11 Prometheus 监控系统(转载)
Prometheus 监控系统
Prometheus 与 Ceph
Dashboard 能够提供部分 Ceph 的监控能力,然而如果要更加细化的监控能力和自定义监控则无法实现, prometheus 是新一代的监控系统,能够提供更加完善的监控指标和告警能力,一个完善的 prometheus 系统通常包含:
- exporter:监控agent端,用于上报,mgr默认已经提供,内置有监控指标
- promethues:监控服务端,存储监控数据,提供查询,监控,告警,展示等能力;
- grafana:从prometheus中获取监控指标并通过模版进行展示

exporters 客户端
Rook 默认启用了 exporters 客户端,以 rook-ceph-mgr service 的方式提供 9283 端口作为 agent 端,默认是 ClusterIP ,可以启用为 NodePort 给外部访问,如下开启
[root@m1 ~]# kubectl -n rook-ceph get svc -l app=rook-ceph-mgr
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr ClusterIP 10.68.82.138 <none> 9283/TCP 3d
rook-ceph-mgr-dashboard ClusterIP 10.68.153.82 <none> 8443/TCP 3d
rook-ceph-mgr-dashboard-external-https NodePort 10.68.41.90 <none> 8443:35832/TCP 155m
[root@m1 ~]# kubectl -n rook-ceph edit svc rook-ceph-mgr
# Please edit the object below. Lines beginning with a '#' will be ignored,
# and an empty file will abort the edit. If an error occurs while saving this file will be
# reopened with the relevant failures.
#
apiVersion: v1
kind: Service
metadata:
creationTimestamp: "2022-11-24T03:24:57Z"
labels:
app: rook-ceph-mgr
rook_cluster: rook-ceph
name: rook-ceph-mgr
namespace: rook-ceph
ownerReferences:
- apiVersion: ceph.rook.io/v1
blockOwnerDeletion: true
controller: true
kind: CephCluster
name: rook-ceph
uid: 8279c0cb-e44f-4af6-8689-115025bb2940
resourceVersion: "406301"
uid: 88c71e2d-9a07-441f-a3ad-25f00e551806
spec:
clusterIP: 10.68.82.138
clusterIPs:
- 10.68.82.138
ports:
- name: http-metrics
port: 9283
protocol: TCP
targetPort: 9283
selector:
app: rook-ceph-mgr
rook_cluster: rook-ceph
sessionAffinity: None
type: NodePort
status:
loadBalancer: {}
[root@m1 ~]# kubectl -n rook-ceph get svc -l app=rook-ceph-mgr
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr NodePort 10.68.82.138 <none> 9283:38769/TCP 3d
rook-ceph-mgr-dashboard ClusterIP 10.68.153.82 <none> 8443/TCP 3d
rook-ceph-mgr-dashboard-external-https NodePort 10.68.41.90 <none> 8443:35832/TCP 156m
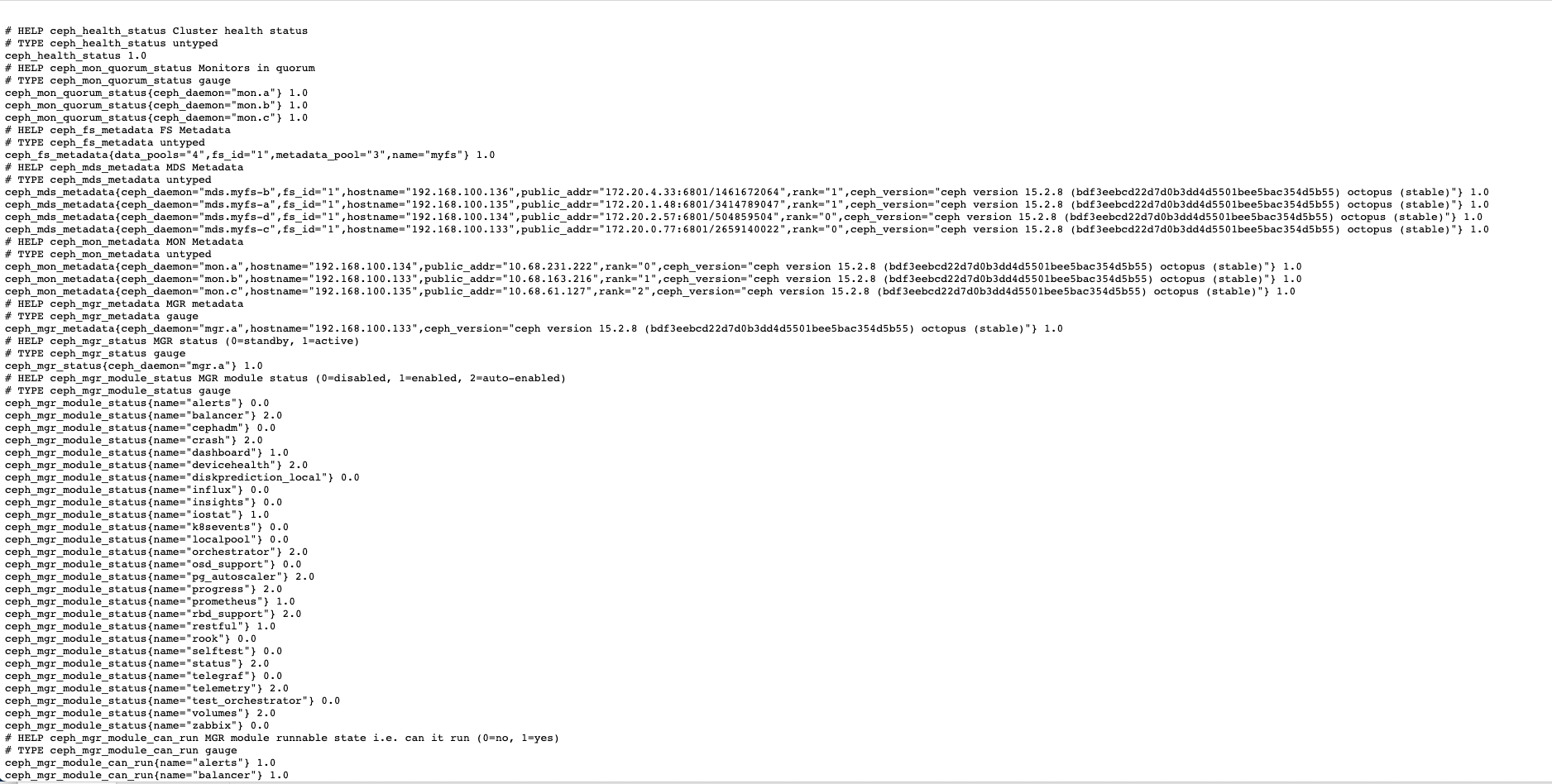
修改后可以通过控制台的打开 agent 的 metrics 地址,可以查看到有 mgr exporter 所上报的监控数据,非常详细,能够覆盖大部分所需的监控指标和数据
[root@m1 ~]# curl http://m1:38769/metrics
# HELP ceph_health_status Cluster health status
# TYPE ceph_health_status untyped
ceph_health_status 1.0
# HELP ceph_mon_quorum_status Monitors in quorum
# TYPE ceph_mon_quorum_status gauge
ceph_mon_quorum_status{ceph_daemon="mon.a"} 1.0
ceph_mon_quorum_status{ceph_daemon="mon.b"} 1.0
ceph_mon_quorum_status{ceph_daemon="mon.c"} 1.0
# HELP ceph_fs_metadata FS Metadata
# TYPE ceph_fs_metadata untyped
ceph_fs_metadata{data_pools="4",fs_id="1",metadata_pool="3",name="myfs"} 1.0
# HELP ceph_mds_metadata MDS Metadata
# TYPE ceph_mds_metadata untyped
......
浏览器访问:http://m1:38769/metrics
部署 Prometheus Operator
Prometheus 以容器化的形式运行在 kubernetes ,这个工作将会很复杂,涉及到多个组件的配置和集成,幸运的是,社区已经提供了 Operator 给我们使用,我们直接使用即可,如下是部署的方式:
[root@m1 ceph]# kubectl apply -f https://ghproxy.com/https://raw.githubusercontent.com/coreos/prometheus-operator/v0.40.0/bundle.yaml
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
serviceaccount/prometheus-operator created
service/prometheus-operator created
运行之后会自动部署一个 prometheus-operator 的容器,这个容器是 prometheus 的服务端容器
[root@m1 ceph]# kubectl get pods
NAME READY STATUS RESTARTS AGE
prometheus-operator-7ccf6dfc8-sdhdp 1/1 Running 0 81s
部署 Prometheus Instances
[root@m1 ceph]# cd monitoring/
[root@m1 monitoring]# kubectl apply -f prometheus.yaml
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus-rules created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created
prometheus.monitoring.coreos.com/rook-prometheus created
[root@m1 monitoring]# kubectl apply -f prometheus-service.yaml
service/rook-prometheus created
[root@m1 monitoring]# kubectl apply -f service-monitor.yaml
servicemonitor.monitoring.coreos.com/rook-ceph-mgr created
- 查看部署信息
[root@m1 monitoring]# kubectl -n rook-ceph get pods -l app=prometheus
NAME READY STATUS RESTARTS AGE
prometheus-rook-prometheus-0 3/3 Running 1 100s
[root@m1 monitoring]# kubectl -n rook-ceph get svc | grep prom
prometheus-operated ClusterIP None <none> 9090/TCP 2m42s
rook-prometheus NodePort 10.68.99.134 <none> 9090:30900/TCP 2m34s
[root@m1 monitoring]# kubectl -n rook-ceph get ServiceMonitor
NAME AGE
rook-ceph-mgr 3m19s
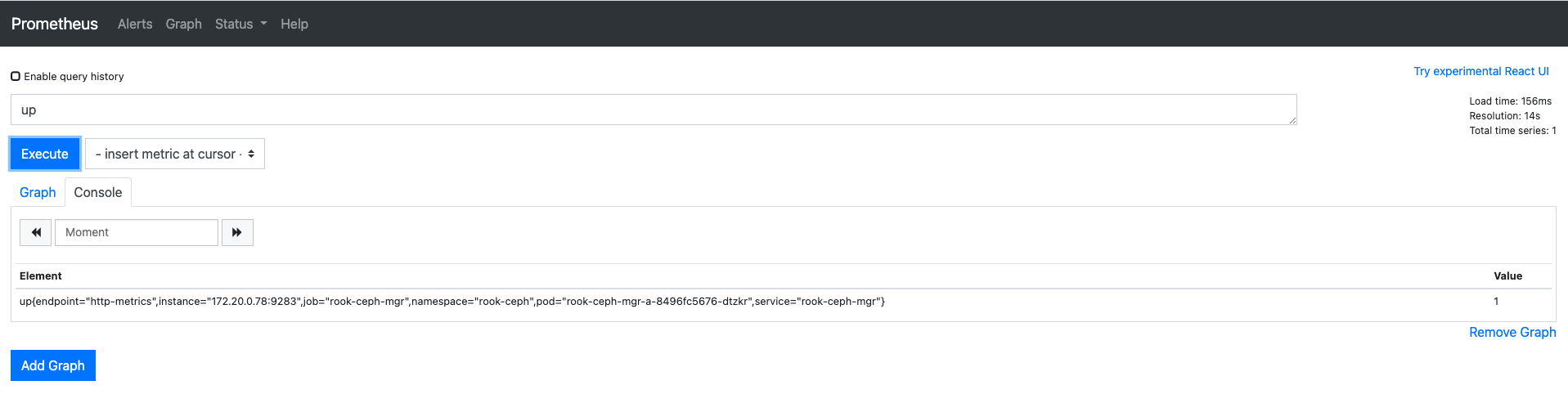
Prometheus 控制台
proemthesu 默认提供了一个 9090 端口可以供访问,通过该端口可以访问到 prometheus 的控制台, service-monitor 部署了一个 NodePort 的服务,通过 nodeport 的方式可以访问到 prometheus 的控制台,访问端口为 30900 ,如下:
[root@m1 monitoring]# kubectl -n rook-ceph get svc | grep rook-prom
rook-prometheus NodePort 10.68.99.134 <none> 9090:30900/TCP 6m
打开控制台可以进行数据的查询

安装 grafana 服务端
prometheus 将 exporter 上报的监控数据进行统一的存储,在 prometheus 中可以通过 PromSQL 查询监控数据并进行数据的展示, prometheus 提供了比较简陋的图形界面,这些图形界面显然无法满足到日常实际的需求,幸运的是, grafana 是这方面的高手,因此我们通过 grafana 进行数据的展示, grafana 支持将prometheus做为一个后端进行展示,如下是安装的方法:
[root@node0 prometheus]# yum install https://mirrors.cloud.tencent.com/grafana/yum/rpm/grafana-9.2.3-1.x86_64.rpm
[root@m1 monitoring]# systemctl enable grafana-server --now
Created symlink from /etc/systemd/system/multi-user.target.wants/grafana-server.service to /usr/lib/systemd/system/grafana-server.service.
[root@m1 monitoring]# ss -tnlp | grep grafana
LISTEN 0 32768 [::]:3000 [::]:* users:(("grafana-server",pid=99022,fd=8))
配置 grafana 数据源
grafana 是一个数据展示的开源工具,其数据需要依托于后端的数据源(Data Sources),因此需要配置数据源,以便更好和 grafana 进行集成,如下是配置 prometheus 和 grafana 进行集成,需要 prometheus 的 9090 端口
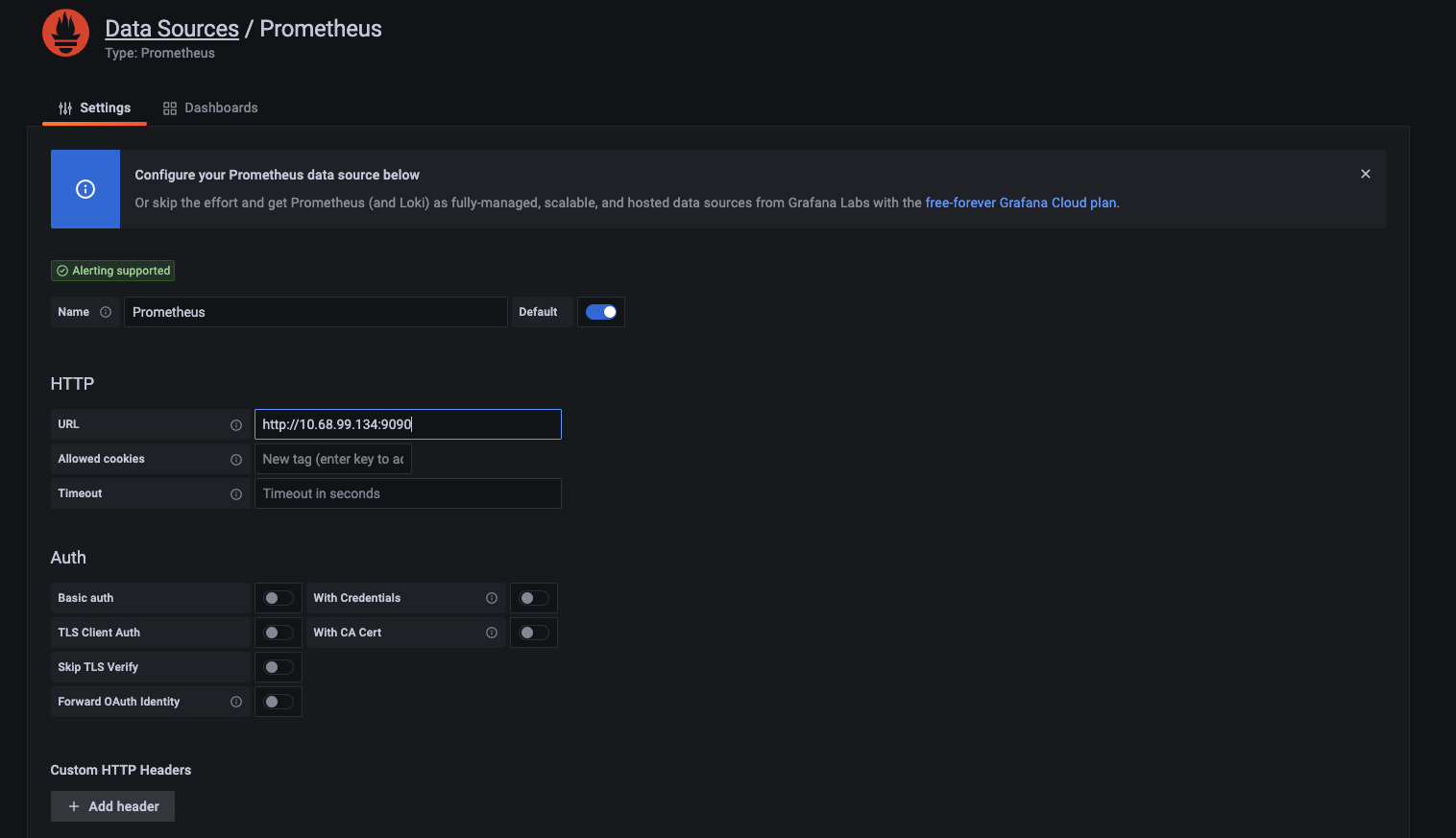
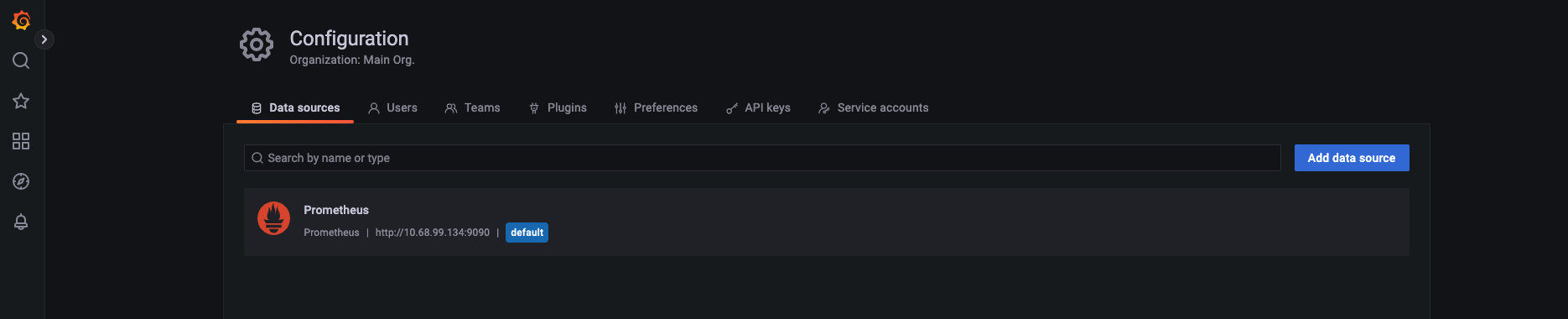
配置 Grafana 展板
grafana 如何展示 prometheus 的数据呢?需要编写 PromSQL 实现和 prometheus 集成,幸好已经有很多定义好的 json 模版,我们直接使用即可,下载 json 后将其 import 到 grafana 中
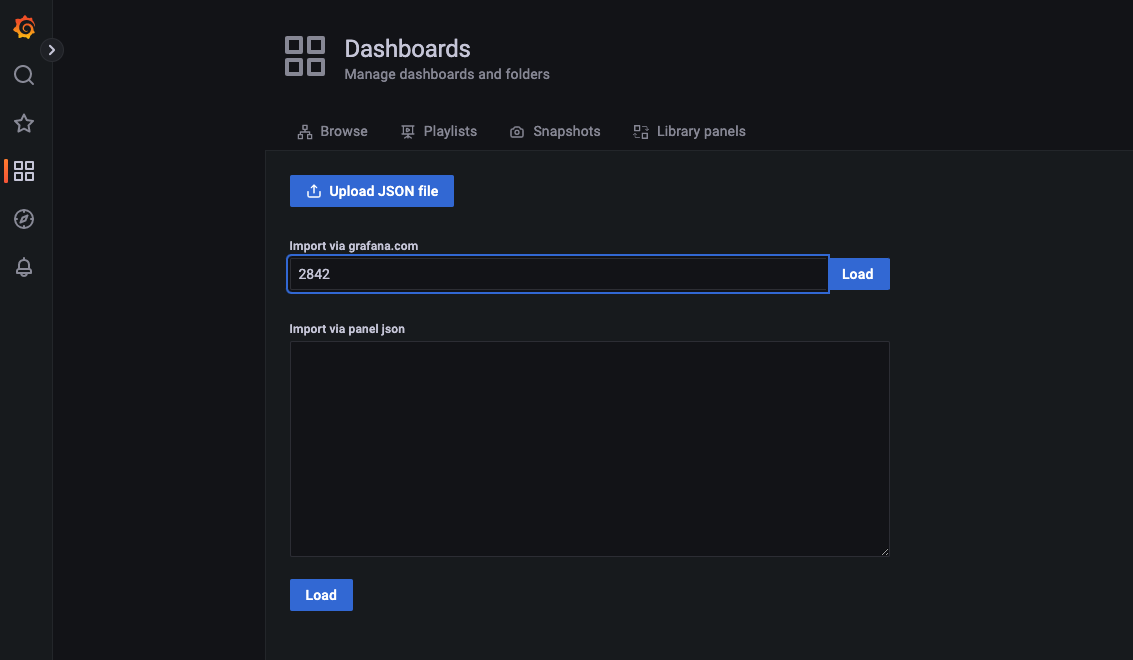
Grafana 监控展示
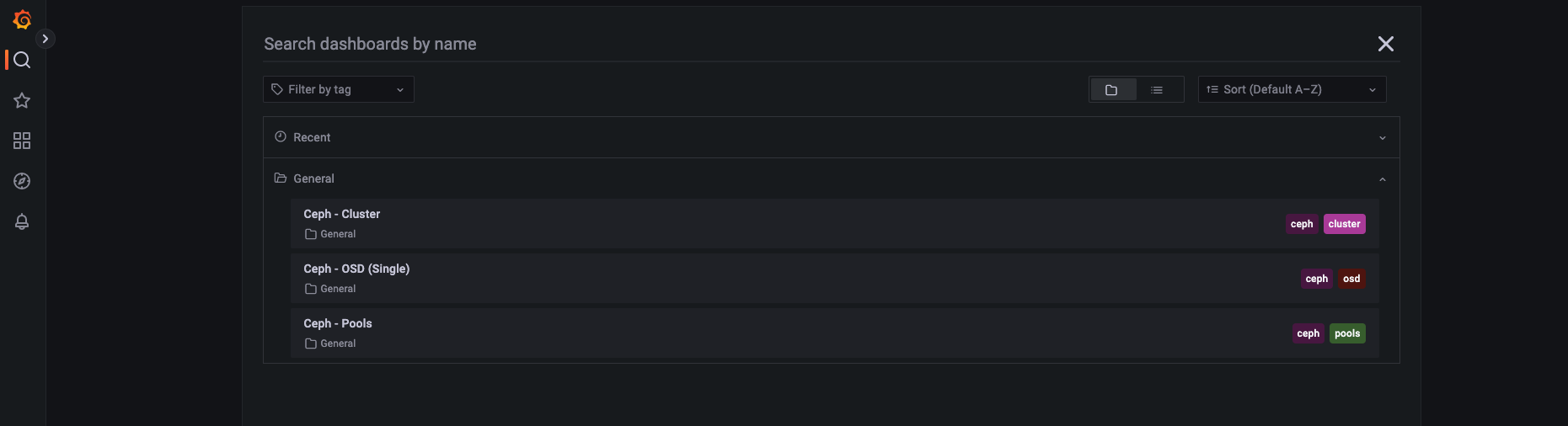
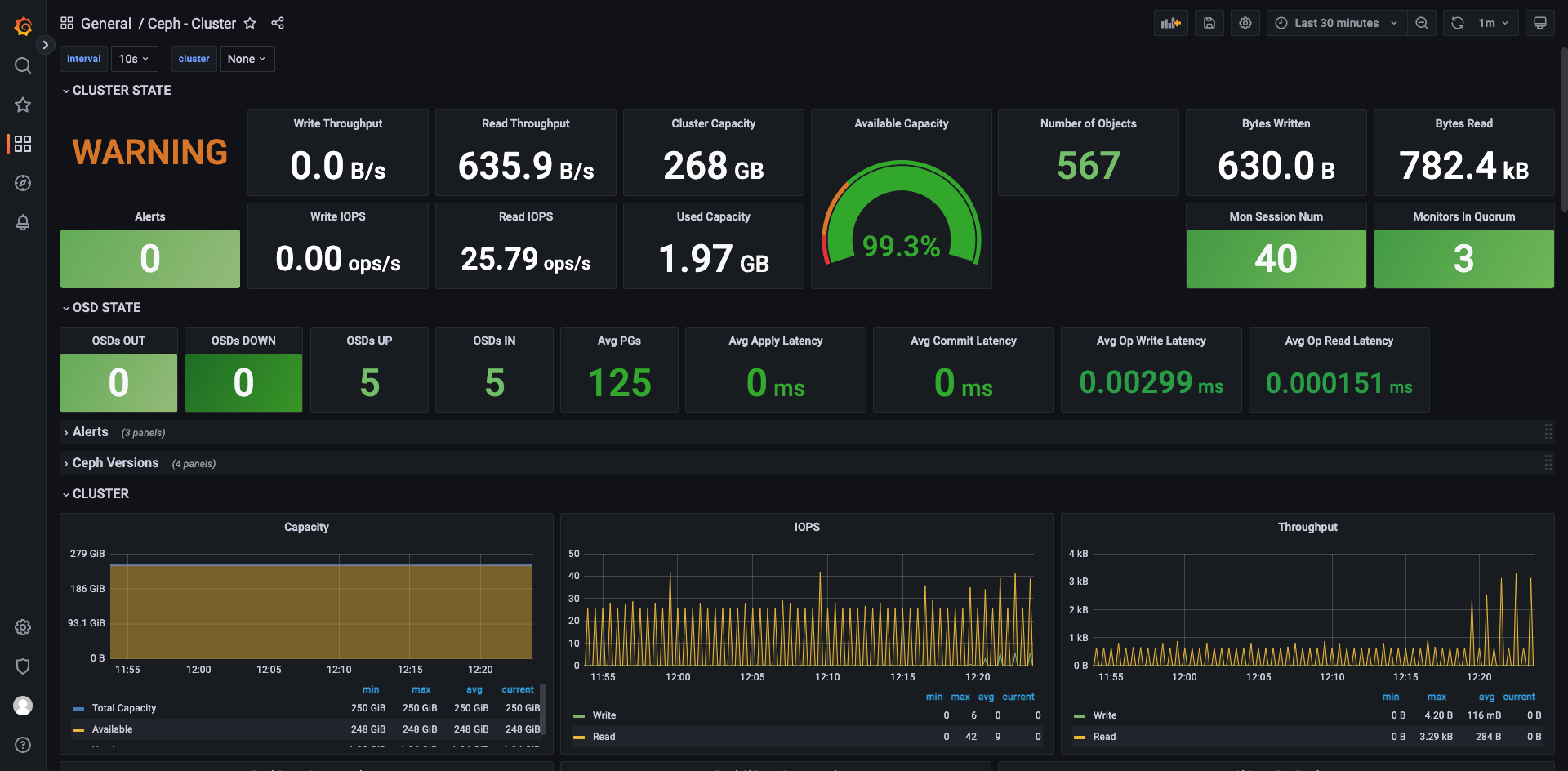
Cluster 监控展示
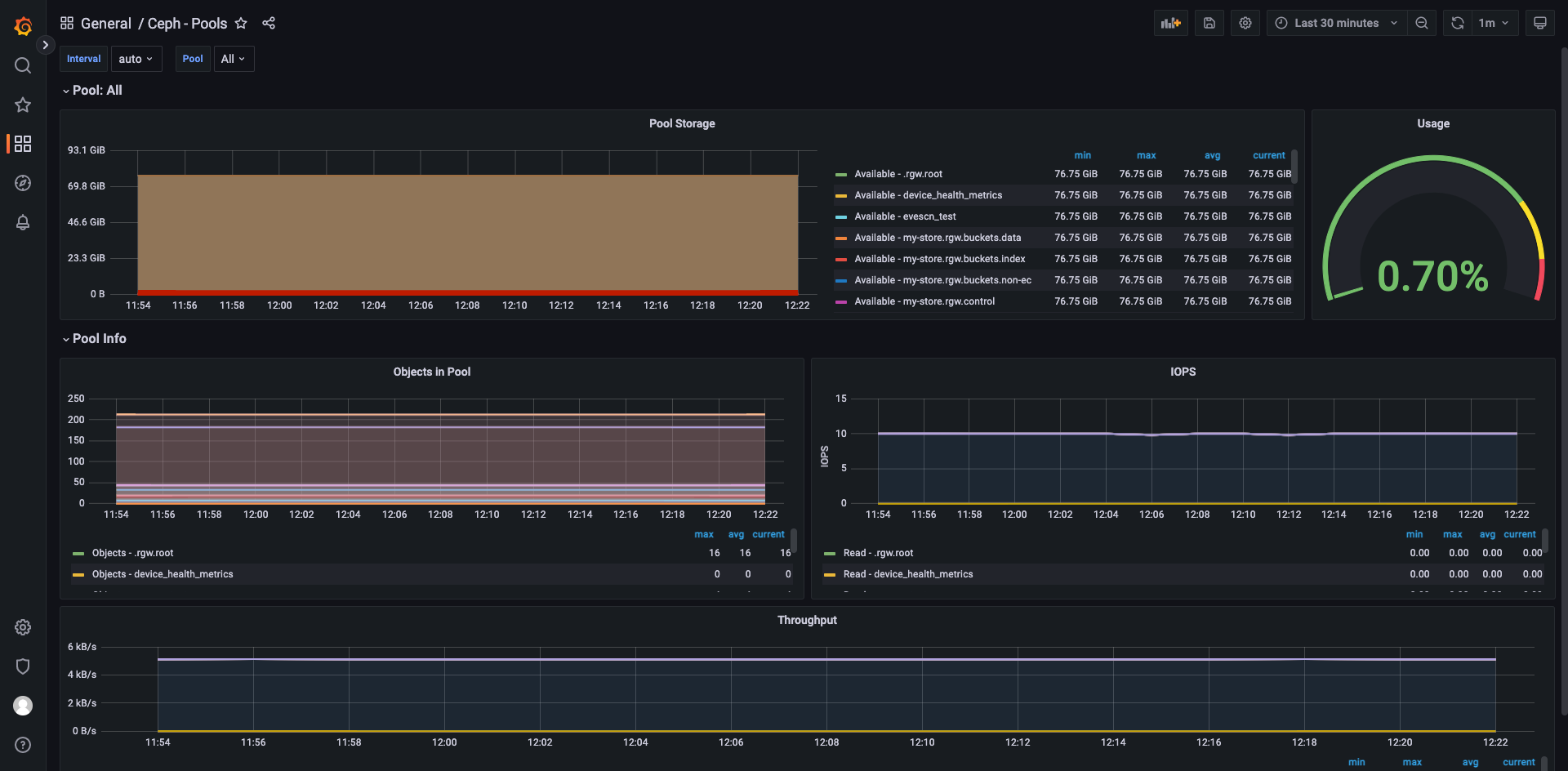
Pool 的监控展示
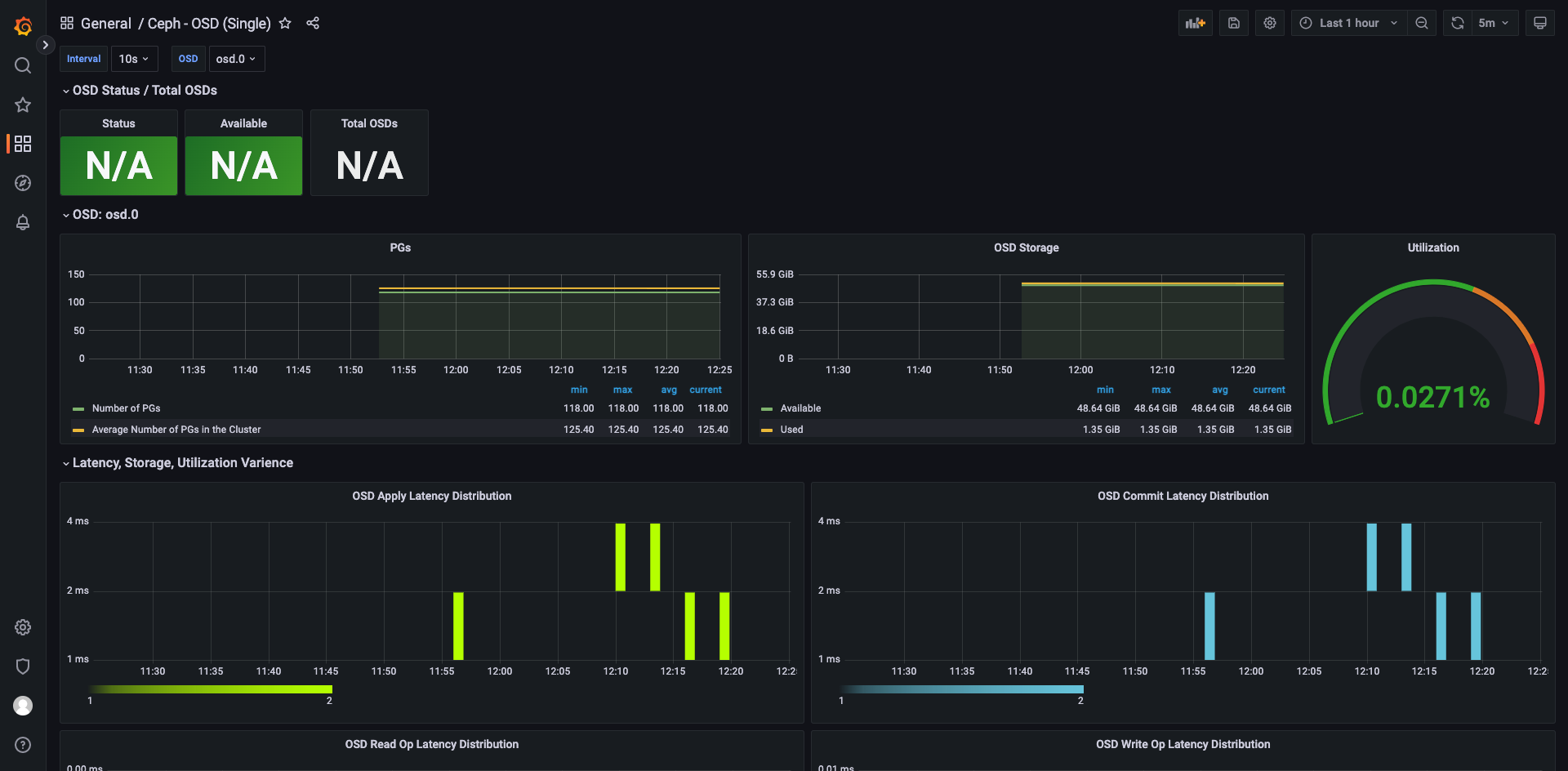
OSD 监控展示
配置 Prometheus Alerts
Create the RBAC rules to enable monitoring.
[root@m1 monitoring]# kubectl create -f rbac.yaml
role.rbac.authorization.k8s.io/rook-ceph-monitor created
rolebinding.rbac.authorization.k8s.io/rook-ceph-monitor created
role.rbac.authorization.k8s.io/rook-ceph-metrics created
rolebinding.rbac.authorization.k8s.io/rook-ceph-metrics created
Make following changes to your CephCluster object (e.g., cluster.yaml).
[root@m1 monitoring]# vim ../cluster.yaml
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
[...]
spec:
[...]
monitoring:
enabled: true # 启动配置,默认为 false
rulesNamespace: "rook-ceph"
[...]
(Where rook-ceph is the CephCluster name / namespace)
Deploy or update the CephCluster object.
[root@m1 monitoring]# kubectl apply -f ../cluster.yaml
cephcluster.ceph.rook.io/rook-ceph configured
集群添加告警信息
[root@m1 monitoring]# cat prometheus-ceph-v14-rules.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: rook-prometheus
role: alert-rules
name: prometheus-ceph-rules
namespace: rook-ceph
spec:
groups:
- name: ceph.rules
rules:
- expr: |
kube_node_status_condition{condition="Ready",job="kube-state-metrics",status="true"} * on (node) group_right() max(label_replace(ceph_disk_occupation{job="rook-ceph-mgr"},"node","$1","exported_instance","(.*)")) by (node)
record: cluster:ceph_node_down:join_kube
- expr: |
avg(max by(instance) (label_replace(label_replace(ceph_disk_occupation{job="rook-ceph-mgr"}, "instance", "$1", "exported_instance", "(.*)"), "device", "$1", "device", "/dev/(.*)") * on(instance, device) group_right() (irate(node_disk_read_time_seconds_total[1m]) + irate(node_disk_write_time_seconds_total[1m]) / (clamp_min(irate(node_disk_reads_completed_total[1m]), 1) + irate(node_disk_writes_completed_total[1m])))))
record: cluster:ceph_disk_latency:join_ceph_node_disk_irate1m
- name: telemeter.rules
rules:
- expr: |
count(ceph_osd_metadata{job="rook-ceph-mgr"})
record: job:ceph_osd_metadata:count
- expr: |
count(kube_persistentvolume_info * on (storageclass) group_left(provisioner) kube_storageclass_info {provisioner=~"(.*rbd.csi.ceph.com)|(.*cephfs.csi.ceph.com)"})
record: job:kube_pv:count
- expr: |
sum(ceph_pool_rd{job="rook-ceph-mgr"}+ ceph_pool_wr{job="rook-ceph-mgr"})
record: job:ceph_pools_iops:total
- expr: |
sum(ceph_pool_rd_bytes{job="rook-ceph-mgr"}+ ceph_pool_wr_bytes{job="rook-ceph-mgr"})
record: job:ceph_pools_iops_bytes:total
- expr: |
count(count(ceph_mon_metadata{job="rook-ceph-mgr"} or ceph_osd_metadata{job="rook-ceph-mgr"} or ceph_rgw_metadata{job="rook-ceph-mgr"} or ceph_mds_metadata{job="rook-ceph-mgr"} or ceph_mgr_metadata{job="rook-ceph-mgr"}) by(ceph_version))
record: job:ceph_versions_running:count
- name: ceph-mgr-status
rules:
- alert: CephMgrIsAbsent
annotations:
description: Ceph Manager has disappeared from Prometheus target discovery.
message: Storage metrics collector service not available anymore.
severity_level: critical
storage_type: ceph
expr: |
absent(up{job="rook-ceph-mgr"} == 1)
for: 5m
labels:
severity: critical
- alert: CephMgrIsMissingReplicas
annotations:
description: Ceph Manager is missing replicas.
message: Storage metrics collector service doesn't have required no of replicas.
severity_level: warning
storage_type: ceph
expr: |
sum(up{job="rook-ceph-mgr"}) < 1
for: 5m
labels:
severity: warning
- name: ceph-mds-status
rules:
- alert: CephMdsMissingReplicas
annotations:
description: Minimum required replicas for storage metadata service not available.
Might affect the working of storage cluster.
message: Insufficient replicas for storage metadata service.
severity_level: warning
storage_type: ceph
expr: |
sum(ceph_mds_metadata{job="rook-ceph-mgr"} == 1) < 2
for: 5m
labels:
severity: warning
- name: quorum-alert.rules
rules:
- alert: CephMonQuorumAtRisk
annotations:
description: Storage cluster quorum is low. Contact Support.
message: Storage quorum at risk
severity_level: error
storage_type: ceph
expr: |
count(ceph_mon_quorum_status{job="rook-ceph-mgr"} == 1) <= ((count(ceph_mon_metadata{job="rook-ceph-mgr"}) % 2) + 1)
for: 15m
labels:
severity: critical
- alert: CephMonHighNumberOfLeaderChanges
annotations:
description: Ceph Monitor {{ $labels.ceph_daemon }} on host {{ $labels.hostname
}} has seen {{ $value | printf "%.2f" }} leader changes per minute recently.
message: Storage Cluster has seen many leader changes recently.
severity_level: warning
storage_type: ceph
expr: |
(ceph_mon_metadata{job="rook-ceph-mgr"} * on (ceph_daemon) group_left() (rate(ceph_mon_num_elections{job="rook-ceph-mgr"}[5m]) * 60)) > 0.95
for: 5m
labels:
severity: warning
- name: ceph-node-alert.rules
rules:
- alert: CephNodeDown
annotations:
description: Storage node {{ $labels.node }} went down. Please check the node
immediately.
message: Storage node {{ $labels.node }} went down
severity_level: error
storage_type: ceph
expr: |
cluster:ceph_node_down:join_kube == 0
for: 30s
labels:
severity: critical
- name: osd-alert.rules
rules:
- alert: CephOSDCriticallyFull
annotations:
description: Utilization of storage device {{ $labels.ceph_daemon }} of device_class
type {{$labels.device_class}} has crossed 80% on host {{ $labels.hostname
}}. Immediately free up some space or add capacity of type {{$labels.device_class}}.
message: Back-end storage device is critically full.
severity_level: error
storage_type: ceph
expr: |
(ceph_osd_metadata * on (ceph_daemon) group_right(device_class) (ceph_osd_stat_bytes_used / ceph_osd_stat_bytes)) >= 0.80
for: 40s
labels:
severity: critical
- alert: CephOSDNearFull
annotations:
description: Utilization of storage device {{ $labels.ceph_daemon }} of device_class
type {{$labels.device_class}} has crossed 75% on host {{ $labels.hostname
}}. Immediately free up some space or add capacity of type {{$labels.device_class}}.
message: Back-end storage device is nearing full.
severity_level: warning
storage_type: ceph
expr: |
(ceph_osd_metadata * on (ceph_daemon) group_right(device_class) (ceph_osd_stat_bytes_used / ceph_osd_stat_bytes)) >= 0.75
for: 40s
labels:
severity: warning
- alert: CephOSDDiskNotResponding
annotations:
description: Disk device {{ $labels.device }} not responding, on host {{ $labels.host
}}.
message: Disk not responding
severity_level: error
storage_type: ceph
expr: |
label_replace((ceph_osd_in == 1 and ceph_osd_up == 0),"disk","$1","ceph_daemon","osd.(.*)") + on(ceph_daemon) group_left(host, device) label_replace(ceph_disk_occupation,"host","$1","exported_instance","(.*)")
for: 1m
labels:
severity: critical
- alert: CephOSDDiskUnavailable
annotations:
description: Disk device {{ $labels.device }} not accessible on host {{ $labels.host
}}.
message: Disk not accessible
severity_level: error
storage_type: ceph
expr: |
label_replace((ceph_osd_in == 0 and ceph_osd_up == 0),"disk","$1","ceph_daemon","osd.(.*)") + on(ceph_daemon) group_left(host, device) label_replace(ceph_disk_occupation,"host","$1","exported_instance","(.*)")
for: 1m
labels:
severity: critical
- alert: CephDataRecoveryTakingTooLong
annotations:
description: Data recovery has been active for too long. Contact Support.
message: Data recovery is slow
severity_level: warning
storage_type: ceph
expr: |
ceph_pg_undersized > 0
for: 2h
labels:
severity: warning
- alert: CephPGRepairTakingTooLong
annotations:
description: Self heal operations taking too long. Contact Support.
message: Self heal problems detected
severity_level: warning
storage_type: ceph
expr: |
ceph_pg_inconsistent > 0
for: 1h
labels:
severity: warning
- name: persistent-volume-alert.rules
rules:
- alert: PersistentVolumeUsageNearFull
annotations:
description: PVC {{ $labels.persistentvolumeclaim }} utilization has crossed
75%. Free up some space or expand the PVC.
message: PVC {{ $labels.persistentvolumeclaim }} is nearing full. Data deletion
or PVC expansion is required.
severity_level: warning
storage_type: ceph
expr: |
(kubelet_volume_stats_used_bytes * on (namespace,persistentvolumeclaim) group_left(storageclass, provisioner) (kube_persistentvolumeclaim_info * on (storageclass) group_left(provisioner) kube_storageclass_info {provisioner=~"(.*rbd.csi.ceph.com)|(.*cephfs.csi.ceph.com)"})) / (kubelet_volume_stats_capacity_bytes * on (namespace,persistentvolumeclaim) group_left(storageclass, provisioner) (kube_persistentvolumeclaim_info * on (storageclass) group_left(provisioner) kube_storageclass_info {provisioner=~"(.*rbd.csi.ceph.com)|(.*cephfs.csi.ceph.com)"})) > 0.75
for: 5s
labels:
severity: warning
- alert: PersistentVolumeUsageCritical
annotations:
description: PVC {{ $labels.persistentvolumeclaim }} utilization has crossed
85%. Free up some space or expand the PVC immediately.
message: PVC {{ $labels.persistentvolumeclaim }} is critically full. Data
deletion or PVC expansion is required.
severity_level: error
storage_type: ceph
expr: |
(kubelet_volume_stats_used_bytes * on (namespace,persistentvolumeclaim) group_left(storageclass, provisioner) (kube_persistentvolumeclaim_info * on (storageclass) group_left(provisioner) kube_storageclass_info {provisioner=~"(.*rbd.csi.ceph.com)|(.*cephfs.csi.ceph.com)"})) / (kubelet_volume_stats_capacity_bytes * on (namespace,persistentvolumeclaim) group_left(storageclass, provisioner) (kube_persistentvolumeclaim_info * on (storageclass) group_left(provisioner) kube_storageclass_info {provisioner=~"(.*rbd.csi.ceph.com)|(.*cephfs.csi.ceph.com)"})) > 0.85
for: 5s
labels:
severity: critical
- name: cluster-state-alert.rules
rules:
- alert: CephClusterErrorState
annotations:
description: Storage cluster is in error state for more than 10m.
message: Storage cluster is in error state
severity_level: error
storage_type: ceph
expr: |
ceph_health_status{job="rook-ceph-mgr"} > 1
for: 10m
labels:
severity: critical
- alert: CephClusterWarningState
annotations:
description: Storage cluster is in warning state for more than 10m.
message: Storage cluster is in degraded state
severity_level: warning
storage_type: ceph
expr: |
ceph_health_status{job="rook-ceph-mgr"} == 1
for: 10m
labels:
severity: warning
- alert: CephOSDVersionMismatch
annotations:
description: There are {{ $value }} different versions of Ceph OSD components
running.
message: There are multiple versions of storage services running.
severity_level: warning
storage_type: ceph
expr: |
count(count(ceph_osd_metadata{job="rook-ceph-mgr"}) by (ceph_version)) > 1
for: 10m
labels:
severity: warning
- alert: CephMonVersionMismatch
annotations:
description: There are {{ $value }} different versions of Ceph Mon components
running.
message: There are multiple versions of storage services running.
severity_level: warning
storage_type: ceph
expr: |
count(count(ceph_mon_metadata{job="rook-ceph-mgr"}) by (ceph_version)) > 1
for: 10m
labels:
severity: warning
- name: cluster-utilization-alert.rules
rules:
- alert: CephClusterNearFull
annotations:
description: Storage cluster utilization has crossed 75% and will become read-only
at 85%. Free up some space or expand the storage cluster.
message: Storage cluster is nearing full. Data deletion or cluster expansion
is required.
severity_level: warning
storage_type: ceph
expr: |
ceph_cluster_total_used_raw_bytes / ceph_cluster_total_bytes > 0.75
for: 5s
labels:
severity: warning
- alert: CephClusterCriticallyFull
annotations:
description: Storage cluster utilization has crossed 80% and will become read-only
at 85%. Free up some space or expand the storage cluster immediately.
message: Storage cluster is critically full and needs immediate data deletion
or cluster expansion.
severity_level: error
storage_type: ceph
expr: |
ceph_cluster_total_used_raw_bytes / ceph_cluster_total_bytes > 0.80
for: 5s
labels:
severity: critical
- alert: CephClusterReadOnly
annotations:
description: Storage cluster utilization has crossed 85% and will become read-only
now. Free up some space or expand the storage cluster immediately.
message: Storage cluster is read-only now and needs immediate data deletion
or cluster expansion.
severity_level: error
storage_type: ceph
expr: |
ceph_cluster_total_used_raw_bytes / ceph_cluster_total_bytes >= 0.85
for: 0s
labels:
severity: critical
[root@m1 monitoring]# kubectl apply -f prometheus-ceph-v14-rules.yaml
prometheusrule.monitoring.coreos.com/prometheus-ceph-rules created
配置完成后,打开 prometheus 的控制台即可看到 alter 相关的告警,如下
- 告警详情

- 告警配置


 浙公网安备 33010602011771号
浙公网安备 33010602011771号