07 云原生 CephFS 文件存储(转载)
云原生 CephFS 文件存储
CephFS 文件存储概述
RBD 特点:
- RBD块存储只能用于单个
VM或者单个pods使用,无法提供给多个虚拟机或者多个pods”同时“使用,如果虚拟机或pods有共同访问存储的需求需要使用CephFS实现。
NAS 网络附加存储:多个客户端同时访问
- EFS
- NAS
- CFS
CephFS 特点:
- POSIX-compliant semantics (符合 POSIX 的语法)
- Separates metadata from data (metadata和data 分离,数据放入data,元数据放入metadata)
- Dynamic rebalancing (动态从分布,自愈)
- Subdirectory snapshots (子目录筷子)
- Configurable striping (可配置切片)
- Kernel driver support (内核级别挂载)
- FUSE support (用户空间级别挂载)
- NFS/CIFS deployable (NFS/CIFS方式共享出去提供使用)
- Use with Hadoop (replace HDFS) (支持Hadoop 的 HDFS)
MDS 架构解析

大部分文件存储均通过元数据服务( metadata )查找元数据信息,通过 metadata 访问实际的数据, Ceph 中通过 MDS 来提供 metadata 服务,内置高可用架构,支持部署单Active-Standby 方式部署,也支持双主 Active 方式部署,其通过交换日志 Journal 来保障元数据的一致性。
MDS 和 FS 部署
FS 资源清单
[root@m1 kubernetes]# cd ceph/
[root@m1 ceph]# cat filesystem.yaml
#################################################################################################################
# Create a filesystem with settings with replication enabled for a production environment.
# A minimum of 3 OSDs on different nodes are required in this example.
# kubectl create -f filesystem.yaml
#################################################################################################################
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs
namespace: rook-ceph # namespace:cluster
spec:
# The metadata pool spec. Must use replication.
metadataPool:
replicated:
size: 3
requireSafeReplicaSize: true
parameters:
# Inline compression mode for the data pool
# Further reference: https://docs.ceph.com/docs/nautilus/rados/configuration/bluestore-config-ref/#inline-compression
compression_mode: none
# gives a hint (%) to Ceph in terms of expected consumption of the total cluster capacity of a given pool
# for more info: https://docs.ceph.com/docs/master/rados/operations/placement-groups/#specifying-expected-pool-size
#target_size_ratio: ".5"
# The list of data pool specs. Can use replication or erasure coding.
dataPools:
- failureDomain: host
replicated:
size: 3
# Disallow setting pool with replica 1, this could lead to data loss without recovery.
# Make sure you're *ABSOLUTELY CERTAIN* that is what you want
requireSafeReplicaSize: true
parameters:
# Inline compression mode for the data pool
# Further reference: https://docs.ceph.com/docs/nautilus/rados/configuration/bluestore-config-ref/#inline-compression
compression_mode: none
# gives a hint (%) to Ceph in terms of expected consumption of the total cluster capacity of a given pool
# for more info: https://docs.ceph.com/docs/master/rados/operations/placement-groups/#specifying-expected-pool-size
#target_size_ratio: ".5"
# Whether to preserve filesystem after CephFilesystem CRD deletion
preserveFilesystemOnDelete: true
# The metadata service (mds) configuration
metadataServer:
# The number of active MDS instances
activeCount: 1
# Whether each active MDS instance will have an active standby with a warm metadata cache for faster failover.
# If false, standbys will be available, but will not have a warm cache.
activeStandby: true
# The affinity rules to apply to the mds deployment
placement:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: role
# operator: In
# values:
# - mds-node
# topologySpreadConstraints:
# tolerations:
# - key: mds-node
# operator: Exists
# podAffinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-mds
# topologyKey: kubernetes.io/hostname will place MDS across different hosts
topologyKey: kubernetes.io/hostname
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-mds
# topologyKey: */zone can be used to spread MDS across different AZ
# Use <topologyKey: failure-domain.beta.kubernetes.io/zone> in k8s cluster if your cluster is v1.16 or lower
# Use <topologyKey: topology.kubernetes.io/zone> in k8s cluster is v1.17 or upper
topologyKey: topology.kubernetes.io/zone
# A key/value list of annotations
annotations:
# key: value
# A key/value list of labels
labels:
# key: value
resources:
# The requests and limits set here, allow the filesystem MDS Pod(s) to use half of one CPU core and 1 gigabyte of memory
# limits:
# cpu: "500m"
# memory: "1024Mi"
# requests:
# cpu: "500m"
# memory: "1024Mi"
# priorityClassName: my-priority-class
部署 FS
[root@m1 ceph]# kubectl apply -f filesystem.yaml
cephfilesystem.ceph.rook.io/myfs created
验证 FS 部署情况
MDS 部署需要创建两个 pool : metadata pool 和 data pool,支持使用副本或就删码的方式部署,同时需要部署 metadata 服务, metadata 以 active-standby 的方式部署,部署完毕之后会创建两个 pods 用于承载 mds
[root@m1 ceph]# kubectl -n rook-ceph get pods -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-6f9b88585c-nqfqt 1/1 Running 0 50s
rook-ceph-mds-myfs-b-6dd748578f-jsmxc 1/1 Running 0 49s
Ceph 中会自动部署好 mds 和文件系统
[root@m1 ceph]# ceph -s
cluster:
id: 17a413b5-f140-441a-8b35-feec8ae29521
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 10m)
mgr: a(active, since 22h)
mds: myfs:1 {0=myfs-a=up:active} 1 up:standby-replay # 启动了 2 个 mds
osd: 5 osds: 5 up (since 22h), 5 in (since 22h)
data:
pools: 4 pools, 97 pgs
objects: 456 objects, 1.3 GiB
usage: 8.8 GiB used, 241 GiB / 250 GiB avail
pgs: 97 active+clean
io:
client: 852 B/s rd, 1 op/s rd, 0 op/s wr
Pool 信息
# 查看 lspools 情况
[root@m1 ceph]# ceph osd lspools
1 device_health_metrics
2 replicapool
3 myfs-metadata
4 myfs-data0
CephFS 文件系统
# 查看 fs 源数据和数据情况
[root@m1 ceph]# ceph fs ls
name: myfs, metadata pool: myfs-metadata, data pools: [myfs-data0 ]
MDS 高可用性
MDS 支持双主的方式部署,即单个文件系统有多组 metadata 服务器,每组均有主备active-standby 的方式部署
[root@m1 ceph]# vim filesystem.yaml
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs
namespace: rook-ceph
spec:
metadataPool:
replicated:
size: 3
requireSafeReplicaSize: true
dataPools:
- failureDomain: host
replicated:
size: 3
requireSafeReplicaSize: true
preserveFilesystemOnDelete: true
metadataServer:
activeCount: 2 # 修改为 2,表示双主
activeStandby: true
......
创建完毕之后,会自动创建额外两个 pods
[root@m1 ceph]# kubectl apply -f filesystem.yaml
[root@m1 ceph]# kubectl -n rook-ceph get pods -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-6f9b88585c-nqfqt 1/1 Running 0 14m
rook-ceph-mds-myfs-b-6dd748578f-jsmxc 1/1 Running 0 14m
rook-ceph-mds-myfs-c-58dd67d577-66cvh 1/1 Running 0 67s
rook-ceph-mds-myfs-d-895ff6d69-k2scn 1/1 Running 0 67s
查看 ceph 的状态如下
[root@m1 ceph]# ceph -s
cluster:
id: 17a413b5-f140-441a-8b35-feec8ae29521
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 67s)
mgr: a(active, since 22h)
mds: myfs:2 {0=myfs-a=up:active,1=myfs-c=up:active} 2 up:standby-replay
osd: 5 osds: 5 up (since 22h), 5 in (since 22h)
data:
pools: 4 pools, 97 pgs
objects: 475 objects, 1.3 GiB
usage: 8.8 GiB used, 241 GiB / 250 GiB avail
pgs: 97 active+clean
io:
client: 2.5 KiB/s rd, 4 op/s rd, 0 op/s wr
MDS 高级调度
mds 通过 placement 提供了调度机制,支持节点调度, pods 亲和力调度, pods 反亲和调度,节点容忍和拓扑调度等,先看下节点的调度,通过 ceph-mds=enabled 标签选择具备满足条件的 node 节点
# 修改 filesystem.yaml 文件信息
[root@m1 ceph]# vim filesystem.yaml
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs
namespace: rook-ceph
spec:
metadataPool:
replicated:
size: 3
requireSafeReplicaSize: true
parameters:
compression_mode: none
dataPools:
- failureDomain: host
replicated:
size: 3
requireSafeReplicaSize: true
parameters:
compression_mode: none
preserveFilesystemOnDelete: true
metadataServer:
activeCount: 2
activeStandby: true
placement:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mds
operator: In
values:
- enabled
重新 apply 之后, mds 的 pods 会自动重启调度,没有满足条件的 node 时 pods 会处于 pending 状态,无法找到合适的 node 节点,因此需要给节点打上标签
[root@m1 ceph]# kubectl apply -f filesystem.yaml
cephfilesystem.ceph.rook.io/myfs configured
[root@m1 ceph]# kubectl -n rook-ceph get pods -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-5c745fd554-v94hk 0/1 Pending 0 1s
rook-ceph-mds-myfs-b-6dd748578f-jsmxc 1/1 Running 0 23m
rook-ceph-mds-myfs-c-58dd67d577-66cvh 1/1 Running 0 10m
rook-ceph-mds-myfs-d-895ff6d69-k2scn 1/1 Running 0 10m
[root@node-1 ceph]# kubectl label node 192.168.100.133 ceph-mds=enabled
[root@node-1 ceph]# kubectl label node 192.168.100.134 ceph-mds=enabled
[root@node-1 ceph]# kubectl label node 192.168.100.135 ceph-mds=enabled
[root@node-1 ceph]# kubectl label node 192.168.100.136 ceph-mds=enabled

nodeAffinity 节点亲和力调度算法只能将 pods 运行至特定的节点上,如果 pods 都落在同个节点上,其高可用性如何保障呢?需要借助 pods 反亲和调度算法来实现
# 修改配置文件,设置 pods 反亲和性
[root@m1 ceph]# vim filesystem.yaml
apiVersion: ceph.rook.io/v1
kind: CephFilesystem
metadata:
name: myfs
namespace: rook-ceph
spec:
metadataPool:
replicated:
size: 3
requireSafeReplicaSize: true
parameters:
compression_mode: none
dataPools:
- failureDomain: host
replicated:
size: 3
requireSafeReplicaSize: true
parameters:
compression_mode: none
preserveFilesystemOnDelete: true
metadataServer:
activeCount: 2
activeStandby: true
placement:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: ceph-mds
operator: In
values:
- enabled
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-mds
# topologyKey: kubernetes.io/hostname will place MDS across different hosts
topologyKey: kubernetes.io/hostname
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- rook-ceph-mds
topologyKey: topology.kubernetes.io/zone
重新 apply 资源清单
[root@m1 ceph]# kubectl apply -f filesystem.yaml
cephfilesystem.ceph.rook.io/myfs configured
重启 pods 后, pods 会按照反亲和力将其调度至合适的不同的节点
[root@m1 ceph]# kubectl -n rook-ceph delete pods rook-ceph-mds-myfs-a-5558ffd8db-fpphx
pod "rook-ceph-mds-myfs-a-5558ffd8db-fpphx" deleted
[root@m1 ceph]# kubectl -n rook-ceph delete pods rook-ceph-mds-myfs-b-55df4cd74b-52km6
pod "rook-ceph-mds-myfs-b-55df4cd74b-52km6" deleted
[root@m1 ceph]# kubectl -n rook-ceph delete pods rook-ceph-mds-myfs-c-7d5b7f5bfd-p4z2x
pod "rook-ceph-mds-myfs-c-7d5b7f5bfd-p4z2x" deleted
[root@m1 ceph]# kubectl -n rook-ceph delete pods rook-ceph-mds-myfs-d-b4f7b4c5d-jgrfl
pod "rook-ceph-mds-myfs-d-b4f7b4c5d-jgrfl" deleted

部署 CephFS 存储类
Rook 默认将 CephFS 相关的存储驱动已安装好,只需要通过 storageclass 消费即可
[root@m1 ceph]# cat csi/cephfs/storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-cephfs
provisioner: rook-ceph.cephfs.csi.ceph.com # driver:namespace:operator
parameters:
# clusterID is the namespace where operator is deployed.
clusterID: rook-ceph # namespace:cluster
# CephFS filesystem name into which the volume shall be created
fsName: myfs
# Ceph pool into which the volume shall be created
# Required for provisionVolume: "true"
pool: myfs-data0
# Root path of an existing CephFS volume
# Required for provisionVolume: "false"
# rootPath: /absolute/path
# The secrets contain Ceph admin credentials. These are generated automatically by the operator
# in the same namespace as the cluster.
csi.storage.k8s.io/provisioner-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/provisioner-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/controller-expand-secret-name: rook-csi-cephfs-provisioner
csi.storage.k8s.io/controller-expand-secret-namespace: rook-ceph # namespace:cluster
csi.storage.k8s.io/node-stage-secret-name: rook-csi-cephfs-node
csi.storage.k8s.io/node-stage-secret-namespace: rook-ceph # namespace:cluster
# (optional) The driver can use either ceph-fuse (fuse) or ceph kernel client (kernel)
# If omitted, default volume mounter will be used - this is determined by probing for ceph-fuse
# or by setting the default mounter explicitly via --volumemounter command-line argument.
# mounter: kernel
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
# uncomment the following line for debugging
#- debug
apply 之后可以查看到 rook-ceph.cephfs.csi.ceph.com 的 storageclass
[root@m1 ceph]# kubectl apply -f csi/cephfs/storageclass.yaml
storageclass.storage.k8s.io/rook-cephfs created
[root@m1 ceph]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate true 16h
rook-cephfs rook-ceph.cephfs.csi.ceph.com Delete Immediate true 4s
容器调用 CephFS
kube-registry 资源清单
[root@m1 ceph]# cat csi/cephfs/kube-registry.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: cephfs-pvc
namespace: kube-system
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: rook-cephfs
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-registry
namespace: kube-system
labels:
k8s-app: kube-registry
kubernetes.io/cluster-service: "true"
spec:
replicas: 3
selector:
matchLabels:
k8s-app: kube-registry
template:
metadata:
labels:
k8s-app: kube-registry
kubernetes.io/cluster-service: "true"
spec:
containers:
- name: registry
image: registry:2
imagePullPolicy: Always
resources:
limits:
cpu: 100m
memory: 100Mi
env:
# Configuration reference: https://docs.docker.com/registry/configuration/
- name: REGISTRY_HTTP_ADDR
value: :5000
- name: REGISTRY_HTTP_SECRET
value: "Ple4seCh4ngeThisN0tAVerySecretV4lue"
- name: REGISTRY_STORAGE_FILESYSTEM_ROOTDIRECTORY
value: /var/lib/registry
volumeMounts:
- name: image-store
mountPath: /var/lib/registry
ports:
- containerPort: 5000
name: registry
protocol: TCP
livenessProbe:
httpGet:
path: /
port: registry
readinessProbe:
httpGet:
path: /
port: registry
volumes:
- name: image-store
persistentVolumeClaim:
claimName: cephfs-pvc
readOnly: false
部署 kube-registry 服务
[root@m1 ceph]# kubectl apply -f csi/cephfs/kube-registry.yaml
persistentvolumeclaim/cephfs-pvc created
deployment.apps/kube-registry created
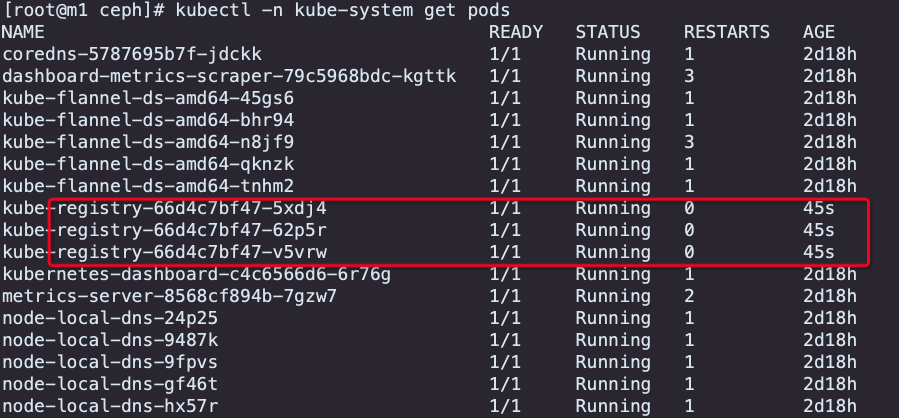
对接成功后会自动创建 PV 和 PVC , PVC 位于 kube-system 命名空间下

测试数据共享存储
[root@m1 ceph]# kubectl -n kube-system exec -it kube-registry-66d4c7bf47-5xdj4 -- sh
/ # cd /var/lib/registry/
/var/lib/registry # ls
docker
/var/lib/registry # echo "Evescn Test Page" > index.html
/var/lib/registry # cat index.html
Evescn Test Page
/var/lib/registry # ls -lh
total 1K
-rw-r--r-- 1 root root 17 Nov 25 07:35 index.html
[root@m1 ceph]# kubectl -n kube-system exec -it kube-registry-66d4c7bf47-v5vrw -- ls /var/lib/registry/ -lh
total 1K
-rw-r--r-- 1 root root 17 Nov 25 07:35 index.html
[root@m1 ceph]# kubectl -n kube-system exec -it kube-registry-66d4c7bf47-v5vrw -- cat /var/lib/registry/index.html
Evescn Test Page
镜像仓库功能验证
kube-registry 部署了三个 pods ,需要通过 service 将其暴露给外部服务使用
[root@m1 ceph]# vim /tmp/registry-svc
apiVersion: v1
kind: Service
metadata:
name: kube-registry-svc
namespace: kube-system
spec:
selector:
k8s-app: kube-registry
kubernetes.io/cluster-service: "true"
type: NodePort
ports:
- port: 5000
targetPort: 5000
nodePort: 35000
- 暴露端口
[root@m1 ceph]# kubectl apply -f /tmp/registry-svc
service/kube-registry-svc created
[root@m1 ceph]# kubectl -n kube-system get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.68.253.27 <none> 8000/TCP 2d23h
kube-dns ClusterIP 10.68.0.2 <none> 53/UDP,53/TCP,9153/TCP 2d23h
kube-dns-upstream ClusterIP 10.68.64.102 <none> 53/UDP,53/TCP 2d23h
kube-registry-svc NodePort 10.68.149.54 <none> 5000:35000/TCP 38s
kubernetes-dashboard NodePort 10.68.234.146 <none> 443:34823/TCP 2d23h
metrics-server ClusterIP 10.68.40.177 <none> 443/TCP 2d23h
node-local-dns ClusterIP None <none> 9253/TCP 2d23h
修改docker的配置,将私有镜像仓库加入insecure-registries,默认如果不是https的话会报错,因此需要将其加入
[root@m1 ceph]# cat /etc/docker/daemon.json
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"http://hub-mirror.c.163.com"
],
"insecure-registries": [ "10.68.149.54:5000" ],
"max-concurrent-downloads": 10,
"log-driver": "json-file",
"log-level": "warn",
"log-opts": {
"max-size": "10m",
"max-file": "3"
},
"data-root": "/var/lib/docker"
}
加入后执行 systemctl restart docker 重启一下服务,然后执行功能验证
[root@m1 ceph]# systemctl restart docker
[root@m1 ceph]# docker info
Client:
Context: default
Debug Mode: false
Server:
......
Insecure Registries:
10.68.149.54:5000
127.0.0.0/8
......
打包镜像,并推送到 10.68.149.54 registry 服务
[root@m1 ceph]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest 88736fe82739 9 days ago 142MB
......
[root@m1 ceph]# docker tag 88736fe82739 10.68.149.54:5000/nginx:v1
[root@m1 ceph]# docker push 10.68.149.54:5000/nginx:v1
The push refers to repository [10.68.149.54:5000/nginx]
6cffb086835a: Pushed
e2d75d87993c: Pushed
5a5bafd53f76: Pushed
f86e88a471f4: Pushed
f7ed3797e296: Pushed
ec4a38999118: Pushed
v1: digest: sha256:6ad8394ad31b269b563566998fd80a8f259e8decf16e807f8310ecc10c687385 size: 1570
登陆 registry Pod 查看数据
[root@m1 ceph]# kubectl -n kube-system exec -it kube-registry-66d4c7bf47-5xdj4 -- ls /var/lib/registry/ -lh
total 0
drwxr-xr-x 1 root root 1 Nov 25 07:55 docker
-rw-r--r-- 1 root root 17 Nov 25 07:35 index.html
[root@m1 ceph]# kubectl -n kube-system exec -it kube-registry-66d4c7bf47-62p5r -- ls /var/lib/registry/ -lh
total 0
drwxr-xr-x 1 root root 1 Nov 25 07:55 docker
-rw-r--r-- 1 root root 17 Nov 25 07:35 index.html
[root@m1 ceph]# kubectl -n kube-system exec -it kube-registry-66d4c7bf47-v5vrw -- ls /var/lib/registry/ -lh
total 0
drwxr-xr-x 1 root root 1 Nov 25 07:55 docker
-rw-r--r-- 1 root root 17 Nov 25 07:35 index.html
外部访问 CephFS
非容器化服务如何访问 CephFS 呢?使用 mount 的方式将CephFS挂载到本地目录即可,先获取到 mon 和 keyring 的认证信息,如下:
[root@m1 ceph]# cat /etc/ceph/
ceph.conf keyring rbdmap
[root@m1 ceph]# cat /etc/ceph/ceph.conf
[global]
mon_host = 10.68.231.222:6789,10.68.163.216:6789,10.68.61.127:6789
[client.admin]
keyring = /etc/ceph/keyring
[root@m1 ceph]# cat /etc/ceph/keyring
[client.admin]
key = AQDm435jUMuCKhAAXXPqMX08cLyjs/EOvchkzA==
执行挂载操作
[root@m1 ceph]# mount -t ceph -o name=admin,secret=AQDm435jUMuCKhAAXXPqMX08cLyjs/EOvchkzA==,mds_namespace=myfs 10.68.231.222:6789,10.68.163.216:6789,10.68.61.127:6789:/ /mnt/
验证数据
[root@m1 ceph]# df -h | grep mnt
10.68.231.222:6789,10.68.163.216:6789,10.68.61.127:6789:/ 76G 56M 76G 1% /mnt
[root@m1 ceph]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 250 GiB 241 GiB 4.3 GiB 9.3 GiB 3.72
TOTAL 250 GiB 241 GiB 4.3 GiB 9.3 GiB 3.72
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
device_health_metrics 1 1 0 B 0 0 B 0 76 GiB
replicapool 2 32 1.4 GiB 461 4.1 GiB 1.76 76 GiB
myfs-metadata 3 32 1.2 MiB 44 6.2 MiB 0 76 GiB
myfs-data0 4 32 54 MiB 33 166 MiB 0.07 76 GiB
[root@m1 ceph]# ls /mnt/volumes/csi/csi-vol-393d244e-6c71-11ed-b915-ceaf19f1c01f/4fe3c8f3-b013-448d-bb5c-faad5716a26c/
docker index.html
[root@m1 ceph]# cat /mnt/volumes/csi/csi-vol-393d244e-6c71-11ed-b915-ceaf19f1c01f/4fe3c8f3-b013-448d-bb5c-faad5716a26c/index.html
Evescn Test Page
CephFS集群维护
- pods状态
- ceph状态
- fs状态
- 日志查看
- 驱动日志
- 服务日志
pods状态查看,mds以pods的形式运行,需要确保pods运行正常
[root@m1 ceph]# kubectl -n rook-ceph get pods -l app=rook-ceph-mds
NAME READY STATUS RESTARTS AGE
rook-ceph-mds-myfs-a-5558ffd8db-zs8v6 1/1 Running 0 5h41m
rook-ceph-mds-myfs-b-55df4cd74b-tfr76 1/1 Running 0 5h41m
rook-ceph-mds-myfs-c-7d5b7f5bfd-lx64s 1/1 Running 2 5h41m
rook-ceph-mds-myfs-d-85c7d88dc4-tntmp 1/1 Running 0 5h41m
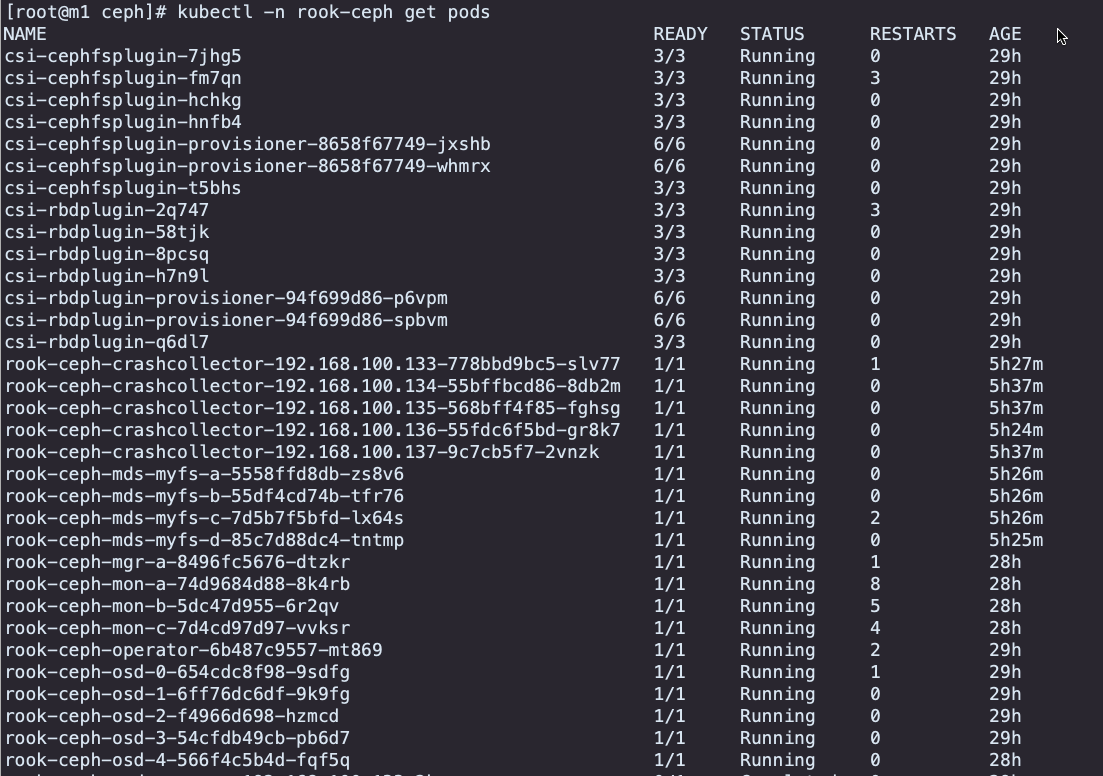
Ceph状态查看
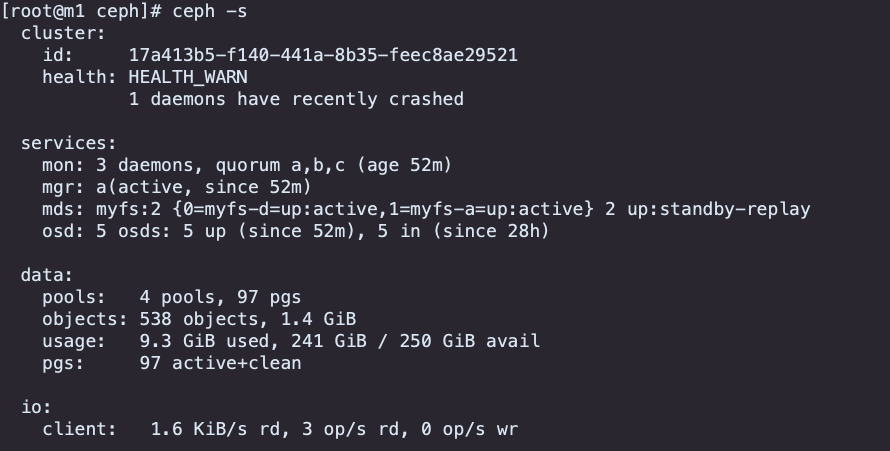
查看CephFS文件系统

容器日志查看,包含 mds 的日志和对接驱动的日志,当服务异常的时候可以结合日志信息进行排查, provisioner 包含有多个不同的容器
- csi-attacher 挂载
- csi-snapshotter 快照
- csi-resizer 调整大小
- csi-provisioner 创建
- csi-cephfsplugin 驱动agent
# 驱动日志查看
[root@m1 ceph]# kubectl -n rook-ceph logs -f csi-cephfsplugin-provisioner-8658f67749-whmrx
error: a container name must be specified for pod csi-cephfsplugin-provisioner-8658f67749-whmrx, choose one of: [csi-attacher csi-snapshotter csi-resizer csi-provisioner csi-cephfsplugin liveness-prometheus]
mds 容器日志查看
[root@m1 ceph]# kubectl -n rook-ceph logs -f rook-ceph-mds-myfs-a-5558ffd8db-zs8v6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号