
redis除了5种数据类型之外,还提供了其他功能,如:慢查询,pipeline,事务,发布订阅和消息队列,Bitmap,HyperLogLog,GEO
1.慢查询日志
许多存储系统(如:MySQL)提供慢查询日志帮助开发与运维人员定位系统存在的慢操作.所谓慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阈值,就将这条命令的相关信息(例如:发生时间,耗时,命令的详细信息)记录到慢查询日志中,Redis也提供了类似的功能
1.1生命周期
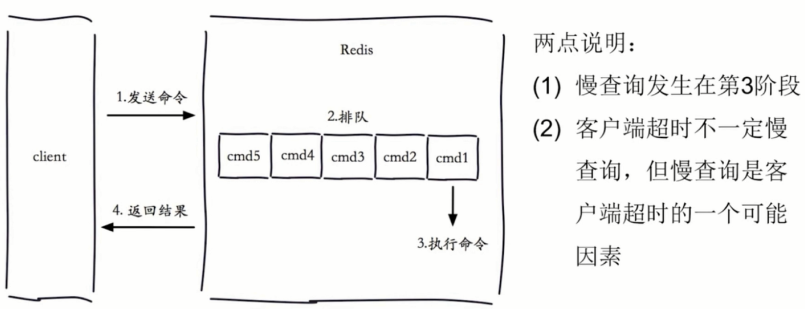
需要注意,慢查询只统计步骤3的时间,所以没有慢查询并不代表客户端没有超时问题。
1.2慢查询的两个配置参数
对于慢查询功能,需要明确两件事:
- 预设阈值怎么设置?
- 慢查询记录存放在那?
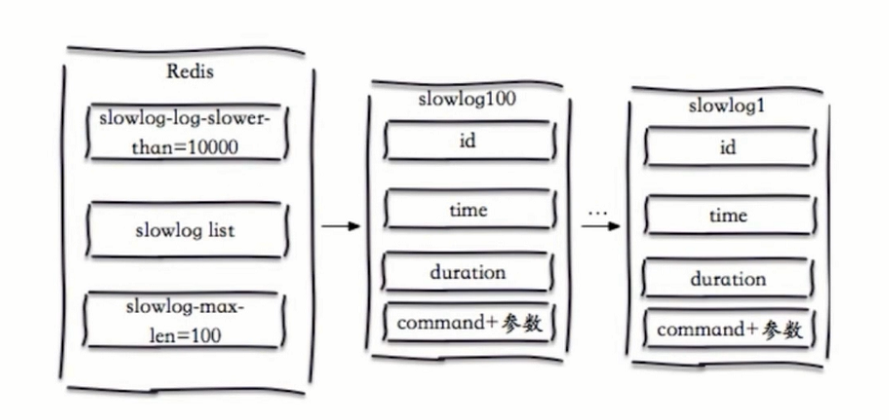
Redis提供了slowlog-log-slower-than和slowlog-max-len配置来解决这两个问题
- slowlog-log-slower-than:就是这个预设阈值,它的单位是毫秒(1秒=1000000微秒)默认值是10000,假如执行了一条"很慢"的命令(例如key *),如果执行时间超过10000微秒,那么它将被记录在慢查询日志中。
如果slowlog-log-slower-than=0会记录所有命令,slowlog-log-slower-than<0对于任何命令都不会进行记录。
- slowlog-max-len:只是说明了慢查询日志最多存储多少条,并没有说明存放在哪里?实际上Redis使用了一个列表来存储慢查询日志,slowlog-max-len就是列表的最大长度.一个新的命令满足慢查询条件时被插入到这个列表中,当慢查询日志列表已处于其最大长度时,最早插入的一个命令将从列表中移出,例如slowlog-max-len设置长度为64.当有第65条慢查询日志插入的话,那么队头的第一条数据就出列,第65条慢查询就会入列。
在Redis中有两种修改配置的方法:
- 修改配置文件
- 使用config set命令动态修改
如:
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1024
config rewrite
如果需要将Redis配置持久化到本地配置文件,要执行config rewrite命令
1.3慢查询命令
- slowlog get [n]:获取慢查询日志,参数n可以指定条数。
如:
127.0.0.1:6379> slowlog get 2
1) 1) (integer) 5
2) (integer) 1590659533
3) (integer) 13060
4) 1) "SET"
2) "image:code:9KQUuRJ4"
3) "2141"
5) "127.0.0.1:39410"
6) ""
2) 1) (integer) 4
2) (integer) 1590353732
3) (integer) 10220
4) 1) "auth"
2) "123456"
5) "aa.bb.cc.dd:42450"
6) ""
127.0.0.1:6379>
可以看到每个查询日志有4个属性组成,分别是慢查询日志的表示id、发生时间戳、命令耗时、执行命令和参数。
- slowlog len:获取慢查询日志列表当前长度。
127.0.0.1:6379> slowlog len
(integer) 6
127.0.0.1:6379>
- slowlog reset:慢查询日志重置
127.0.0.1:6370> slowlog len
(integer) 23
127.0.0.1:6370> slowlog reset
OK
127.0.0.1:6370> slowlog len
(integer) 0
1.4运维经验
慢查询功能可以有效地帮助我们找到Redis可能存在的瓶颈,但在实际使用过程中要注意以下几点:
- slowlog-max-len:线上建议调大慢查询列表,记录慢查询时Redis会对长命令做阶段操作,并不会占用大量内存.增大慢查询列表可以减缓慢查询被剔除的可能,例如线上可设置为1000以上。
- slowlog-log-slower-than:默认值超过10毫秒判定为慢查询,需要根据Redis并发量调整该值.由于Redis采用单线程相应命令,对于高流量的场景,如果命令执行时间超过1毫秒以上,那么Redis最多可支撑OPS不到1000因此对于高OPS场景下的Redis建议设置为1毫秒。
- 慢查询只记录命令的执行时间,并不包括命令排队和网络传输时间.因此客户端执行命令的时间会大于命令的实际执行时间.因为命令执行排队机制,慢查询会导致其他命令级联阻塞,因此客户端出现请求超时时,需要检查该时间点是否有对应的慢查询,从而分析是否为慢查询导致的命令级联阻塞。
- 由于慢查询日志是一个先进先出的队列,也就是说如果慢查询比较多的情况下,可能会丢失部分慢查询命令,为了防止这种情况发生,可以定期执行slowlog get命令将慢查询日志持久化到其他存储中(例如:MySQL、ElasticSearch等),然后可以通过可视化工具进行查询。
2.Pipeline(流水线)
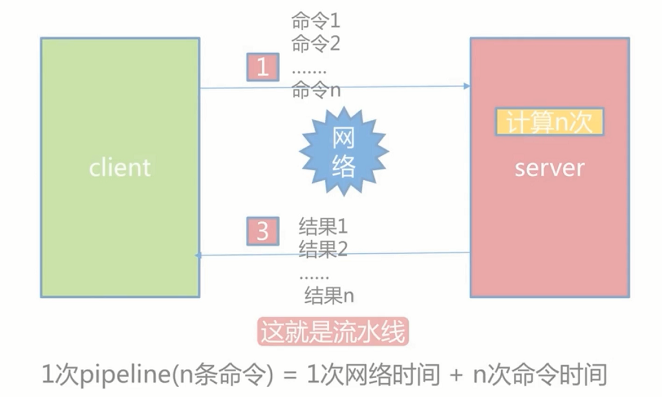
2.1流水线的作用
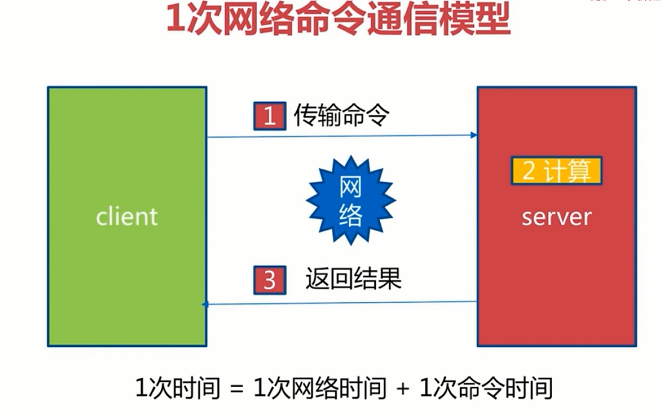
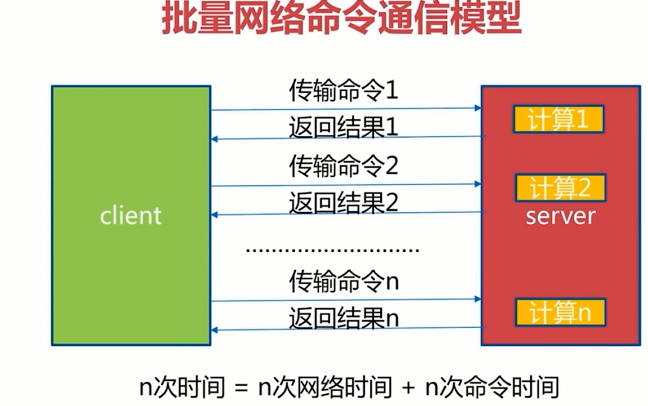
Redis提供了批量操作命令(例如mget,mset等),有效的节约RTT.但大部分命令是不支持批量操作的,例如要执行n次hgetall命令,并没有mhgetall存在,需要消耗n次RTT.Redis的客户端和服务端可能不是在不同的机器上.例如客户端在北京,Redis服务端在上海,两地直线距离为1300公里,那么1次RTT时间=1300×2/(300000×2/3)=13毫秒(光在真空中传输速度为每秒30万公里,这里假设光纤的速度为光速的2/3),那么客户端在1秒内大约只能执行80次左右的命令,这个和Redis的高并发高吞吐背道而驰。
Pipeline(流水线)机制能改善上面这类问题,它能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令按照顺序执行并装填结果返回给客户端。
Pipeline并不是什么新的技术和机制,很多技术上都使用过.而且RTT在不同网络环境下会有不同,例如同机房和同机器会比较快,跨机房跨地区会比较慢.Redis命令真正执行的时间通常在微秒级别,所以才会有Redis性能瓶颈是网络这样的说法。
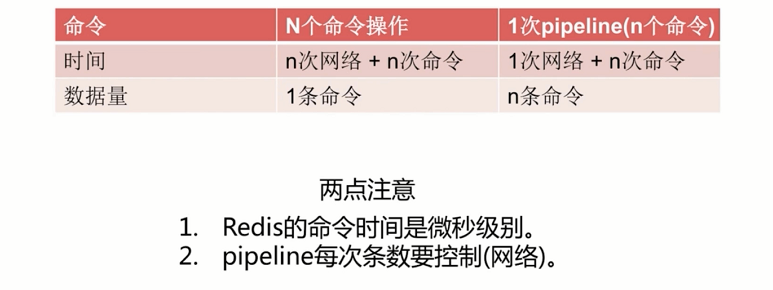
2.2原生批量命令与Pipeline对比
可以使用Pipeline模拟出批量操作的效果,但是在使用时需要质疑它与原生批量命令的区别,具体包含几点:
- 原生批量命令是原子性,Pipeline是非原子性的。
- 原生批量命令是一个命令对应多个key,Pipeline支持多个命令。
- 原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端与客户端的共同实现。
2.3Pipeline使用建议
- 注意每次Pipeline携带数据量。一次组装Pipeline数据量过大,一方面会增加客户端的等待时机,另一方面会造成一定的网络阻塞,可以将一次包含大量命令的Pipeline拆分成多次较小的Pipeline来完成。
- Pipeline每次只能作用在一个Redis节点上,但即使在分布式Redis场景中,也可以作为批量操作的重要优化方法。
- 原生命令操作与Pipeline的区别。
3.事务
为了保证多条命令组合的原子性,Redis提供了简单的事务以及集成Lua脚本来解决这个问题。
事务表示一组动作,要么全部成功,要不全部不成功.例如在在电商网站中用户购买商品A那么需要将商品A的库存-1,并创建一个订单.这两个操作要么远不执行成功,要么全部执行不成功,否则会出现数据不一致的情况。
Redis提供了简单的功能,将一组需要一起执行的命令放到multi和exec两个命令之间.multi命令代表事务的开始,exec命令代表事务结束,他们之间的命令是原子顺序执行的。
例如上述的用户购买商品问题:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> hincrby commodity:a:detail stock -1
QUEUE
127.0.0.1:6379> rpush user:1:orders {"commodity":'a',..}
QUEUE
可以看到数据操作命令返回的结果是QUEUE,代表命令并没有真正执行,而是暂时保存在Redis中.如果此时另一个客户端执行llen user:1:orders返回结果为0。
127.0.0.1:6379> llen user:1:orders
(integer) 0
只有当exec执行后,用户购买商品的行为才算完成,如下两个结果对应hincrby和rpush命令。
127.0.0.1:6379> exec
1) (integer) 4 # 商品原库存为5
2) (integer) 1
127.0.0.1:6379> llen user:1:orders
(integer) 1
如果要停止事务的执行,可以使用discard命令替代exec命令即可。
127.0.0.1:6379> discard
OK
127.0.0.1:6379> llen user:1:orders
(integer) 0
如果事务中的命令出现错误,Redis的处理机制也不尽相同。
3.1命令错误
例如下面操作错将set写成了sett,属于语法错误,会造成整个事务无法执行,key和counter的值未发生变化:
127.0.0.1:6379> mget key counter
1) "hello"
2) "100"
127.0.0.1:6379> multi
OK
127.0.0.1:6379> sett key world
(error) ERR unknown command 'sett'
127.0.0.1:6379> incr counter
QUEUE
127.0.0.1:6379> exec
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> mget key counter
1) "hello"
2) "100"
3.2运行时错误
例如用户购买商品,误把rpush写成了zadd:
127.0.0.1:6379> multi
OK
127.0.0.1:6379> hincrby commodity:a:detail stock -1
QUEUED
127.0.0.1:6379> zadd user:1:orders {"commodity":'a',..}
QUEUED
127.0.0.1:6379> exec
1) (integer) 1
2) (error) WRONGTYPE Operation against a key holding the wrong kind of value.
127.0.0.1:6379> hget commodity:a:detail stack
(integer) 3
可以看到Redis并不支持回滚功能,hincrby commodity🅰️detail stock -1命令已经执行成功,开发者需要自己修改这类问题。
4.发布订阅(Pub/Sub)和消息队列
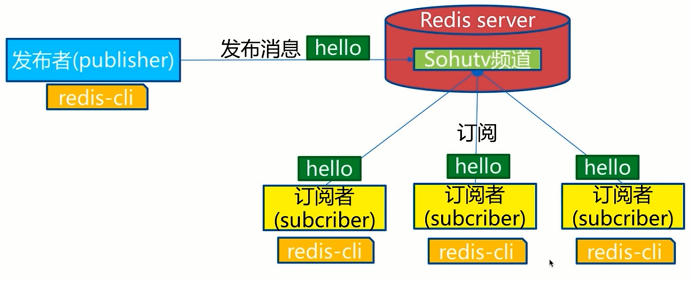
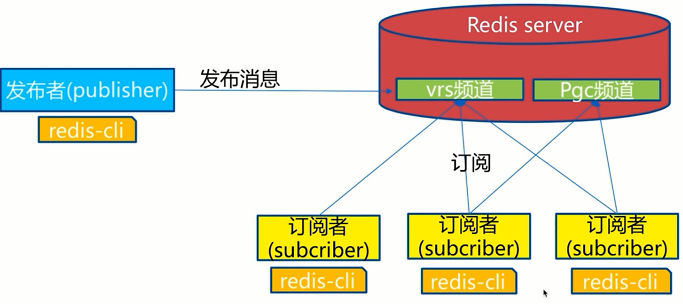
4.1发布订阅
Redis 发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。
发布者和订阅者都是Redis客户端,Channel则为Redis服务器端,发布者将消息发送到某个的频道,订阅了这个频道的订阅者就能接收到这条消息。Redis的这种发布订阅机制与基于主题的发布订阅类似,Channel相当于主题。
模型:
API:
| 序号 | 命令及描述 |
|---|---|
| 1 | PSUBSCRIBE pattern [pattern ...] 订阅一个或多个符合给定模式的频道。 |
| 2 | PUBSUB subcommand [argument [argument ...]] 查看订阅与发布系统状态。 |
| 3 | PUBLISH channel message 将信息发送到指定的频道。 |
| 4 | PUNSUBSCRIBE [pattern [pattern ...]] 退订所有给定模式的频道。 |
| 5 | SUBSCRIBE channel [channel ...] 订阅给定的一个或多个频道的信息。 |
| 6 | UNSUBSCRIBE [channel [channel ...]] 指退订给定的频道。 |
- publish发布:
127.0.0.1:6379> publish test:tv "hello world"
(integer) 1 ##订阅者个数
127.0.0.1:6379>
- subscribe订阅:
127.0.0.1:6379> SUBSCRIBE test:tv
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "test:tv"
3) (integer) 1
1) "message"
2) "test:tv"
3) "hello world"
- unsubscribe取消订阅:
127.0.0.1:6379> UNSUBSCRIBE test:tv
1) "unsubscribe"
2) "test:tv"
3) (integer) 0
Redis发布订阅与ActiveMQ的比较:
- ActiveMQ支持多种消息协议,包括AMQP,MQTT,Stomp等,并且支持JMS规范,但Redis没有提供对这些协议的支持。
- ActiveMQ提供持久化功能,但Redis无法对消息持久化存储,一旦消息被发送,如果没有订阅者接收,那么消息就会丢失。
- ActiveMQ提供了消息传输保障,当客户端连接超时或事务回滚等情况发生时,消息会被重新发送给客户端,Redis没有提供消息传输保障。
总之,ActiveMQ所提供的功能远比Redis发布订阅要复杂,毕竟Redis不是专门做发布订阅的,但是如果系统中已经有了Redis,并且需要基本的发布订阅功能,就没有必要再安装ActiveMQ了,因为可能ActiveMQ提供的功能大部分都用不到,而Redis的发布订阅机制就能满足需求。
4.2消息队列
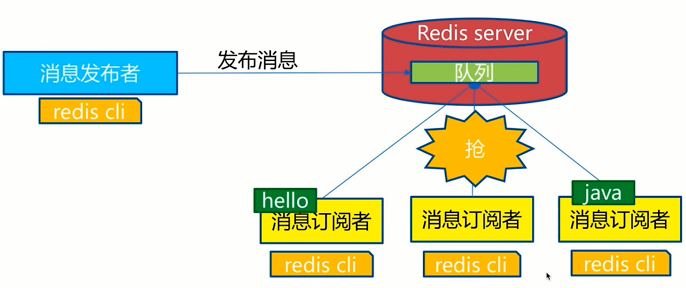
基于List的 LPUSH+BRPOP 的实现。
使用rpush和lpush操作入队列,lpop和rpop操作出队列。
List支持多个生产者和消费者并发进出消息,每个消费者拿到都是不同的列表元素。
但是当队列为空时,lpop和rpop会一直空轮训,消耗资源;所以引入阻塞读blpop和brpop(b代表blocking),阻塞读在队列没有数据的时候进入休眠状态,
一旦数据到来则立刻醒过来,消息延迟几乎为零。
注意:
你以为上面的方案很完美?还有个问题需要解决:空闲连接的问题。
如果线程一直阻塞在那里,Redis客户端的连接就成了闲置连接,闲置过久,服务器一般会主动断开连接,减少闲置资源占用,这个时候blpop和brpop或抛出异常,
所以在编写客户端消费者的时候要小心,如果捕获到异常,还有重试。
缺点:
- 做消费者确认ACK麻烦,不能保证消费者消费消息后是否成功处理的问题(宕机或处理异常等),通常需要维护一个Pending列表,保证消息处理确认。
- 不能做广播模式,如pub/sub,消息发布/订阅模型
- 不能重复消费,一旦消费就会被删除
- 不支持分组消费
参考:https://segmentfault.com/a/1190000009915519
参考:https://segmentfault.com/a/1190000011440752
参考:https://www.jianshu.com/p/d32b16f12f09

 浙公网安备 33010602011771号
浙公网安备 33010602011771号