JS 字符集使用哪一种编码,怎么计算字符串所占字节数?
字符编码基础
unicode
unicode是一种字符集,源于一个很简单的想法:将全世界所有的字符包含在一个集合里,计算机只要支持这一个字符集,就能显示所有的字符,再也不会有乱码。
而Unicode只规定了每个字符的码点,到底用什么样的字节序表示这个码点,就涉及到编码方法。
UTF-32 与 UTF-8
最直观的编码方法是,每个码点使用四个字节表示,字节内容一一对应码点。这种编码方法就叫做 UTF-32。UTF-32 的优点在于,转换规则简单直观,查找效率高。缺点在于浪费空间,同样内容的英语文本,它会比 ASCII 编码大四倍。这个缺点致命,实际上没有人使用这种编码方法,HTML 5 标准就明文规定,网页不得编码成UTF-32。
因此诞生了UTF-8,UTF-8是一种变长的编码方法,字符长度从1个字节到4个字节不等。越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同。
注意UTF-8只是unicode的实现方式之一。例如"严"的unicode码为4E25,而UTF-8编码为E4B8A5,两者是不同的。
UCS-2
UCS-2(2个字节的通用字符集)是一种固定长度的编码格式,只需要使用编码为 16 字节编码单元来表示码位。这样的表示结果将和 UTF-16 在 0 到 0xFFFF (BMP)范围内大多数的结果一样。
UTF-16(16 位 Unicode 转换格式)是对 UCS-2 的一个扩展,它允许表示比 BMP 范围内更多的字符。它是一种可变长度格式,它的每个码位能够使用 1 位或者 2 位 16字节编码单元来表示。这种方式能够编码的码位在 0 到 0x10FFFF 之间。
简单来说,UTF-16 是 UCS-2 的扩展。
UTF-16
UTF-16 编码介于UTF-32与UTF-8之间,同时结合了定长和变长两种编码方法的特点。
它的编码规则很简单:基本平面的字符占用2个字节,辅助平面的字符占用4个字节。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)。
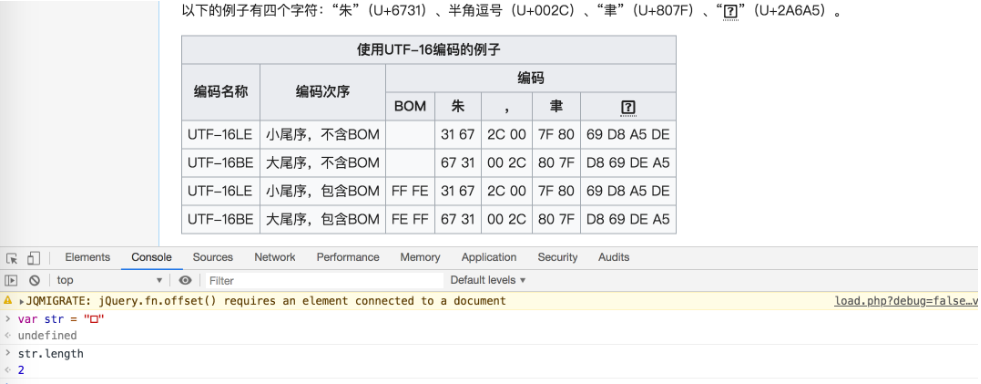
JS 的字符集使用哪一种编码?
ES 5.1 有一段话
A conforming implementation of this International standard shall interpret characters in conformance with the Unicode Standard, Version 3.0 or later and ISO/IEC 10646-1 with either UCS-2 or UTF-16 as the adopted encoding form, implementation level 3. If the adopted ISO/IEC 10646-1 subset is not otherwise specified, it is presumed to be the BMP subset, collection 300. If the adopted encoding form is not otherwise specified, it is presumed to be the UTF-16 encoding form.
所以 JS 引擎可以选择使用 UCS-2 或者 UTF-16。
为什么不能选择 UTF-8呢?由于历史原因,最先出现的 UCS-2,接着 1996 年 UTF-16 随着 Unicode 2.0 标准诞生,就可以迁移到了 UTF-16。但是它们无法移至 UTF-8,是因为这将破坏 API 接口中的二进制兼容性(以及其他功能)。
另外即使是Java,它也以相同的方式运行:它最初支持 UCS-2,但在 J2SE 5.0 中移至 UTF-16。
你可以通过下图的代码得到严字的 unicode 码。
var str = '严'
str.charCodeAt(0).toString(16) // "4e25"
计算字符串所占字节数
/**
* 计算字符串所占的内存字节数,默认使用UTF-8的编码方式计算,使用一至四个字节为每个字符编码
* 参考来源: http://www.jb51.net/article/73675.htm
*
* 000000 - 00007F(128个代码) 0zzzzzzz(00-7F) 一个字节
* 000080 - 0007FF(1920个代码) 110yyyyy(C0-DF) 10zzzzzz(80-BF) 两个字节
* 000800 - 00D7FF & 00E000 - 00FFFF(61440个代码) 1110xxxx(E0-EF) 10yyyyyy 10zzzzzz 三个字节
* 010000 - 10FFFF(1048576个代码) 11110www(F0-F7) 10xxxxxx 10yyyyyy 10zzzzzz 四个字节
*
* 注: Unicode在范围 D800-DFFF 中不存在任何字符
* {@link http://zh.wikipedia.org/wiki/UTF-8}
*
* UTF-16 大部分使用两个字节编码,编码超出 65535 的使用四个字节
* 000000 - 00FFFF 两个字节
* 010000 - 10FFFF 四个字节
*
* {@link http://zh.wikipedia.org/wiki/UTF-16}
* @param {String} str
* @param {String} charset utf-8
* @return {Number}
*/
var sizeof = function(str, charset) {
var total = 0,
charCode,
i,
len;
charset = charset ? charset.toLowerCase() : '';
if (charset === 'utf-16' || charset === 'utf16') {
for (i = 0, len = str.length; i < len; i++) {
charCode = str.charCodeAt(i);
if (charCode <= 0xffff) {
total += 2;
} else {
total += 4;
}
}
} else {
for (i = 0, len = str.length; i < len; i++) {
charCode = str.charCodeAt(i);
if (charCode <= 0x007f) {
total += 1;
} else if (charCode <= 0x07ff) {
total += 2;
} else if (charCode <= 0xffff) {
total += 3;
} else {
total += 4;
}
}
}
return total;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号