05 定制 Rook 集群(转载)
定制 Rook 集群
placement 调度概述
rook借助kubernetes的默认调度机制,Ceph组件以pods的形式调度运行在kubernetes节点中- 然而每个节点因⻆色的不同,其机器的配置也有所不同
- 比如
mds对CPU计算要求较高,磁盘次之 - 相反
osd节点则对磁盘和内存要求较高,CPU次之 - 因此在规划的时候需要根据觉得的不同而分配节点
最终效果:根据规划来分配⻆色
rook 提供了多种调度策略
- nodeAffinity 节点亲和力调度,根据labels选择合适的调度节点
- podAffinity pods 亲和力调度,将pods调度到具有相同性质类型的节点上
- podAntiAffinity pods 反亲和调度,将pods调度到与某些pods相反的节点
- topologySpreadConstraints 拓扑选择调度
- tolerations 污点容忍调度,允许调度到某些具有“污点”的节点上
rook 支持的调度对象
- mon
- mgr
- osd
- cleanup
清理重建 rook 集群
删除资源对象
[root@m1 ceph]# kubectl delete -f cluster.yaml
[root@m1 ceph]# kubectl delete -f operator.yaml
[root@m1 ceph]# kubectl delete -f common.yaml
[root@m1 ceph]# kubectl delete -f crds.yaml
删除 rook 源数据目录
[root@m1 ceph]# ansible all -m shell -a "rm -rf /var/lib/rook/"
n2 | CHANGED | rc=0 >>
n1 | CHANGED | rc=0 >>
n4 | CHANGED | rc=0 >>
n3 | CHANGED | rc=0 >>
m1 | CHANGED | rc=0 >>
[root@m1 ceph]# ls /var/lib/rook/
ls: cannot access /var/lib/rook/: No such file or directory
清理磁盘信息,登陆到每个节点上,将 vgs 和 pv 删除
如果存在需要删除,此次清理
Rook集群无残留项,无需执行
[root@node-1 ~]# vgremove ceph-1a17705e-abd6-4b9d-8eee-d0f57a62801a --yes #通过 vgs可以查看
[root@node-1 ~]# pvremove /dev/vdb
删除 devicemapper 映射,登陆到每个节点上,将 devicemapper 删除
- 删除
m1节点的/mnt/挂载
[root@m1 ceph]# umount /mnt/
- 删除
devicemapper
[root@m1 ceph]# dmsetup ls
ceph--7d042c98--859f--4f48--9c9a--f6a2a39879fe-osd--block--43177789--5a9b--43bd--9d12--78896689215a (253:2)
centos-swap (253:1)
centos-root (253:0)
[root@m1 ~]# dmsetup remove --force ceph--7d042c98--859f--4f48--9c9a--f6a2a39879fe-osd--block--43177789--5a9b--43bd--9d12--78896689215a
[root@m1 ~]# dmsetup ls
centos-swap (253:1)
centos-root (253:0)
# 格式化磁盘数据
[root@m1 ceph]# dd if=/dev/zero of=/dev/sdb bs=1G count=50
删除 rook-ceph 命名空间
如果存在需要删除,此次清理
Rook集群直接删除了rook-ceph名称空间
由于一些资源对象未能删除,导致 rook-ceph 这个命名空间无法删除,解决方法可以找到 cephclusters.ceph.rook.io 自定义资源中的finalizers删除
[root@m1 ~]# kubectl edit customresourcedefinitions.apiextensions.k8s.io
cephclusters.ceph.rook.io
...省略...
finalizers:
- kubernetes
定制 mon 调度参数
背景:生产环境有一些专⻔的节点用于
mon、mgr,存储节点节点使用单独的节点承担,利用调度机制实现
122 placement:
123 mon:
124 nodeAffinity:
125 requiredDuringSchedulingIgnoredDuringExecution:
126 nodeSelectorTerms:
127 - matchExpressions:
128 - key: ceph-mon
129 operator: In
130 values:
131 - enabled
#设置磁盘的参数,调整为false,方便后面定制
185 storage: # cluster level storage configuration and selection
186 useAllNodes: false
187 useAllDevices: false
分别给节点打上标签
[root@m1 ceph]# kubectl label node 192.168.100.133 ceph-mon=enabled
node/192.168.100.133 labeled
[root@m1 ceph]# kubectl label node 192.168.100.134 ceph-mon=enabled
node/192.168.100.134 labeled
[root@m1 ceph]# kubectl label node 192.168.100.135 ceph-mon=enabled
node/192.168.100.135 labeled
[root@m1 ceph]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
192.168.100.133 Ready master 28h v1.20.5 ...,ceph-mon=enabled,...
192.168.100.134 Ready node 28h v1.20.5 ...,ceph-mon=enabled,...
192.168.100.135 Ready node 28h v1.20.5 ...,ceph-mon=enabled,...
192.168.100.136 Ready node 28h v1.20.5 ......
192.168.100.137 Ready node 28h v1.20.5 ......
定制 mgr 调度参数
修改
mgr的调度参数,修改完之后重新kubectl apply -f cluster.yaml配置使其加载到集群中
122 placement:
123 mon:
......
132 mgr:
133 nodeAffinity:
134 requiredDuringSchedulingIgnoredDuringExecution:
135 nodeSelectorTerms:
136 - matchExpressions:
137 - key: ceph-mgr
138 operator: In
139 values:
140 - enabled
- 部署
rook集群
[root@m1 ceph]# kubectl apply -f crds.yaml
[root@m1 ceph]# kubectl apply -f common.yaml
[root@m1 ceph]# kubectl apply -f operator.yaml
[root@m1 ceph]# kubectl get ns
NAME STATUS AGE
default Active 28h
kube-node-lease Active 28h
kube-public Active 28h
kube-system Active 28h
rook-ceph Active 22s
[root@m1 ceph]# kubectl -n rook-ceph get pods
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-7fdf75bb9d-7p695 1/1 Running 0 15s
[root@m1 ceph]# kubectl apply -f cluster.yaml
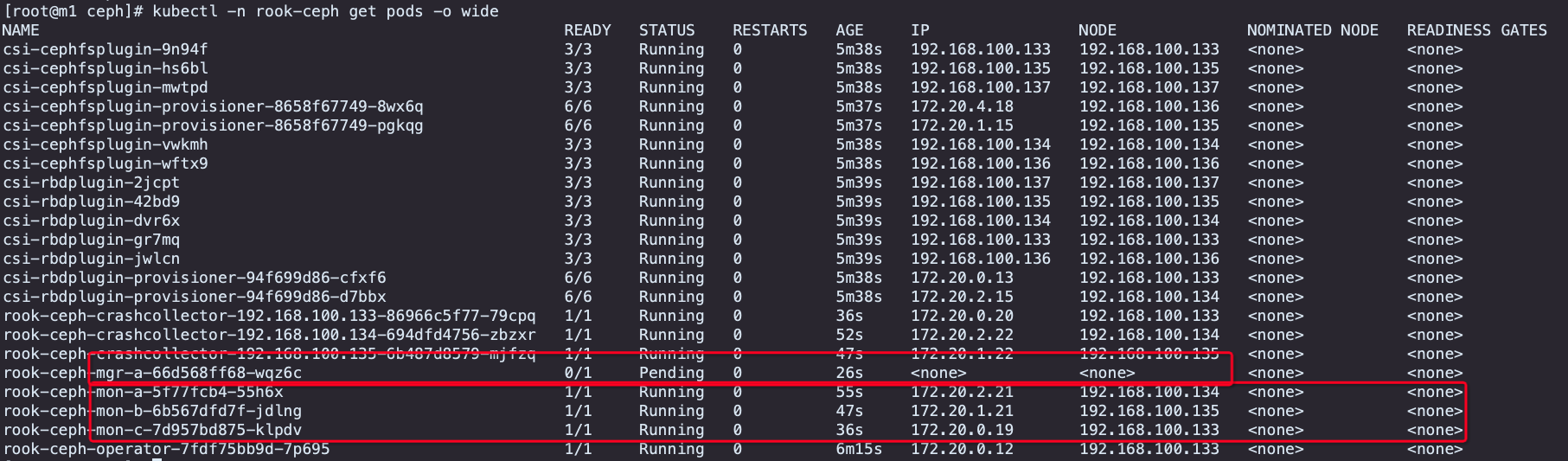
mon节点调度到了对应的m1,n1,n2节点上
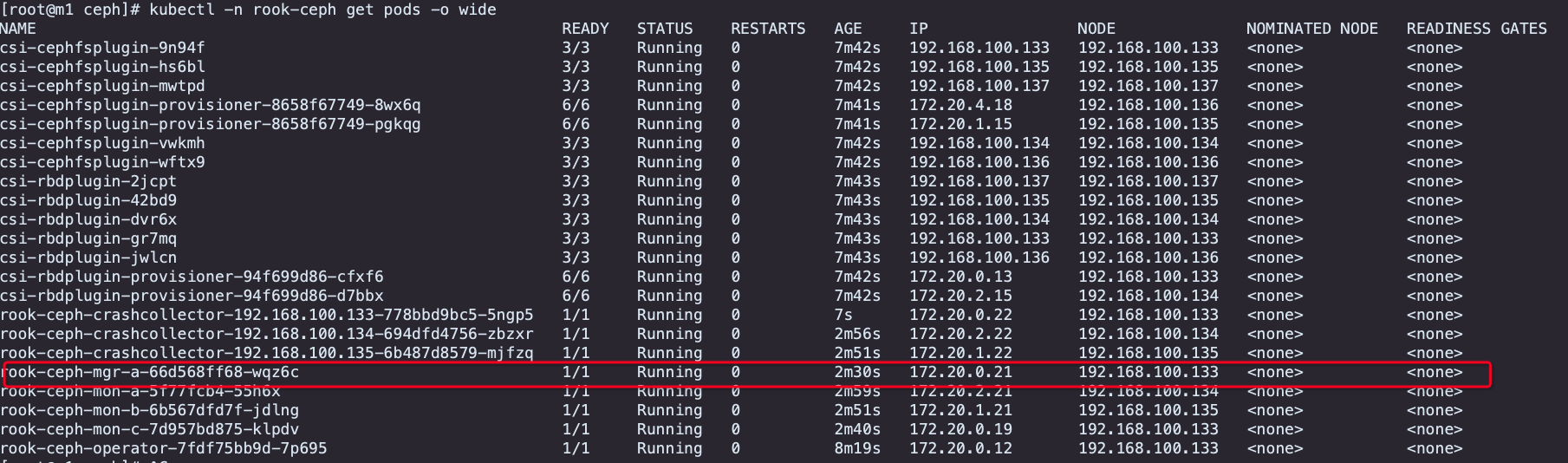
mgr节点此时调度会失败,给m1和n1打上ceph-mgr=enabled的标签
[root@m1 ceph]# kubectl label node 192.168.100.133 ceph-mgr=enabled
[root@m1 ceph]# kubectl label node 192.168.100.134 ceph-mgr=enabled
[root@m1 ceph]# kubectl get nodes --show-labels
NAME STATUS ROLES AGE VERSION LABELS
192.168.100.133 Ready master 28h v1.20.5 ...,ceph-mgr=enabled,ceph-mon=enabled,...
192.168.100.134 Ready node 28h v1.20.5 ...,ceph-mgr=enabled,ceph-mon=enabled,...
192.168.100.135 Ready node 28h v1.20.5 ...,ceph-mon=enabled,...
192.168.100.136 Ready node 28h v1.20.5 ......
192.168.100.137 Ready node 28h v1.20.5 ......
定制 osd 存储节点
rook 默认会使用所有节点上的所有满足条件的磁盘,并将其加入到 Ceph 集群中作为 osd ⻆色,生产环境中磁盘有特定的功能和⻆色,需要根据磁盘类型来分配。同时生产中扩容会涉及到数据的均衡 (rebalance) 操作,因此需要在低峰期或者单次扩容较少的 osd ,避免扩容对生产业务造成影响
194 storage: # cluster level storage configuration and selection
195 useAllNodes: false
196 useAllDevices: false
......
207 nodes:
208 - name: "m1"
209 devices:
210 - name: "sdb"
211 config:
212 storeType: bluestore
213 journalSizeMB: "4096"
214 - name: "n1"
215 devices:
216 - name: "sdb"
217 config:
218 storeType: bluestore
219 journalSizeMB: "4096"
220 - name: "n2"
221 devices:
222 - name: "sdb"
223 config:
224 storeType: bluestore
225 journalSizeMB: "4096"
226 - name: "n3"
227 devices:
228 - name: "sdb"
229 config:
230 storeType: bluestore
231 journalSizeMB: "4096"
修改配置完毕后重新 kubectl apply -f cluster.yaml ,会根据预先设置内容创建 osd。
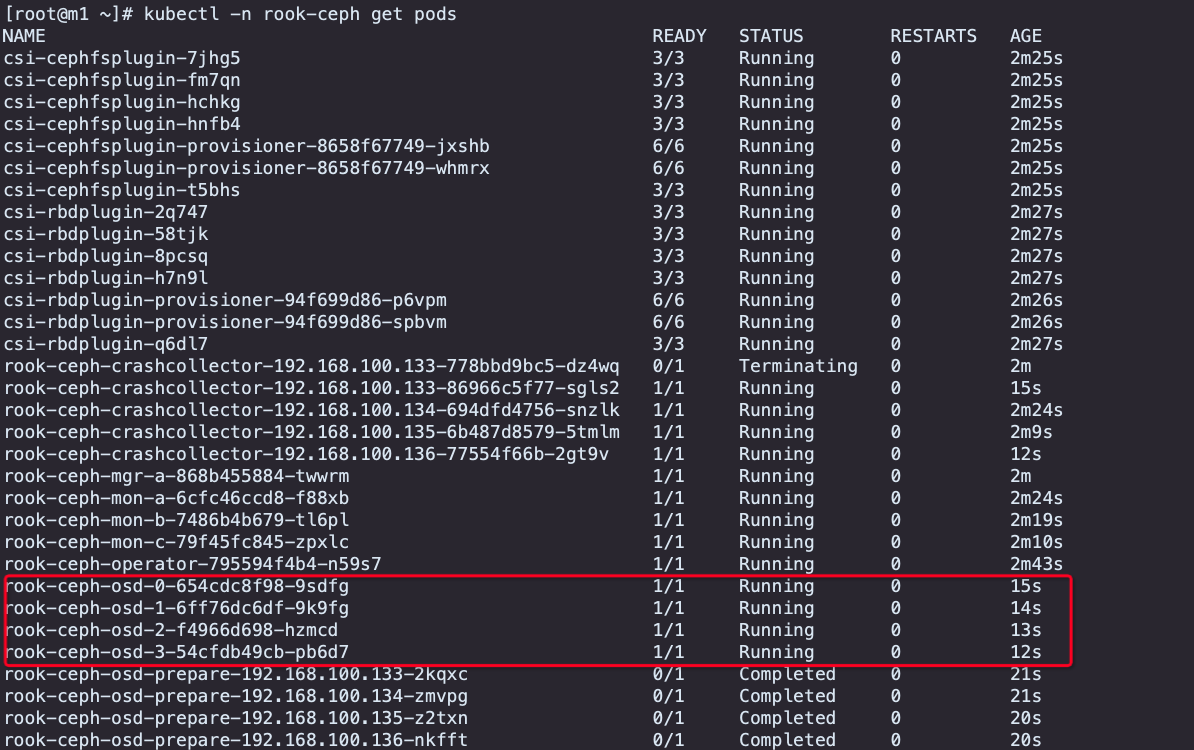
定制 osd 调度参数
结合调度算法,将满足条件的节点分配到特定节点上,同时使用节点上特定的磁盘
设置 osd 的调度参数
207 nodes:
......
232 - name: "192.168.100.137"
233 devices:
234 - name: "sdb"
235 config:
236 storeType: bluestore
237 journalSizeMB: "4096"
定制 osd 的磁盘参数
122 placement:
......
141 osd:
142 nodeAffinity:
143 requiredDuringSchedulingIgnoredDuringExecution:
144 nodeSelectorTerms:
145 - matchExpressions:
146 - key: ceph-osd
147 operator: In
148 values:
149 - enabled
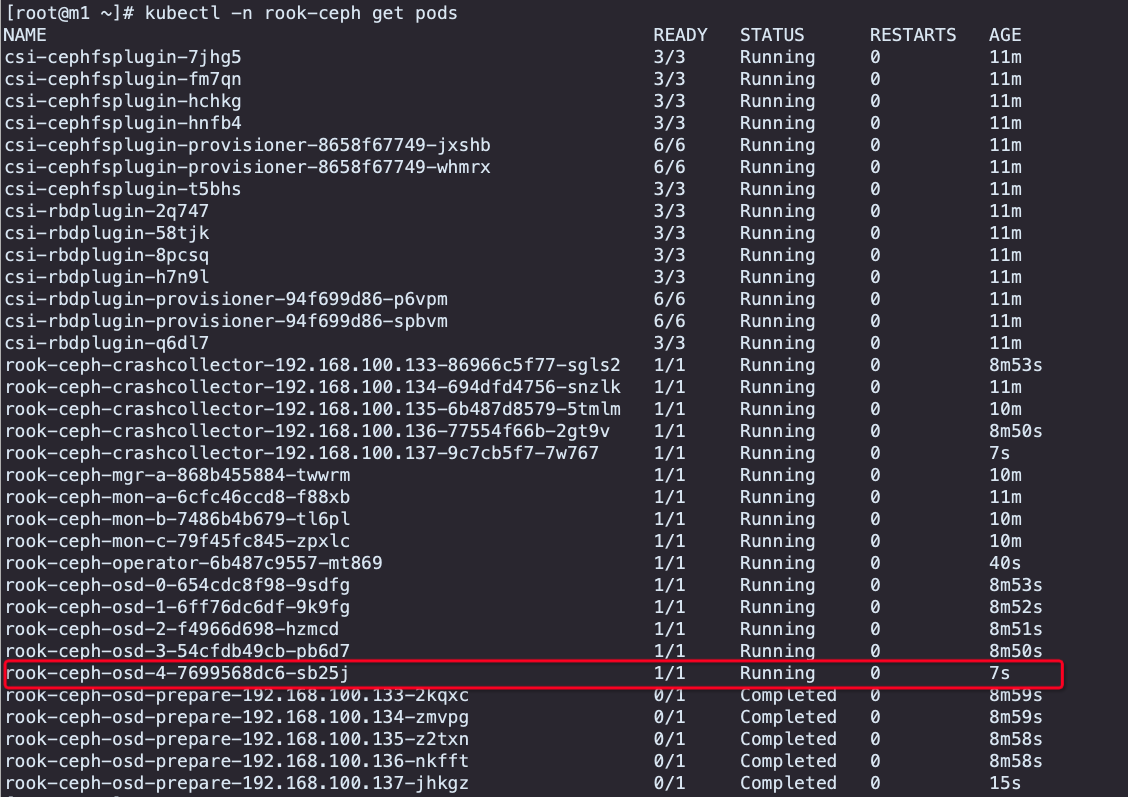
重新 kubectl apply -f cluster.yaml 发现 n4 无法加入到集群中,因为不满足调度的参数,添加标签使其满足调度,同理将其他存储节点打上 ceph-osd 的标签(存量的暂时先不设置,后续调整磁盘参数后查看效果)
[root@m1 ceph]# kubectl -n rook-ceph logs -f rook-ceph-operator-795594f4b4-n59s7
......
2022-11-24 03:31:57.376559 I | op-osd: no volume sources defined to configure OSDs on PVCs.
2022-11-24 03:31:57.376574 I | op-osd: start provisioning the osds on nodes, if needed
2022-11-24 03:31:57.571258 I | op-osd: 0 of the 5 storage nodes are valid
2022-11-24 03:31:57.571274 W | op-osd: no valid nodes available to run osds on nodes in namespace rook-ceph
2022-11-24 03:31:57.571278 I | op-osd: start osds after provisioning is completed, if needed
2022-11-24 03:31:57.601027 I | op-mgr: successful modules: prometheus
2022-11-24 03:31:58.629896 I | op-mgr: successful modules: balancer
2022-11-24 03:31:58.641230 I | op-mgr: successful modules: mgr module(s) from the spec
2022-11-24 03:31:58.681946 I | cephclient: successfully disallowed pre-octopus osds and enabled all new octopus-only functionality
2022-11-24 03:31:58.681965 I | op-osd: completed running osds in namespace rook-ceph
[root@m1 ceph]# kubectl label node 192.168.100.137 ceph-osd=enabled
node/192.168.100.137 labeled
定制资源限制
默认组件没有设置资源分配,当出现资源争抢的时候可能会出现驱逐,为了保证 Ceph 的核心组件能分配
到特定的资源,需要设置合理的资源分配
- mon,内存推荐128G
- mds
- osd,每T磁盘建议需要有4G
确保组件能够分配到足够的资源
180 resources:
182 mon:
183 limits:
184 cpu: "300m"
185 memory: "512Mi"
186 requests:
187 cpu: "300m"
188 memory: "512Mi"
189 mgr:
190 limits:
191 cpu: "300m"
192 memory: "512Mi"
193 requests:
194 cpu: "300m"
195 memory: "512Mi"
196 osd:
197 limits:
198 cpu: "300m"
199 memory: "512Mi"
200 requests:
201 cpu: "300m"
202 memory: "512Mi"
osd 启动失败排障
修改完资源配置之后, osd 会自动重启以加载配置文件内容, osd 启动失败,可以通过查看 pods 日志文件内容定位
[root@m1 ceph]# kubectl -n rook-ceph logs rook-ceph-osd-4-566f4c5b4d-fqf5q
查看发现有大量堆栈导致的异常,修改 osd 的资源分配后重新 kubectl apply -f cluster.yaml 启动正常
180 resources:
......
196 osd:
197 limits:
198 cpu: "1000m"
199 memory: "2048Mi"
200 requests:
201 cpu: "1000m"
202 memory: "2048Mi"
健康检查机制
kubernetes 默认提供了健康探测机制,通常包含有三种:
- LivenessProbe 检测是否存活
- ReadinessProbe 检测是否就绪
- StartupProbe 检测是否启动
rook 提供了 daemonHealth 和 livenessProbe 健康探测机制,用于检测守护进程和是否存活(用于 Ceph 内部检测)
288 healthCheck:
289 daemonHealth:
290 mon:
291 disabled: false
292 interval: 45s
293 osd:
294 disabled: false
295 interval: 60s
296 status:
297 disabled: false
298 interval: 60s
299 # Change pod liveness probe, it works for all mon,mgr,osd daemons
300 livenessProbe:
301 mon:
302 disabled: false
303 mgr:
304 disabled: false
305 osd:
306 disabled: false
mon 存活探测机制
[root@m1 ~]# kubectl -n rook-ceph get pods rook-ceph-mon-a-74d9684d88-8k4rb -o yaml
......
livenessProbe:
exec:
command:
- env
- -i
- sh
- -c
- ceph --admin-daemon /run/ceph/ceph-mon.a.asok mon_status
failureThreshold: 3
initialDelaySeconds: 10
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
mgr 存活探测机制
[root@m1 ~]# kubectl -n rook-ceph get pods rook-ceph-mgr-a-8496fc5676-dtzkr -o yaml
......
livenessProbe:
failureThreshold: 3
httpGet:
path: /
port: 9283
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
osd 存活探测机制
[root@m1 ~]# kubectl -n rook-ceph get pods rook-ceph-osd-1-6ff76dc6df-9k9fg -o yaml
......
livenessProbe:
exec:
command:
- env
- -i
- sh
- -c
- ceph --admin-daemon /run/ceph/ceph-osd.1.asok status
failureThreshold: 3
initialDelaySeconds: 45
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
如上的 livenessProbe 存活探测机制是根据开关设定开启的探测方法,不同的⻆色其探测的方式有所区别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号