Mysql 索引使用以及优化策略
示例数据库
原文: https://www.kancloud.cn/kancloud/theory-of-mysql-index/41847
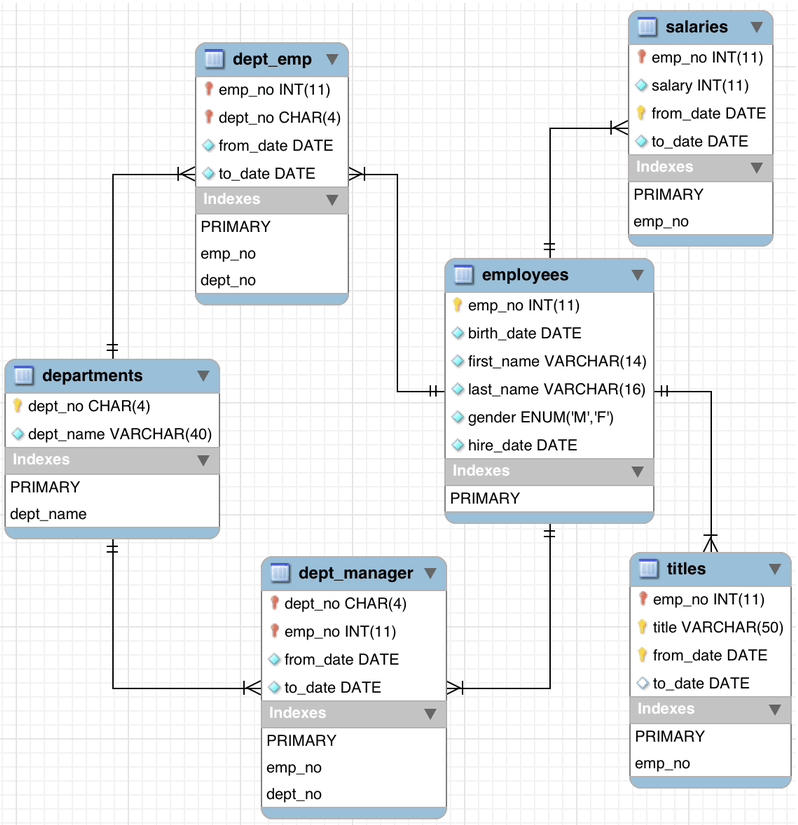
mysql 示例数据库 Employees 地址:https://dev.mysql.com/doc/employee/en/sakila-structure.html
github 下载地址:https://github.com/datacharmer/test_db
最左前缀原理与相关优化
首先解释一下最左前缀匹配原则
- 对于联合索引,MySQL 会一直向右匹配直到遇到范围查询(> , < ,between,like)就停止匹配。比如 a = 3 and b = 4 and c > 5 and d = 6,如果建立的是(a,b,c,d)这种顺序的索引,那么 d 是用不到索引的,但是如果建立的是 (a,b,d,c)这种顺序的索引的话,那么就没问题,而且 a,b,d 的顺序可以随意调换。
- = 和 in 可以乱序,比如 a = 3 and b = 4 and c = 5 建立 (a,b,c)索引可以任意顺序。
- 如果建立的索引顺序是 (a,b)那么直接采用 where b = 5 这种查询条件是无法利用到索引的,这一条最能体现最左匹配的特性。(a, b, c) 里 才用 where a = 1 and c = 2,那么其实也只能用到 a 做索引。
索引选择性判断
既然索引可以加快查询速度,那么是不是只要是查询语句需要,就建上索引?答案是否定的。因为索引虽然加快了查询速度,但索引也是有代价的:索引文件本身要消耗存储空间,同时索引会加重插入、删除和修改记录时的负担,另外,MySQL在运行时也要消耗资源维护索引,因此索引并不是越多越好。一般两种情况下不建议建索引。
第一种情况是表记录比较少,例如一两千条甚至只有几百条记录的表,没必要建索引,让查询做全表扫描就好了。至于多少条记录才算多,这个个人有个人的看法,我个人的经验是以2000作为分界线,记录数不超过 2000可以考虑不建索引,超过2000条可以酌情考虑索引。
另一种不建议建索引的情况是索引的选择性较低。所谓索引的选择性(Selectivity),是指不重复的索引值(也叫基数,Cardinality)与表记录数(#T)的比值。选择性越高的索引价值越大。
例如
> SELECT count(DISTINCT(title))/count(*) AS Selectivity FROM employees.titles;
+-------------+
| Selectivity |
+-------------+
| 0.0000 |
+-------------+
title的选择性不足0.0001(精确值为0.00001579),所以实在没有什么必要为其单独建索引。依照个人的经验,要选择性大于 70% 的时候才能单独建索引。
为什么查询不为常用的每个列创建独立索引 ?
at 5.3.3。
SELECT film_id, actor_id FROM sakila.film_actor
WHERE actor_id = 1 OR film_id = 1;
在MySQL 5.0和更新的版本中,查询能够同时使用这两个单列索引进行扫描,并将结果进行合并。这种算法有三个变种:OR条件的联合(union),AND条件的相交(intersection),组合前两种情况的联合及相交。做联合操作时(通常是 or),通常耗费CPU、内存资源。
但如果是一个是单列索引,另一个非索引,那么会引发回表查询, explain 的 extra 显示 using where,此时先根据单列索引查到数据后,再回表进一步筛选非索引列。
咨询 dba,根据经验,才发现联合索引的建立要求的条件挺苛刻。一般程序开发中很难确定最左前缀的选择,因为这个查询条件可能并不一定包含那个最左前缀。dba如是说
对于查询列来说。一般基值比较(基值大是指这个列在全表数据中,重复项很少)大的,单列加索引。基值比较少,但是经常查询的,可以加联合索引。排序的可以考虑加联合索引,查询列在前,排序列在后。其他的不推荐联合索引
前缀索引的使用
优点:兼顾索引长度和选择性。
缺点:但是其缺点是不能用于ORDER BY和GROUP BY操作,也不能用于覆盖索引(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)
例子,如果我们想按名字搜索一个人,就只能全表扫描了
EXPLAIN SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido';
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
| 1 | SIMPLE | employees | ALL | NULL | NULL | NULL | NULL | 300024 | Using where |
+----+-------------+-----------+------+---------------+------+---------+------+--------+-------------+
如果频繁按名字搜索员工,这样显然效率很低,因此我们可以考虑建索引。有两种选择,建或,看下两个索引的选择性:
SELECT count(DISTINCT(first_name))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.0042 |
+-------------+
SELECT count(DISTINCT(concat(first_name, last_name)))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.9313 |
+-------------+
显然选择性太低,选择性很好,但是first_name和last_name加起来长度为30,有没有兼顾长度和选择性的办法?可以考虑用first_name和last_name的前几个字符建立索引,例如,看看其选择性:
SELECT count(DISTINCT(concat(first_name, left(last_name, 3))))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.7879 |
+-------------+
选择性还不错,但离0.9313还是有点距离,那么把last_name前缀加到4:
SELECT count(DISTINCT(concat(first_name, left(last_name, 4))))/count(*) AS Selectivity FROM employees.employees;
+-------------+
| Selectivity |
+-------------+
| 0.9007 |
+-------------+
这时选择性已经很理想了,而这个索引的长度只有18,比短了接近一半,我们把这个前缀索引 建上:
ALTER TABLE employees.employees
ADD INDEX `first_name_last_name4` (first_name, last_name(4));
此时再执行一遍按名字查询,比较分析一下与建索引前的结果:
SHOW PROFILES;
+----------+------------+---------------------------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+---------------------------------------------------------------------------------+
| 87 | 0.11941700 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
| 90 | 0.00092400 | SELECT * FROM employees.employees WHERE first_name='Eric' AND last_name='Anido' |
+----------+------------+---------------------------------------------------------------------------------+
性能的提升是显著的,查询速度提高了120多倍。
前缀索引兼顾索引大小和查询速度,但是其缺点是不能用于ORDER BY和GROUP BY操作,也不能用于Covering index(即当索引本身包含查询所需全部数据时,不再访问数据文件本身)。
为什么说主键最好使用与业务无关的自增字段
在使用InnoDB存储引擎时,如果没有特别的需要,请永远使用一个与业务无关的自增字段作为主键。
经常看到有帖子或博客讨论主键选择问题,有人建议使用业务无关的自增主键,有人觉得没有必要,完全可以使用如学号或身份证号这种唯一字段作为主键。不论支持哪种论点,大多数论据都是业务层面的。如果从数据库索引优化角度看,使用InnoDB引擎而不使用自增主键绝对是一个糟糕的主意。
上文讨论过InnoDB的索引实现,InnoDB使用聚集索引,数据记录本身被存于主索引(一颗B+Tree)的叶子节点上。这就要求同一个叶子节点内(大小为一个内存页或磁盘页)的各条数据记录按主键顺序存放,因此每当有一条新的记录插入时,MySQL会根据其主键将其插入适当的节点和位置,如果页面达到装载因子(InnoDB默认为15/16),则开辟一个新的页(节点)。
如果表使用自增主键,那么每次插入新的记录,记录就会顺序添加到当前索引节点的后续位置,当一页写满,就会自动开辟一个新的页。如下图所示:
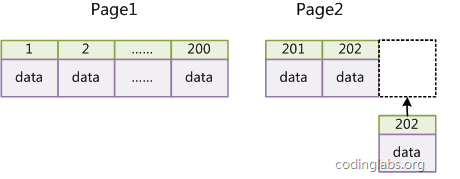
这样就会形成一个紧凑的索引结构,近似顺序填满。由于每次插入时也不需要移动已有数据,因此效率很高,也不会增加很多开销在维护索引上。
如果使用非自增主键(如果身份证号或学号等),由于每次插入主键的值近似于随机,因此每次新纪录都要被插到现有索引页得中间某个位置:
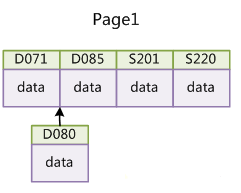
此时MySQL不得不为了将新记录插到合适位置而移动数据,甚至目标页面可能已经被回写到磁盘上而从缓存中清掉,此时又要从磁盘上读回来,这增加了很多开销,同时频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
因此,只要可以,请尽量在InnoDB上采用自增字段做主键。
参考
《高性能MySQL》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号