15 Ceph 高级参数配置(转载)
Ceph 高级参数配置
调整命名空间
cd cluster/examples/kubernetes/ceph
export ROOK_OPERATOR_NAMESPACE="rook-ceph"
export ROOK_CLUSTER_NAMESPACE="rook-ceph"
sed -i.bak \
-e "s/\(.*\):.*# namespace:operator/\1: $ROOK_OPERATOR_NAMESPACE # namespace:operator/g" \
-e "s/\(.*\):.*# namespace:cluster/\1: $ROOK_CLUSTER_NAMESPACE # namespace:cluster/g" \
-e "s/\(.*serviceaccount\):.*:\(.*\) # serviceaccount:namespace:operator/\1:$ROOK_OPERATOR_NAMESPACE:\2 # serviceaccount:namespace:operator/g" \
-e "s/\(.*serviceaccount\):.*:\(.*\) # serviceaccount:namespace:cluster/\1:$ROOK_CLUSTER_NAMESPACE:\2 # serviceaccount:namespace:cluster/g" \
-e "s/\(.*\): [-_A-Za-z0-9]*\.\(.*\) # driver:namespace:operator/\1: $ROOK_OPERATOR_NAMESPACE.\2 # driver:namespace:operator/g" \
-e "s/\(.*\): [-_A-Za-z0-9]*\.\(.*\) # driver:namespace:cluster/\1: $ROOK_CLUSTER_NAMESPACE.\2 # driver:namespace:cluster/g" \
common.yaml operator.yaml cluster.yaml # add other files or change these as desired for your config
# You need to use `apply` for all Ceph clusters after the first if you have only one Operator
kubectl apply -f common.yaml -f operator.yaml -f cluster.yaml # add other files as desired for yourconfig
采集容器日志
[root@m1 rbd]# cat /tmp/log.sh
#!/bin/bash
log_path="/var/log/rook"
DATE=`date +%F`
mkdir -pv log_path
for p in $(kubectl -n rook-ceph get pods -o jsonpath='{.items[*].metadata.name}')
do
for c in $(kubectl -n rook-ceph get pod ${p} -o jsonpath='{.spec.containers[*].name}')
do
echo "BEGIN logs from pod: ${p} ${c}"
kubectl -n rook-ceph logs -c ${c} ${p} | tee ${log_path}/${c}_${p}_${DATE}.logs
echo "END logs from pod: ${p} ${c}"
done
done
EOF
[root@m1 rbd]# ls /var/log/rook/ -lh
total 11M
-rw-r--r-- 1 root root 64 Dec 2 16:35 ceph-crash_rook-ceph-crashcollector-192.168.100.133-778bbd9bc5-slv77_2022-12-02.logs
-rw-r--r-- 1 root root 329 Dec 2 16:35 ceph-crash_rook-ceph-crashcollector-192.168.100.134-55bffbcd86-8db2m_2022-12-02.logs
-rw-r--r-- 1 root root 64 Dec 2 16:35 ceph-crash_rook-ceph-crashcollector-192.168.100.135-568bff4f85-ftdvx_2022-12-02.logs
-rw-r--r-- 1 root root 64 Dec 2 16:35 ceph-crash_rook-ceph-crashcollector-192.168.100.136-55fdc6f5bd-kqtgh_2022-12-02.logs
-rw-r--r-- 1 root root 64 Dec 2 16:35 ceph-crash_rook-ceph-crashcollector-192.168.100.137-9c7cb5f7-svz9z_2022-12-02.logs
-rw-r--r-- 1 root root 517 Dec 2 16:35 csi-attacher_csi-cephfsplugin-provisioner-8658f67749-jxshb_2022-12-02.logs
-rw-r--r-- 1 root root 517 Dec 2 16:34 csi-attacher_csi-cephfsplugin-provisioner-8658f67749-jxshb_.logs
-rw-r--r-- 1 root root 734 Dec 2 16:35 csi-attacher_csi-cephfsplugin-provisioner-8658f67749-whmrx_2022-12-02.logs
-rw-r--r-- 1 root root 1.0K Dec 2 16:35 csi-attacher_csi-rbdplugin-provisioner-94f699d86-bh4fv_2022-12-02.logs
-rw-r--r-- 1 root root 728 Dec 2 16:35 csi-attacher_csi-rbdplugin-provisioner-94f699d86-p6vpm_2022-12-02.logs
......
采集 OSD 信息
Ceph 里面包含有很多的配置信息,这些配置信息可以通过 socket 的方式去获取到,如 ceph --admin-daemon /var/run/ceph/mon-node-1.socket config show 即可获取到 m1 这个 mon 的配置信息,同时可以通过 config set,config get 的方式临时配置和获取到配置参数信息, rook 将节点容器化之后我们需要进入到相关的容器中去获取信息,如下
[root@m1 rbd]# kubectl -n rook-ceph exec -it rook-ceph-mon-a-6cfc46ccd8-xrmzn -- bash
[root@rook-ceph-mon-a-6cfc46ccd8-xrmzn /]# ceph --admin-daemon /var/run/ceph/ceph-mon.a.asok config show | head
{
"name": "mon.a",
"cluster": "ceph",
"admin_socket": "/var/run/ceph/ceph-mon.a.asok",
"admin_socket_mode": "",
"allow_ansi": "Terminal",
"auth_client_required": "cephx, none",
"auth_cluster_required": "cephx",
"auth_debug": "false",
"auth_mon_ticket_ttl": "43200.000000",
同样,OSD 作为一个容器的形式运行在集群中,可以进入到容器中去查看相关的信息
[root@m1 rbd]# kubectl -n rook-ceph exec -it rook-ceph-osd-1-5866f9f558-jq994 -- bash
[root@rook-ceph-osd-1-5866f9f558-jq994 /]# ls -l /var/lib/ceph/osd/ceph-1/
total 28
lrwxrwxrwx 1 ceph ceph 93 Dec 1 05:29 block -> /dev/ceph-4a84daae-a3c8-40a3-822b-100c8e47d8d2/osd-block-da31a738-a678-4aa1-b238-5ce69ba5aaa0
-rw------- 1 ceph ceph 37 Dec 1 05:29 ceph_fsid
-rw------- 1 ceph ceph 37 Dec 1 05:29 fsid
-rw------- 1 ceph ceph 55 Dec 1 05:29 keyring
-rw------- 1 ceph ceph 6 Dec 1 05:29 ready
-rw------- 1 ceph ceph 3 Dec 1 05:29 require_osd_release
-rw------- 1 ceph ceph 10 Dec 1 05:29 type
-rw------- 1 ceph ceph 2 Dec 1 05:29 whoami
[root@rook-ceph-osd-1-5866f9f558-jq994 /]# lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
|-sda1 xfs fef3e1da-62e1-41eb-b1cb-19021cce0cf5
`-sda2 LVM2_member wzFi9m-QD1s-G4Yi-SBN4-7ud9-8wYk-NGx1dS
|-centos-root xfs 9886a31d-694b-4957-ad05-247edc04dd88 /var/lib/ceph/osd/ceph-1
`-centos-swap swap 239e607c-1a07-44d5-ae89-1b415e160ff8
sdb LVM2_member 3EQj3n-Gkb8-aDVN-iTJj-JrpZ-mhjU-Yyph3G
`-ceph--4a84daae--a3c8--40a3--822b--100c8e47d8d2-osd--block--da31a738--a678--4aa1--b238--5ce69ba5aaa0
sr0 iso9660 CentOS 7 x86_64 2020-11-03-14-55-29-00
官方提供查看 OSD 信息的脚本
# Get OSD Pods
# This uses the example/default cluster name "rook"
OSD_PODS=$(kubectl get pods --all-namespaces -l \
app=rook-ceph-osd,rook_cluster=rook-ceph -o jsonpath='{.items[*].metadata.name}')
# Find node and drive associations from OSD pods
for pod in $(echo ${OSD_PODS})
do
echo "Pod: ${pod}"
echo "Node: $(kubectl -n rook-ceph get pod ${pod} -o jsonpath='{.spec.nodeName}')"
kubectl -n rook-ceph exec ${pod} -- sh -c '\
for i in /var/lib/ceph/osd/ceph-*; do
[ -f ${i}/ready ] || continue
echo -ne "-$(basename ${i}) "
echo $(lsblk -n -o NAME,SIZE ${i}/block 2> /dev/null || \
findmnt -n -v -o SOURCE,SIZE -T ${i}) $(cat ${i}/type)
done | sort -V
echo'
done
配置 pool 参数
Ceph 提供了调整 pool 的参数,即ceph osd pool set size|pg_num|pgp_num等参数,如调整副本数量
[root@m1 rbd]# ceph osd pool get testpool1 size
size: 3
[root@m1 rbd]# ceph osd pool set testpool1 size 2
set pool 13 size to 2
[root@m1 rbd]# ceph osd pool get testpool1 size
size: 2
除了副本数量之外, pool 还有一个很重要的参数是 PG 数量, PG 是 place group 的简写,和 PGP 一起代表数据的分布情况,通过 crush 算法将 PG 分布到同步的 OSD 上, OSD 上的 PG 如果分布过少的话可能会导致数据的丢失,因此需要设定一个相对合理的数值,默认已经开启了 自动调整pg 的功能,如下
[root@m1 rbd]# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE
device_health_metrics 0 3.0 249.9G 0.0000 1.0 1 on
replicapool 1454M 3.0 249.9G 0.0171 1.0 32 on
myfs-metadata 3252k 3.0 249.9G 0.0000 4.0 32 on
myfs-data0 108.4M 3.0 249.9G 0.0013 1.0 32 on
my-store.rgw.control 0 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.meta 7525 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.log 222.5k 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.buckets.index 830.3k 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.buckets.non-ec 1352 3.0 249.9G 0.0000 1.0 8 on
.rgw.root 3927 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.buckets.data 3314 3.0 249.9G 0.0000 1.0 32 on
evescn_test 900.9k 3.0 249.9G 0.0000 1.0 32 on
testpool1 0 2.0 249.9G 0.0000 1.0 16 on
testpool2 0 2.0 249.9G 0.0000 1.0 16 on
Ceph 会根据数据的情况,自动调整的 PG 的的大小,一般而言生产中需要手动设定 PG 的大小,因此需要将其关闭
[root@m1 rbd]# ceph osd pool get testpool1 pg_autoscale_mode
pg_autoscale_mode: on
[root@m1 rbd]# ceph osd pool set testpool1 pg_autoscale_mode off
set pool 13 pg_autoscale_mode to off
[root@m1 rbd]# ceph osd pool get testpool1 pg_autoscale_mode
pg_autoscale_mode: off
关闭之后,则需要手动设定 PG 和 PGP 的数量
[root@m1 rbd]# ceph osd pool set testpool1 pg_num 32
set pool 13 pg_num to 32
[root@m1 rbd]# ceph osd pool set testpool1 pgp_num 32
set pool 13 pgp_num to 32
[root@m1 rbd]# ceph osd pool autoscale-status
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE
device_health_metrics 0 3.0 249.9G 0.0000 1.0 1 on
replicapool 1454M 3.0 249.9G 0.0171 1.0 32 on
myfs-metadata 3252k 3.0 249.9G 0.0000 4.0 32 on
myfs-data0 108.4M 3.0 249.9G 0.0013 1.0 32 on
my-store.rgw.control 0 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.meta 7525 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.log 222.5k 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.buckets.index 830.3k 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.buckets.non-ec 1352 3.0 249.9G 0.0000 1.0 8 on
.rgw.root 3927 3.0 249.9G 0.0000 1.0 8 on
my-store.rgw.buckets.data 3314 3.0 249.9G 0.0000 1.0 32 on
evescn_test 900.9k 3.0 249.9G 0.0000 1.0 32 on
testpool1 0 2.0 249.9G 0.0000 1.0 32 off
testpool2 0 2.0 249.9G 0.0000 1.0 32 on
调整 mon 参数
调整Ceph的参数一般有两种方式:
- 临时调整,通过
config set的方式做调整,可以在线调整Ceph的参数,这种调整是临时有效 - 永久生效,调整
ceph.conf置文件,调整后需要重启各个组件进程
先来看一个例子,创建 pool 的时候都会分配 pg_num 和 pgp_num 数量,这个值默认是 32
[root@m1 rbd]# kubectl -n rook-ceph exec -it rook-ceph-mon-a-6cfc46ccd8-xrmzn -- bash
[root@rook-ceph-mon-a-6cfc46ccd8-xrmzn /]# ceph --admin-daemon /var/run/ceph/ceph-mon.a.asok config show | grep pg_num
"mgr_debug_aggressive_pg_num_changes": "false",
"mon_max_pool_pg_num": "65536",
"mon_warn_on_pool_pg_num_not_power_of_two": "true",
"osd_pool_default_pg_num": "32", # 每个 pool 默认的 pg_num 为 32
"rgw_rados_pool_pg_num_min": "8",
此时创建一个 pool 其默认的 pg_num 和 pgp_num 是 32 ,可以通过如下的例子来验证
[root@m1 rbd]# ceph osd pool create pool1
pool 'pool1' created
[root@m1 rbd]# ceph osd pool get pool1 pg_num
pg_num: 32
[root@m1 rbd]# ceph osd pool get pool1 pgp_num
pgp_num: 32
调整参数,将其值从 32 修改为 16
[root@rook-ceph-mon-a-6cfc46ccd8-xrmzn /]# ceph --admin-daemon /var/run/ceph/ceph-mon.a.asok config set osd_pool_default_pg_num 16
{
"success": "osd_pool_default_pg_num = '16' (not observed, change may require restart) "
}
相同的方法,修改另外两个 mon 的参数,修改完毕后测试如下
[root@m1 rbd]# ceph osd pool create pool2
pool 'pool1' created
[root@m1 rbd]# ceph osd pool get pool2 pg_num
pg_num: 16
[root@m1 rbd]# ceph osd pool get pool2 pgp_num
pgp_num: 16
防止池误删除
默认可以删除 pool ,其通过 mon_allow_pool_delete 参数的开关进行控制,默认是 true ,因此可以删除 pool
[root@rook-ceph-mon-a-6cfc46ccd8-xrmzn /]# ceph --admin-daemon /var/run/ceph/ceph-mon.a.asok config show | grep delete
"mon_allow_pool_delete": "true",
因此可以将 pool 删除
[root@m1 rbd]# ceph osd pool rm pool1 pool1 --yes-i-really-really-mean-it
pool 'pool1' removed
为了防止误删除,将开关关闭,3 个 mon 服务都需要执行
[root@rook-ceph-mon-a-6cfc46ccd8-xrmzn /]# ceph --admin-daemon /var/run/ceph/ceph-mon.a.asok config set mon_allow_pool_delete false
{
"success": "mon_allow_pool_delete = 'false' "
}
关闭之后再次删除时,会提示 deletion 禁用而导致无法删除
[root@m1 rbd]# ceph osd pool rm pool2 pool2 --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
制定 Ceph 配置
config set 的方式是临时有效的,如果需要使配置永久生效需要修改 ceph.conf 配置文件,使配置能够永久生效,在 rook 中需要通过修改 rook-config-override 这个 configmap 实现配置的管理,如:
[root@m1 rbd]# cat overide.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: rook-config-override
namespace: rook-ceph
data:
config: |
[global]
osd crush update on start = false
osd pool default size = 2
mon_allow_pool_delete = true
osd_pool_default_pg_num = 64
将其 apply 到集群中
[root@m1 rbd]# kubectl apply -f overide.yaml
Warning: resource configmaps/rook-config-override is missing the kubectl.kubernetes.io/last-applied-configuration annotation which is required by kubectl apply. kubectl apply should only be used on resources created declaratively by either kubectl create --save-config or kubectl apply. The missing annotation will be patched automatically.
configmap/rook-config-override configured
查看配置文件
[root@m1 rbd]# kubectl get configmaps -n rook-ceph rook-config-override -o yaml
apiVersion: v1
data:
config: |
[global]
osd crush update on start = false
osd pool default size = 2
mon_allow_pool_delete = true
osd_pool_default_pg_num = 64
kind: ConfigMap
......
重启组件技巧
修改 rook-config-override 之后,容器中的 configmap 会自动去读区到 configmap 配置文件的内容,如下
[root@rook-ceph-mon-a-6cfc46ccd8-xrmzn /]# cat /etc/ceph/ceph.conf
[global]
osd crush update on start = false
osd pool default size = 2
mon_allow_pool_delete = true
osd_pool_default_pg_num = 64
然而读取之后其配置并未生效,如果需要使配置生效,需要将对应的组件做重启,包括 MON,MGR,RGW,MDS,OSD 等,重启的时候需要注意单次不要重启一个 pods 进程,确保 pods 启动完毕之后,结合 ceph -s 观察状态,待 ceph 状态正常之后再重启其他的进程,如下重启 mon 的进程
[root@m1 rbd]# kubectl -n rook-ceph delete pods rook-ceph-mon-a-6cfc46ccd8-xrmzn
观察 Ceph 集群的状态,待 Ceph 状态正常之后再重启另外的 monitor 进程
[root@m1 rbd]# ceph -s
cluster:
id: 17a413b5-f140-441a-8b35-feec8ae29521
health: HEALTH_WARN
2 daemons have recently crashed
services:
mon: 3 daemons, quorum b,d,e (age 3s)
mgr: a(active, since 61m)
mds: myfs:2 {0=myfs-d=up:active,1=myfs-b=up:active} 2 up:standby-replay
osd: 5 osds: 5 up (since 4m), 5 in (since 26h)
rgw: 2 daemons active (my.store.a, my.store.b)
task status:
data:
pools: 15 pools, 289 pgs
objects: 910 objects, 1.5 GiB
usage: 10 GiB used, 240 GiB / 250 GiB avail
pgs: 289 active+clean
io:
client: 2.1 KiB/s rd, 4 op/s rd, 0 op/s wr
此外,重启 OSD 需要特别注意,其涉及到数据的迁移,因此需要确保重启过程中 ceph 的状态为 active+clean 才能继续下一步骤的重启,避免因为重启而导致数据大规模移动影响正常的业务,如下是官网提供的重启组件建议
- mons: ensure all three mons are online and healthy before restarting each mon pod, one at a time.
- mgrs: the pods are stateless and can be restarted as needed, but note that this will disrupt the Ceph dashboard during restart.
- OSDs: restart your the pods by deleting them, one at a time, and running
ceph -sbetween each restart to ensure the cluster goes back to “active/clean” state. - RGW: the pods are stateless and can be restarted as needed.
- MDS: the pods are stateless and can be restarted as needed.
重启完毕 mon,mgr,rgw,mds,osd 组件之后,查看配置文件,可以看到已经生效
[root@m1 rbd]# kubectl -n rook-ceph exec -it rook-ceph-mon-b-7486b4b679-hbsng -- bash
[root@rook-ceph-mon-b-7486b4b679-hbsng /]# ceph --admin-daemon /var/run/ceph/ceph-mon.b.asok config show | grep osd_pool_default_pg_num
"osd_pool_default_pg_num": "64",
[root@rook-ceph-mon-b-7486b4b679-hbsng /]# ceph --admin-daemon /var/run/ceph/ceph-mon.b.asok config show | grep "osd_pool_default_size"
"osd_pool_default_size": "2",
Ceph 调优实践
apiVersion: v1
kind: ConfigMap
metadata:
name: rook-config-override
namespace: rook-ceph
data:
config: |
[global]
osd crush update on start = false
osd pool default size = 2
mon_allow_pool_delete = true
osd_pool_default_pg_num = 32
mon_max_pg_per_osd = 250 # 每个osd上最多PG数量,超过则告警
mon_osd_full_ratio = 0.95 # osd利用率达到95%时数据无法写入
mon_osd_nearfull_ratio = 0.85 # 接近写满时告警
[osd]
osd_recovery_op_priority = 1 # osd数据恢复时优先级,默认为3
osd_recovery_max_active = 1 # osd同时恢复时pg的数量,默认是0
osd_max_backfills = 1 # backfills数据填充的数量
osd_recovery_max_chunk = 1048576 # 恢复时数据块大小,默认8388608
osd_scrub_begin_hour = 1 # scrub一致性校验开始的时间,默认为0
osd_scrub_end_hour = 6 # scrub一致性校验结束的时间,默认为24
调整 CRUSH 结构
crushmap 是 Ceph 决定数据分布的方式,一把采用默认的 crushmap 即可,有些场景需要做调整,如:
- 数据分布:如SSD+HDD融合环境,需要将SSD资源池和HDD资源池分开,给两种不同的业务混合使用
- 权重分配:OSD默认会根据容量分配对应的weight,但数据不是绝对的平均,容量不平均的时候可以调整
- OSD亲和力:调整OSD数据主写的亲和力机制
数据的分布,如混合场景,调整相对复杂,可以参考此博客
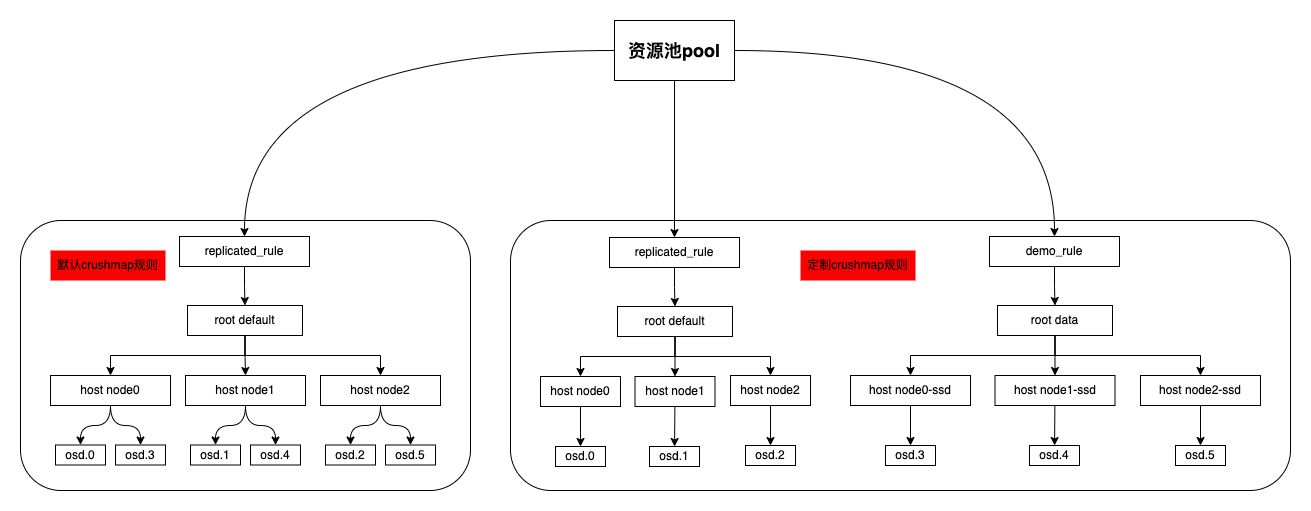
如某个 OSD 利用率过高,达到 85% 的时候会提示 nearfull ,这个时候需要扩容 OSD 到集群中,如果其他的 OSD 利用率不高,则可以根据需要调整 OSD 的权重,触发数据的重新分布,如下:
[root@m1 rbd]# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.04880 1.00000 50 GiB 1.9 GiB 937 MiB 600 KiB 1023 MiB 48 GiB 3.83 0.96 172 up
1 hdd 0.04880 1.00000 50 GiB 1.9 GiB 967 MiB 732 KiB 1023 MiB 48 GiB 3.89 0.98 178 up
2 hdd 0.04880 1.00000 50 GiB 2.2 GiB 1.2 GiB 369 KiB 1024 MiB 48 GiB 4.48 1.12 160 up
3 hdd 0.04880 1.00000 50 GiB 1.9 GiB 909 MiB 2.2 MiB 1022 MiB 48 GiB 3.78 0.95 185 up
4 hdd 0.04880 1.00000 50 GiB 2.0 GiB 1001 MiB 2.1 MiB 1022 MiB 48 GiB 3.96 0.99 172 up
TOTAL 250 GiB 10 GiB 5.0 GiB 5.9 MiB 5.0 GiB 240 GiB 3.99
MIN/MAX VAR: 0.95/1.12 STDDEV: 0.25
[root@m1 rbd]# ceph osd crush reweight osd.3 0.8
reweighted item id 3 name 'osd.3' to 0.8 in crush map
[root@m1 rbd]# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.04880 1.00000 50 GiB 1.9 GiB 937 MiB 600 KiB 1023 MiB 48 GiB 3.83 0.96 173 up
1 hdd 0.04880 1.00000 50 GiB 1.9 GiB 967 MiB 732 KiB 1023 MiB 48 GiB 3.89 0.98 167 up
2 hdd 0.04880 1.00000 50 GiB 2.2 GiB 1.2 GiB 369 KiB 1024 MiB 48 GiB 4.48 1.12 170 up
3 hdd 0.79999 1.00000 50 GiB 1.9 GiB 909 MiB 2.2 MiB 1022 MiB 48 GiB 3.78 0.95 206 up
4 hdd 0.04880 1.00000 50 GiB 2.0 GiB 1001 MiB 2.1 MiB 1022 MiB 48 GiB 3.96 0.99 151 up
TOTAL 250 GiB 10 GiB 5.0 GiB 5.9 MiB 5.0 GiB 240 GiB 3.99
调整之后,会自动的做数据的 rebalance
[root@m1 rbd]# ceph -s
cluster:
id: 17a413b5-f140-441a-8b35-feec8ae29521
health: HEALTH_WARN
Degraded data redundancy: 815/2730 objects degraded (29.853%), 72 pgs degraded
2 daemons have recently crashed
services:
mon: 3 daemons, quorum b,d,e (age 8m)
mgr: a(active, since 69m)
mds: myfs:2 {0=myfs-d=up:active,1=myfs-b=up:active} 2 up:standby-replay
osd: 5 osds: 5 up (since 12m), 5 in (since 26h); 57 remapped pgs
rgw: 2 daemons active (my.store.a, my.store.b)
task status:
data:
pools: 15 pools, 289 pgs
objects: 910 objects, 1.5 GiB
usage: 10 GiB used, 240 GiB / 250 GiB avail
pgs: 815/2730 objects degraded (29.853%)
465/2730 objects misplaced (17.033%)
190 active+clean
41 active+recovery_wait+degraded
31 active+recovery_wait+undersized+degraded+remapped
24 active+remapped+backfill_wait
2 active+recovery_wait+remapped
1 active+recovering
io:
recovery: 0 B/s, 2 keys/s, 0 objects/s
定制 OSD 网络
Ceph 提供了两个不同的网络,用于不同的功能:
public network:业务网络,用于连接Ceph集群建立数据通道cluster network:数据网络,用于Ceph内部的心跳,数据同步
apiVersion: v1
data:
config: |
[global]
# override配置文件中进行设置
public network = 10.0.7.0/24
cluster network = 10.0.10.0/24
public addr = ""
cluster addr = ""
默认这两个网络集成在一起,如果有两张不同的网卡,可以将其进行分开,首先需要将网络设置为 hostNetwork , hostNetwork 意味着容器网络和宿主机网络位于同一个网络类型,这个调整只能在 rook 初始化集群的时候做调整,配置位于 cluster.yaml 文件
[root@m1 rbd]# cd ../../
[root@m1 ceph]# vim cluster.yaml
71 network:
72 # enable host networking
73 #provider: host
调整故障域
Ceph 支持设置资源池的故障域,何为故障域?故障域是指当出现异常时能容忍的范围, Ceph 支持多种不同类型的故障域,常⻅的故障域有:
datacenter:数据中心级别,如三个副本,分别落在三个不同的数据中心rack:机架级别,如三个副本,分别落在三个不同的数据机柜host:宿主机级别,如三个副本,分别落在三个不同的宿主机,默认规则osd:磁盘级别,如三个副本,分别落在三个不同的磁盘上
创建 pool 的时候可以定义 pool 所使用的故障域,如下创建一个 pool 所使用的故障域为 osd
#修改配置
[root@m1 ceph]# grep -v "[.*#]" pool.yaml
apiVersion: ceph.rook.io/v1
kind: CephBlockPool
metadata:
name: test-domain
namespace: rook-ceph
spec:
failureDomain: osd #故障域
replicated:
size: 3
requireSafeReplicaSize: true
创建之后,可以通过如下命令进行校验
[root@m1 ceph]# kubectl apply -f pool.yaml
cephblockpool.ceph.rook.io/test-domain created
# 查看底层 pool 信息
[root@m1 ceph]# ceph osd lspools
1 device_health_metrics
2 replicapool
3 myfs-metadata
4 myfs-data0
5 my-store.rgw.control
6 my-store.rgw.meta
7 my-store.rgw.log
8 my-store.rgw.buckets.index
9 my-store.rgw.buckets.non-ec
10 .rgw.root
11 my-store.rgw.buckets.data
12 evescn_test
13 testpool1
14 testpool2
16 pool2
17 test-domain
# 查看 crush_rule 规则
[root@m1 ceph]# ceph osd pool get test-domain crush_rule
crush_rule: test-domain
# 查看故障域类型
[root@m1 ceph]# ceph osd crush rule dump test-domain
{
"rule_id": 12,
"rule_name": "test-domain",
"ruleset": 12,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "choose_firstn",
"num": 0,
"type": "osd" # 故障域类型
},
{
"op": "emit"
}
]
}
对于 osd 的故障域来说,其将数据分布在三个不同的磁盘上,不管这三个磁盘是否落在同个宿主机上,因此存在有数据丢失的⻛险,基于各种因素需要调整故障域时,可以通过如下的方法进行调整,首先需要创建一个故障域关联的规则
[root@m1 ceph]# ceph osd crush rule create-replicated happylau-rule default host
[root@m1 ceph]# ceph osd crush rule dump happylau-rule
{
"rule_id": 13,
"rule_name": "happylau-rule",
"ruleset": 13,
"type": 1,
"min_size": 1,
"max_size": 10,
"steps": [
{
"op": "take",
"item": -1,
"item_name": "default"
},
{
"op": "chooseleaf_firstn",
"num": 0,
"type": "host" # 创建 happylau-rule 的规则,故障域为 host
},
{
"op": "emit"
}
]
}
创建 rule 规则之后,将其应用在对应的 pool 上
[root@m1 ceph]# ceph osd pool set test-domain crush_rule happylau-rule
set pool 17 crush_rule to happylau-rule
[root@m1 ceph]# ceph osd pool get test-domain crush_rule
crush_rule: happylau-rule

 浙公网安备 33010602011771号
浙公网安备 33010602011771号