06 OSD 扩容和换盘
OSD 纵向扩容
OSD 扩容可以分为纵向扩容(scale up)和横行扩容(scale out)
纵向扩容(scale up):扩容服务器的磁盘空间,完成对 OSD 空间的扩容
横行扩容(scale out):添加新的服务器加入集群,完成对 OSD 空间的扩容,要求新服务器也需要从 0-1 部署 ceph 集群服务
OSD node0 新增一块磁盘
[root@node0 ceph-deploy]# cd /data/ceph-deploy/
# 添加新的磁盘
[root@node0 ceph-deploy]# ceph-deploy osd create node0 --data /dev/sdc
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy osd create node0 --data /dev/sdc
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] bluestore : None
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7f3f155ad998>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] fs_type : xfs
[ceph_deploy.cli][INFO ] block_wal : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] journal : None
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] host : node0
[ceph_deploy.cli][INFO ] filestore : None
[ceph_deploy.cli][INFO ] func : <function osd at 0x7f3f155dd938>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] zap_disk : False
[ceph_deploy.cli][INFO ] data : /dev/sdc
[ceph_deploy.cli][INFO ] block_db : None
[ceph_deploy.cli][INFO ] dmcrypt : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] dmcrypt_key_dir : /etc/ceph/dmcrypt-keys
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.osd][DEBUG ] Creating OSD on cluster ceph with data device /dev/sdc
[node0][DEBUG ] connected to host: node0
[node0][DEBUG ] detect platform information from remote host
[node0][DEBUG ] detect machine type
[node0][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.9.2009 Core
[ceph_deploy.osd][DEBUG ] Deploying osd to node0
[node0][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[node0][DEBUG ] find the location of an executable
[node0][INFO ] Running command: /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sdc
[node0][WARNIN] Running command: /usr/bin/ceph-authtool --gen-print-key
[node0][WARNIN] Running command: /usr/bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -i - osd new b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9
[node0][WARNIN] Running command: /usr/sbin/vgcreate --force --yes ceph-18f50dfb-d14b-43ec-b40b-40d4fd9bff1f /dev/sdc
[node0][WARNIN] stdout: Physical volume "/dev/sdc" successfully created.
[node0][WARNIN] stdout: Volume group "ceph-18f50dfb-d14b-43ec-b40b-40d4fd9bff1f" successfully created
[node0][WARNIN] Running command: /usr/sbin/lvcreate --yes -l 12799 -n osd-block-b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9 ceph-18f50dfb-d14b-43ec-b40b-40d4fd9bff1f
[node0][WARNIN] stdout: Logical volume "osd-block-b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9" created.
[node0][WARNIN] Running command: /usr/bin/ceph-authtool --gen-print-key
[node0][WARNIN] Running command: /usr/bin/mount -t tmpfs tmpfs /var/lib/ceph/osd/ceph-3
[node0][WARNIN] Running command: /usr/bin/chown -h ceph:ceph /dev/ceph-18f50dfb-d14b-43ec-b40b-40d4fd9bff1f/osd-block-b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9
[node0][WARNIN] Running command: /usr/bin/chown -R ceph:ceph /dev/dm-3
[node0][WARNIN] Running command: /usr/bin/ln -s /dev/ceph-18f50dfb-d14b-43ec-b40b-40d4fd9bff1f/osd-block-b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9 /var/lib/ceph/osd/ceph-3/block
[node0][WARNIN] Running command: /usr/bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring mon getmap -o /var/lib/ceph/osd/ceph-3/activate.monmap
[node0][WARNIN] stderr: 2022-10-21 18:24:15.253 7f7d62f34700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
[node0][WARNIN] 2022-10-21 18:24:15.253 7f7d62f34700 -1 AuthRegistry(0x7f7d5c0662f8) no keyring found at /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx
[node0][WARNIN] stderr: got monmap epoch 3
[node0][WARNIN] Running command: /usr/bin/ceph-authtool /var/lib/ceph/osd/ceph-3/keyring --create-keyring --name osd.3 --add-key AQBOc1Jjx5srLBAA6OZuZM8JGED2o2B3hBa52A==
[node0][WARNIN] stdout: creating /var/lib/ceph/osd/ceph-3/keyring
[node0][WARNIN] added entity osd.3 auth(key=AQBOc1Jjx5srLBAA6OZuZM8JGED2o2B3hBa52A==)
[node0][WARNIN] Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3/keyring
[node0][WARNIN] Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3/
[node0][WARNIN] Running command: /usr/bin/ceph-osd --cluster ceph --osd-objectstore bluestore --mkfs -i 3 --monmap /var/lib/ceph/osd/ceph-3/activate.monmap --keyfile - --osd-data /var/lib/ceph/osd/ceph-3/ --osd-uuid b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9 --setuser ceph --setgroup ceph
[node0][WARNIN] stderr: 2022-10-21 18:24:15.614 7ff9c213ca80 -1 bluestore(/var/lib/ceph/osd/ceph-3/) _read_fsid unparsable uuid
[node0][WARNIN] --> ceph-volume lvm prepare successful for: /dev/sdc
[node0][WARNIN] Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3
[node0][WARNIN] Running command: /usr/bin/ceph-bluestore-tool --cluster=ceph prime-osd-dir --dev /dev/ceph-18f50dfb-d14b-43ec-b40b-40d4fd9bff1f/osd-block-b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9 --path /var/lib/ceph/osd/ceph-3 --no-mon-config
[node0][WARNIN] Running command: /usr/bin/ln -snf /dev/ceph-18f50dfb-d14b-43ec-b40b-40d4fd9bff1f/osd-block-b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9 /var/lib/ceph/osd/ceph-3/block
[node0][WARNIN] Running command: /usr/bin/chown -h ceph:ceph /var/lib/ceph/osd/ceph-3/block
[node0][WARNIN] Running command: /usr/bin/chown -R ceph:ceph /dev/dm-3
[node0][WARNIN] Running command: /usr/bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-3
[node0][WARNIN] Running command: /usr/bin/systemctl enable ceph-volume@lvm-3-b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9
[node0][WARNIN] stderr: Created symlink from /etc/systemd/system/multi-user.target.wants/ceph-volume@lvm-3-b9d5f757-a8e7-459f-9cef-2dde0aa3a1f9.service to /usr/lib/systemd/system/ceph-volume@.service.
[node0][WARNIN] Running command: /usr/bin/systemctl enable --runtime ceph-osd@3
[node0][WARNIN] stderr: Created symlink from /run/systemd/system/ceph-osd.target.wants/ceph-osd@3.service to /usr/lib/systemd/system/ceph-osd@.service.
[node0][WARNIN] Running command: /usr/bin/systemctl start ceph-osd@3
[node0][WARNIN] --> ceph-volume lvm activate successful for osd ID: 3
[node0][WARNIN] --> ceph-volume lvm create successful for: /dev/sdc
[node0][INFO ] checking OSD status...
[node0][DEBUG ] find the location of an executable
[node0][INFO ] Running command: /bin/ceph --cluster=ceph osd stat --format=json
[ceph_deploy.osd][DEBUG ] Host node0 is now ready for osd use.
查看新添加磁盘
[root@node0 ceph-deploy]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.19519 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.04880 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
-7 0.04880 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
查看磁盘空间是否增加
[root@node0 ceph-deploy]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 200 GiB 195 GiB 731 MiB 4.7 GiB 2.36
TOTAL 200 GiB 195 GiB 731 MiB 4.7 GiB 2.36
POOLS:
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
ceph-demo 1 128 412 MiB 103 684 MiB 0.36 112 GiB
.rgw.root 2 32 1.5 KiB 4 768 KiB 0 74 GiB
default.rgw.control 3 32 0 B 8 0 B 0 62 GiB
default.rgw.meta 4 32 2.4 KiB 10 1.7 MiB 0 77 GiB
default.rgw.log 5 32 0 B 207 0 B 0 64 GiB
default.rgw.buckets.index 6 32 0 B 3 0 B 0 69 GiB
default.rgw.buckets.data 7 32 16 EiB 1 192 KiB 0 16 EiB
cephfs_metadata 8 16 21 KiB 22 1.8 MiB 0 62 GiB
cephfs_data 9 16 2.0 KiB 3 576 KiB 0 62 GiB
数据 rebalancing 重分布
Rebalancing
When you add a Ceph OSD Daemon to a Ceph Storage Cluster, the cluster map gets
updated with the new OSD. Referring back to Calculating PG IDs, this changes
the cluster map. Consequently, it changes object placement, because it changes
an input for the calculations. The following diagram depicts the rebalancing
process (albeit rather crudely, since it is substantially less impactful with
large clusters) where some, but not all of the PGs migrate from existing OSDs
(OSD 1, and OSD 2) to the new OSD (OSD 3). Even when rebalancing, CRUSH is
stable. Many of the placement groups remain in their original configuration,
and each OSD gets some added capacity, so there are no load spikes on the
new OSD after rebalancing is complete.
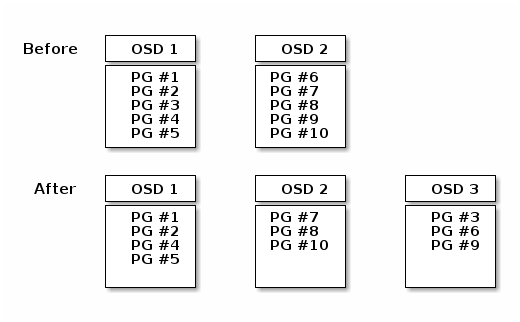
添加新 osd 磁盘,模拟数据重分布
ceph 集群新增 osd,默认会导致数据重分布(可以使用指令暂时禁止同步)。建议生产环境新增 osd 放到业务访问量少的情况进行
# 集群新增 osd
[root@node0 ceph-deploy]# ceph-deploy osd create node1 --data /dev/sdc
[root@node0 ceph-deploy]# ceph-deploy osd create node2 --data /dev/sdc
# 查看数据 rebalancing 重分布
[root@node0 ceph-deploy]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_WARN
Reduced data availability: 1 pg peering
Degraded data redundancy: 540/890 objects degraded (60.674%), 29 pgs degraded
services:
mon: 3 daemons, quorum node0,node1,node2 (age 5h)
mgr: node1(active, since 5h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 3s), 6 in (since 3s); 40 remapped pgs
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 323 objects, 241 MiB
usage: 6.8 GiB used, 293 GiB / 300 GiB avail
pgs: 22.159% pgs not active
540/890 objects degraded (60.674%)
154/890 objects misplaced (17.303%)
232 active+clean
73 peering
17 active+recovery_wait+degraded
12 active+recovery_wait+undersized+degraded+remapped
8 active+remapped+backfill_wait
5 remapped+peering
3 active+recovery_wait+remapped
1 active+recovering
1 active+recovering+undersized+remapped
io:
recovery: 0 B/s, 0 objects/s
progress:
Rebalancing after osd.4 marked in
[======================........]
Rebalancing after osd.5 marked in
[..............................]
[root@node0 ceph-deploy]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_WARN
Degraded data redundancy: 1794/980 objects degraded (183.061%), 93 pgs degraded
services:
mon: 3 daemons, quorum node0,node1,node2 (age 5h)
mgr: node1(active, since 5h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 10s), 6 in (since 10s); 37 remapped pgs
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.8 GiB used, 293 GiB / 300 GiB avail
pgs: 1794/980 objects degraded (183.061%)
167/980 objects misplaced (17.041%)
243 active+clean
64 active+recovery_wait+degraded
29 active+recovery_wait+undersized+degraded+remapped
9 active+remapped+backfill_wait
5 active+recovery_wait
1 active+recovering
1 active+recovering+undersized+remapped
io:
client: 185 KiB/s rd, 10 MiB/s wr, 22 op/s rd, 15 op/s wr
recovery: 9.3 MiB/s, 2 keys/s, 7 objects/s
progress:
Rebalancing after osd.4 marked in
[======================........]
Rebalancing after osd.5 marked in
[===============...............]
[root@node0 ceph-deploy]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_OK
services:
mon: 3 daemons, quorum node0,node1,node2 (age 5h)
mgr: node1(active, since 5h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 3m), 6 in (since 3m)
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.7 GiB used, 293 GiB / 300 GiB avail
pgs: 352 active+clean
io:
client: 4.0 KiB/s rd, 0 B/s wr, 3 op/s rd, 2 op/s wr
临时关闭 rebalancing
查看 rebalancing 的线程配置
建议使用 一个线程进行数据填充,使用默认配置即可
[root@node0 ceph-deploy]# ceph --admin-daemon /var/run/ceph/ceph-mon.node0.asok config show | grep max_b
......
"osd_max_backfills": "1", # osd 使用1个线程进行数据传输, 数据越大同步越快,但是会牺牲性能,数据 rebalancing 重分布的线程数
......
数据 rebalancing 时使用的网络
[root@node0 ceph-deploy]# cat /etc/ceph/ceph.conf
[global]
fsid = 97702c43-6cc2-4ef8-bdb5-855cfa90a260
public_network = 192.168.100.0/24 # 客户端连接使用的网络
cluster_network = 192.168.100.0/24 # 数据重分布,集群内部通信使用的网络,建议使用万兆网络。生产环境这2个网络最好分开,减少他们之间的影响
mon_initial_members = node0
mon_host = 192.168.100.130
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
mon_max_pg_per_osd=1000
[client.rgw.node0]
rgw_frontends = "civetweb port=80"
临时关闭 rebalancing
# 查看标志位
[root@node0 ceph-deploy]# ceph -h | grep reb
noin|nobackfill|norebalance|norecover|
noin|nobackfill|norebalance|norecover|
# 关闭 rebalance
[root@node0 ceph-deploy]# ceph osd set norebalance
norebalance is set
[root@node0 ceph-deploy]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_WARN
norebalance flag(s) set # 集群不健康,设置了 norebalance 标志位
services:
mon: 3 daemons, quorum node0,node1,node2 (age 15h)
mgr: node1(active, since 15h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 9h), 6 in (since 9h)
flags norebalance
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.7 GiB used, 293 GiB / 300 GiB avail
pgs: 352 active+clean
# 同步的还需要关闭 backfill 才能完全关闭数据填充
[root@node0 ceph-deploy]# ceph osd set nobackfill
nobackfill is set
[root@node0 ceph-deploy]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_WARN
nobackfill,norebalance flag(s) set # 设置了 nobackfill,norebalance 标志位
services:
mon: 3 daemons, quorum node0,node1,node2 (age 15h)
mgr: node1(active, since 15h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 9h), 6 in (since 9h)
flags nobackfill,norebalance
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.7 GiB used, 293 GiB / 300 GiB avail
pgs: 352 active+clean
开启 rebalancing 功能
[root@node0 ceph-deploy]# ceph osd unset nobackfill
nobackfill is unset
[root@node0 ceph-deploy]# ceph osd unset norebalance
norebalance is unset
[root@node0 ceph-deploy]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_OK
services:
mon: 3 daemons, quorum node0,node1,node2 (age 15h)
mgr: node1(active, since 15h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 9h), 6 in (since 9h)
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.7 GiB used, 293 GiB / 300 GiB avail
pgs: 352 active+clean
OSD 坏盘更换
磁盘坏盘后,需要剔除坏盘,并替换新磁盘
第一步:剔除坏磁盘
第二步:集群添加新硬盘
如何查看磁盘
[root@node2 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
查看磁盘延迟,巡检磁盘是否正常
延迟过大表示磁盘快要坏了,但是还未完全坏
[root@node0 ~]# ceph osd perf
osd commit_latency(ms) apply_latency(ms)
5 0 0
4 0 0
0 0 0
1 0 0
2 0 0
3 0 0
剔除坏磁盘
停止 ceph-osd@5 服务,模拟磁盘坏了
# 远程到 node2 节点
[root@node0 ceph-deploy]# ssh node2
Last login: Sat Oct 22 00:01:41 2022 from node0
# 查看磁盘信息
[root@node2 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 up 1.00000 1.00000
# 停止 ceph-osd@5 服务,模拟磁盘坏了
[root@node2 ~]# systemctl stop ceph-osd@5
查看磁盘信息和集群状态
# 再次查看磁盘信息
[root@node2 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 down 1.00000 1.00000
# 查看集群状态
[root@node2 ~]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_WARN
1 osds down
Reduced data availability: 22 pgs inactive, 75 pgs peering
Degraded data redundancy: 80/980 objects degraded (8.163%), 31 pgs degraded
services:
mon: 3 daemons, quorum node0,node1,node2 (age 17h)
mgr: node1(active, since 17h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 5 up (since 5s), 6 in (since 11h)
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.7 GiB used, 293 GiB / 300 GiB avail
pgs: 22.159% pgs not active
80/980 objects degraded (8.163%) # osd 磁盘坏掉后,暂时不会立刻开始 rebalancing,默认会等待一段时间后开始 数据重分布
188 active+clean
78 peering
55 active+undersized
31 active+undersized+degraded
从 osd map 中移除坏掉的磁盘,让 osd 立即开始 rebalancing
# 查看磁盘信息
[root@node2 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 down 1.00000 1.00000
# osd out 从 osd map 中移除坏磁盘
[root@node2 ~]# ceph osd out osd.5
marked out osd.5.
# 再次查看磁盘信息
[root@node2 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.29279 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.09760 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 hdd 0.04880 osd.5 down 0 1.00000 # osd.5 磁盘的 REWEIGHT 从 1 -> 0
# 查看集群状态,应该是在进行 rebalancing
[root@node2 ~]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_WARN
Degraded data redundancy: 872/980 objects degraded (88.980%), 53 pgs degraded
services:
mon: 3 daemons, quorum node0,node1,node2 (age 17h)
mgr: node1(active, since 17h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 5 up (since 2m), 5 in (since 27s); 24 remapped pgs
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 5.6 GiB used, 244 GiB / 250 GiB avail
pgs: 872/980 objects degraded (88.980%)
298 active+clean
28 active+recovery_wait+degraded
21 active+recovery_wait+undersized+degraded+remapped
4 active+undersized+degraded+remapped+backfill_wait
1 active+recovery_wait
io:
recovery: 35 B/s, 7 objects/s
从 crush map 中删除 osd.5 数据
# 查看 crush map 数据
[root@node2 ~]# ceph osd crush dump
{
"devices": [
......
{
"id": 4,
"name": "osd.4",
"class": "hdd"
},
{
"id": 5,
"name": "osd.5",
"class": "hdd"
}
],
"types": [
......
],
......
}
# 从 crush map 中删除 osd.5
[root@node2 ~]# ceph osd crush rm osd.5
removed item id 5 name 'osd.5' from crush map
# 再次查看 crush map 数据
[root@node2 ~]# ceph osd crush dump
{
"devices": [
......
{
"id": 4,
"name": "osd.4",
"class": "hdd"
} # 没有 osd.5 信息
],
"types": [
......
],
......
}
[root@node2 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.24399 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.04880 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
5 0 osd.5 down 0 1.00000
从 osd 中删除 osd.5
# 从 osd 中删除 osd.5
[root@node2 ~]# ceph osd rm osd.5
removed osd.5
# 查看 osd 磁盘数据,没有 osd.5 磁盘
[root@node2 ~]# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.24399 root default
-3 0.09760 host node0
0 hdd 0.04880 osd.0 up 1.00000 1.00000
3 hdd 0.04880 osd.3 up 1.00000 1.00000
-5 0.09760 host node1
1 hdd 0.04880 osd.1 up 1.00000 1.00000
4 hdd 0.04880 osd.4 up 1.00000 1.00000
-7 0.04880 host node2
2 hdd 0.04880 osd.2 up 1.00000 1.00000
# 查看集群状态
[root@node2 ~]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_OK
services:
mon: 3 daemons, quorum node0,node1,node2 (age 17h)
mgr: node1(active, since 17h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 5 osds: 5 up (since 48m), 5 in (since 46m) # 此处 osd 数据已经跟新为 5 块磁盘了
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 5.8 GiB used, 244 GiB / 250 GiB avail
pgs: 352 active+clean
从 auth 中删除 osd.5 认证数据
# 查看 auth 数据
[root@node2 ~]# ceph auth list
......
osd.4
key: AQAFxFJjgPC7GxAAVwvROc0Usys/XIVVOls/OQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
osd.5
key: AQAaxFJjz7wmNhAAQOtu8dC/DKtXihbiy2KdZw==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
......
# 从 auth 中删除 osd.5 认证数据
[root@node2 ~]# ceph auth rm osd.5
updated
# 再次查看 auth 数据
[root@node2 ~]# ceph auth list
......
osd.4
key: AQAFxFJjgPC7GxAAVwvROc0Usys/XIVVOls/OQ==
caps: [mgr] allow profile osd
caps: [mon] allow profile osd
caps: [osd] allow *
# 以及没有 osd.5 数据
......
卸载磁盘
[root@node2 ~]# umount /var/lib/ceph/osd/ceph-5
删除 lvm 删除逻辑卷
# 查看 /dev/sdc 磁盘 PV Name
[root@node0 ceph-deploy]# pvdisplay
......
--- Physical volume ---
PV Name /dev/sdc
VG Name ceph-0bf75583-89f5-4ce4-a703-667003938236
PV Size 50.00 GiB / not usable 4.00 MiB
Allocatable yes (but full)
PE Size 4.00 MiB
Total PE 12799
Free PE 0
Allocated PE 12799
PV UUID 6uIHbB-61oC-rbLg-K1HD-gPvc-yl80-R0gdVm
# 通过 PV Name 获取到 lvm 数据
[root@node2 ~]# lvdisplay | grep -B 2 "ceph-0bf75583-89f5-4ce4-a703-667003938236"
--- Logical volume ---
LV Path /dev/ceph-0bf75583-89f5-4ce4-a703-667003938236/osd-block-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7
LV Name osd-block-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7
VG Name ceph-0bf75583-89f5-4ce4-a703-667003938236
# dmsetup 查看当前 设备映射
[root@node2 ~]# dmsetup ls
ceph--90ab5473--6ad3--48b7--b733--64bc4baff012-osd--block--816b6503--9551--48a2--823e--1c6a52ea213b (253:2)
ceph--0bf75583--89f5--4ce4--a703--667003938236-osd--block--a69e2242--dbfc--4ed7--9e17--7d05fd2e6fe7 (253:3)
centos-swap (253:1)
centos-root (253:0)
[root@node2 ~]# dmsetup ls --tree
ceph--90ab5473--6ad3--48b7--b733--64bc4baff012-osd--block--816b6503--9551--48a2--823e--1c6a52ea213b (253:2)
└─ (8:16)
ceph--0bf75583--89f5--4ce4--a703--667003938236-osd--block--a69e2242--dbfc--4ed7--9e17--7d05fd2e6fe7 (253:3)
└─ (8:32)
centos-swap (253:1)
└─ (8:2)
centos-root (253:0)
└─ (8:2)
# 删除 /dev/sdc 设备映射
[root@node2 ~]# dmsetup remove --force /dev/mapper/ceph--0bf75583--89f5--4ce4--a703--667003938236-osd--block--a69e2242--dbfc--4ed7--9e17--7d05fd2e6fe7
# 再次查看当前 设备映射
[root@node2 ~]# dmsetup ls
ceph--90ab5473--6ad3--48b7--b733--64bc4baff012-osd--block--816b6503--9551--48a2--823e--1c6a52ea213b (253:2)
centos-swap (253:1)
centos-root (253:0)
[root@node2 ~]# dmsetup ls --tree
ceph--90ab5473--6ad3--48b7--b733--64bc4baff012-osd--block--816b6503--9551--48a2--823e--1c6a52ea213b (253:2)
└─ (8:16)
centos-swap (253:1)
└─ (8:2)
centos-root (253:0)
└─ (8:2)
添加新磁盘
重置 node2 /dev/sdc 磁盘
[root@node2 ~]# exit
logout
Connection to node2 closed.
[root@node0 ceph-deploy]# ceph-deploy disk zap node2 /dev/sdc
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy disk zap node2 /dev/sdc
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : zap
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7fd276ee0830>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] host : node2
[ceph_deploy.cli][INFO ] func : <function disk at 0x7fd276f149b0>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] disk : ['/dev/sdc']
[ceph_deploy.osd][DEBUG ] zapping /dev/sdc on node2
[node2][DEBUG ] connected to host: node2
[node2][DEBUG ] detect platform information from remote host
[node2][DEBUG ] detect machine type
[node2][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.9.2009 Core
[node2][DEBUG ] zeroing last few blocks of device
[node2][DEBUG ] find the location of an executable
[node2][INFO ] Running command: /usr/sbin/ceph-volume lvm zap /dev/sdc
[node2][WARNIN] --> Zapping: /dev/sdc
[node2][WARNIN] --> --destroy was not specified, but zapping a whole device will remove the partition table
[node2][WARNIN] Running command: /bin/dd if=/dev/zero of=/dev/sdc bs=1M count=10 conv=fsync
[node2][WARNIN] stderr: 10+0 records in
[node2][WARNIN] 10+0 records out
[node2][WARNIN] 10485760 bytes (10 MB) copied
[node2][WARNIN] stderr: , 0.00989675 s, 1.1 GB/s
[node2][WARNIN] --> Zapping successful for: <Raw Device: /dev/sdc>
添加新磁盘
[root@node0 ceph-deploy]# ceph-deploy osd create node2 --data /dev/sdc
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /usr/bin/ceph-deploy osd create node2 --data /dev/sdc
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] bluestore : None
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0x7ff65df77998>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] fs_type : xfs
[ceph_deploy.cli][INFO ] block_wal : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] journal : None
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] host : node2
[ceph_deploy.cli][INFO ] filestore : None
[ceph_deploy.cli][INFO ] func : <function osd at 0x7ff65dfa7938>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] zap_disk : False
[ceph_deploy.cli][INFO ] data : /dev/sdc
[ceph_deploy.cli][INFO ] block_db : None
[ceph_deploy.cli][INFO ] dmcrypt : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] dmcrypt_key_dir : /etc/ceph/dmcrypt-keys
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.osd][DEBUG ] Creating OSD on cluster ceph with data device /dev/sdc
[node2][DEBUG ] connected to host: node2
[node2][DEBUG ] detect platform information from remote host
[node2][DEBUG ] detect machine type
[node2][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.9.2009 Core
[ceph_deploy.osd][DEBUG ] Deploying osd to node2
[node2][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[node2][DEBUG ] find the location of an executable
[node2][INFO ] Running command: /usr/sbin/ceph-volume --cluster ceph lvm create --bluestore --data /dev/sdc
[node2][WARNIN] Running command: /bin/ceph-authtool --gen-print-key
[node2][WARNIN] Running command: /bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring -i - osd new a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7
[node2][WARNIN] Running command: /usr/sbin/vgcreate --force --yes ceph-0bf75583-89f5-4ce4-a703-667003938236 /dev/sdc
[node2][WARNIN] stdout: Physical volume "/dev/sdc" successfully created.
[node2][WARNIN] stdout: Volume group "ceph-0bf75583-89f5-4ce4-a703-667003938236" successfully created
[node2][WARNIN] Running command: /usr/sbin/lvcreate --yes -l 12799 -n osd-block-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7 ceph-0bf75583-89f5-4ce4-a703-667003938236
[node2][WARNIN] stdout: Logical volume "osd-block-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7" created.
[node2][WARNIN] Running command: /bin/ceph-authtool --gen-print-key
[node2][WARNIN] Running command: /bin/mount -t tmpfs tmpfs /var/lib/ceph/osd/ceph-5
[node2][WARNIN] Running command: /bin/chown -h ceph:ceph /dev/ceph-0bf75583-89f5-4ce4-a703-667003938236/osd-block-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7
[node2][WARNIN] Running command: /bin/chown -R ceph:ceph /dev/dm-3
[node2][WARNIN] Running command: /bin/ln -s /dev/ceph-0bf75583-89f5-4ce4-a703-667003938236/osd-block-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7 /var/lib/ceph/osd/ceph-5/block
[node2][WARNIN] Running command: /bin/ceph --cluster ceph --name client.bootstrap-osd --keyring /var/lib/ceph/bootstrap-osd/ceph.keyring mon getmap -o /var/lib/ceph/osd/ceph-5/activate.monmap
[node2][WARNIN] stderr: 2022-10-22 12:46:01.082 7f136d85b700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
[node2][WARNIN] 2022-10-22 12:46:01.082 7f136d85b700 -1 AuthRegistry(0x7f13680662f8) no keyring found at /etc/ceph/ceph.client.bootstrap-osd.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,, disabling cephx
[node2][WARNIN] stderr: got monmap epoch 3
[node2][WARNIN] Running command: /bin/ceph-authtool /var/lib/ceph/osd/ceph-5/keyring --create-keyring --name osd.5 --add-key AQCIdVNjfBsaJhAAJ+I6/GPW22v8jesXc2RLfQ==
[node2][WARNIN] stdout: creating /var/lib/ceph/osd/ceph-5/keyring
[node2][WARNIN] added entity osd.5 auth(key=AQCIdVNjfBsaJhAAJ+I6/GPW22v8jesXc2RLfQ==)
[node2][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-5/keyring
[node2][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-5/
[node2][WARNIN] Running command: /bin/ceph-osd --cluster ceph --osd-objectstore bluestore --mkfs -i 5 --monmap /var/lib/ceph/osd/ceph-5/activate.monmap --keyfile - --osd-data /var/lib/ceph/osd/ceph-5/ --osd-uuid a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7 --setuser ceph --setgroup ceph
[node2][WARNIN] stderr: 2022-10-22 12:46:01.398 7f1aac3e7a80 -1 bluestore(/var/lib/ceph/osd/ceph-5/) _read_fsid unparsable uuid
[node2][WARNIN] --> ceph-volume lvm prepare successful for: /dev/sdc
[node2][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-5
[node2][WARNIN] Running command: /bin/ceph-bluestore-tool --cluster=ceph prime-osd-dir --dev /dev/ceph-0bf75583-89f5-4ce4-a703-667003938236/osd-block-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7 --path /var/lib/ceph/osd/ceph-5 --no-mon-config
[node2][WARNIN] Running command: /bin/ln -snf /dev/ceph-0bf75583-89f5-4ce4-a703-667003938236/osd-block-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7 /var/lib/ceph/osd/ceph-5/block
[node2][WARNIN] Running command: /bin/chown -h ceph:ceph /var/lib/ceph/osd/ceph-5/block
[node2][WARNIN] Running command: /bin/chown -R ceph:ceph /dev/dm-3
[node2][WARNIN] Running command: /bin/chown -R ceph:ceph /var/lib/ceph/osd/ceph-5
[node2][WARNIN] Running command: /bin/systemctl enable ceph-volume@lvm-5-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7
[node2][WARNIN] stderr: Created symlink from /etc/systemd/system/multi-user.target.wants/ceph-volume@lvm-5-a69e2242-dbfc-4ed7-9e17-7d05fd2e6fe7.service to /usr/lib/systemd/system/ceph-volume@.service.
[node2][WARNIN] Running command: /bin/systemctl enable --runtime ceph-osd@5
[node2][WARNIN] Running command: /bin/systemctl start ceph-osd@5
[node2][WARNIN] --> ceph-volume lvm activate successful for osd ID: 5
[node2][WARNIN] --> ceph-volume lvm create successful for: /dev/sdc
[node2][INFO ] checking OSD status...
[node2][DEBUG ] find the location of an executable
[node2][INFO ] Running command: /bin/ceph --cluster=ceph osd stat --format=json
[ceph_deploy.osd][DEBUG ] Host node2 is now ready for osd use.
# 查看集群状态
[root@node0 ceph-deploy]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_WARN
Reduced data availability: 3 pgs inactive, 12 pgs peering
Degraded data redundancy: 276/958 objects degraded (28.810%), 13 pgs degraded
services:
mon: 3 daemons, quorum node0,node1,node2 (age 18h)
mgr: node1(active, since 18h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 4s), 6 in (since 4s); 27 remapped pgs
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 350 objects, 277 MiB
usage: 6.8 GiB used, 293 GiB / 300 GiB avail
pgs: 25.852% pgs not active
276/958 objects degraded (28.810%)
8/958 objects misplaced (0.835%)
245 active+clean
86 peering
8 active+recovery_wait+degraded
5 remapped+peering
5 active+recovery_wait+undersized+degraded+remapped
1 active+recovery_wait
1 active+remapped+backfill_wait
1 active+recovering
io:
recovery: 0 B/s, 2 keys/s, 14 objects/s
progress:
Rebalancing after osd.5 marked in
[..............................]
数据一致性检查
Data Consistency
As part of maintaining data consistency and cleanliness, Ceph OSDs also scrub
objects within placement groups. That is, Ceph OSDs compare object metadata in
one placement group with its replicas in placement groups stored in other
OSDs. Scrubbing (usually performed daily) catches OSD bugs or filesystem
errors, often as a result of hardware issues. OSDs also perform deeper
scrubbing by comparing data in objects bit-for-bit. Deep scrubbing (by default
performed weekly) finds bad blocks on a drive that weren’t apparent in a light
scrub.
See Data Scrubbing for details on configuring scrubbing.
高可用 osd 存储数据,如何确保数据一致性?ceph 会做定期检查,检查方式有2种:
第一种:scrub (轻量数据一致性检查)
第二种:Deep scrubbing (深度的数据一致性检查)
轻量数据一致性检查
- 对比 object metadata 数据是否一致
- 文件名,文件属性,文件大小是否一致等
- 每天一次
- 不一致,从主的 pg 中复制一份数据出去进行同步
深度数据一致性检查
- 对比数据内容
- 对比数据是否一样
- 每周做一次
手动执行数据一致性命令
查看检查数据一致性的命令
[root@node2 ~]# ceph -h | grep scrub
......
pg deep-scrub <pgid> start deep-scrub on <pgid>
pg scrub <pgid> start scrub on <pgid>
查看 pg id
[root@node2 ~]# ceph pg dump
手动执行轻量数据检查
[root@node2 ~]# ceph pg scrub 1.7c
instructing pg 1.7c on osd.0 to scrub
手动执行深度数据检查
[root@node2 ~]# ceph pg deep-scrub 1.7c
cinstructing pg 1.7c on osd.0 to deep-scrub
查看集群状态
# 因为测试环境数据少,没有捕捉到命令运行的一些情况
[root@node2 ~]# ceph -s
cluster:
id: 97702c43-6cc2-4ef8-bdb5-855cfa90a260
health: HEALTH_OK
services:
mon: 3 daemons, quorum node0,node1,node2 (age 18h)
mgr: node1(active, since 18h), standbys: node2, node0
mds: cephfs-demo:1 {0=node1=up:active} 2 up:standby
osd: 6 osds: 6 up (since 33m), 6 in (since 33m)
rgw: 1 daemon active (node0)
task status:
data:
pools: 9 pools, 352 pgs
objects: 361 objects, 305 MiB
usage: 6.8 GiB used, 293 GiB / 300 GiB avail
pgs: 352 active+clean
全量执行一次 deep-scrub
[root@node2 ~]# for i in `ceph pg dump | grep "active+clean" | awk '{print $1}'`; do ceph pg deep-scrub ${i}; done

 浙公网安备 33010602011771号
浙公网安备 33010602011771号