj=multiprocessing.Manager() 11 t=obj.dict() 12 t[0]=4 13 for i in range(4): 14 p=multiprocessing.Process(target=test,args=(t,e)) 15 p.start() 16 if __name__ == '__main__': 17 inp=input(">") 18 while True: 19 if inp!='q': 20 e.acquire() 21 e.notify(int(inp)) 22 e.release()
d:进程池。
进程multiprocessing给我们提供了相应的方法。分别为:appy方法、app_async方法。
appy方法:并不是并发执行任务,而是当前进程执行完,才执行下个,串行执行。
1 import multiprocessing 2 import time 3 4 5 def task(args): 6 time.sleep(2) 7 print(args) 8 9 10 pool=multiprocessing.Pool(5)##初始化5个进程。 11 if __name__ == '__main__': 12 for i in range(10): 13 pool.apply(func=task,args=(i,))#从进程调用一个进程执行任务。 14 print("_____end_____") 15 0 16 1 17 2 18 3 19 4 20 5 21 6 22 7 23 8 24 9 25 _____end_____
app_async()异步执行(从队列获取任务,执行任务。),这个比较常用。可以看做是并发执行任务。
1 import multiprocessing 2 import time 3 4 5 def task(args): 6 time.sleep(1) 7 print(args) 8 9 10 pool=multiprocessing.Pool(5)##初始化5个进程。 11 if __name__ == '__main__': 12 for i in range(10): 13 pool.apply_async(func=task,args=(i,))#从进程调用一个进程执行任务。 14 pool.close()##执行close或者terminal方法,要不然会报断言错误。terminnal方法表示任务立即终止。 15 pool.join()#主进程等待子进程执行完任务。 16 print("_____end_____")
协程:
原理:多线程、多进程是系统执行的。而协程是程序员”操纵“。将一个线程分解成多个“微线程”,执行不同的任务。比如说:多次URL请求。每次URL请求耗时3S。如果用多线程执行的话,会出现资源浪费(维护、等待3s),可以用协程,我们可以让线程循环执行url请求,而不是在等待执行结果。也就说。可以在等待的同时执行其他的任务。

通过gevnet和greenlet方法执行。genvent是对greenlet的封装,底层还是调用greenlet。
安装:pip install gevent(安装这个自动安装greenlet)
1 from greenlet import greenlet 2 3 4 def test1(): 5 print(12) 6 gr2.switch() 7 print(34) 8 gr2.switch() 9 10 11 def test2(): 12 print(56) 13 gr1.switch() 14 print(78) 15 16 gr1 = greenlet(test1) 17 gr2 = greenlet(test2) 18 gr1.switch()
如上代码:当执行到gr1.switch()的时候,会执行test1函数,执行到test1函数到gr2.switch()的时候执行test2, 遵循这个规则依次执行下去。也就是说通过greenlet来控制线程的执行流。
1 import gevent 2 3 def foo(): 4 print('Running in foo') 5 gevent.sleep(0)#执行切换。 6 print('Explicit context switch to foo again') 7 8 def bar(): 9 print('Explicit context to bar') 10 gevent.sleep(0)#执行切换。 11 print('Implicit context switch back to bar') 12 13 gevent.joinall([ 14 gevent.spawn(foo), 15 gevent.spawn(bar), 16 ])##创建协程。 17 Running in foo 18 Explicit context to bar 19 Explicit context switch to foo again 20 Implicit context switch back to bar
IO操作:执行http请求。
1 from gevent import monkey; monkey.patch_all() 2 import gevent 3 import requests 4 5 def f(url): 6 print('GET: %s' % url) 7 resp = requests.get(url) 8 data = resp.text 9 print('%d bytes received from %s.' % (len(data), url)) 10 11 gevent.joinall([ 12 gevent.spawn(f, 'https://www.python.org/'), 13 gevent.spawn(f, 'https://www.yahoo.com/'), 14 gevent.spawn(f, 'https://github.com/'), 15 ])#创建协程、循环执行这个url 16 GET: https://www.python.org/ 17 GET: https://www.yahoo.com/ 18 GET: https://github.com/ 19 47394 bytes received from https://www.python.org/. 20 25528 bytes received from https://github.com/. 21 447316 bytes received from https://www.yahoo.com/.
monkey.patch_all()
底层封装socket,具有可以让线程可以一边执行url请求,一边可以收到url请求的结果。
应用场景:在python爬虫框架:scrapy就是用协程(gevent)来实现的,比较高效。
url存活检测(上线之后检测url的存活情况)。
一旦涉及到IO操作,比如http请求,gevent执行效率很高。
缓存:
本质:python通过socket连接服务端(缓存端)通过端口,建立连接 ,在服务端执行相应的命令。
安装memcache:
1:
1 wget http://memcached.org/latest 2 yum install -y libevent-devel.x86_64#64位操作系统。 3 ./configure 4 make && make install
虚拟机用的是网易的源。yum配置文件:
1 [base_server] 2 name=base_server 3 baseurl=http://mirrors.163.com/centos/6.8/os/x86_64/ 4 enabled=1 5 gpgcheck=0
启动:
memcached -d -m 10 -u root -p 11211 -c 256 -P /tmp/memcached.pid
参数说明:
1 参数说明: 2 -d 是启动一个守护进程 3 -m 是分配给Memcache使用的内存数量,单位是MB 4 -u 是运行Memcache的用户 5 -l 是监听的服务器IP地址 6 -p 是设置Memcache监听的端口,最好是1024以上的端口 7 -c 选项是最大运行的并发连接数,默认是1024,按照你服务器的负载量来设定 8 -P 是设置保存Memcache的pid文件
memcache处理的数据类型:
a)key value形式:
1 #!/usr/bin/env python 2 #-*-coding:utf-8-*- 3 # author:liumeide 4 import memcache 5 6 mc = memcache.Client(['192.168.1.104:11211'], debug=True) 7 mc.set("OK", "evil")#设置键值对。 8 ret = mc.get('OK')#获取键值对。 9 print(ret) 10 evil
debug=True:表示运行过程中如果出现错误,显示错误信息。
b)支持集群操作:
python-memcached模块原生支持集群操作,其原理是在内存维护一个主机列表,且集群中主机的权重值和主机在列表中重复出现的次数成正比
1 主机 权重 2 10.10.1.1 3 3 10.10.1.2 2 4 10.10.1.3 1 5 6 那么在内存中主机列表为: 7 host_list = ["10.10.1.1", "10.10.1.2", "10.10.1.2", "10.10.1.3", ]
如果用户根据如果要在内存中创建一个键值对(如:k1 = "v1"),那么要执行一下步骤:
- 根据算法将 k1 转换成一个数字
- 将数字和主机列表长度求余数,得到一个值 N( 0 <= N < 列表长度 )
- 在主机列表中根据 第2步得到的值为索引获取主机,例如:host_list[N]
- 连接 将第3步中获取的主机,将 k1 = "v1" 放置在该服务器的内存中

代码实现如下:
1 mc = memcache.Client([('10.10.10.1:12000', 1), ('10.10.1.2:12000', 2), ('10.10.1.3:12000', 1)], debug=True) 2 3 mc.set('key1', 'value1')
c) add 添加一条键值对,如果有报错:MemCached: while expecting 'STORED', got unexpected response 'NOT_STORED'
1 mc = memcache.Client(['192.168.1.104:11211'], debug=True) 2 mc.add("ok", "tom")#添加键值对。 3 ret = mc.get('ok')#获取键值对。 4 print(ret) 5 tom
d)replace修改某个键值对。如果不存在报异常:MemCached: while expecting 'STORED', got unexpected response 'NOT_STORED'
1 import memcache 2 3 mc = memcache.Client(['192.168.1.104:11211'], debug=True) 4 mc.replace("ok", "come")#添加键值对。 5 ret = mc.get('ok')#获取键值对。 6 print(ret) 7 come
e)set修改键值对,如果不存在话创建,存在的话进行修改,这个一对一。set_multi 是对多个键值对进行修改。注意多个时候,里面放的是字典key:value。
1 import memcache 2 3 mc = memcache.Client(['192.168.1.104:11211'], debug=True) 4 mc.set("11", "come")#如果存在,修改,不存在创建。 5 mc.set_multi({"ok": "bye","cc":9})#如果存在,修改,不存在创建。 6 ret = mc.get('ok')#获取键值对。 7 ret1 = mc.get('11')#获取键值对。 8 print(ret,ret1) 9 bye come
f) delet delet_multi删除键值对,删除多个键值对。需要注意删除里面是key值而且是列表。
1 import memcache 2 3 mc = memcache.Client(['192.168.1.104:11211'], debug=True) 4 mc.delete("11")#如果存在,修改,不存在创建。 5 mc.delete_multi(["ok","cc"])#如果存在,修改,不存在创建
g) get 和get_multi获取键值对、多个键值对。
import memcache mc = memcache.Client(['192.168.1.104:11211'], debug=True) mc.set("11", "come")#如果存在,修改,不存在创建。 mc.set_multi({"ok": "bye","cc":9})#如果存在,修改,不存在创建。。 ret = mc.get('ok')#获取键值对。 ret1 = mc.get_multi(['11','ok'])#获取多个键值对。 print(ret,ret1) bye {'11': 'come', 'ok': 'bye'}
h)append 和 prepend,append在修改指定的key值,在该值的后面追加内容,prepend则相反。
1 mc.append("11",22) 2 ret=mc.get("11") 3 print(ret) 4 come22
1 mc.prepend("11",22) 2 ret=mc.get("11") 3 print(ret) 4 22come22
i)decr和incr 将memcache中的一个值减少(默认是1)或者增加
1 ret=mc.get("cc") 2 mc.decr("cc") 3 ret1=mc.get("cc") 4 print(ret,ret1) 5 8 7
1 ret=mc.get("cc") 2 mc.incr("cc",2) 3 ret1=mc.get("cc") 4 print(ret,ret1) 5 7 9
j)cas和gets
比如说:我们在淘宝进行抢购商品的时候,没抢购一次,相应的存货应该自减,但是如果在相同时间内程序获取相同的存货数据,修改提交。在memcache中,会出现数据的不一致。
这样导致数据的混乱,cas和gets就是解决这个问题。类似线程的互斥锁的作用,memcache内部:每当程序来获取数据的时候,返回当前一个数字和对应的键值,当用户提交修改的时候。
memcache会把当前的数字和程序提交的数字进行比对,如果相等,说明这段时间内没有程序进行修改,如果不相等,提交失败。修改不了。
1 v=mc.gets("cc") 2 time.sleep(20) 3 #在gets和cas之间如果有提交数据,在下面的cas不成功。我测试没出现异常?也正常修改。。。。 4 mc.cas("cc",999)
安装redis
wget http://download.redis.io/releases/redis-3.0.6.tar.gz tar xvzf redis-3.0.6.tar.gz cd redis-3.0.6 make PREFIX=/export/server/redis install
启动:
1 nohup /export/server/redis/bin/redis-server &
安装API:
1 pip.exe install redis
redis针对数据类型:
1:字符串string.
2:hash 操作。
3:列表操作。
4:集合操作。
5:排序操作,比如说:([(11,1),(12,2)])根据后面第二值进行操作。
6:管道
7:发布订阅
a)操作:
添加值:
1 import redis 2 3 rc=redis.Redis(host="192.168.1.104",port=6379) 4 rc.set("test","ok") 5 v=rc.get("test") 6 print(str(v,encoding="utf-8")) 7 ok
注意:返回的结果是字节!!!!
b)连接方式:连接池
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池
1 import redis 2 3 pool = redis.ConnectionPool(host='192.168.1.104', port=6379) 4 r = redis.Redis(connection_pool=pool) 5 r.set('ok', '11') 6 print(str(r.get('ok'),encoding="utf-8")) 7 11
c)操作:
字符串:redis中。字符串是按照一个name对应一个value来存储。

set(name, value, ex=None, px=None, nx=False, xx=False)
1 在Redis中设置值,默认,不存在则创建,存在则修改 2 参数: 3 ex,过期时间(秒) 4 px,过期时间(毫秒) 5 nx,如果设置为True,则只有name不存在时,当前set操作才执行 6 xx,如果设置为True,则只有name存在时,岗前set操作才执行
设置过期时间:
1 import redis 2 3 pool = redis.ConnectionPool(host='192.168.1.104', port=6379) 4 r = redis.Redis(connection_pool=pool) 5 r.setex('ok', '11',2) 6 print(str(r.get('ok'),encoding="utf-8")) 7 11
mset(*args, **kwargs) 批量设置
1 批量设置值 2 如: 3 mset(k1='v1', k2='v2') 4 或 5 mget({'k1': 'v1', 'k2': 'v2'})
1 import redis 2 3 pool = redis.ConnectionPool(host='192.168.1.104', port=6379) 4 r = redis.Redis(connection_pool=pool) 5 r.mset(a="2",b="4") 6 print(str(r.get("a"),encoding="utf-8"))
mget(keys, *args)批量获取值
1 批量获取 2 如: 3 mget('ylr', 'xi') 4 或 5 r.mget(['ylr', 'x'])
append(key, value)
1 # 在redis name对应的值后面追加内容 2 3 # 参数: 4 key, redis的name 5 value, 要追加的字符串
incrbyfloat(self, name, amount=1.0)
1 # 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 2 3 # 参数: 4 # name,Redis的name 5 # amount,自增数(浮点型)
decr(self, name, amount=1)
1 # 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 2 3 # 参数: 4 # name,Redis的name 5 # amount,自减数(整数)
Hash操作:
存储:如下图:

hset(name, key, value)
1 # name对应的hash中设置一个键值对(不存在,则创建;否则,修改) 2 3 # 参数: 4 # name,redis的name 5 # key,name对应的hash中的key 6 # value,name对应的hash中的value 7 8 # 注: 9 # hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name, mapping)
1 # 在name对应的hash中批量设置键值对 2 3 # 参数: 4 # name,redis的name 5 # mapping,字典,如:{'k1':'v1', 'k2': 'v2'} 6 7 # 如: 8 # r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
1 # 在name对应的hash中获取根据key获取value
hmget(name, keys, *args)
1 # 在name对应的hash中获取多个key的值 2 3 # 参数: 4 # name,reids对应的name 5 # keys,要获取key集合,如:['k1', 'k2', 'k3'] 6 # *args,要获取的key,如:k1,k2,k3 7 8 # 如: 9 # r.mget('xx', ['k1', 'k2']) 10 # 或 11 # print r.hmget('xx', 'k1', 'k2')
List操作:

lpush(name,values)
1 # 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 2 3 # 如: 4 # r.lpush('oo', 11,22,33) 5 # 保存顺序为: 33,22,11 6 7 # 扩展: 8 # rpush(name, values) 表示从右向左操作
1 import redis 2 3 pool = redis.ConnectionPool(host='192.168.1.104', port=6379) 4 r = redis.Redis(connection_pool=pool) 5 r.lpush("oo",[1,2,3])
lpushx(name,value)
1 # 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边 2 3 # 更多: 4 # rpushx(name, value) 表示从右向左操作
1 import redis 2 3 pool = redis.ConnectionPool(host='192.168.1.104', port=6379) 4 r = redis.Redis(connection_pool=pool) 5 # r.lpush("oo",[1,2,3]) 6 r.lpush("oo",4)
llen(name)
1 # name对应的list元素的个数
1 import redis 2 3 pool = redis.ConnectionPool(host='192.168.1.104', port=6379) 4 r = redis.Redis(connection_pool=pool) 5 r.lpushx("oo",5) 6 print(r.llen("oo")) 7 4
linsert(name, where, refvalue, value))
1 # 在name对应的列表的某一个值前或后插入一个新值 2 3 # 参数: 4 # name,redis的name 5 # where,BEFORE或AFTER 6 # refvalue,标杆值,即:在它前后插入数据 7 # value,要插入的数据
r.lset(name, index, value)
1 # 对name对应的list中的某一个索引位置重新赋值 2 3 # 参数: 4 # name,redis的name 5 # index,list的索引位置 6 # value,要设置的值
r.lrem(name, value, num)
1 # 在name对应的list中删除指定的值 2 3 # 参数: 4 # name,redis的name 5 # value,要删除的值 6 # num, num=0,删除列表中所有的指定值; 7 # num=2,从前到后,删除2个; 8 # num=-2,从后向前,删除2个
1 import redis 2 3 pool = redis.ConnectionPool(host='192.168.1.104', port=6379) 4 r = redis.Redis(connection_pool=pool) 5 r.lrem("oo",5,-1) 6 print(r.llen("oo")) 7 3
常用操作:
delete(*names):根据删除redis中的任意数据类型
exists(name):检测redis的name是否存在
keys(pattern='*'):
1 # 根据模型获取redis的name 2 3 # 更多: 4 # KEYS * 匹配数据库中所有 key 。 5 # KEYS h?llo 匹配 hello , hallo 和 hxllo 等。 6 # KEYS h*llo 匹配 hllo 和 heeeeello 等。 7 # KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name ,time):为某个redis的某个name设置超时时间
rename(src, dst): 对redis的name重命名为
move(name, db)): 将redis的某个值移动到指定的db下
randomkey():随机获取一个redis的name(不删除)
type(name): 获取name对应值的类型
scan(cursor=0, match=None, count=None)
scan_iter(match=None, count=None)
同字符串操作,用于增量迭代获取key
c:管道:
如果在redis操作中,执行多个命令的时候可以用pipline实现一次请求指定多个命令,并且默认情况下一次pipline 是原子性操作。
1 import redis 2 3 pool = redis.ConnectionPool(host='192.168.1.104', port=6379) 4 5 r = redis.Redis(connection_pool=pool) 6 7 pipe = r.pipeline(transaction=True) 8 9 r.set('test', 'ok') 10 r.set('test1', 'cc') 11 print(r.get("test")) 12 print(r.get("test1")) 13 14 pipe.execute() 15 b'ok' 16 b'cc'
d:发布订阅:

小样:
#!/usr/bin/env python # -*- coding:utf-8 -*- import redis class RedisHelper: def __init__(self): self.__conn = redis.Redis(host='10.211.55.4') self.chan_sub = 'fm104.5' self.chan_pub = 'fm104.5' def public(self, msg): self.__conn.publish(self.chan_pub, msg) return True def subscribe(self): pub = self.__conn.pubsub() pub.subscribe(self.chan_sub) pub.parse_response() return pub
订阅者:
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 from monitor.RedisHelper import RedisHelper 5 6 obj = RedisHelper() 7 redis_sub = obj.subscribe() 8 9 while True: 10 msg= redis_sub.parse_response() 11 print msg
发布者:
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 4 from monitor.RedisHelper import RedisHelper 5 6 obj = RedisHelper() 7 obj.public('hello')
更多redis和memcache 操作:http://www.cnblogs.com/wupeiqi/articles/5132791.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号