07 Ceph 集群运维
Ceph 守护服务管理
全局管理 一台机器有多个ceph 服务
STARTING ALL daemons
To start all daemons on a Ceph Node (irrespective of type), execute the following:
sudo systemctl start ceph.target # start all daemons
STOPPING ALL daemons
To stop all daemons on a Ceph Node (irrespective of type), execute the following:
sudo systemctl stop ceph\*.service ceph\*.target
服务分类管理
STARTING ALL DAEMONS BY TYPE
To start all daemons of a particular type on a Ceph Node, execute one of the following:
sudo systemctl start ceph-osd.target
sudo systemctl start ceph-mon.target
sudo systemctl start ceph-mds.target
STOPPING ALL DAEMONS BY TYPE
To stop all daemons of a particular type on a Ceph Node, execute one of the following:
sudo systemctl stop ceph-mon\*.service ceph-mon.target
sudo systemctl stop ceph-osd\*.service ceph-osd.target
sudo systemctl stop ceph-mds\*.service ceph-mds.target
更细力度的服务管理
STARTING A DAEMON
To start a specific daemon instance on a Ceph Node, execute one of the following:
sudo systemctl start ceph-osd@{id}
sudo systemctl start ceph-mon@{hostname}
sudo systemctl start ceph-mds@{hostname}
For example:
sudo systemctl start ceph-osd@1
sudo systemctl start ceph-mon@ceph-server
sudo systemctl start ceph-mds@ceph-server
STOPPING A DAEMON
To stop a specific daemon instance on a Ceph Node, execute one of the following:
sudo systemctl stop ceph-osd@{id}
sudo systemctl stop ceph-mon@{hostname}
sudo systemctl stop ceph-mds@{hostname}
For example:
sudo systemctl stop ceph-osd@1
sudo systemctl stop ceph-mon@ceph-server
sudo systemctl stop ceph-mds@ceph-server
演示
# 查看集群状态
[root@node0 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
# 按类型停止 osd 守护进程 STOPPING ALL DAEMONS BY TYPE
[root@node0 ~]# systemctl stop ceph-osd.target
# 再次查看集群状态,node0 节点 2个 osd 服务都 down
[root@node0 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 down 1.00000 1.00000
3 hdd 0.04880 osd.3 down 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
# 启动守护进程 STARTING A DAEMON
[root@node0 ~]# systemctl start ceph-osd@0
# 查看集群状态, osd.0 磁盘恢复正常
[root@node0 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 down 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
# 启动守护进程 STARTING A DAEMON
[root@node0 ~]# systemctl start ceph-osd@3
# 查看集群状态, osd.3 磁盘恢复正常
[root@node0 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
Ceph 服务日志分析
Ceph 日常存放目录
日志目录:/var/log/ceph/
查看 mon 日志
[root@node0 ceph]# tail -f /var/log/ceph/ceph-mon.node0.log
2022-10-22 20:43:30.061 7fee793c7700 4 rocksdb: [db/db_impl_compaction_flush.cc:1403] [default] Manual compaction starting
2022-10-22 20:43:30.061 7fee793c7700 4 rocksdb: [db/db_impl_compaction_flush.cc:1403] [default] Manual compaction starting
2022-10-22 20:43:30.061 7fee793c7700 4 rocksdb: [db/db_impl_compaction_flush.cc:1403] [default] Manual compaction starting
2022-10-22 20:43:30.061 7fee793c7700 4 rocksdb: [db/db_impl_compaction_flush.cc:1403] [default] Manual compaction starting
2022-10-22 20:43:30.061 7fee793c7700 4 rocksdb: [db/db_impl_compaction_flush.cc:1403] [default] Manual compaction starting
2022-10-22 20:43:34.997 7fee803d5700 1 mon.node0@0(leader).osd e322 _set_new_cache_sizes cache_size:1020054731 inc_alloc: 71303168 full_alloc: 71303168 kv_alloc: 872415232
2022-10-22 20:43:39.998 7fee803d5700 1 mon.node0@0(leader).osd e322 _set_new_cache_sizes cache_size:1020054731 inc_alloc: 71303168 full_alloc: 71303168 kv_alloc: 872415232
2022-10-22 20:43:44.999 7fee803d5700 1 mon.node0@0(leader).osd e322 _set_new_cache_sizes cache_size:1020054731 inc_alloc: 71303168 full_alloc: 71303168 kv_alloc: 872415232
2022-10-22 20:43:50.000 7fee803d5700 1 mon.node0@0(leader).osd e322 _set_new_cache_sizes cache_size:1020054731 inc_alloc: 71303168 full_alloc: 71303168 kv_alloc: 872415232
2022-10-22 20:43:55.001 7fee803d5700 1 mon.node0@0(leader).osd e322 _set_new_cache_sizes cache_size:1020054731 inc_alloc: 71303168 full_alloc: 71303168 kv_alloc: 872415232
模拟 osd.0 坏盘,查看日志
# 手动停止服务,模拟 osd.0 坏盘
[root@node0 ceph]# systemctl stop ceph-osd@0
# 查看 osd 存储,osd.0 down
[root@node0 ceph]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 down 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
# 查看 osd.0 日志
[root@node0 ceph]# tail -10f /var/log/ceph/ceph-osd.0.log
AddFile(Keys): cumulative 0, interval 0
Cumulative compaction: 0.01 GB write, 0.01 MB/s write, 0.00 GB read, 0.00 MB/s read, 0.1 seconds
Interval compaction: 0.00 GB write, 0.00 MB/s write, 0.00 GB read, 0.00 MB/s read, 0.0 seconds
Stalls(count): 0 level0_slowdown, 0 level0_slowdown_with_compaction, 0 level0_numfiles, 0 level0_numfiles_with_compaction, 0 stop for pending_compaction_bytes, 0 slowdown for pending_compaction_bytes, 0 memtable_compaction, 0 memtable_slowdown, interval 0 total count
** File Read Latency Histogram By Level [default] **
2022-10-22 20:46:05.991 7fed76190700 -1 received signal: Terminated from /usr/lib/systemd/systemd --switched-root --system --deserialize 22 (PID: 1) UID: 0
2022-10-22 20:46:05.991 7fed76190700 -1 osd.0 322 *** Got signal Terminated ***
2022-10-22 20:46:05.991 7fed76190700 -1 osd.0 322 *** Immediate shutdown (osd_fast_shutdown=true) ***
# 启动服务
[root@node0 ceph]# systemctl start ceph-osd@0
Ceph 集群状态监控
监控集群有2种方式:
第一种:ceph 进入命令交互界面
第二种:直接使用命令加子命令模式
监控集群有2种方式
交互模式
ceph
ceph> health
ceph> status
ceph> quorum_status
ceph> mon stat
[root@node0 ~]# ceph
ceph> health
HEALTH_OK
ceph> status
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_OK
services:
mon: 3 daemons, quorum node0,node1,node2 (age 26h)
mgr: node1(active, since 26h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 4m), 6 in (since 8h)
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.8 GiB used, 293 GiB / 300 GiB avail
pgs: 352 active+clean
ceph> mon stat
e3: 3 mons at {node0=[v2:192.168.100.130:3300/0,v1:192.168.100.130:6789/0],node1=[v2:192.168.100.131:3300/0,v1:192.168.100.131:6789/0],node2=[v2:192.168.100.132:3300/0,v1:192.168.100.132:6789/0]}, election epoch 28, leader 0 node0, quorum 0,1,2 node0,node1,node2
ceph> exit
命令 加 子命令模式
[root@node0 ~]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_OK
services:
mon: 3 daemons, quorum node0,node1,node2 (age 26h)
mgr: node1(active, since 26h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 4m), 6 in (since 8h)
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.8 GiB used, 293 GiB / 300 GiB avail
pgs: 352 active+clean
[root@node0 ~]# ceph status
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_OK
services:
mon: 3 daemons, quorum node0,node1,node2 (age 26h)
mgr: node1(active, since 26h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 4m), 6 in (since 8h)
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.8 GiB used, 293 GiB / 300 GiB avail
pgs: 352 active+clean
动态监视集群状态
ceph -w 动态监视集群状态
[root@node0 ceph-deploy]# ceph -w
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_OK
services:
mon: 3 daemons, quorum node0,node1,node2 (age 42h)
mgr: node1(active, since 2d), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 43h), 6 in (since 2d)
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.8 GiB used, 293 GiB / 300 GiB avail
pgs: 352 active+clean
2022-10-24 16:06:19.714395 mon.node0 [INF] osd.0 failed (root=default,host=node0) (connection refused reported by osd.5)
2022-10-24 16:06:20.458219 mon.node0 [WRN] Health check failed: 1 osds down (OSD_DOWN)
2022-10-24 16:06:21.465945 mon.node0 [WRN] Health check failed: Reduced data availability: 7 pgs inactive, 33 pgs peering (PG_AVAILABILITY)
2022-10-24 16:06:23.467453 mon.node0 [WRN] Health check failed: Degraded data redundancy: 141/980 objects degraded (14.388%), 53 pgs degraded (PG_DEGRADED)
2022-10-24 16:06:27.456981 mon.node0 [INF] Health check cleared: PG_AVAILABILITY (was: Reduced data availability: 7 pgs inactive, 33 pgs peering)
2022-10-24 16:06:33.388498 mon.node0 [WRN] Health check update: Degraded data redundancy: 168/980 objects degraded (17.143%), 63 pgs degraded (PG_DEGRADED)
2022-10-24 16:06:50.486208 mon.node0 [INF] Health check cleared: OSD_DOWN (was: 1 osds down)
2022-10-24 16:06:50.493443 mon.node0 [INF] osd.0 [v2:192.168.100.130:6810/14455,v1:192.168.100.130:6811/14455] boot
2022-10-24 16:06:51.493477 mon.node0 [WRN] Health check update: Degraded data redundancy: 149/980 objects degraded (15.204%), 56 pgs degraded (PG_DEGRADED)
2022-10-24 16:06:57.477310 mon.node0 [WRN] Health check update: Degraded data redundancy: 31/980 objects degraded (3.163%), 8 pgs degraded (PG_DEGRADED)
2022-10-24 16:07:03.396045 mon.node0 [WRN] Health check update: Degraded data redundancy: 6/980 objects degraded (0.612%), 2 pgs degraded (PG_DEGRADED)
2022-10-24 16:07:03.826353 mon.node0 [INF] Health check cleared: PG_DEGRADED (was: Degraded data redundancy: 6/980 objects degraded (0.612%), 2 pgs degraded)
2022-10-24 16:07:03.826378 mon.node0 [INF] Cluster is now healthy
- 启动一个新的终端,执行命令
[root@node0 ~]# systemctl stop ceph-osd@0
[root@node0 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 down 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
[root@node0 ~]# systemctl start ceph-osd@0
集群状态监控
集群空间使用情况
[root@node0 ceph-deploy]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 300 GiB 293 GiB 857 MiB 6.8 GiB 2.28
TOTAL 300 GiB 293 GiB 857 MiB 6.8 GiB 2.28
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
ceph-demo 1 128 300 MiB 103 603 MiB 0.21 139 GiB
.rgw.root 2 32 1.2 KiB 4 768 KiB 0 93 GiB
default.rgw.control 3 32 0 B 8 0 B 0 93 GiB
default.rgw.meta 4 32 2.5 KiB 10 1.7 MiB 0 93 GiB
default.rgw.log 5 32 0 B 207 0 B 0 93 GiB
default.rgw.buckets.index 6 32 243 B 3 243 B 0 93 GiB
default.rgw.buckets.data 7 32 465 B 1 192 KiB 0 93 GiB
cephfs_metadata 8 16 16 KiB 22 1.5 MiB 0 93 GiB
cephfs_data 9 16 2.0 KiB 3 576 KiB 0 93 GiB
集群 osd 情况
[root@node0 ceph-deploy]# ceph osd stat
6 osds: 6 up (since 3m), 6 in (since 2d); epoch: e330
[root@node0 ceph-deploy]# ceph osd dump
epoch 330
fsid 97702c43-6cc2-4ef8-bdb5-855cfa90a260
created 2022-10-13 14:03:10.074146
modified 2022-10-24 16:06:51.492556
flags sortbitwise,recovery_deletes,purged_snapdirs,pglog_hardlimit
crush_version 18
full_ratio 0.95
backfillfull_ratio 0.9
nearfull_ratio 0.85
require_min_compat_client jewel
min_compat_client jewel
require_osd_release nautilus
pool 1 'ceph-demo' replicated size 2 min_size 1 crush_rule 0 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode warn last_change 28 lfor 0/0/20 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd
removed_snaps [1~3]
pool 2 '.rgw.root' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode warn last_change 31 flags hashpspool stripe_width 0 application rgw
pool 3 'default.rgw.control' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode warn last_change 33 flags hashpspool stripe_width 0 application rgw
pool 4 'default.rgw.meta' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode warn last_change 35 flags hashpspool stripe_width 0 application rgw
pool 5 'default.rgw.log' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode warn last_change 37 flags hashpspool stripe_width 0 application rgw
pool 6 'default.rgw.buckets.index' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode warn last_change 40 flags hashpspool stripe_width 0 application rgw
pool 7 'default.rgw.buckets.data' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode warn last_change 53 flags hashpspool stripe_width 0 application rgw
pool 8 'cephfs_metadata' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 16 pgp_num 16 autoscale_mode warn last_change 66 flags hashpspool stripe_width 0 pg_autoscale_bias 4 pg_num_min 16 recovery_priority 5 application cephfs
pool 9 'cephfs_data' replicated size 3 min_size 2 crush_rule 0 object_hash rjenkins pg_num 16 pgp_num 16 autoscale_mode warn last_change 66 flags hashpspool stripe_width 0 application cephfs
max_osd 6
osd.0 up in weight 1 up_from 329 up_thru 329 down_at 327 last_clean_interval [325,326) [v2:192.168.100.130:6810/14455,v1:192.168.100.130:6811/14455] [v2:192.168.100.130:6812/14455,v1:192.168.100.130:6813/14455] exists,up f1519628-b073-4e5e-9870-d6e6f3efc9b4
osd.1 up in weight 1 up_from 68 up_thru 329 down_at 67 last_clean_interval [58,66) [v2:192.168.100.131:6802/1147,v1:192.168.100.131:6803/1147] [v2:192.168.100.131:6804/1147,v1:192.168.100.131:6805/1147] exists,up 09042370-86ae-4a6d-99ac-ce2a513ed2b6
osd.2 up in weight 1 up_from 68 up_thru 329 down_at 67 last_clean_interval [58,66) [v2:192.168.100.132:6802/1145,v1:192.168.100.132:6803/1145] [v2:192.168.100.132:6804/1145,v1:192.168.100.132:6805/1145] exists,up 816b6503-9551-48a2-823e-1c6a52ea213b
osd.3 up in weight 1 up_from 320 up_thru 320 down_at 318 last_clean_interval [80,317) [v2:192.168.100.130:6802/8408,v1:192.168.100.130:6803/8408] [v2:192.168.100.130:6804/8408,v1:192.168.100.130:6805/8408] exists,up b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9
osd.4 up in weight 1 up_from 128 up_thru 329 down_at 0 last_clean_interval [0,0) [v2:192.168.100.131:6812/3219,v1:192.168.100.131:6813/3219] [v2:192.168.100.131:6814/3219,v1:192.168.100.131:6815/3219] exists,up 2e404cc8-4b71-40e0-91ee-eb0ddafd6e8a
osd.5 up in weight 1 up_from 270 up_thru 329 down_at 0 last_clean_interval [0,0) [v2:192.168.100.132:6810/6104,v1:192.168.100.132:6811/6104] [v2:192.168.100.132:6812/6104,v1:192.168.100.132:6813/6104] exists,up a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7
[root@node0 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
[root@node0 ceph-deploy]# ceph osd df
ID CLASS WEIGHT REWEIGHT SIZE RAW USE DATA OMAP META AVAIL %USE VAR PGS STATUS
0 hdd 0.04880 1.00000 50 GiB 1.1 GiB 147 MiB 20 KiB 1024 MiB 49 GiB 2.29 1.00 147 up
3 hdd 0.04880 1.00000 50 GiB 1.2 GiB 163 MiB 27 KiB 1024 MiB 49 GiB 2.32 1.02 167 up
1 hdd 0.04880 1.00000 50 GiB 1.2 GiB 155 MiB 11 KiB 1024 MiB 49 GiB 2.30 1.01 148 up
4 hdd 0.04880 1.00000 50 GiB 1.1 GiB 102 MiB 0 B 1 GiB 49 GiB 2.20 0.97 151 up
2 hdd 0.04880 1.00000 50 GiB 1.1 GiB 119 MiB 11 KiB 1024 MiB 49 GiB 2.23 0.98 151 up
5 hdd 0.04880 1.00000 50 GiB 1.2 GiB 171 MiB 0 B 1 GiB 49 GiB 2.33 1.02 164 up
TOTAL 300 GiB 6.8 GiB 856 MiB 72 KiB 6.0 GiB 293 GiB 2.28
MIN/MAX VAR: 0.97/1.02 STDDEV: 0.05
集群 mon 监控
[root@node0 ceph-deploy]# ceph mon stat
ceph mon dumpe3: 3 mons at {node0=[v2:192.168.100.130:3300/0,v1:192.168.100.130:6789/0],node1=[v2:192.168.100.131:3300/0,v1:192.168.100.131:6789/0],node2=[v2:192.168.100.132:3300/0,v1:192.168.100.132:6789/0]}, election epoch 34, leader 0 node0, quorum 0,1,2 node0,node1,node2
[root@node0 ceph-deploy]# ceph mon dump
epoch 3
fsid 97702c43-6cc2-4ef8-bdb5-855cfa90a260
last_changed 2022-10-13 17:57:43.445773
created 2022-10-13 14:03:09.897152
min_mon_release 14 (nautilus)
0: [v2:192.168.100.130:3300/0,v1:192.168.100.130:6789/0] mon.node0
1: [v2:192.168.100.131:3300/0,v1:192.168.100.131:6789/0] mon.node1
2: [v2:192.168.100.132:3300/0,v1:192.168.100.132:6789/0] mon.node2
dumped monmap epoch 3
- 查看 mon 仲裁信息
[root@node0 ceph-deploy]# ceph quorum_status
{"election_epoch":34,"quorum":[0,1,2],"quorum_names":["node0","node1","node2"],"quorum_leader_name":"node0","quorum_age":152319,"monmap":{"epoch":3,"fsid":"97702c43-6cc2-4ef8-bdb5-855cfa90a260","modified":"2022-10-13 17:57:43.445773","created":"2022-10-13 14:03:09.897152","min_mon_release":14,"min_mon_release_name":"nautilus","features":{"persistent":["kraken","luminous","mimic","osdmap-prune","nautilus"],"optional":[]},"mons":[{"rank":0,"name":"node0","public_addrs":{"addrvec":[{"type":"v2","addr":"192.168.100.130:3300","nonce":0},{"type":"v1","addr":"192.168.100.130:6789","nonce":0}]},"addr":"192.168.100.130:6789/0","public_addr":"192.168.100.130:6789/0"},{"rank":1,"name":"node1","public_addrs":{"addrvec":[{"type":"v2","addr":"192.168.100.131:3300","nonce":0},{"type":"v1","addr":"192.168.100.131:6789","nonce":0}]},"addr":"192.168.100.131:6789/0","public_addr":"192.168.100.131:6789/0"},{"rank":2,"name":"node2","public_addrs":{"addrvec":[{"type":"v2","addr":"192.168.100.132:3300","nonce":0},{"type":"v1","addr":"192.168.100.132:6789","nonce":0}]},"addr":"192.168.100.132:6789/0","public_addr":"192.168.100.132:6789/0"}]}}
集群 mds 监控
[root@node0 ceph-deploy]# ceph mds stat
ceph fs dumpcephfs-demo:1 {0=node1=up:active} 2 up:standby
[root@node0 ceph-deploy]# ceph fs dump
e17
enable_multiple, ever_enabled_multiple: 0,0
compat: compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
legacy client fscid: 1
Filesystem 'cephfs-demo' (1)
fs_name cephfs-demo
epoch 17
flags 12
created 2022-10-21 16:47:10.066665
modified 2022-10-21 18:23:02.523832
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
min_compat_client -1 (unspecified)
last_failure 0
last_failure_osd_epoch 71
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=no anchor table,9=file layout v2,10=snaprealm v2}
max_mds 1
in 0
up {0=34638}
failed
damaged
stopped
data_pools [9]
metadata_pool 8
inline_data disabled
balancer
standby_count_wanted 1
[mds.node1{0:34638} state up:active seq 28 addr [v2:192.168.100.131:6800/3992748387,v1:192.168.100.131:6801/3992748387]]
Standby daemons:
[mds.node2{-1:34641} state up:standby seq 2 addr [v2:192.168.100.132:6800/3052708911,v1:192.168.100.132:6801/3052708911]]
[mds.node0{-1:54117} state up:standby seq 1 addr [v2:192.168.100.130:6800/2560866791,v1:192.168.100.130:6801/2560866791]]
dumped fsmap epoch 17
admin socket
查看某个具体的守护进程 socket 配置
# 查看 socket 配置帮助信息
[root@node0 ceph-deploy]# ceph --admin-daemon /var/run/ceph/ceph-mon.node0.asok help
{
"add_bootstrap_peer_hint": "add peer address as potential bootstrap peer for cluster bringup",
"add_bootstrap_peer_hintv": "add peer address vector as potential bootstrap peer for cluster bringup",
"config diff": "dump diff of current config and default config",
"config diff get": "dump diff get <field>: dump diff of current and default config setting <field>",
"config get": "config get <field>: get the config value",
"config help": "get config setting schema and descriptions",
"config set": "config set <field> <val> [<val> ...]: set a config variable",
"config show": "dump current config settings",
"config unset": "config unset <field>: unset a config variable",
"dump_historic_ops": "show recent ops",
"dump_historic_ops_by_duration": "show recent ops, sorted by duration",
"dump_historic_slow_ops": "show recent slow ops",
"dump_mempools": "get mempool stats",
"get_command_descriptions": "list available commands",
"git_version": "get git sha1",
"help": "list available commands",
"log dump": "dump recent log entries to log file",
"log flush": "flush log entries to log file",
"log reopen": "reopen log file",
"mon_status": "show current monitor status",
"ops": "show the ops currently in flight",
"perf dump": "dump perfcounters value",
"perf histogram dump": "dump perf histogram values",
"perf histogram schema": "dump perf histogram schema",
"perf reset": "perf reset <name>: perf reset all or one perfcounter name",
"perf schema": "dump perfcounters schema",
"quorum enter": "force monitor back into quorum",
"quorum exit": "force monitor out of the quorum",
"quorum_status": "show current quorum status",
"sessions": "list existing sessions",
"sync_force": "force sync of and clear monitor store",
"version": "get ceph version"
}
# 查看 mon 时钟相关的配置
[root@node0 ceph-deploy]# ceph --admin-daemon /var/run/ceph/ceph-mon.node0.asok config show | grep clock
"mon_clock_drift_allowed": "0.050000",
"mon_clock_drift_warn_backoff": "5.000000",
"osd_op_queue_mclock_anticipation_timeout": "0.000000",
"osd_op_queue_mclock_client_op_lim": "0.000000",
"osd_op_queue_mclock_client_op_res": "1000.000000",
"osd_op_queue_mclock_client_op_wgt": "500.000000",
"osd_op_queue_mclock_osd_rep_op_lim": "0.000000",
"osd_op_queue_mclock_osd_rep_op_res": "1000.000000",
"osd_op_queue_mclock_osd_rep_op_wgt": "500.000000",
"osd_op_queue_mclock_peering_event_lim": "0.001000",
"osd_op_queue_mclock_peering_event_res": "0.000000",
"osd_op_queue_mclock_peering_event_wgt": "1.000000",
"osd_op_queue_mclock_pg_delete_lim": "0.001000",
"osd_op_queue_mclock_pg_delete_res": "0.000000",
"osd_op_queue_mclock_pg_delete_wgt": "1.000000",
"osd_op_queue_mclock_recov_lim": "0.001000",
"osd_op_queue_mclock_recov_res": "0.000000",
"osd_op_queue_mclock_recov_wgt": "1.000000",
"osd_op_queue_mclock_scrub_lim": "0.001000",
"osd_op_queue_mclock_scrub_res": "0.000000",
"osd_op_queue_mclock_scrub_wgt": "1.000000",
"osd_op_queue_mclock_snap_lim": "0.001000",
"osd_op_queue_mclock_snap_res": "0.000000",
"osd_op_queue_mclock_snap_wgt": "1.000000",
"rgw_dmclock_admin_lim": "0.000000",
"rgw_dmclock_admin_res": "100.000000",
"rgw_dmclock_admin_wgt": "100.000000",
"rgw_dmclock_auth_lim": "0.000000",
"rgw_dmclock_auth_res": "200.000000",
"rgw_dmclock_auth_wgt": "100.000000",
"rgw_dmclock_data_lim": "0.000000",
"rgw_dmclock_data_res": "500.000000",
"rgw_dmclock_data_wgt": "500.000000",
"rgw_dmclock_metadata_lim": "0.000000",
"rgw_dmclock_metadata_res": "500.000000",
"rgw_dmclock_metadata_wgt": "500.000000",
# 查看选举仲裁相关的信息
[root@node0 ceph-deploy]# ceph --admin-daemon /var/run/ceph/ceph-mon.node0.asok quorum_status
{
"election_epoch": 34,
"quorum": [
0,
1,
2
],
"quorum_names": [
"node0",
"node1",
"node2"
],
"quorum_leader_name": "node0",
"quorum_age": 152848,
"monmap": {
"epoch": 3,
"fsid": "97702c43-6cc2-4ef8-bdb5-855cfa90a260",
"modified": "2022-10-13 17:57:43.445773",
"created": "2022-10-13 14:03:09.897152",
"min_mon_release": 14,
"min_mon_release_name": "nautilus",
"features": {
"persistent": [
"kraken",
"luminous",
"mimic",
"osdmap-prune",
"nautilus"
],
"optional": []
},
"mons": [
{
"rank": 0,
"name": "node0",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "192.168.100.130:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "192.168.100.130:6789",
"nonce": 0
}
]
},
"addr": "192.168.100.130:6789/0",
"public_addr": "192.168.100.130:6789/0"
},
{
"rank": 1,
"name": "node1",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "192.168.100.131:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "192.168.100.131:6789",
"nonce": 0
}
]
},
"addr": "192.168.100.131:6789/0",
"public_addr": "192.168.100.131:6789/0"
},
{
"rank": 2,
"name": "node2",
"public_addrs": {
"addrvec": [
{
"type": "v2",
"addr": "192.168.100.132:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "192.168.100.132:6789",
"nonce": 0
}
]
},
"addr": "192.168.100.132:6789/0",
"public_addr": "192.168.100.132:6789/0"
}
]
}
}
# 设置 socket 参数
[root@node0 ceph-deploy]# #ceph --admin-daemon /var/run/ceph/ceph-mon.node0.asok config set mon_clock_drift_allowed 1.0
Ceph 资源池管理
Pools
pools 提供 快速自我恢复,包含多个pg,crush rules 规则定义数据如何存放,快照
Pools are logical partitions for storing objects.
When you first deploy a cluster without creating a pool, Ceph uses the default
pools for storing data. A pool provides you with:
- Resilience: You can set how many OSD are allowed to fail without losing data.
For replicated pools, it is the desired number of copies/replicas of an object.
A typical configuration stores an object and two additional copies
(i.e.,size = 3), but you can configure the number of copies/replicas at
pool granularity.
For erasure coded pools, it is the number of coding chunks
(i.e.m=2in the erasure code profile) - Placement Groups: You can set the number of placement groups for the pool.
A typical configuration targets approximately 100 placement groups per OSD to
provide optimal balancing without using up too many computing resources. When
setting up multiple pools, be careful to set a reasonable number of
placement groups for each pool and for the cluster as a whole. Note that each PG
belongs to a specific pool, so when multiple pools use the same OSDs, you must
take care that the sum of PG replicas per OSD is in the desired PG per OSD
target range. - CRUSH Rules: When you store data in a pool, placement of the object
and its replicas (or chunks for erasure coded pools) in your cluster is governed
by CRUSH rules. You can create a custom CRUSH rule for your pool if the default
rule is not appropriate for your use case. - Snapshots: When you create snapshots with
ceph osd pool mksnap,
you effectively take a snapshot of a particular pool.
To organize data into pools, you can list, create, and remove pools.
You can also view the utilization statistics for each pool.
查看 pools
[root@node0 ceph-deploy]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_metadata
9 cephfs_data
创建一个 pools
For example:
osd_pool_default_pg_num = 128
osd_pool_default_pgp_num = 128
To create a pool, execute:
ceph osd pool create {pool-name} [{pg-num} [{pgp-num}]] [replicated] \
[crush-rule-name] [expected-num-objects]
ceph osd pool create {pool-name} [{pg-num} [{pgp-num}]] erasure \
[erasure-code-profile] [crush-rule-name] [expected_num_objects] [--autoscale-mode=<on,off,warn>]
[root@node0 ceph-deploy]# ceph osd pool create pool-demo 16 16
pool 'pool-demo' created
获取 pools 参数
[root@node0 ceph-deploy]# ceph osd pool get pool
Invalid command: missing required parameter var(size|min_size|pg_num|pgp_num|crush_rule|hashpspool|nodelete|nopgchange|nosizechange|write_fadvise_dontneed|noscrub|nodeep-scrub|hit_set_type|hit_set_period|hit_set_count|hit_set_fpp|use_gmt_hitset|target_max_objects|target_max_bytes|cache_target_dirty_ratio|cache_target_dirty_high_ratio|cache_target_full_ratio|cache_min_flush_age|cache_min_evict_age|erasure_code_profile|min_read_recency_for_promote|all|min_write_recency_for_promote|fast_read|hit_set_grade_decay_rate|hit_set_search_last_n|scrub_min_interval|scrub_max_interval|deep_scrub_interval|recovery_priority|recovery_op_priority|scrub_priority|compression_mode|compression_algorithm|compression_required_ratio|compression_max_blob_size|compression_min_blob_size|csum_type|csum_min_block|csum_max_block|allow_ec_overwrites|fingerprint_algorithm|pg_autoscale_mode|pg_autoscale_bias|pg_num_min|target_size_bytes|target_size_ratio)
osd pool get <poolname> size|min_size|pg_num|pgp_num|crush_rule|hashpspool|nodelete|nopgchange|nosizechange|write_fadvise_dontneed|noscrub|nodeep-scrub|hit_set_type|hit_set_period|hit_set_count|hit_set_fpp|use_gmt_hitset|target_max_objects|target_max_bytes|cache_target_dirty_ratio|cache_target_dirty_high_ratio|cache_target_full_ratio|cache_min_flush_age|cache_min_evict_age|erasure_code_profile|min_read_recency_for_promote|all|min_write_recency_for_promote|fast_read|hit_set_grade_decay_rate|hit_set_search_last_n|scrub_min_interval|scrub_max_interval|deep_scrub_interval|recovery_priority|recovery_op_priority|scrub_priority|compression_mode|compression_algorithm|compression_required_ratio|compression_max_blob_size|compression_min_blob_size|csum_type|csum_min_block|csum_max_block|allow_ec_overwrites|fingerprint_algorithm|pg_autoscale_mode|pg_autoscale_bias|pg_num_min|target_size_bytes|target_size_ratio : get pool parameter <var>
Error EINVAL: invalid command
查看 pools
[root@node0 ceph-deploy]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_metadata
9 cephfs_data
10 pool-demo
查看新建 pool-demo size 配置
[root@node0 ceph-deploy]# ceph osd pool get pool-demo size
size: 3
查看新建 pool-demo pg_num 配置
[root@node0 ceph-deploy]# ceph osd pool get pool-demo pg_num
pg_num: 16
修改新建 pool-demo size 配置
[root@node0 ceph-deploy]# ceph osd pool set pool-demo size 2
set pool 10 size to 2
[root@node0 ceph-deploy]# ceph osd pool get pool-demo size
size: 2
设置 pools application
对资源池类型进行分类,有 cephfs(文件系统) rwg(object对象存储) rbd(块设备) 3种资源池类型
[root@node0 ceph-deploy]# ceph -h | grep appl
osd pool application disable <poolname> <app> {--yes-i-really-mean-it} disables use of an application <app> on pool <poolname>
osd pool application enable <poolname> <app> {--yes-i-really-mean-it} enable use of an application <app> [cephfs,rbd,rgw] on pool <poolname>
osd pool application get {<poolname>} {<app>} {<key>} get value of key <key> of application <app> on pool <poolname>
osd pool application rm <poolname> <app> <key> removes application <app> metadata key <key> on pool <poolname>
osd pool application set <poolname> <app> <key> <value> sets application <app> metadata key <key> to <value> on pool <poolname>
[root@node0 ceph-deploy]# ceph osd pool application get pool-demo
{}
[root@node0 ceph-deploy]# ceph osd pool application enable pool-demo rbd
enabled application 'rbd' on pool 'pool-demo'
[root@node0 ceph-deploy]# ceph osd pool application get pool-demo
{
"rbd": {}
}
设置磁盘配额
[root@node0 ceph-deploy]# ceph -h | grep quota
osd pool get-quota <poolname> obtain object or byte limits for pool
osd pool set-quota <poolname> max_objects|max_bytes <val> set object or byte limit on pool
[root@node0 ceph-deploy]# ceph osd pool set-quota pool-demo max_objects 100
set-quota max_objects = 100 for pool pool-demo
[root@node0 ceph-deploy]# ceph osd pool get-quota pool-demo
quotas for pool 'pool-demo':
max objects: 100 objects
max bytes : N/A
pools 容量查看
[root@node0 ceph-deploy]# rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.rgw.root 768 KiB 4 0 12 0 0 0 23 23 KiB 4 4 KiB 0 B 0 B
ceph-demo 603 MiB 103 0 206 0 0 0 1476 6.5 MiB 362 309 MiB 0 B 0 B
cephfs_data 576 KiB 3 0 9 0 0 0 0 0 B 3 4 KiB 0 B 0 B
cephfs_metadata 1.5 MiB 22 0 66 0 0 0 33 54 KiB 87 50 KiB 0 B 0 B
default.rgw.buckets.data 192 KiB 1 0 3 0 0 0 6883 8.4 MiB 22480 32 MiB 0 B 0 B
default.rgw.buckets.index 243 B 3 0 9 0 0 0 20762 21 MiB 10374 5.1 MiB 0 B 0 B
default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B 0 B 0 B
default.rgw.log 0 B 207 0 621 0 0 0 299479 292 MiB 199590 2 KiB 0 B 0 B
default.rgw.meta 1.7 MiB 10 0 30 0 0 0 49 45 KiB 39 18 KiB 0 B 0 B
pool-demo 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B
total_objects 361
total_used 6.8 GiB
total_avail 293 GiB
total_space 300 GiB
[root@node0 ceph-deploy]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 300 GiB 293 GiB 862 MiB 6.8 GiB 2.28
TOTAL 300 GiB 293 GiB 862 MiB 6.8 GiB 2.28
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
ceph-demo 1 128 300 MiB 103 603 MiB 0.21 139 GiB
.rgw.root 2 32 1.2 KiB 4 768 KiB 0 93 GiB
default.rgw.control 3 32 0 B 8 0 B 0 93 GiB
default.rgw.meta 4 32 2.5 KiB 10 1.7 MiB 0 93 GiB
default.rgw.log 5 32 0 B 207 0 B 0 93 GiB
default.rgw.buckets.index 6 32 243 B 3 243 B 0 93 GiB
default.rgw.buckets.data 7 32 465 B 1 192 KiB 0 93 GiB
cephfs_metadata 8 16 16 KiB 22 1.5 MiB 0 93 GiB
cephfs_data 9 16 2.0 KiB 3 576 KiB 0 93 GiB
pool-demo 10 16 0 B 0 0 B 0 139 GiB
Ceph PG 数据分布
什么是 PG
pg 关联在 pool上,pg 内部存放着 obj,pg 通过 crush map 算法落在 osd上
A placement group (PG) aggregates objects within a pool because
tracking object placement and object metadata on a per-object basis is
computationally expensive--i.e., a system with millions of objects
cannot realistically track placement on a per-object basis.
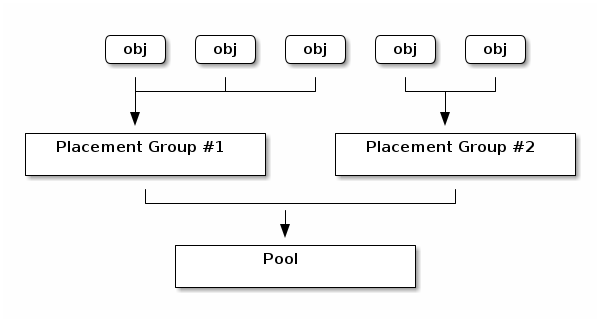
The Ceph client will calculate which placement group an object should
be in. It does this by hashing the object ID and applying an operation
based on the number of PGs in the defined pool and the ID of the pool.
See Mapping PGs to OSDs for details.
The object’s contents within a placement group are stored in a set of
OSDs. For instance, in a replicated pool of size two, each placement
group will store objects on two OSDs, as shown below.
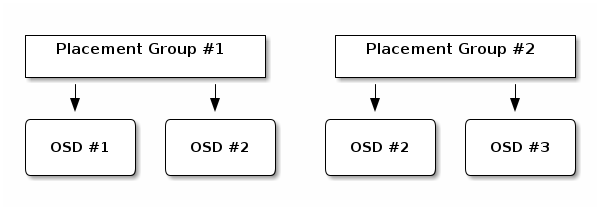
Should OSD #2 fail, another will be assigned to Placement Group #1 and
will be filled with copies of all objects in OSD #1. If the pool size
is changed from two to three, an additional OSD will be assigned to
the placement group and will receive copies of all objects in the
placement group.
Placement groups do not own the OSD; they share it with other
placement groups from the same pool or even other pools. If OSD #2
fails, the Placement Group #2 will also have to restore copies of
objects, using OSD #3.
When the number of placement groups increases, the new placement
groups will be assigned OSDs. The result of the CRUSH function will
also change and some objects from the former placement groups will be
copied over to the new Placement Groups and removed from the old ones.
pg 作用
决定数据分布情况
pg 越多,数据越分散,丢数据概率下,
pg 越少,数据越集中不分散,丢数据概率高
提供计算的效率
没有pg的情况,每个 obj 落入到osd,对 ceph 计算负载大
有了 pg 后,pg 会存放多个 obj,大大加快计算效率
pg 如何设置
输入计算设置的 pg
If you have more than 50 OSDs, we recommend approximately 50-100
placement groups per OSD to balance out resource usage, data
durability and distribution. If you have less than 50 OSDs, choosing
among the preselection above is best. For a single pool of objects,
you can use the following formula to get a baseline
Total PGs =\frac{OSDs×100pool}{size}
Where pool size is either the number of replicas for replicated
pools or the K+M sum for erasure coded pools (as returned by ceph
osd erasure-code-profile get).
You should then check if the result makes sense with the way you
designed your Ceph cluster to maximize data durability,
object distribution and minimize resource usage.
The result should always be rounded up to the nearest power of two.
Only a power of two will evenly balance the number of objects among
placement groups. Other values will result in an uneven distribution of
data across your OSDs. Their use should be limited to incrementally
stepping from one power of two to another.
As an example, for a cluster with 200 OSDs and a pool size of 3
replicas, you would estimate your number of PGs as follows
\frac{200×100}{3}=6667
Nearest power of 2: 8192
When using multiple data pools for storing objects, you need to ensure
that you balance the number of placement groups per pool with the
number of placement groups per OSD so that you arrive at a reasonable
total number of placement groups that provides reasonably low variance
per OSD without taxing system resources or making the peering process
too slow.
For instance a cluster of 10 pools each with 512 placement groups on
ten OSDs is a total of 5,120 placement groups spread over ten OSDs,
that is 512 placement groups per OSD. That does not use too many
resources. However, if 1,000 pools were created with 512 placement
groups each, the OSDs will handle ~50,000 placement groups each and it
would require significantly more resources and time for peering.
You may find the PGCalc tool helpful.
Ceph 参数配置调整
删除 pool
# 查看 pool
[root@node0 ceph-deploy]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_metadata
9 cephfs_data
10 pool-demo
# 删除 pool
[root@node0 ceph-deploy]# ceph osd pool rm pool-demo pool-demo --yes-i-really-really-mean-it
Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool
# 查看 pool
[root@node0 ceph-deploy]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_metadata
9 cephfs_data
10 pool-demo
# 查看服务配置,默认不允许删除 pool
[root@node0 ceph-deploy]# ceph --admin-daemon /var/run/ceph/ceph-mon.node0.asok config show | grep mon_allow_pool_delete
"mon_allow_pool_delete": "false",
3 个节点临时修改配置
[root@node0 ceph-deploy]# ceph --admin-daemon /var/run/ceph/ceph-mon.node0.asok config set mon_allow_pool_delete true
{
"success": "mon_allow_pool_delete = 'true' "
}
[root@node0 ceph-deploy]# ceph --admin-daemon /var/run/ceph/ceph-mon.node0.asok config show | grep mon_allow_pool_delete
"mon_allow_pool_delete": "true",
[root@node0 ceph-deploy]# ssh node1
Last login: Sat Oct 22 00:01:33 2022 from node0
[root@node1 ~]# ceph --admin-daemon /var/run/ceph/ceph-mon.node1.asok config set mon_allow_pool_delete true
{
"success": "mon_allow_pool_delete = 'true' "
}
[root@node1 ~]# exit
logout
Connection to node1 closed.
[root@node0 ceph-deploy]# ssh node2
Last login: Sat Oct 22 13:01:28 2022 from node0
[root@node2 ~]# ceph --admin-daemon /var/run/ceph/ceph-mon.node2.asok config set mon_allow_pool_delete true
{
"success": "mon_allow_pool_delete = 'true' "
}
[root@node2 ~]# exit
logout
Connection to node2 closed.
再次删除 pool
[root@node0 ceph-deploy]# ceph osd pool rm pool-demo pool-demo --yes-i-really-really-mean-it
pool 'pool-demo' removed
[root@node0 ceph-deploy]# ceph osd lspools
1 ceph-demo
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_metadata
9 cephfs_data
重启服务后失效
[root@node0 ceph-deploy]# systemctl restart ceph-mon@node0
[root@node0 ceph-deploy]# ceph --admin-daemon /var/run/ceph/ceph-mon.node0.asok config show | grep mon_allow_pool_delete
"mon_allow_pool_delete": "false",
永久生效
# 填写新的配置信息 mon_allow_pool_delete = true
[root@node0 ceph-deploy]# cat ceph.conf
[global]
fsid = 97702c43-6cc2-4ef8-bdb5-855cfa90a260
public_network = 192.168.100.0/24
cluster_network = 192.168.100.0/24
mon_initial_members = node0
mon_host = 192.168.100.130
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
mon_max_pg_per_osd=1000
mon_allow_pool_delete = true # 新增配置项
[client.rgw.node0]
rgw_frontends = "civetweb port=80"
# 推送配置文件
[root@node0 ceph-deploy]# ceph-deploy --overwrite-conf config push node0 node1 node2
# 重启服务
[root@node0 ceph-deploy]# ansible all -m shell -a "systemctl restart ceph-mon.target"
node0 | CHANGED | rc=0 >>
node1 | CHANGED | rc=0 >>
node2 | CHANGED | rc=0 >>
# 查看配置是否生效
[root@node0 ceph-deploy]# ansible all -m shell -a "ceph --admin-daemon /var/run/ceph/ceph-mon.node*.asok config show | grep mon_allow_pool_delete"
node0 | CHANGED | rc=0 >>
"mon_allow_pool_delete": "true",
node1 | CHANGED | rc=0 >>
"mon_allow_pool_delete": "true",
node2 | CHANGED | rc=0 >>
"mon_allow_pool_delete": "true",

 浙公网安备 33010602011771号
浙公网安备 33010602011771号