
vue computed 实现原理与 watch 对比
原理
<div id="app">
{{num}}
{{num1}}
</div>
var app = new Vue({
el: '#app',
data: {
num: 1
},
computed: {
num1 () {
return this.num + 1;
}
}
});
console.log(app);
computed 本质是一个惰性求值的订阅者。data 属性的 Observer 挂在 _data 属性下,而 computed 属性挂在 _computedWatchers 下。而发布者 Dep 里存放了两个订阅者,而和computed相关的订阅者,其实只做了一件事情,标记 dirty 为 true,等待 get 时再真正计算。
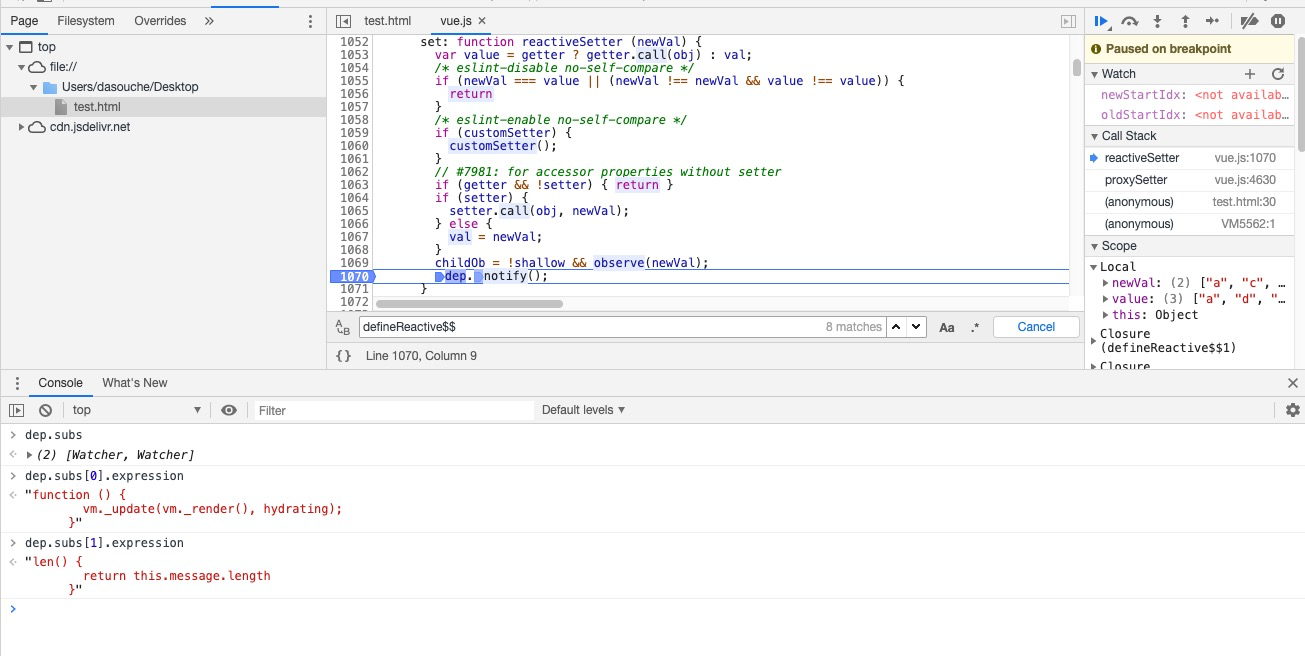
computed 内部实现了一个惰性的 watcher,也就是 _computedWatchers,_computedWatchers 不会立刻求值,同时持有一个 dep 实例。
其内部通过 this.dirty 属性标记计算属性是否需要重新求值
变更流程如下:
- 当 computed 的依赖的状态发生改变时,就会通知这个惰性的 watcher。
- computed watcher 通过 this.dep.subs.length 判断有没有订阅者,
- 有的话,会重新计算,然后对比新旧值,如果变化了,会重新渲染。 (Vue 想确保不仅仅是计算属性依赖的值发生变化,而是当计算属性最终计算的值发生变化时才会触发渲染 watcher 重新渲染,本质上是一种优化。)
- 没有的话,仅仅把
this.dirty = true。 (当计算属性依赖于其他数据时,属性并不会立即重新计算,只有之后其他地方需要读取属性的时候,它才会真正计算,即具备 lazy(懒计算)特性。)
watch
这是 computed 的 watcher 观察者结构。特有的 lazy 为 true 代表 getter 时需要计算更新,注意 cb 只是一个空的函数,啥也不做,但是 expression 有值
Watcher {
vm: Vue {_uid: 0, _isVue: true, $options: {…}, _renderProxy: Proxy, _self: Vue, …}
deep: false
user: false
lazy: true
sync: false
before: undefined
cb: function noop(a, b, c) {}
id: 1
active: true
dirty: false
deps: (2) [Dep, Dep]
newDeps: []
depIds: Set(2) {3, 6}
newDepIds: Set(0) {}
expression: "len() {↵ return this.message.length↵ }"
getter: ƒ len()
value: 2
__proto__: Object
}
这是 watch 的 观察者结构,注意 user 为 true,expression 里没有关键内容,但是 cb 里有,更新值的时候就是判定 user 为 true 时,调用 cb 获取新值。
Watcher {
vm: Vue {_uid: 0, _isVue: true, $options: {…}, _renderProxy: Proxy, _self: Vue, …}
deep: false
user: true
lazy: false
sync: false
before: undefined
cb: function message() {
this.full = this.message.join(',');
}
id: 2
active: true
dirty: false
deps: (2) [Dep, Dep]
newDeps: []
depIds: Set(2) {3, 6}
newDepIds: Set(0) {}
expression: "message"
getter: ƒ (obj)
value: (2) ["a", "c", __ob__: Observer],
__proto__: Object
}
与 watch 有什么区别
computed 计算属性 : 依赖其它属性值,并且 computed 的值有缓存,只有它依赖的属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值。
watch 侦听器 : 更多的是「观察」的作用,无缓存性,类似于某些数据的监听回调,每当监听的数据变化时都会执行回调进行后续操作。
与 watch 运用场景的对比
需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许我们执行异步操作 ( 访问一个 API ),限制我们执行该操作的频率,并在我们得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
当我们需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时,都要重新计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号