
转载:https://www.cnblogs.com/axing-articles/p/11415763.html
1.定义:
MVCC(Multi-Version Concurrency Control,多版本并发控制)一种并发控制机制,在数据库中用来控制并发执行的事务,控制事务隔离进行。
2.核心思想:
MVCC是通过保存数据在某个时间点的快照来进行控制的。使用MVCC就是允许同一个数据记录拥有多个不同的版本。然后在查询时通过添加相对应的约束条件,就可以获取用户想要的对应版本的数据。
3.基本数据结构:
(1)redo log:
重做日志记录。存储事务操作的最新数据记录,方便日后使用。
(2)undo log:
撤回日志记录,也称版本链。当前事务未提交之前,undo log保存了当前事务的正在操作的数据记录的所有版本的信息,undo log中的数据可作为数据旧版本快照供其他并发事务进行快照读。每次有其它事务提交对当前数据行的修改,都是添加到undo log中。undo log是由每个数据行的多个不同的版本链接在一起构成的一个记录“链表”。如下图:
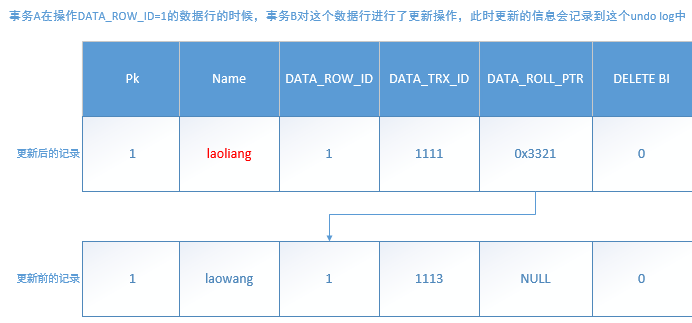
(3)read_view(快照):
①read_view的简单理解:
会对数据在每个时刻的状态拍成照片记录下来。那么之后获取某时刻的数据时就还是原来的照片上的数据,是不会变的。其实也可以简单理解为是一个版本链的集合,只不过在这里的版本链是经过筛选的。
②read_view的基本结构:
read_view->creator_trx_id = 当前事务id; # 当前的事务id
read_view->up_limit_id = 12654; # 当前活跃事务的最小id
read_view->low_limit_id = 12659; # 当前活跃事务的最小id
read_view->trx_ids = [12654, 12659]; # 当前活跃的事务的id列表,又称活跃事务链表。表示在记录当前快照时的所有活跃的、未提交的事务
read_view->m_trx_ids = 2; # 当前活跃的事务id列表长度
注意:
-
read_view中包含了活跃事务链表,这个链表表示此时还在活跃的事务,指的是那些在当前快照中还未提交的事务。(注意:新建事务(当前事务)与正在内存中commit 的事务不在活跃事务链表)。
-
read_view中不会显示所有的数据行,只会显示“可见”的记录。筛选方式如下所述。
③read_view的记录筛选方式:
前提:DATA_TRX_ID 表示每个数据行的最新的事务ID;up_limit_id表示当前快照中的最先开始的事务;low_limit_id表示当前快照中的最慢开始的事务,即最后一个事务。
-
如果记录的DATA_TRX_ID < up_limit_id:在创建read_view时,修改该记录的事务已提交,该记录可被快照中的事务读取到(即可见)。
-
如果DATA_TRX_ID >= low_limit_id:表示该记录是在当前read_view创建之后被其它事务修改的,该记录在当前快照中肯定不可见。此时需要从DB_ROLL_PTR指针所指向的回滚段中取出最新的undo-log的版本号, 然后用它继续重新开始整套比较算法。
-
如果up_limit_id <= DATA_TRX_ID < low_limit_i:
-
需要在活跃事务链表中查找是否存在ID为DATA_TRX_ID的值的事务。
-
如果存在,那么因为在活跃事务链表中的事务是未提交的,所以该记录是不可见的。此时需要从DB_ROLL_PTR指针所指向的回滚段中取出最新的undo-log的版本号, 然后用它继续重新开始整套比较算法。(详细分析为什么“不可见”:因为DATA_TRX_ID只有在事务提交之后才会更新,而此时因为事务还存在于活跃事务链表中,所以说明事务是还没有commit,所以此时不可能存在对应的数据行,只有在当前事务提交之后才会有对应的数据行。)
-
如果不存在,所以是可见的。(分析:按照上一点的对“不可见”原因的分析,可明白只能是当前本事务更新了这条记录,因为在当前read view中,只能是当前事务和正在内存中commit的事务不在事务活跃链表中,对于“正在内存中commit的事务”,因为它还没有commit,所以肯定是不可能读取到它的即将要commit的数据的,而所以只能是当前事务对这个数据行做了修改了,虽然未提交,但是因为是在当前事务中,所以肯定是可以读取到更新的数据的。
-
④read_view的更新方式:
注意:仅分析RC级别和RR级别,因为MVCC不适用于其它两个隔离级别。
a、对于Read Committed级别的:
-
基本描述:每次执行select都会创建新的read_view,更新旧read_view,保证能读取到其他事务已经COMMIT的内容(读提交的语义);
-
详细分析:假设当前有事务A和事务A+1并发进行。在当前级别下,事务A每次select的时候会创建新的read_view,此时可以简单理解为事务A会提交,也就是让事务A执行完毕,然后创建一个新的事务比如是事务A+2。这样子的话,因为事务A+2的事务ID肯定是比事务A+1的ID大,所以就能够读取到事务A+1的更新了。那么便可以读取到在创建这个新的read_view之前事务A+1所提交的所有信息。这是RC级别下能读取到其他事务已经COMMIT的内容的原因所在。
b、对于Repeatable Read级别的:
- 第一次select时更新这个read_view,以后不会再更新,后续所有的select都是复用这个read_view。所以能保证每次读取的一致性,即都是读取第一次读取到的内容(可重复读的语义)。
注意:通过对read view的更新方式的分析可以得出:对于InnoDB下的MVCC来说,RR虽然比RC隔离级别高,但是开销反而相对少(因为不用频繁更新read_view)。
read_view的详细分析:https://www.iteye.com/blog/mahl1990-2347029
4.MVCC在mysql的具体实现:
(1)基本数据结构的定义:
在mysql中,在实现MVCC时,会为每一个表添加如下几个隐藏的字段:
-
6字节的DATA_TRX_ID:标记了最新更新这条行记录的transaction id,每处理一个事务,其值自动设置为当前事务ID(DATA_TRX_ID只有在事务提交之后才会更新);
-
7字节的DATA_ROLL_PTR:一个rollback指针,指向当前这一行数据的上一个版本,找之前版本的数据就是通过这个指针,通过这个指针将数据的多个版本连接在一起构成一个undo log版本链;
-
6字节的DB_ROW_ID:隐含的自增ID,如果数据表没有主键,InnoDB会自动以DB_ROW_ID产生一个聚簇索引。这是一个用来唯一标识每一行的字段;
-
DELETE BIT位:用于标识当前记录是否被删除,这里的不是真正的删除数据,而是标志出来的删除。真正意义的删除是在commit的时候。
MVCC在二级索引结构下的分析:https://www.cnblogs.com/stevenczp/p/8018986.html
(2)增删改查:
①增加:INSERT
- 设置新记录的DATA_TRX_ID为当前事务ID,其他的采用默认的。
②删除:DELETE
- 修改DATA_TRX_ID的值为当前的执行删除操作的事务的ID,然后设置DELETE BIT为True,表示被删除
③修改:UPDATE <==> INSERT + DELETE
-
用X锁锁定该行(因为是写操作);
-
记录redo log:将更新之后的数据记录到redo log中,以便日后使用;
-
记录undo log:将更新之后的数据记录到undo log中,设置当前数据行的DATA_TRX_ID为当前事务ID,回滚指针DATA_ROLL_PTR指向undo log中的当前数据行更新之前的数据行,同时设置更新之前的数据行的DATA_TRX_ID为当前事务ID,并且设置DELETE BIT为True,表示被删除。
④查找:SELECT
-
如果当前数据行的DELETE BIT为False,只查找版本早于当前事务版本的数据行(也就是数据行的DATA_TRX_ID必须小于等于当前事务的ID),这确保当前事务读取的行都是事务之前已经存在的,或者是由当前事务创建或修改的行;
-
如果当前数据行的DELETE BIT为True,表示被删除,那么只能返回DATA_TRX_ID的值大于当前事务的行。获取在当前事务开始之前,还没有被删除的行。
注意:
a、此时就是要去查找read_view,判断其中是否有需要的记录;
b、就算在当前事务提交的时候,也不会读取到DATA_TRX_ID大于当前事务ID的数据记录(而默认情况下,RR隔离级别下,当前事务一commit,就能够读取到其他事务的commit)。这也是MVCC能够解决幻读的原因。
5.使用MVCC核心优势:
(1)在mysql中,使用MVCC本质上是为了在进行读操作的时候代替加锁,减少加锁带来的负担。
(2)在mysql的InnoDB引擎,并且是在RR隔离级别下,通过使用MVCC和gap锁来解决幻读问题(详细解决方式参见下方的第7点)。
6.MVCC与四大隔离级别的关系的分析:
分析了在MVCC的控制之下,如何实现四大隔离级别。
(1)Read Uncimmitted级别:
由于存在脏读,即能读到未提交事务的数据行,所以不适用MVCC。原因是MVCC的DATA_TRX_ID只有在事务提交之后才会更新,而在Read uncimmitted级别下,由于是读取未提交的,所以说MVCC在这个级别下是不适用的。
(2)Read Committed级别:
查找操作:
分析:假设当前有事务A、事务A+1、数据B(DATA_TRX_ID为A-1)。
-
事务A进行查找,此时找出事务ID小于它本身的,所以此时数据B可以被找到;
-
如果在事务A还没有执行完毕的时候,事务A+1对数据B进行了更新操作,那么此时数据B的undo log则被更新为“数据B(DATA_TRX_ID为A+1)-> 数据B(DATA_TRX_ID为A-1)”;
-
此时如果事务A再次进行查找操作,会更新read_view。更新旧的read_view,并且开启新的事务A+2。那么根据MVCC的规定,就能够找到数据B(DATA_TRX_ID为A+1),可以找到更新之后的。这样子的话就等价于能够读取到别的事务commit的最新的数据记录。这就符合RC级别的语义。
(3)Repeatable Read级别:
查找操作:
分析:假设当前有:事务A、事务A+1,数据B(DATA_TRX_ID为A-1)。
-
事务A进行查找,此时找出事务ID小于它本身的,所以此时数据B可以被找到;
-
如果在事务A还没有执行完毕的时候,事务A+1对数据B进行了更新操作,那么此时数据B的undo log则被更新为“数据B(DATA_TRX_ID为A+1)-> 数据B(DATA_TRX_ID为A-1)”;
-
此时如果事务A再次进行查找操作,那么根据MVCC的规定,还是只能找到数据B(DATA_TRX_ID为A-1)(因为B(DATA_TRX_ID为A+1)的事务ID比当前事务A的事务ID大,所以不会被找到),不会找到更新之后的。这样子的话就等价于只能够读取到事务A开始时读取到的数据记录。这就符合RR级别的语义。
(4)Serialization级别:
串行化由于是会对所涉及到的表加锁,并非行锁,自然也就不存在行的版本控制问题
总结:通过上面的分析可得:MVCC只适用于MySQL隔离级别中的读已提交(Read committed)和可重复读(Repeatable Read)
7.MVCC、gap锁解决幻读问题的分析:
前提:InnoDB引擎、RR隔离级别(gap锁只存在于这个级别下)
(1)首先了解数据记录的读取方式:快照读和当前读
①快照读:
读快照,可以读取数据的所有版本信息,包括旧版本的信息。其实就是读取MVCC中的read_view,同时结合MVCC进行相对应的控制;
select * from table where ?;
②当前读:
读当前,读取当前数据的最新版本。而且读取到这个数据之后会对这个数据加锁,防止别的事务更改。
(分析:在进行写操作的时候就需要进行“当前读”,读取数据记录的最新版本)
select * from table where ? lock in share mode; # 读锁
select * from table where ? for update; # 写锁
insert into table values (…);
update table set ? where ?;
delete from table where ?;
详见:https://www.jianshu.com/p/27352449bcc0
③RC和RR隔离级别下的快照读和当前读:
-
RC隔离级别下,快照读和当前读结果一样,都是读取已提交的最新;
-
RR隔离级别下,当前读结果是其他事务已经提交的最新结果,快照读是读当前事务之前读到的结果。RR下创建快照读的时机决定了读到的版本。
(2)解决幻读问题:
①对于快照读:通过MVCC来进行控制的,不用加锁。按照MVCC中规定的“语法”进行增删改查等操作,以避免幻读。(MVCC的具体内容参见上方第1点到第4点的分析)
②对于当前读:通过next-key锁(行锁+gap锁)来解决问题的。(next-key锁的分析:mysql中的锁)
(3)特殊语句分析:
“MVCC不能根本上解决幻读的情况?”
分析:这句话的含义是指对于快照读,那么是可以通过MVCC来解决的;但是对于当前读,则必须通过next-key锁(行锁+gap锁)来解决。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号