Node Buffer 对象的探究与内存分配代码挖掘
参照 Node 官方文档 Buffer API
作用
在前端开发过程中,一般也只有字符串级别的操作,很少接触字节这样的底层操作。而在后端的领域里,操作网络协议、图片和文件 I/O 十分常见二进制数据,为了让 JS 能处理,node 封装了一个 Buffer 类。
简言之:Buffer 类是专用来操作二进制数据流并与之交互的,也叫缓冲区。
基本使用
创建 Buffer,其中第二个参数是字符编码格式,参照 Node 官方文档-Buffer 与字符编码
// <Buffer 31>
const buf = Buffer.from('1');
// <Buffer 31 30>
const buf1 = Buffer.from('10');
// <Buffer 31 30>
const buf2 = Buffer.from('10', 'utf8');
// <Buffer 0a>
const buf3 = Buffer.from([10]);
// <Buffer 0a>
const buf4 = Buffer.from(buf3);
返回一个已经初始化的 Buffer,可以保证新创建的 Buffer 永远不会包含旧数据。
// 创建一个长度为 10 的 Buffer,
// 其中填充了全部值为 \u0000,也就是空字符串的字节。
const b = Buffer.alloc(10);
console.log(b); // <Buffer 00 00 00 00 00 00 00 00 00 00>
字符串与 Buffer 互转化
const buf = Buffer.from('JS语言', 'utf8');
console.log(buf); // <Buffer 4a 53 e8 af ad e8 a8 80>
console.log(buf.length); // 6,前两个字节是 "JS",后四个字节是 "语言"
console.log(buf.toString('utf8')); // JS语言
Buffer 的应用场景
文件与网络 I/O,与流 Stream 密不可分,只是 Stream 包装了一些东西,不需要开发者手动去创建缓冲区。当然下面直接这样读文件,是不能读超过 2GB 的,得需要用流,这里只是个例子。
var fs = require('fs')
fs.readFile('./1080p.mp4', function(err, data) {
if (err) {
console.log(err);
}
console.log(data)
})
$ node test.js
<Buffer 00 00 00 20 66 74 79 70 69 73 6f 6d 00 00 02 00 69 73 6f 6d 69 73 6f 32 61 76 63 31 6d 70 34 31 00 58 95 99 6d 6f 6f 76 00 00 00 6c 6d 76 68 64 00 00 ... 1877454492 more bytes>
此外 zlib.js 是 Node 核心库之一,也利用了缓冲区 Buffer 的功能来操作二进制数据流来提供压缩或者解压的功能,参照 zlib.js 源码
加解密 crypto 也使用了 Buffer 做二进制操作。
内存机制
Buffer 是一个类 Array 的对象,它的元素都是 16 进制的两位数。是一个典型的 JavaScript 与 C++ 结合的模块,设计性能的相关部分采用了 C++ 实现,而非性能部分采用了 JavaScript 实现。
由于 Buffer 需要处理大量的二进制数据,如果用一点就要向系统申请,则会造成频繁的向系统申请内存调用。所以 Buffer 所占用的内存不再由 V8 分配,而是在 Node.js 的 C++ 层面完成申请,在 JavaScript 中进行内存分配。因此,这部分内存我们称之为堆外内存。由此,v8 的垃圾回收影响不了堆外内存。
图片来自 Node.js之Buffer对象浅析
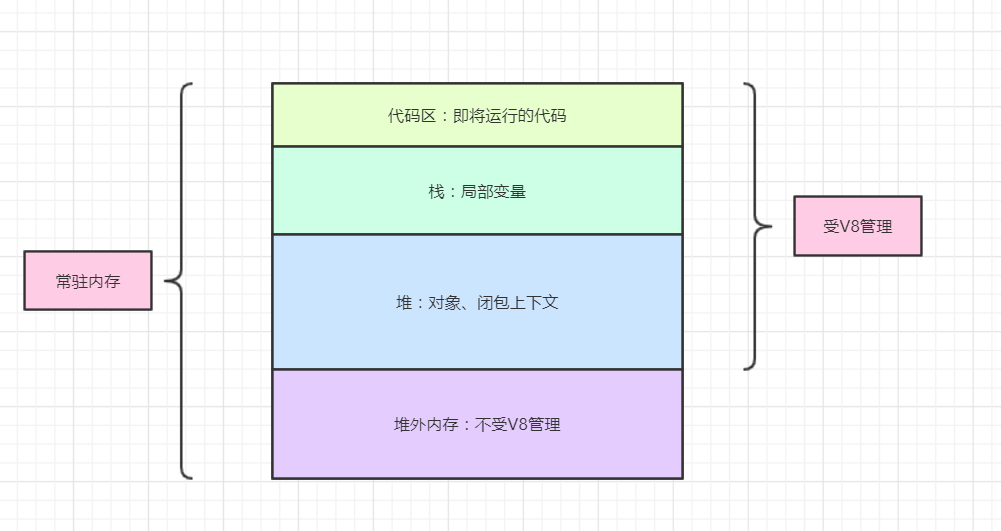
Buffer 内存分配原理
Node.js 中采用了 slab 机制进行预先申请、事后分配。slab 是一种动态的内存管理机制,它就是一块申请好的固定大小的内存区域,有 3 种状态
- full: 完全分配
- partial: 部分分配
- empty: 没有被分配
这种机制以 8kb 为界限决定当前分配的对象是大对象还是小对象。
Node 12.x buffer.js 源码 里就写上了以下代码,所以才能明白“为什么说 Buffer 在创建时大小就已经被确定的且无法调整”。
Buffer.poolSize = 8 * 1024;
创建缓冲区的函数如下 v12.x/lib/buffer.js#L156,加载时调用 createPool() 相当于初始化了一个 8kb 的内存空间,这样第一次内存分配也会变得高效,初始化的同时还用偏移量 poolOffset 来记录使用了多少字节。
Buffer.poolSize = 8 * 1024;
let poolSize, poolOffset, allocPool;
... // 中间代码省略
function createPool() {
poolSize = Buffer.poolSize;
allocPool = createUnsafeArrayBuffer(poolSize);
setHiddenValue(allocPool, arraybuffer_untransferable_private_symbol, true);
poolOffset = 0;
}
createPool();
如果分配了一个 2048 字节的 Buffer 对象,当前 slab 内存应该如下
Buffer.alloc(2 * 1024)
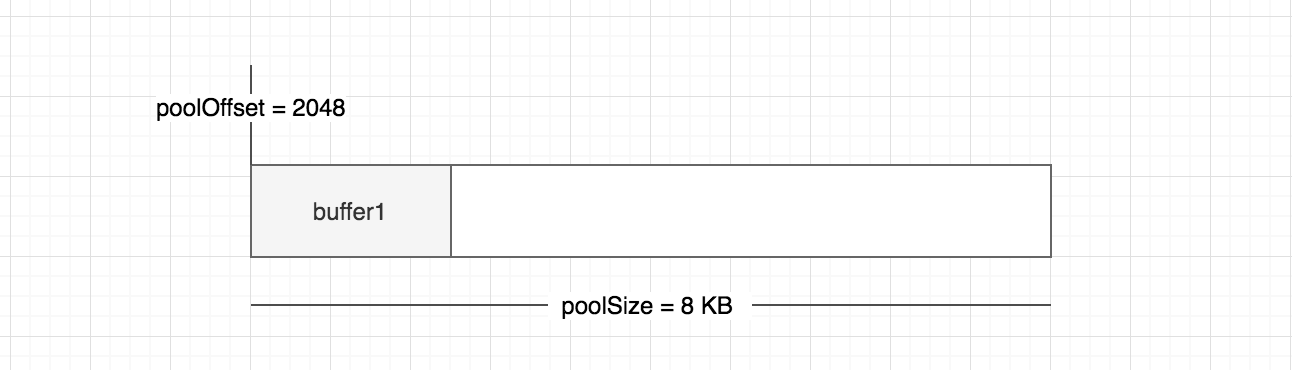
分配的过程见 v12.x/lib/buffer.js#L408
// L147
function createUnsafeBuffer(size) {
zeroFill[0] = 0;
try {
return new FastBuffer(size);
} finally {
zeroFill[0] = 1;
}
}
// .....
// L408
function allocate(size) {
if (size <= 0) {
return new FastBuffer();
}
// 8096 右移 1 为 4096,即要分配的空间小于 4kb
if (size < (Buffer.poolSize >>> 1)) {
// 当此 slab 剩余空间不够分配,则 createPool 再申请一块 slab 的内存。
if (size > (poolSize - poolOffset))
createPool();
// 够分配那就直接分配,偏移量加上。
const b = new FastBuffer(allocPool, poolOffset, size);
poolOffset += size;
alignPool();
return b;
}
// 要分配的空间大于 4kb,直接去创建新的内存区吧
return createUnsafeBuffer(size);
}
FastBuffer 在v12.x/lib/internal/buffer.js#L945,就简短的一行。可以看作 Buffer 继承自 Uint8Array。
class FastBuffer extends Uint8Array {}
内存分配总结
- 在初次加载时就会初始化 1 个 8KB 的内存空间,v12.x/lib/buffer.js#L156 源码有体现
- 根据申请的内存大小分为 小 Buffer 对象 和 大 Buffer 对象
- 小 Buffer (小于 4kb )情况,判断这个 slab 剩余空间是否足够容纳
- 若足够就去使用剩余空间分配,偏移量会增加
- 若不足,就调用 createPool 创建一个新的 slab 空间用来分配
- 大 Buffer (大于 4kb )情况,直接 createUnsafeBuffer(size) 创建。
之所以要判断区别大对象还是小对象,就只是希望小对象不要每次申请时都去向系统申请内存调用。
不论是小 Buffer 对象还是大 Buffer 对象,内存分配是在 C++ 层面完成,内存管理在 JavaScript 层面,最终还是可以被 V8 的垃圾回收标记所回收,回收的是 Buffer 对象本身,堆外内存的那些部分只能交给 C++。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号