Cilium Native Routing with eBPF 模式
Cilium Native Routing with eBPF 模式
一、环境信息
| 主机 | IP |
|---|---|
| ubuntu | 172.16.94.141 |
| 软件 | 版本 |
|---|---|
| docker | 26.1.4 |
| helm | v3.15.0-rc.2 |
| kind | 0.18.0 |
| kubernetes | 1.23.4 |
| ubuntu os | Ubuntu 20.04.6 LTS |
| kernel | 5.11.5 内核升级文档 |
二、安装服务
kind 配置文件信息
root@kind:~# cat install.sh
#!/bin/bash
date
set -v
# 1.prep noCNI env
cat <<EOF | kind create cluster --name=cilium-kubeproxy-replacement --image=kindest/node:v1.23.4 --config=-
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
networking:
# kind 默认使用 rancher cni,cni 我们需要自己创建
disableDefaultCNI: true
# kind 安装 k8s 集群需要禁用 kube-proxy 安装,是 cilium 代替 kube-proxy 功能
kubeProxyMode: "none"
nodes:
- role: control-plane
- role: worker
- role: worker
containerdConfigPatches:
- |-
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."harbor.evescn.com"]
endpoint = ["https://harbor.evescn.com"]
EOF
# 2.remove taints
controller_node_ip=`kubectl get node -o wide --no-headers | grep -E "control-plane|bpf1" | awk -F " " '{print $6}'`
kubectl taint nodes $(kubectl get nodes -o name | grep control-plane) node-role.kubernetes.io/master:NoSchedule-
kubectl get nodes -o wide
# 3.install cni
helm repo add cilium https://helm.cilium.io > /dev/null 2>&1
helm repo update > /dev/null 2>&1
# Direct Routing Options(--set kubeProxyReplacement=strict --set tunnel=disabled --set autoDirectNodeRoutes=true --set ipv4NativeRoutingCIDR="10.0.0.0/8")
# Host Routing[EBPF](--set bpf.masquerade=true)
helm install cilium cilium/cilium \
--set k8sServiceHost=$controller_node_ip \
--set k8sServicePort=6443 \
--version 1.13.0-rc5 \
--namespace kube-system \
--set debug.enabled=true \
--set debug.verbose=datapath \
--set monitorAggregation=none \
--set ipam.mode=cluster-pool \
--set cluster.name=cilium-kubeproxy-replacement-ebpf \
--set kubeProxyReplacement=strict \
--set tunnel=disabled \
--set autoDirectNodeRoutes=true \
--set ipv4NativeRoutingCIDR="10.0.0.0/8" \
--set bpf.masquerade=true
# 4.install necessary tools
for i in $(docker ps -a --format "table {{.Names}}" | grep cilium)
do
echo $i
docker cp /usr/bin/ping $i:/usr/bin/ping
docker exec -it $i bash -c "sed -i -e 's/jp.archive.ubuntu.com\|archive.ubuntu.com\|security.ubuntu.com/old-releases.ubuntu.com/g' /etc/apt/sources.list"
docker exec -it $i bash -c "apt-get -y update >/dev/null && apt-get -y install net-tools tcpdump lrzsz bridge-utils >/dev/null 2>&1"
done
--set 参数解释
-
--set kubeProxyReplacement=strict- 含义: 启用 kube-proxy 替代功能,并以严格模式运行。
- 用途: Cilium 将完全替代 kube-proxy 实现服务负载均衡,提供更高效的流量转发和网络策略管理。
-
--set tunnel=disabled- 含义: 禁用隧道模式。
- 用途: 禁用后,Cilium 将不使用 vxlan 技术,直接在主机之间路由数据包,即 direct-routing 模式。
-
--set autoDirectNodeRoutes=true- 含义: 启用自动直接节点路由。
- 用途: 使 Cilium 自动设置直接节点路由,优化网络流量。
-
--set ipv4NativeRoutingCIDR="10.0.0.0/8"- 含义: 指定用于 IPv4 本地路由的 CIDR 范围,这里是
10.0.0.0/8。 - 用途: 配置 Cilium 使其知道哪些 IP 地址范围应该通过本地路由进行处理,不做 snat , Cilium 默认会对所用地址做 snat。
- 含义: 指定用于 IPv4 本地路由的 CIDR 范围,这里是
-
--set bpf.masquerade- 含义: 启用 eBPF 功能。
- 用途: 使用 eBPF 实现数据路由,提供更高效和灵活的网络地址转换功能。
- 安装
k8s集群和cilium服务
root@kind:~# ./install.sh
Creating cluster "cilium-kubeproxy-replacement-ebpf" ...
✓ Ensuring node image (kindest/node:v1.23.4) 🖼
✓ Preparing nodes 📦 📦 📦
✓ Writing configuration 📜
✓ Starting control-plane 🕹️
✓ Installing StorageClass 💾
✓ Joining worker nodes 🚜
Set kubectl context to "kind-cilium-kubeproxy-replacement-ebpf"
You can now use your cluster with:
kubectl cluster-info --context kind-cilium-kubeproxy-replacement-ebpf
Have a nice day! 👋
- 查看安装的服务
root@kind:~# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system cilium-496vl 1/1 Running 0 8m54s
kube-system cilium-6bt7g 1/1 Running 0 8m54s
kube-system cilium-mfc5w 1/1 Running 0 8m54s
kube-system cilium-operator-dd757785c-82wnx 1/1 Running 0 8m54s
kube-system cilium-operator-dd757785c-v8j7r 1/1 Running 0 8m54s
kube-system coredns-64897985d-66c4c 1/1 Running 0 10m
kube-system coredns-64897985d-st6l6 1/1 Running 0 10m
kube-system etcd-cilium-kubeproxy-replacement-ebpf-control-plane 1/1 Running 0 10m
kube-system kube-apiserver-cilium-kubeproxy-replacement-ebpf-control-plane 1/1 Running 0 10m
kube-system kube-controller-manager-cilium-kubeproxy-replacement-ebpf-control-plane 1/1 Running 0 10m
kube-system kube-scheduler-cilium-kubeproxy-replacement-ebpf-control-plane 1/1 Running 0 10m
local-path-storage local-path-provisioner-5ddd94ff66-s6cjg 1/1 Running 0 10m
查看
Pod服务信息,发现没有kube-proxy服务,因为我们设置了kubeProxyReplacement=strict,那么cilium将完全替代kube-proxy实现服务负载均衡。并且在kind安装k8s集群的时候也需要设置禁用kube-proxy安装kubeProxyMode: "none"
cilium 配置信息
# kubectl -n kube-system exec -it ds/cilium -- cilium status
KVStore: Ok Disabled
Kubernetes: Ok 1.23 (v1.23.4) [linux/amd64]
Kubernetes APIs: ["cilium/v2::CiliumClusterwideNetworkPolicy", "cilium/v2::CiliumEndpoint", "cilium/v2::CiliumNetworkPolicy", "cilium/v2::CiliumNode", "core/v1::Namespace", "core/v1::Node", "core/v1::Pods", "core/v1::Service", "discovery/v1::EndpointSlice", "networking.k8s.io/v1::NetworkPolicy"]
KubeProxyReplacement: Strict [eth0 172.18.0.3 (Direct Routing)]
Host firewall: Disabled
CNI Chaining: none
CNI Config file: CNI configuration file management disabled
Cilium: Ok 1.13.0-rc5 (v1.13.0-rc5-dc22a46f)
NodeMonitor: Listening for events on 128 CPUs with 64x4096 of shared memory
Cilium health daemon: Ok
IPAM: IPv4: 6/254 allocated from 10.0.0.0/24,
IPv6 BIG TCP: Disabled
BandwidthManager: Disabled
Host Routing: BPF
Masquerading: BPF [eth0] 10.0.0.0/8 [IPv4: Enabled, IPv6: Disabled]
Controller Status: 35/35 healthy
Proxy Status: OK, ip 10.0.0.231, 0 redirects active on ports 10000-20000
Global Identity Range: min 256, max 65535
Hubble: Ok Current/Max Flows: 4095/4095 (100.00%), Flows/s: 6.85 Metrics: Disabled
Encryption: Disabled
Cluster health: 3/3 reachable (2024-06-27T09:06:44Z)
KubeProxyReplacement: Strict [eth0 172.18.0.3 (Direct Routing)]- Cilium 完全接管所有 kube-proxy 功能,包括服务负载均衡、NodePort 和其他网络策略管理。这种配置适用于你希望最大限度利用 Cilium 的高级网络功能,并完全替代 kube-proxy 的场景。此模式提供更高效的流量转发和更强大的网络策略管理。
Host Routing: BPF- 使用 BPF 进行主机路由。
Masquerading: BPF [eth0] 10.0.0.0/8 [IPv4: Enabled, IPv6: Disabled]- 使用 BPF 进行 IP 伪装(NAT),接口 eth0,IP 范围 10.0.0.0/8 不回进行 NAT。IPv4 伪装启用,IPv6 伪装禁用。
k8s 集群安装 Pod 测试网络
# cat cni.yaml
apiVersion: apps/v1
kind: DaemonSet
#kind: Deployment
metadata:
labels:
app: evescn
name: evescn
spec:
#replicas: 1
selector:
matchLabels:
app: evescn
template:
metadata:
labels:
app: evescn
spec:
containers:
- image: harbor.dayuan1997.com/devops/nettool:0.9
name: nettoolbox
securityContext:
privileged: true
---
apiVersion: v1
kind: Service
metadata:
name: serversvc
spec:
type: NodePort
selector:
app: evescn
ports:
- name: cni
port: 8080
targetPort: 80
nodePort: 32000
root@kind:~# kubectl apply -f cni.yaml
daemonset.apps/cilium-with-replacement created
service/serversvc created
root@kind:~# kubectl run net --image=harbor.dayuan1997.com/devops/nettool:0.9
pod/net created
- 查看安装服务信息
root@kind:~# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
evescn-jzms5 1/1 Running 0 7m51s 10.0.2.202 cilium-kubeproxy-replacement-ebpf-worker2 <none> <none>
evescn-q7xhn 1/1 Running 0 7m51s 10.0.0.72 cilium-kubeproxy-replacement-ebpf-worker <none> <none>
evescn-zx9kk 1/1 Running 0 3m23s 10.0.1.63 cilium-kubeproxy-replacement-ebpf-control-plane <none> <none>
net 1/1 Running 0 4s 10.0.2.40 cilium-kubeproxy-replacement-ebpf-worker2 <none> <none>
root@kind:~# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 9m
serversvc NodePort 10.96.93.201 <none> 8080:32000/TCP 76s
三、测试网络
同节点 Pod 网络通讯
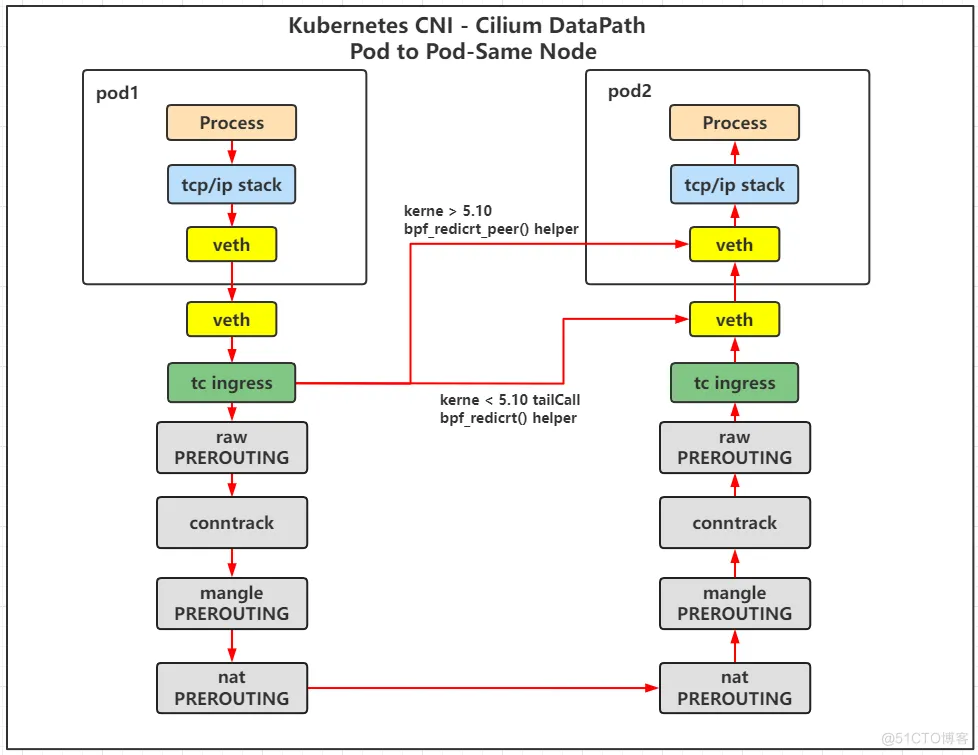
Pod节点信息
## ip 信息
root@kind:~# kubectl exec -it net -- ip a l
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
8: eth0@if9: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ae:32:09:5a:08:5c brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.2.40/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::ac32:9ff:fe5a:85c/64 scope link
valid_lft forever preferred_lft forever
## 路由信息
root@kind:~# kubectl exec -it net -- ip r s
default via 10.0.2.34 dev eth0 mtu 1500
10.0.2.34 dev eth0 scope link
查看 Pod 信息发现在 cilium 中主机的 IP 地址为 32 位掩码,意味着该 IP 地址是单个主机的唯一标识,而不是一个子网。这个主机访问其他 IP 均会走路由到达
Pod节点所在Node节点信息
root@kind:~# docker exec -it cilium-kubeproxy-replacement-ebpf-worker2 bash
## ip 信息
root@cilium-kubeproxy-replacement-ebpf-worker2:/# ip a l
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: cilium_net@cilium_host: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 06:d8:6d:5e:2f:fe brd ff:ff:ff:ff:ff:ff
inet6 fe80::4d8:6dff:fe5e:2ffe/64 scope link
valid_lft forever preferred_lft forever
3: cilium_host@cilium_net: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 1a:5e:33:bb:28:40 brd ff:ff:ff:ff:ff:ff
inet 10.0.2.34/32 scope link cilium_host
valid_lft forever preferred_lft forever
inet6 fe80::185e:33ff:febb:2840/64 scope link
valid_lft forever preferred_lft forever
5: lxc_health@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 4e:0e:82:d4:e2:eb brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::4c0e:82ff:fed4:e2eb/64 scope link
valid_lft forever preferred_lft forever
7: lxccb7c1b078d26@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a6:1d:2b:bd:af:60 brd ff:ff:ff:ff:ff:ff link-netns cni-0f4755bb-f628-7d32-54d6-2fdad2ee5fc3
inet6 fe80::a41d:2bff:febd:af60/64 scope link
valid_lft forever preferred_lft forever
9: lxcbf5cb1e7ceb0@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether be:06:1e:82:86:b6 brd ff:ff:ff:ff:ff:ff link-netns cni-13e7f3e3-70a3-9965-de9a-bfdaa0569170
inet6 fe80::bc06:1eff:fe82:86b6/64 scope link
valid_lft forever preferred_lft forever
23: eth0@if24: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.2/16 brd 172.18.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fc00:f853:ccd:e793::2/64 scope global nodad
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe12:2/64 scope link
valid_lft forever preferred_lft forever
## 路由信息
root@cilium-kubeproxy-replacement-ebpf-worker2:/# ip r s
default via 172.18.0.1 dev eth0
10.0.0.0/24 via 172.18.0.3 dev eth0
10.0.1.0/24 via 172.18.0.4 dev eth0
10.0.2.0/24 via 10.0.2.34 dev cilium_host src 10.0.2.34
10.0.2.34 dev cilium_host scope link
172.18.0.0/16 dev eth0 proto kernel scope link src 172.18.0.2
Pod节点进行ping包测试,查看宿主机路由信息,发现并在数据包会在通过10.0.2.0/24 via 10.0.2.34 dev cilium_host src 10.0.2.34路由信息转发
root@kind:~# kubectl exec -it net -- ping 10.0.2.202 -c 1
PING 10.0.2.202 (10.0.2.202): 56 data bytes
64 bytes from 10.0.2.202: seq=0 ttl=63 time=0.707 ms
--- 10.0.2.202 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 0.707/0.707/0.707 ms
Pod节点eth0网卡抓包
net~$ tcpdump -pne -i eth0
09:19:00.081174 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 98: 10.0.2.40 > 10.0.2.202: ICMP echo request, id 55, seq 0, length 64
09:19:00.081472 be:06:1e:82:86:b6 > ae:32:09:5a:08:5c, ethertype IPv4 (0x0800), length 98: 10.0.2.202 > 10.0.2.40: ICMP echo reply, id 55, seq 0, length 64
Node节点Pod的veth pair网卡lxcbf5cb1e7ceb0抓包
root@cilium-kubeproxy-replacement-ebpf-worker2:/# tcpdump -pne -i lxcbf5cb1e7ceb0
09:19:00.081177 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 98: 10.0.2.40 > 10.0.2.202: ICMP echo request, id 55, seq 0, length 64
通过对比抓包信息,我们发现 Pod 节点 eth0 网卡有 icmp 的 request 和 reply 数据包,但是在 lxcbf5cb1e7ceb0 网卡只有 request 数据包
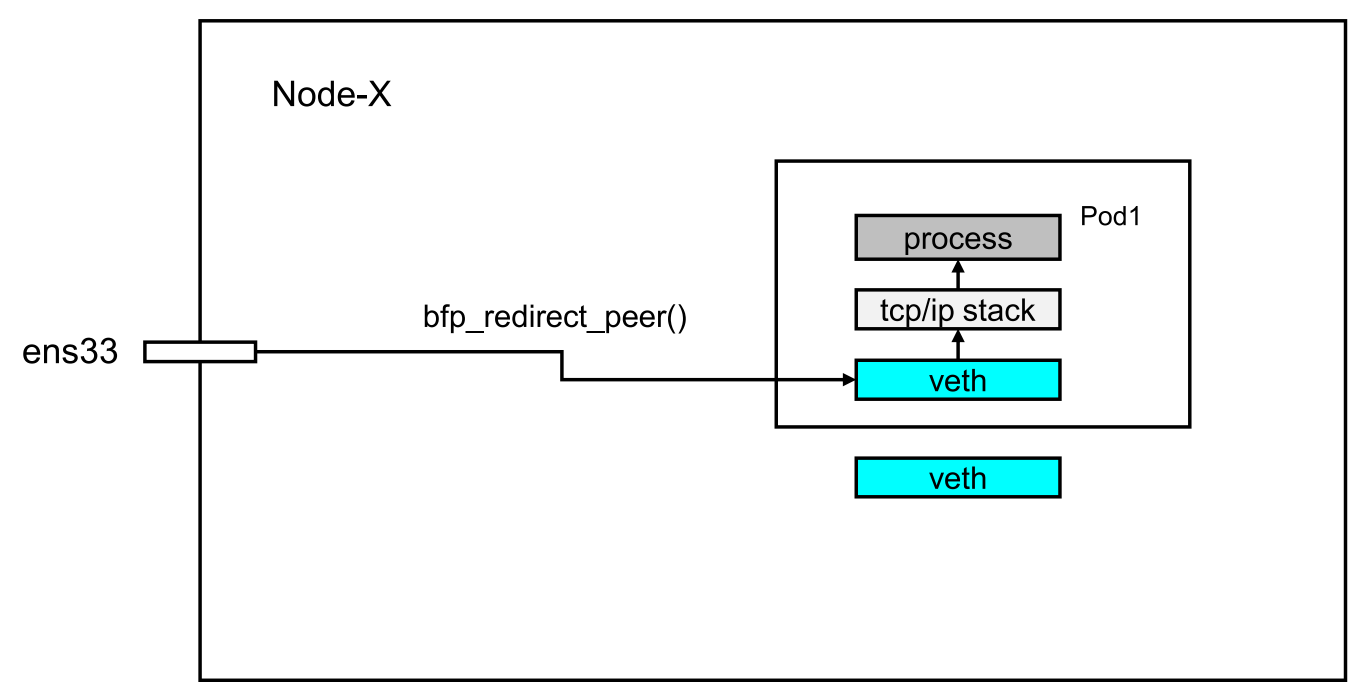
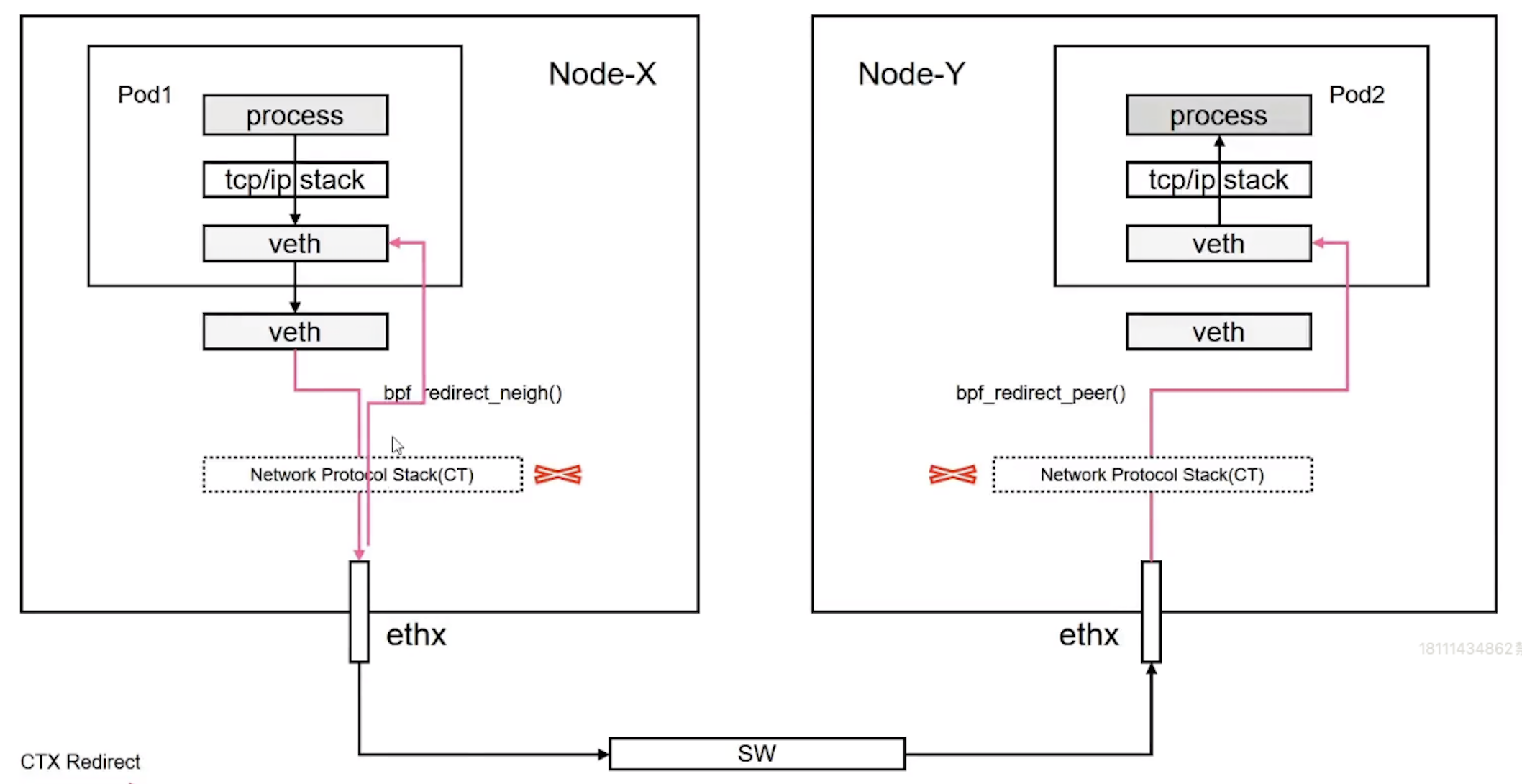
这是因为在内核 5.11.0 以后,具备了 bpf_redict_peer() 和 bpf_redict_neigh() 这两个非常重要的 helper 函数的能力。 cilium 在高版本中开始支持的功能
bpf_redict_peer()
bpf_redirect_peer()在穿越网络命名空间时,可以从网卡入口到Pod入口切换网络命名空间,而无需重新安排软件中断点。这样,物理网卡就能一次性将数据包从堆栈推送到驻留在不同Pod命名空间的应用程序套接字中。这样还能更快地唤醒应用程序,以接收接收到的数据。同样,本地Pod到Pod通信的重新安排点从2个减少到1个,从而改善了延迟。
如下图所示, bpf_redict_peer() 函数可以将同一个节点的pod 通信的步骤进行省略,报文在从源 pod 出来以后,可以直接 redict (直连) 到目的 pod 的 内部网卡 ,而不会经过宿主机上与其对应的 veth pair 网卡,这样在报文的路径就少了一步转发。
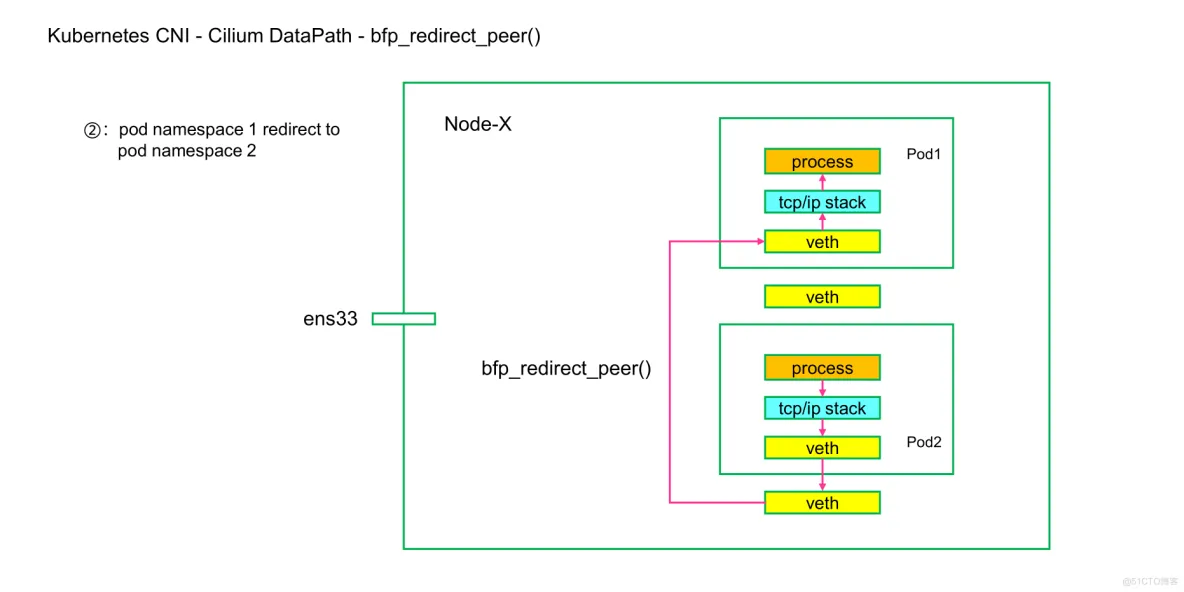
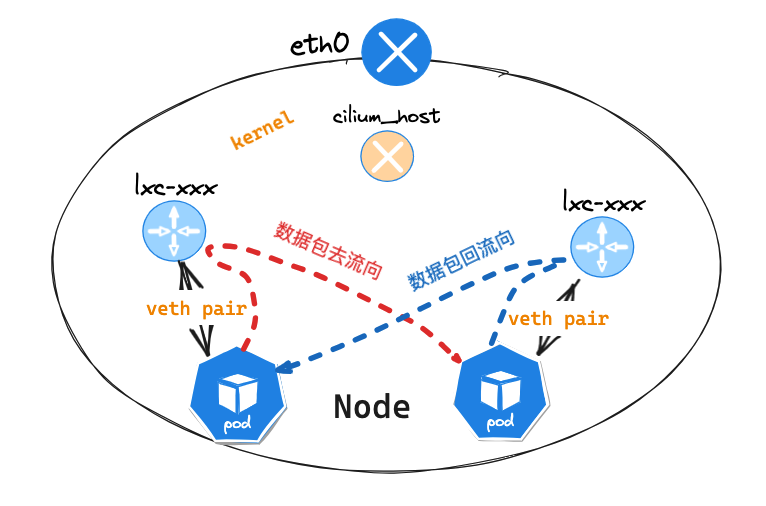
同理,我们可以推测出对于目的 Pod 而言,他的 veth pair 网卡也只能抓到 request 数据包,抓不到 reply 数据包,2 个 Pod 直接的通讯流程如下图:
- 查看
10.0.2.202Pod主机信息
root@kind:~# kubectl exec -it evescn-jzms5 -- ip a l
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
6: eth0@if7: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 7e:55:97:9f:d9:bf brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.2.202/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::7c55:97ff:fe9f:d9bf/64 scope link
valid_lft forever preferred_lft forever
查看 eth0 信息,可以确定在 Pod 的 eth0 网卡在宿主机的 veth pair 网卡位 id = 7 的网卡,查看前面 Node 节点信息发现为: 7: lxccb7c1b078d26
Node节点lxccb7c1b078d26网卡抓包
root@cilium-kubeproxy-replacement-ebpf-worker2:/# tcpdump -pne -i lxccb7c1b078d26
09:41:17.997320 7e:55:97:9f:d9:bf > a6:1d:2b:bd:af:60, ethertype IPv4 (0x0800), length 98: 10.0.2.202 > 10.0.2.40: ICMP echo reply, id 61, seq 0, length 64
- 查看
10.0.2.202Pod主机eht0抓包
evescn-jzms5~$ tcpdump -pne -i eth0
09:41:17.997003 a6:1d:2b:bd:af:60 > 7e:55:97:9f:d9:bf, ethertype IPv4 (0x0800), length 98: 10.0.2.40 > 10.0.2.202: ICMP echo request, id 61, seq 0, length 64
09:41:17.997319 7e:55:97:9f:d9:bf > a6:1d:2b:bd:af:60, ethertype IPv4 (0x0800), length 98: 10.0.2.202 > 10.0.2.40: ICMP echo reply, id 61, seq 0, length 64
启用了
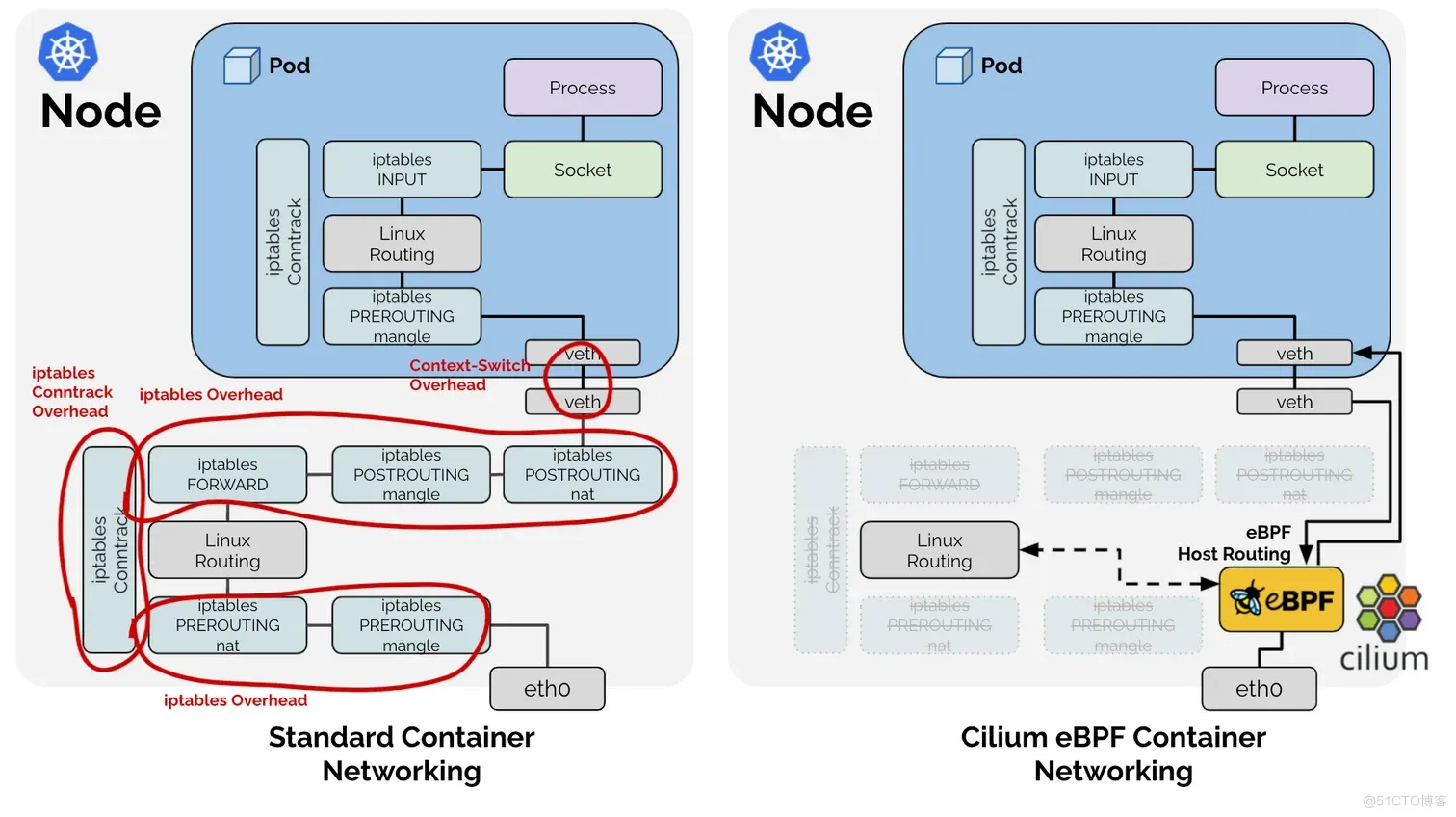
ebpf后,并且kernel内核 大于5.10后,pod数据包流向和传统理解模式有区别,和eth0互为veth pair的网卡,不一定能接受到所有的数据包信息,在生产问题排查中需要注意
不同节点 Pod 网络通讯
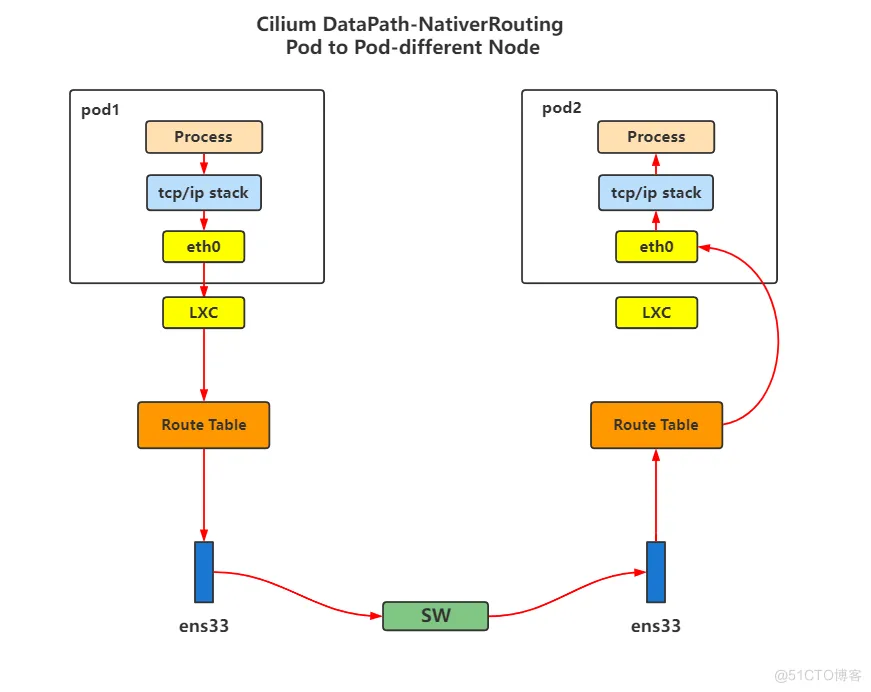
-
Pod节点信息,查看前面: 同节点Pod网络通讯 -
Pod节点所在Node节点信息,查看前面: 同节点Pod网络通讯 -
Pod节点进行ping包测试,查看宿主机路由信息,发现并在数据包会在通过10.0.0.0/24 via 172.18.0.3 dev eth0路由信息转发
root@kind:~# kubectl exec -it net -- ping 10.0.0.72 -c 1
PING 10.0.0.72 (10.0.0.72): 56 data bytes
64 bytes from 10.0.0.72: seq=0 ttl=62 time=1.916 ms
--- 10.0.0.72 ping statistics ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 1.916/1.916/1.916 ms
Pod节点eth0网卡抓包
net~$ tcpdump -pne -i eth0
09:58:03.642047 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 98: 10.0.2.40 > 10.0.0.72: ICMP echo request, id 84, seq 0, length 64
09:58:03.642594 be:06:1e:82:86:b6 > ae:32:09:5a:08:5c, ethertype IPv4 (0x0800), length 98: 10.0.0.72 > 10.0.2.40: ICMP echo reply, id 84, seq 0, length 64
Node节点cilium-kubeproxy-replacement-ebpf-worker2Pod的veth pair网卡lxcbf5cb1e7ceb0抓包
root@cilium-kubeproxy-replacement-ebpf-worker2:/# tcpdump -pne -i lxcbf5cb1e7ceb0
09:58:03.642050 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 98: 10.0.2.40 > 10.0.0.72: ICMP echo request, id 84, seq 0, length 64
通过抓包我们发现,在跨节点的通讯中 veth pair 网卡 lxcbf5cb1e7ceb0 也只有 request 数据包,这是因为 bpf_redict_peer() 还在发挥作用,从宿主机节点来的数据包,只要是到达 Pod 节点的,依旧会跳过 lxc 网卡。
Node节点cilium-kubeproxy-replacement-ebpf-worker2eth0网卡抓包
root@cilium-kubeproxy-replacement-ebpf-worker2:/# tcpdump -pne -i lxc89eb07782005
10:07:48.268822 02:42:ac:12:00:02 > 02:42:ac:12:00:03, ethertype IPv4 (0x0800), length 98: 10.0.2.40 > 10.0.0.72: ICMP echo request, id 92, seq 0, length 64
10:07:48.269136 02:42:ac:12:00:03 > 02:42:ac:12:00:02, ethertype IPv4 (0x0800), length 98: 10.0.0.72 > 10.0.2.40: ICMP echo reply, id 92, seq 0, length 64
查看 eth0 网卡抓包信息,发现数据包下一跳 mac 02:42:ac:12:00:03 ,按照之前的路由信息,分析此地址应该为 172.18.0.3 节点 eth0 mac 地址
查看 cilium-kubeproxy-replacement-ebpf-worker2 节点 mac 信息
root@cilium-kubeproxy-replacement-ebpf-worker2:/#arp -n
Address HWtype HWaddress Flags Mask Iface
172.18.0.3 ether 02:42:ac:12:00:03 C eth0
172.18.0.4 ether 02:42:ac:12:00:04 C eth0
172.18.0.1 ether 02:42:2f:fe:43:35 C eth0
Node节点cilium-kubeproxy-replacement-ebpf-workereth0网卡抓包
root@cilium-kubeproxy-replacement-ebpf-worker2:/# tcpdump -pne -i eth0 icmp
10:10:17.229336 02:42:ac:12:00:02 > 02:42:ac:12:00:03, ethertype IPv4 (0x0800), length 98: 10.0.2.40 > 10.0.0.72: ICMP echo request, id 99, seq 0, length 64
10:10:17.229622 02:42:ac:12:00:03 > 02:42:ac:12:00:02, ethertype IPv4 (0x0800), length 98: 10.0.0.72 > 10.0.2.40: ICMP echo reply, id 99, seq 0, length 64
查看 eth0 网卡抓包信息,数据包源 mac 02:42:ac:12:00:02 为 172.18.0.2 eth0 mac 地址,目的 mac 02:42:ac:12:00:03 ,为本机 eth0 mac 地址
查看 cilium-kubeproxy-replacement-worker 节点 ip 信息
root@cilium-kubeproxy-replacement-worker:/# ip a l
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: cilium_net@cilium_host: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ba:d4:d5:86:e4:c4 brd ff:ff:ff:ff:ff:ff
inet6 fe80::b8d4:d5ff:fe86:e4c4/64 scope link
valid_lft forever preferred_lft forever
3: cilium_host@cilium_net: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether a2:5e:1d:03:8c:f6 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.231/32 scope link cilium_host
valid_lft forever preferred_lft forever
inet6 fe80::a05e:1dff:fe03:8cf6/64 scope link
valid_lft forever preferred_lft forever
5: lxc_health@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ee:cc:02:10:9d:55 brd ff:ff:ff:ff:ff:ff link-netnsid 1
inet6 fe80::eccc:2ff:fe10:9d55/64 scope link
valid_lft forever preferred_lft forever
7: lxcbf1d9227d372@if6: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 0e:ed:9c:12:3a:08 brd ff:ff:ff:ff:ff:ff link-netns cni-db59179b-ceed-fde3-c1c7-e6d3f83506d5
inet6 fe80::ced:9cff:fe12:3a08/64 scope link
valid_lft forever preferred_lft forever
9: lxc7f220bbf2953@if8: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 1e:be:cd:8f:63:93 brd ff:ff:ff:ff:ff:ff link-netns cni-cbfca9ee-4591-ba92-8c08-de2aa5d0d090
inet6 fe80::1cbe:cdff:fe8f:6393/64 scope link
valid_lft forever preferred_lft forever
11: lxc6df5bdb74383@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether e2:6f:f4:74:3d:fd brd ff:ff:ff:ff:ff:ff link-netns cni-4f819e17-233a-2637-281c-ce0f9c505fa9
inet6 fe80::e06f:f4ff:fe74:3dfd/64 scope link
valid_lft forever preferred_lft forever
13: lxc56a9c4b40736@if12: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether f6:1c:ec:b2:0f:ba brd ff:ff:ff:ff:ff:ff link-netns cni-c56449c3-5791-8823-56f9-44fa8ab5cfd6
inet6 fe80::f41c:ecff:feb2:fba/64 scope link
valid_lft forever preferred_lft forever
25: eth0@if26: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 02:42:ac:12:00:03 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.3/16 brd 172.18.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fc00:f853:ccd:e793::3/64 scope global nodad
valid_lft forever preferred_lft forever
inet6 fe80::42:acff:fe12:3/64 scope link
valid_lft forever preferred_lft forever
- 目标
Podip信息
evescn-q7xhn~$ip a l
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
12: eth0@if13: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ca:8f:99:91:17:f2 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.0.0.72/32 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::c88f:99ff:fe91:17f2/64 scope link
valid_lft forever preferred_lft forever
目标 Pod eth0 网卡的 veth pair 是 13: lxc56a9c4b40736,分别在 cilium-kubeproxy-replacement-worker 节点 lxc56a9c4b40736 网卡和 Pod eth0 网卡抓包
Node节点cilium-kubeproxy-replacement-ebpf-worker目标Pod的veth pair网卡lxc56a9c4b40736抓包
root@cilium-kubeproxy-replacement-ebpf-worker:/# tcpdump -pne -i lxc56a9c4b40736
10:10:17.229512 ca:8f:99:91:17:f2 > f6:1c:ec:b2:0f:ba, ethertype IPv4 (0x0800), length 98: 10.0.0.72 > 10.0.2.40: ICMP echo reply, id 99, seq 0, length 64
- 目标
Pod节点eth0网卡抓包
evescn-q7xhn~$ tcpdump -pne -i eth0
10:10:17.229336 f6:1c:ec:b2:0f:ba > ca:8f:99:91:17:f2, ethertype IPv4 (0x0800), length 98: 10.0.2.40 > 10.0.0.72: ICMP echo request, id 99, seq 0, length 64
10:10:17.229511 ca:8f:99:91:17:f2 > f6:1c:ec:b2:0f:ba, ethertype IPv4 (0x0800), length 98: 10.0.0.72 > 10.0.2.40: ICMP echo reply, id 99, seq 0, length 64
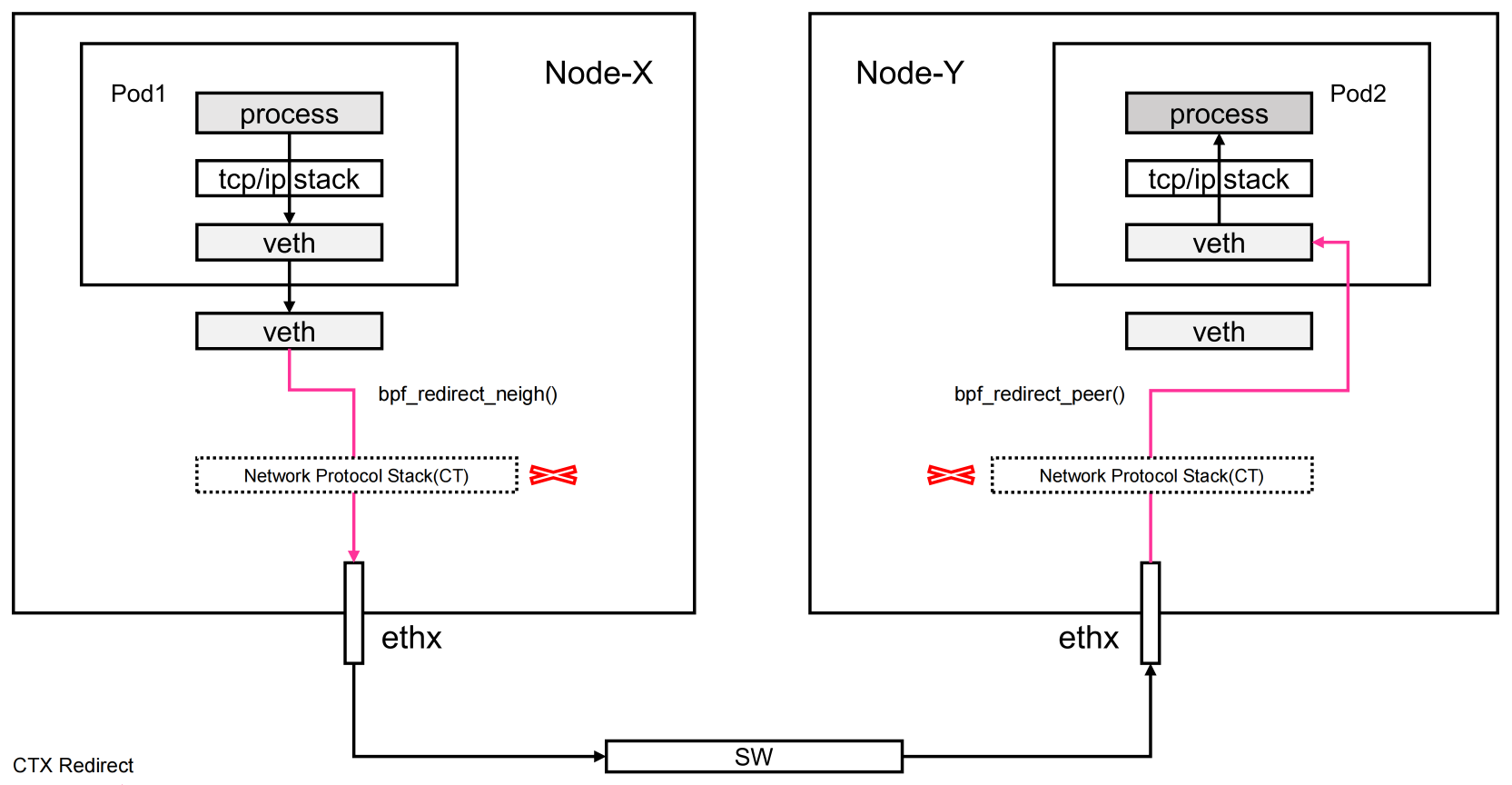
因为 bpf_redict_peer() 的原因,veth pair 网卡 lxc56a9c4b40736 上依旧只有 reply 数据包信息,并且在垮节点通讯中还使用了到了 bpf_redict_neigh() 功能, bpf_redict_neigh() 会跳过宿主机的 iptables,只会查询路由表信息,而不会进入 iptables 规则判断中。这样可以减少数据包的上下文切换等,提高网络数据转发效率。如下图:
bpf_redirect_neigh()通过将流量注入Linux内核的邻接子系统来处理Pod的出口流量,从而找到下一跳并解析网络数据包的第2层地址。只在tc eBPF层进行转发,而不将数据包进一步推向网络堆栈,还能为TCP堆栈提供适当的反向压力,并为TCP的TSQ(TCP小队列)机制提供反馈,以减少TCP数据包可能出现的过度排队现象。也就是说,TCP协议栈会得到数据包已离开节点的反馈,而不是在数据包被推送到主机协议栈进行路由选择时过早地提供不准确的反馈。之所以能做到这一点,是因为数据包的套接字关联在向下传递到NIC驱动程序时可以保持不变。
数据会从 veth pair 网卡,直接进入 ebpf 中,然后经由 ebpf 查询 linux routing 后,直接使用 eth0 发送出去,从而不在走 linux 系统主机的 iptables 规则
Service 网络通讯
- 查看
Service信息
root@kind:~# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 9m
serversvc NodePort 10.96.93.201 <none> 8080:32000/TCP 76s
net服务上请求Pod所在Node节点32000端口
root@kind:~# kubectl exec -ti net -- curl 172.18.0.2:32000
PodName: evescn-jzms5 | PodIP: eth0 10.0.2.202/32
并在 net 服务 eth0 网卡 抓包查看
net~$ tcpdump -pne -i eth0
02:27:19.933659 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 74: 10.0.2.40.32794 > 10.0.2.202.80: Flags [S], seq 1073282361, win 64240, options [mss 1460,sackOK,TS val 3661176389 ecr 0,nop,wscale 7], length 0
02:27:19.933882 be:06:1e:82:86:b6 > ae:32:09:5a:08:5c, ethertype IPv4 (0x0800), length 74: 10.0.2.202.80 > 10.0.2.40.32794: Flags [S.], seq 901038452, ack 1073282362, win 65160, options [mss 1460,sackOK,TS val 3465621389 ecr 3661176389,nop,wscale 7], length 0
02:27:19.934061 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 66: 10.0.2.40.32794 > 10.0.2.202.80: Flags [.], ack 1, win 502, options [nop,nop,TS val 3661176390 ecr 3465621389], length 0
02:27:19.934440 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 146: 10.0.2.40.32794 > 10.0.2.202.80: Flags [P.], seq 1:81, ack 1, win 502, options [nop,nop,TS val 3661176390 ecr 3465621389], length 80: HTTP: GET / HTTP/1.1
02:27:19.934623 be:06:1e:82:86:b6 > ae:32:09:5a:08:5c, ethertype IPv4 (0x0800), length 66: 10.0.2.202.80 > 10.0.2.40.32794: Flags [.], ack 81, win 509, options [nop,nop,TS val 3465621389 ecr 3661176390], length 0
02:27:19.936129 be:06:1e:82:86:b6 > ae:32:09:5a:08:5c, ethertype IPv4 (0x0800), length 302: 10.0.2.202.80 > 10.0.2.40.32794: Flags [P.], seq 1:237, ack 81, win 509, options [nop,nop,TS val 3465621391 ecr 3661176390], length 236: HTTP: HTTP/1.1 200 OK
02:27:19.936308 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 66: 10.0.2.40.32794 > 10.0.2.202.80: Flags [.], ack 237, win 501, options [nop,nop,TS val 3661176392 ecr 3465621391], length 0
02:27:19.936496 be:06:1e:82:86:b6 > ae:32:09:5a:08:5c, ethertype IPv4 (0x0800), length 116: 10.0.2.202.80 > 10.0.2.40.32794: Flags [P.], seq 237:287, ack 81, win 509, options [nop,nop,TS val 3465621391 ecr 3661176392], length 50: HTTP
02:27:19.936687 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 66: 10.0.2.40.32794 > 10.0.2.202.80: Flags [.], ack 287, win 501, options [nop,nop,TS val 3661176392 ecr 3465621391], length 0
02:27:19.938630 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 66: 10.0.2.40.32794 > 10.0.2.202.80: Flags [F.], seq 81, ack 287, win 501, options [nop,nop,TS val 3661176394 ecr 3465621391], length 0
02:27:19.938901 be:06:1e:82:86:b6 > ae:32:09:5a:08:5c, ethertype IPv4 (0x0800), length 66: 10.0.2.202.80 > 10.0.2.40.32794: Flags [F.], seq 287, ack 82, win 509, options [nop,nop,TS val 3465621394 ecr 3661176394], length 0
02:27:19.939118 ae:32:09:5a:08:5c > be:06:1e:82:86:b6, ethertype IPv4 (0x0800), length 66: 10.0.2.40.32794 > 10.0.2.202.80: Flags [.], ack 288, win 501, options [nop,nop,TS val 3661176395 ecr 3465621394], length 0
抓包数据显示, net 服务使用随机端口和 10.0.2.202 80 端口进行 tcp 通讯。
* `KubeProxyReplacement: Strict [eth0 172.18.0.3 (Direct Routing)]`
* Cilium 完全接管所有 kube-proxy 功能,包括服务负载均衡、NodePort 和其他网络策略管理。这种配置适用于你希望最大限度利用 Cilium 的高级网络功能,并完全替代 kube-proxy 的场景。此模式提供更高效的流量转发和更强大的网络策略管理。
cilium 配置 KubeProxyReplacement: Strict [eth0 172.18.0.3 (Direct Routing)],通过配置信息确定 cilium 接管 kube-proxy 的功能,使用 cilium 实现 service 转发。我们可以先检查下默认 kube-proxy 的 conntrack 信息和 iptables 信息
- 先检查下
conntrack信息,发现没有链路信息
root@cilium-kubeproxy-replacement-ebpf-worker2:/# conntrack -L | grep 32000
## 没有数据信息
iptables信息,也没有iptables规则信息
root@cilium-kubeproxy-replacement-ebpf-worker2:/# iptables-save | grep 32000
## 没有数据信息
那么 cilium 是如何查询 service 信息,并返回后端 Pod ip 地址给请求方的?其实 cilium 把数据保存在自身内部,使用 cilium 子命令可以查询到 service 信息
cilium查询service信息
root@kind:~# kubectl -n kube-system exec cilium-2xvsw -- cilium service list
ID Frontend Service Type Backend
1 10.96.0.1:443 ClusterIP 1 => 172.18.0.4:6443 (active)
2 10.96.0.10:53 ClusterIP 1 => 10.0.0.228:53 (active)
2 => 10.0.0.103:53 (active)
3 10.96.0.10:9153 ClusterIP 1 => 10.0.0.228:9153 (active)
2 => 10.0.0.103:9153 (active)
4 10.96.102.191:443 ClusterIP 1 => 172.18.0.2:4244 (active)
5 10.96.93.201:8080 ClusterIP 1 => 10.0.0.72:80 (active)
2 => 10.0.2.202:80 (active)
3 => 10.0.1.63:80 (active)
6 172.18.0.2:32000 NodePort 1 => 10.0.0.72:80 (active)
2 => 10.0.2.202:80 (active)
3 => 10.0.1.63:80 (active)
7 0.0.0.0:32000 NodePort 1 => 10.0.0.72:80 (active)
2 => 10.0.2.202:80 (active)
3 => 10.0.1.63:80 (active)
查看上面的 service 信息得到, 172.18.0.2:32000 后端有 3 个 ip 地址信息,并且后端端口为 80 , cilium 劫持到 Pod 需要访问 service 信息,即会查询该 service 对应的后端 Pod 地址和端口返回给客户端,让客户端使用此地址发起 http 请求
四、TC Hook
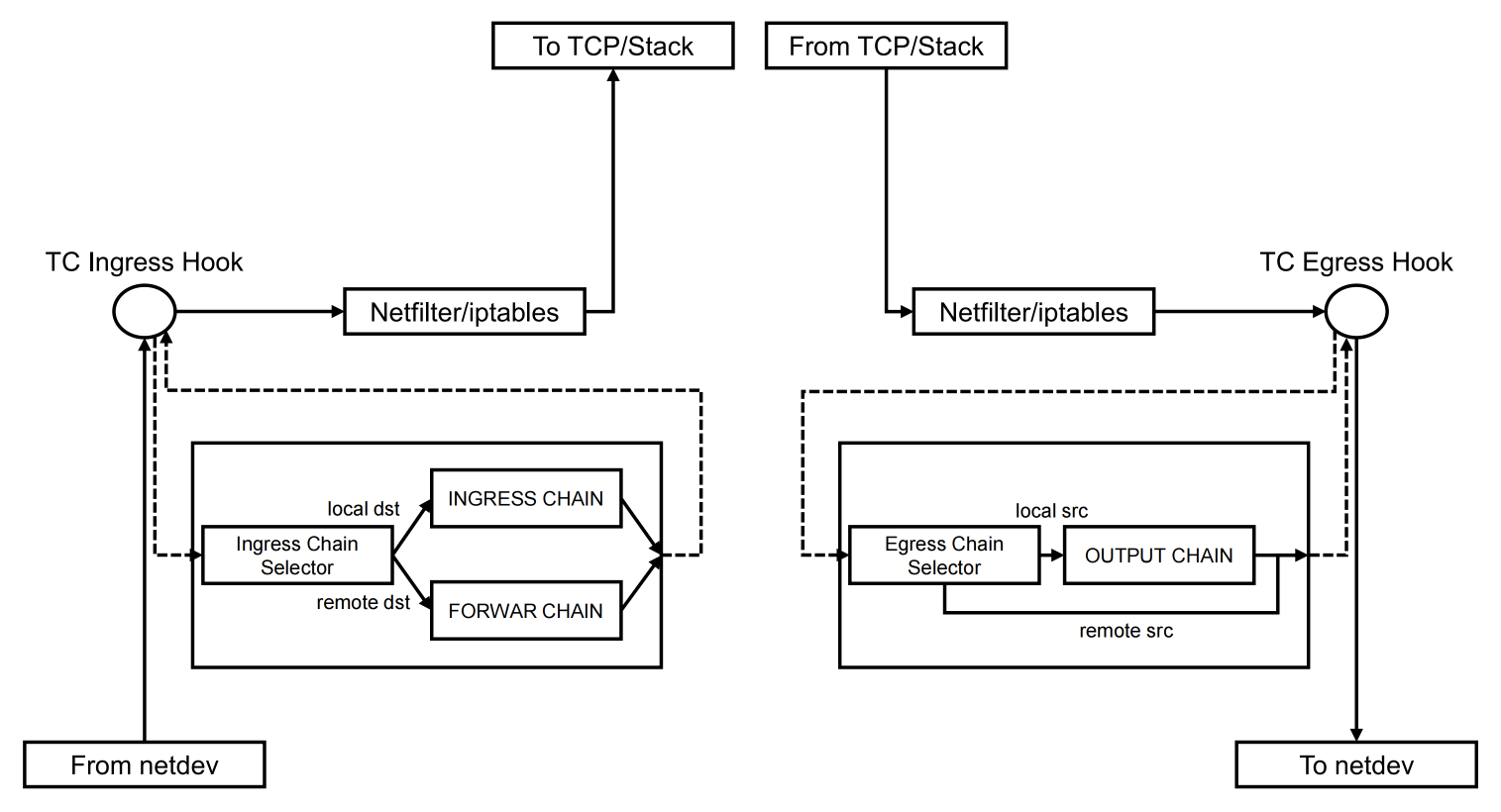
TC from-container
root@cilium-kubeproxy-replacement-ebpf-worker2:/# tc filter show dev lxcbf5cb1e7ceb0 ingress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cilium-lxcbf5cb1e7ceb0 direct-action not_in_hw id 7232 tag 343a0e7d38824f0e jited
此 TC Hook 挂载在 Pod 主机侧的虚拟网络设备上,也就是 lxc-xxx 这个网络设备,方向为 ingress
- 1.当
packet要从Pod出去,首先packet会经过eth0到达Pod对应的lxc-xxx的TC ingress,这里的eBPF程序的Section是from-container。 - 2.数据包是从
Pod发出去的,如果是original类型的数据包,会在这里完成数据包的DNAT操作,管理连接跟踪;如果是reply类型的数据包,会完成reverse DNAT的操作。 - 3.对于有
Network Policy验证需要的数据包,会经过tproxy的方式,将数据包发往cilium proxy去验证是不是可以access,对于正常的从服务端返回的reply数据包,会标记成skip policy,也就是不需要做验证。具体实现参考policy_can_egress4方法。
从 Pod 里出来的数据包的目的方向大致可以分为几个路径
- 1.第一个是
Pod访问本地的Pod,经过ipv4_local_delivery来完成数据包的转发 - 2.第二个是
Pod访问外网,经过Kernel Stack完成解析后,经过物理网卡的to-netdev出去 - 3.第三个是
Pod访问本地的非 Pod 的,也是经过Kernel Stack完成 - 4.第四个是
Pod访问非本机的集群其它机器中的Pod,经过Kernel Stack完成解析后,经过物理网卡to-netdev出去 - 5.第五个是
Pod经过overlay网络访问非本机的集群其它机器中的Pod,经过cilium_vxlan,然后经过Kernel Stack完成解析后经过物理网卡出去
TC to-container
这是一个 eBPF Section ,这是一个比较特别的 eBPF 的程序。它和 Pod 相关,但是却不是挂载在 TC egress 上的,而是以 eBPF 程序,保存在 eBPF 中的 map 中的, eBPF 中有一种 map 类型,是可以保存 eBPF 程序的 (BPF_MAP_TYPE_PROG_ARRAY) ,同时 map 中的程序都有自己的 id 编号,可以用来在 tail call 中直接调用,to-container 就是其中之一,而且是每一个 Pod 都有自己独立的 to-container ,和其它和 Pod 相关的 eBPF 程序一样。
它的主要作用就是,在数据包进入 Pod 进入之前,完成 Policy 的验证,如果验证通过了会使用 Linux 的 redirect 方法,将数据包转发到 Pod 的虚拟网络设备上。至于是 lxc-xxx 还是 eth0,看内核的版本支持不支持 redirect peer,如果支持 redirect peer,就会直接转发到 Pod 的 eth0 ,如果不支持就会转发到 Pod 的主机侧的 lxc-xxx 上。
TC to-netdev
root@cilium-kubeproxy-replacement-ebpf-worker2:/# tc filter show dev eth0 egress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cilium-eth0 direct-action not_in_hw id 7186 tag d1f9b589b59b2d62 jited
此TC Hook挂载在物理网卡的 TC egress 上的 eBPF 程序。主要的作用是: 完成主机数据包出主机,对数据包进行处理。
这里主要有两个场景会涉及到 to-netdev:
- 1.第一个就是开启了主机的防火墙,这里的防火墙不是
iptables实现的,而是基于eBPF实现的Host Network Policy,用于处理什么样的数据包是可以出主机的,通过handle_to_netdev_ipv4方法完成; - 2.第二个就是开启了
NodePort之后,在需要访问的Backend Pod不在主机的时候,会在这里完成SNAT操作,通过handle_nat_fwd方法和nodeport_nat_ipv4_fwd方法完成SNAT。 - 3.和
from-overlay关系:数据包都是从物理网卡到达主机的,那是怎样到达cilium_vxlan的?这个是由挂载在物理网卡的from-netdev,根据隧道类型,将数据包通过redirect的方式,传递到cilium_vxlan的。参见:from-netdev的encap_and_redirect_with_nodeid方法,其中主要有两个方法,一是 __encap_with_nodeid(ctx, tunnel_endpoint, seclabel, monitor) 方法完成encapsulating,二是 ctx_redirect(ctx, ENCAP_IFINDEX, 0) 方法完成将数据包redirect到cilium_vxlan对应的ENCAP_IFINDEX这个ifindex。
TC from-netdev
root@cilium-kubeproxy-replacement-ebpf-worker2:/# tc filter show dev eth0 ingress
filter protocol all pref 1 bpf chain 0
filter protocol all pref 1 bpf chain 0 handle 0x1 cilium-eth0 direct-action not_in_hw id 7177 tag 94772f5b3d31e1ac jited
此TC Hook挂载在物理网卡的 TC ingress 上的 eBPF 程序。主要的作用是,完成主机数据包到达主机,对数据包进行处理。
这里主要有两个场景会涉及到 from-netdev
- 1.第一个就是开启了主机的防火墙,这里的防火墙不是
iptables实现的,而是基于eBPF实现的Host Network Policy,用于处理什么样的数据包是可以访问主机的 - 2.第二个就是开启了
NodePort,可以处理外部通过K8S NodePort的服务访问方式,访问服务,包括DNAT、LB、CT等操作,将外部的访问流量打到本地的Pod,或者通过TC的redirect的方式,将数据流量转发到to-netdev进行SNAT之后,再转发到提供服务的Pod所在的主机

 浙公网安备 33010602011771号
浙公网安备 33010602011771号