
原文:http://events.jianshu.io/p/623ea719f058
mysql的索引做了合理的数据结构转换,查询庞大数据的情况下,极大的提高了效率。
1.索引的本质
索引是能够在MySQL对数据进行排序,生成新的数据结构,最终实现高效率查询数据的一种方式。总的来说,索引就是一种数据结构。
2.索引底层结构
索引的数据结构有如下几种:
-
二叉树
-
红黑树
-
Hash表
-
B-Tree
3.数据库查询
下面是一张数据库的表,有两列数据,分别是Col1和Col2,存储的都是数字。
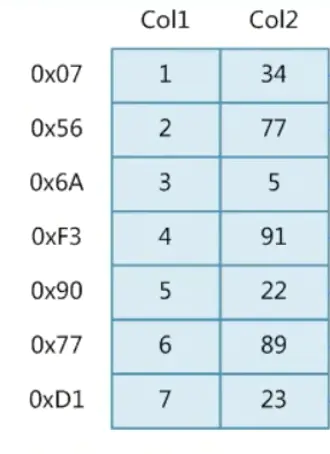
我们来查询一下数字为89的数据,mysql语句如下:
select * from s where s.Col2 = 89
普通模式下,查询的规则是从上往下查询:
| 34 👇🏻
| 77 👇🏻
| 5 👇🏻
| 91 👇🏻
| 22 👇🏻
| 89 👇🏻
终止查询
如果数据表很大,查询的数据又是在表尾的话,那么需要花费非常多的计算时间。
优化?
那么有没有想过其他的优化方案呢,减少在有有序表中的计算?如果是单纯的数字比对,表中又有键值的话,我能想到的第一个就是算法中的二分查找。但是在这里是不适用的,因为数据是无序的。
4.二叉树
利用索引来实现优化,这里使用的二叉查找树。
给Col2所有数据设置索引,给索引的每个节点是一个键值对(key/value),键保存的是所在行位置存储于磁盘的地址指针,value保存的是所在行位置的值。
例如:0x07:34
索引底层使用的数据结构是二叉树,最终存储的结构图如下:
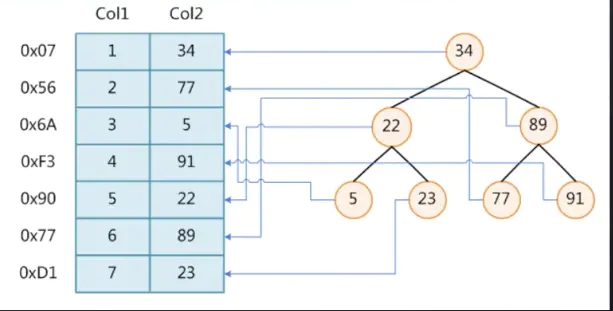
如果我们再查询89的话,从根节点34开始查找
| 34 👇🏻
| 89 👇🏻
终止查询
二叉树查询中,左边的子节点小于它的根节点,根节点小于右边的子节点。通过这个规律就可以很快的查找到对应的值。
效率得到了极大的提高,相比于原始的循序查询来说,减少很多不必要计算。但是索引底层用的并不是二叉树,因为二叉树对于有序列表来说是不能胜任的,我看下面的例子:
有序查询
下面是是二叉树存储有序的数据,我们都知道二叉树右边的子节点是小于根节点的,所以,有序的数据最终排列的结构和链表差不多。
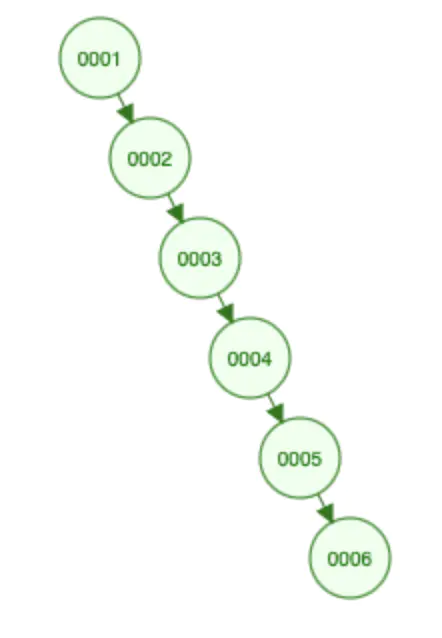
我们查询6的结果是怎么样的呢?
select * from s where s.Col1 = 6
结果如下:
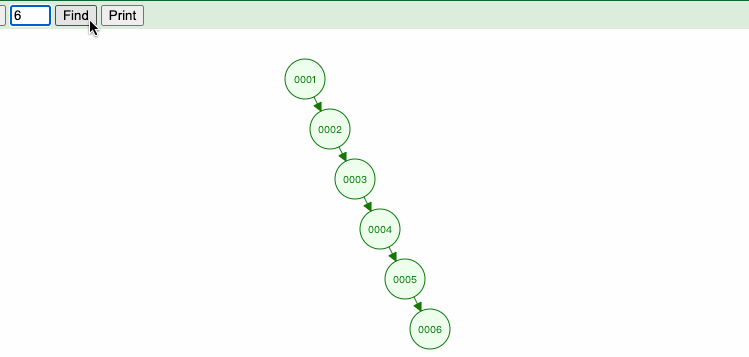
查询结果是,比对了六次才查找到最终结果,和原始查询并无差别,所以二叉树只在一定场景下有用。
5.AVL红黑树
二叉查找树存在不平衡的问题,那么可以通过树的叶子节点自动旋转和调整,让二叉树始终保持基本平衡的状态,这样就能够保持二叉查找树的最佳性能。基于以上思路的自调整平衡二叉树有AVL树和红黑树。
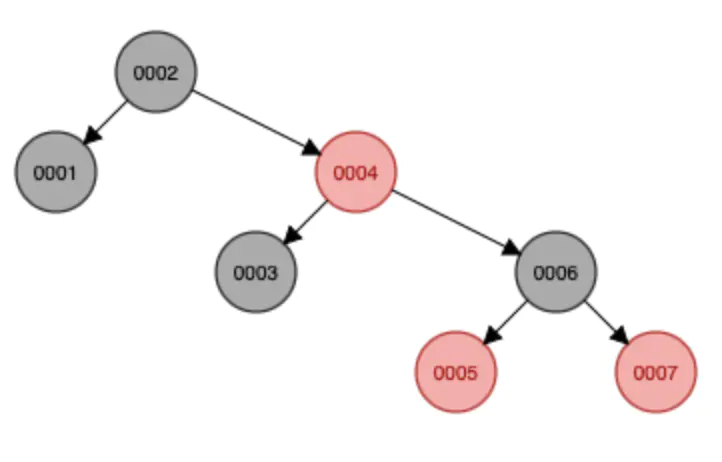
红黑树是一颗自动调整树形态的树结构,当二叉树处于一个不平衡状态下时,红黑树会自动左右旋转叶子节点以及节点变色(红色或者黑色),调整树的形态,使其保持基本的平衡,这个时候如果是查询节点,时间复杂度为O(logn),基本上保证了查找效率。使用二叉树插入七个节点,它的形态就如同一个链表,查询底部节点需要的时间复杂度达到了O(n),而使用红黑树则会自动化调节树的形态,使其达到平衡状态。可见下图:
如果上面的查询换成红黑树会是什么效果呢?
select * from s where s.Col1 = 6
查询过程:
| 2 👇🏻
| 4 👇🏻
| 6 👇🏻
终止查询
动画效果:
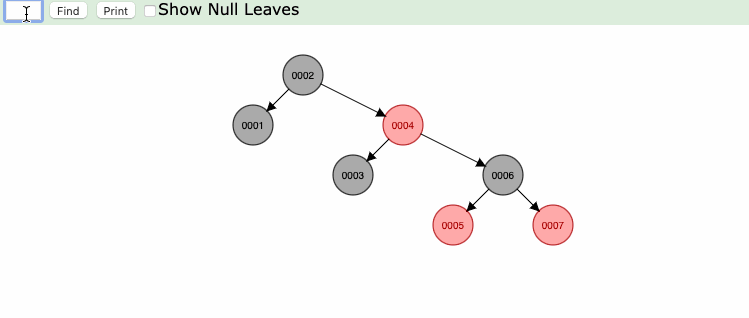
通过上面的动画,可以看到,查询次数明显减少,效率上得到显著的提升。但是依旧还存在问题。
-
数据非常大的情况下,叶子节点太深了
-
每次查找叶子节点为一层,几十几百万层的查询,完全不可控
上面7个节点的形态有一点点的规律,就是有一些向右倾斜,尽管没有二叉树倾斜的厉害,但是倾斜的幅度也是挺大的,而这个只是7个节点而已,那如果有几十万上百万个节点,倾斜的幅度是不可容忍的,倾斜幅度带来的问题的查找的深度。对于查找性能来说是巨大的消耗。
所以应对这个问题,有人考虑到了AVL树,相对于了红黑树来说,AVL树是严格意义上的绝对平衡二叉树,因此在调整二叉树的形态上消耗的性能更多。
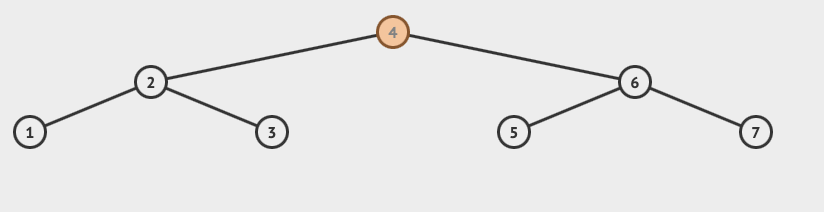
下图为VAL树:
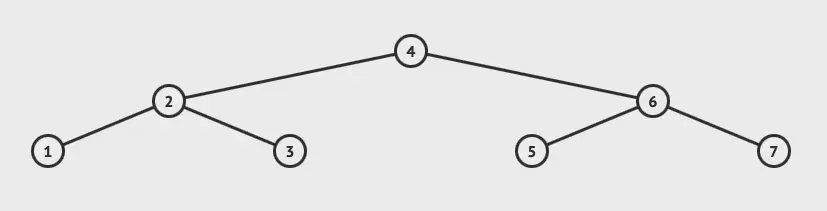
相比于红黑树来说,节点的形态更加的平衡。按照层级来对比,红黑树有4层,AVL只有三层。
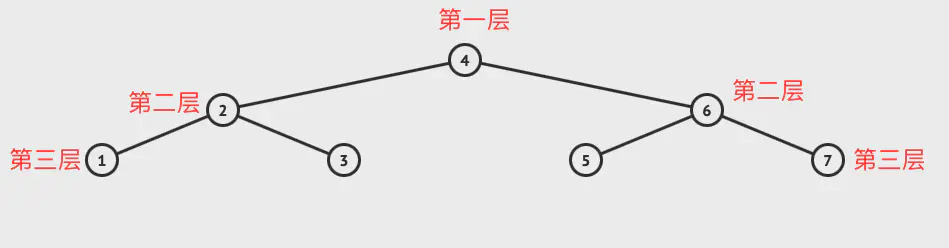
同样是查询节点6,结果会如何呢?
查询过程:
| 4 👇🏻
| 6 👇🏻
终止查询
查询动画:
通过对比发现
-
叶子节点层级减少
-
解决向右倾斜的问题,形态上保持了平衡
-
查询效率提升,大量顺序插入不会导致查询性能的降低,从根本上解决了红黑树遇到的问题
看起来AVL树作为数据查找的数据结构挺不错的,但是AVL树并没有被作为MySQL数据库的索引数据结构。因为数据库查找的瓶颈在于磁盘的I/O操作,如果使用AVL树,每一个树节点只存储一个数据,一次磁盘I/O只能读取一个节点的数据加载到内存中,假设依旧按照上面的查询6,则需要进行两次I/O操作,相比对内存计算来说,I/O操作是效率极低的,所以数据库索引首先考虑尽量减少频繁的I/O操作。
操作系统从上层到底层,各个层次之间存在着很多的I/O操作,比如CPU有I/O,内存有I/O,VMM有I/O,底层磁盘也有I/O。通常来说,一个上层的I/O可能会产生对磁盘的多个I/O,也就是说上层的I/O是稀疏的,底层的I/O是密集的。
这里我们只关注磁盘的 I/O,顾名思义就是磁盘的输入输出。输入指的是对磁盘写入数据,输出指的是从磁盘读出数据。磁盘读取10kb的数据和内存计算10kb的数据所消耗的时间的不一样的,磁盘读取所消耗的时间会比内存更长(感兴趣可以了解一下磁盘I/O性能指标,和CPU计算性能指标)。根据这个特性,可以在每一个节点中尽可能多的存储一些数据,一次磁盘I/O就多家在一些数据到内存中,这个就是B+树的设计原理。
6.B+树
B树是一种数据结构,它有如下特征
-
叶节点具有相同的深度,叶节点的指针为空
-
所有索引元素不重复
-
节点中的数据索引从左到右递增排列

B树和B+树的区别:
-
非叶子节点不存储data,只存储索引,可以放更多的索引
-
叶子结点包含所有索引字段
-
叶子节点用指针链接(链表链接),提高区间访问的性能

B+树中的根节点有15、56、77,在15和56中间的白色是下一个节点的磁盘文件地址。除了根节点是存储在内存中之外,其他的子节点都是存储在磁盘中。当查询的值不在15~56范围区间内,且不是15也不是56的时候,会读取磁盘地址,拉取磁盘文件到内存中(这个过程俗称I/O操作,I/O操作速度是挺慢的),在内存中进行比对查找。因为内存的计算和I/O操作完全不是一个量级的,内存使用的RAM计算。
数据存储量
想要计算MySQL数据存储量,首先就得知道根节点有多大,因为根节点的存储在内存中的,子节点才是存在磁盘中的,那么如何查看根节点的大小呢?
我们可以通过在Navicat Premium中进行sql语句的查询
show GLOBAL STATUS like 'Innodb_page_size'
结果如下:
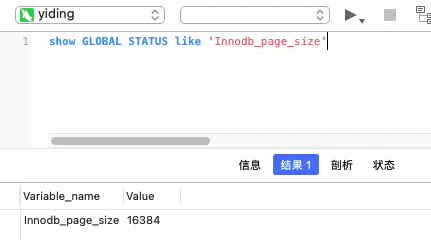
最终查询到的大小是16kb。所以说MySQL设置一个节点最大是16kb。
一个节点的大小是8个字节,索引指针是6个字节(15~56中间白色的区域)
公式:16kb / (8b+6b) = 1170
所以,设置一个节点的话,最大可以存储1170个索引。
如果层级数为三层,即高度为3,那么可以存储多少数据呢?
公式:1170 * 1170 * 1170 = 16亿(左右)
哇,高度为三层,就可以存储这么多的数据。那么如果查询的内容是20的话,只需要经过两次I/O操作,就可以查询到对应的值。
7.MyISAM索引
MyLSAM索引文件和数据文件是分离的,即为非聚集索引。下面讲解一下文件结构和数据结构
MyISAM的数据库一般是存在三个文件中的,分别是后缀为frm、MYD、MYI的文件,如下图:
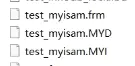
每个文件的作用分别是:
-
frm:存储表结构相关的信息
-
MYD:表数据
-
MYI:表索引,就是我们建表时候是主键
下面是索引的结构图:
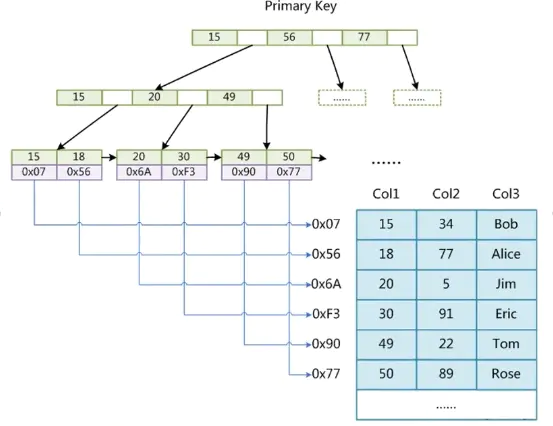
索引查询流程
如果有一个查询:
select * from s where s.Col1 = 30
如果使用的是索引查询,则会读第一个根节点,查找到30,它处于在15~56中间,则会进行一次I/O操作,进入到MYI文件中进行找到对应的索引,将读取的文件交给内存执行B+树查找,为没有找到数据则会进行第二次I/O操作,最终读取到了30这个索引值,索引值存储的是一个索引所在行的磁盘文件地址,这个地址是指向的MYD后缀文件,所以会进行I/O读取MYD后缀的数据表文件读取对应行的值
以上就是MyISAM索引引擎底层搜索所经历的流程。
8.InnoDB索引
InnoDB索引文件是合在一起的,即索引和数据存在一个文件,因此它属于聚集索引。
InnoDB的数据库一般存在两个文件中,分别是后缀为frm、ibd的文件,如下图:
每个文件的作用分别是:
-
frm:存储表结构相关信息
-
ibd:存储表的索引,和所有的数据
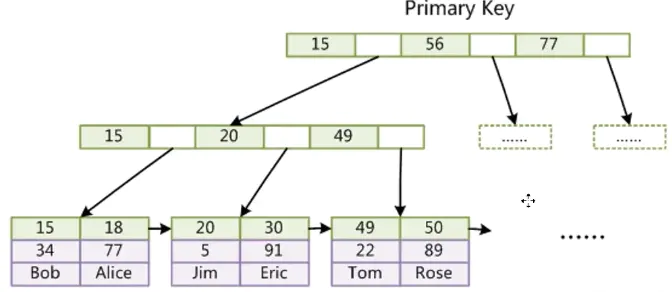
下面是索引的结构图:
特性
-
InnoDB的叶子节点存储的是每个索引所在行的所有数据字段,即所在行完整的数据。(参见最底层叶子节点索引15,下面是所在行的数据34、Bob)
-
表文件本身就是B+树组织的一个索引结构文件
-
由于主键和数据都是在一个文件内的,所有InnoDB必须要有主键,并且推荐使用整型的自增主键
-
非主键索引结构的叶子节点存储的是主键值,这个是为了实现一致性,节省存储的空间
9.小结
-
索引底层使用的是B+Tree结构。
-
索引最底层的叶子节点是排好序的链表,可以访问左右相邻节点。
-
数据库类型有很多种,比如MyISAM、InnoDB,它们区别于聚集索引和非聚集索引。
-
聚集索引是索引和数据都存储在一个文件中,非聚集索引是将索引和数据分别存储在不同的文件,索引键指向的是数据文件索引所在行的数据内容。
10.几个问题
聚集索引和非聚集索引哪个效率更高
以MyISAM数据结构和InnoDB数据结构来说:
非聚集索引查询到索引值之后,只是拿到了索引所在行的磁盘文件地址,需要通过这个地址再进行一次I/O操作。
聚集索引读取到叶子节点索引值之后,即那到了索引所在行的完整的数据内容,不需要额外的I/O操作。
因此,聚集索引效率更高!
为什么InnoDB必须要设置索引
因为InnoDB是聚集索引,索引和数据都是存到在一个文件中的,如果没有索引的话,全部数据就没办法合理的组织起来。
如果放肆,就是不加索引怎么办?
如果使用InnoDB建表的时候,没有显式的指定一个主键,则会自动帮你找到一个合适的唯一索引作为主键,若找不到符合条件唯一索引条件的字段时,会生成类似于ROW_ID的虚拟列充当该表的主键。
为什么主键建议设置为整型自增
为什么是整型
在索引查找的过程中,其实做的是比对计算,通过大小比对,知道所查询的索引在什么区间范围内,从根节点进行比对,根节点没有,再到叶子节点进行比对,这个过程中,使用整型是效率比较高的一种方式。
如果使用的是字符串对比,例如要查找一个索引是asdf20,根节点的区间范围是asdf15~asdf56,那么查询过程中需要对asdf20进行字符串拆分,逐个逐个字符串进行比对,字符串比对过程中还需要转换成ASCII码,然后再进行大小比对,这个效率是及其底下的。
为什么要自增?
在创建表之后,数据库引擎会自动将主键进行排序。我们手动的设置为自增能够,减少引擎的额外计算,要不每次添加一个数据,数据库引擎都会进行所有数据排列,当短时间内处理的数据量很大时,会损耗特别多计算量。
有序链表的好处
之所以引擎会将底层叶子节点设置为有序的,是为了很好的处理一些业务场景,比如范围查找,如下面查找语句:
select * from s where s.Col2 > 20
查找的节点不是单一节点,而是范围节点,查找的流程就是先在根节点找到索引为20的这个节点,找到之后,向下找出其底层叶子节点,利用有序链表的特性,直接把大于20的所有数据存储到集合中,输出即可!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号