[译]在Pandas的Dataframe中删除行、列
导入模块
import pandas as pd
创建dataframe
data = {'name': ['Jason', 'Molly', 'Tina', 'Jake', 'Amy'],
'year': [2012, 2012, 2013, 2014, 2014],
'reports': [4, 24, 31, 2, 3]}
df = pd.DataFrame(data, index = ['Cochice', 'Pima', 'Santa Cruz', 'Maricopa', 'Yuma'])
df
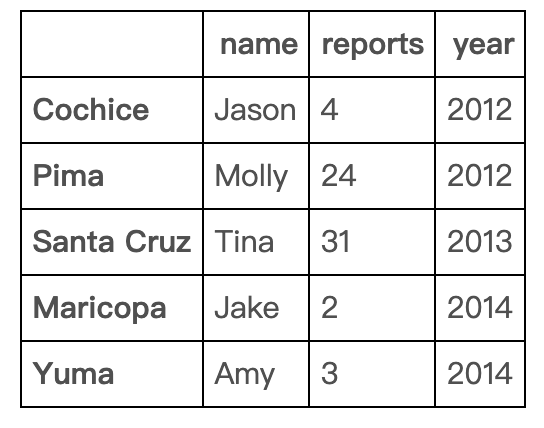
删除行
df.drop(['Cochice', 'Pima'])
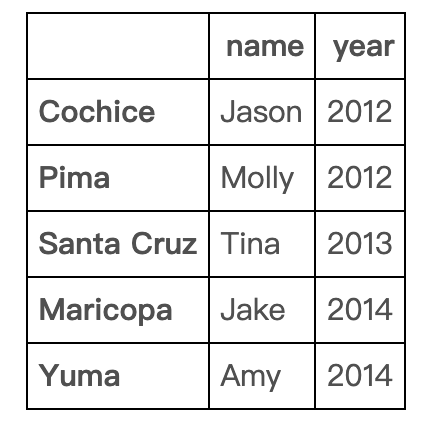
删除列
df.drop('reports', axis=1)
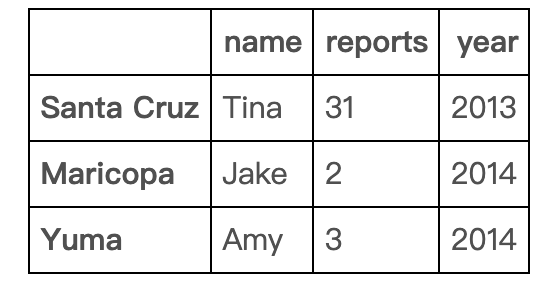
删除一个包含特定值的行
就下面这个例子来说:创建一个名为df的新dataframe,取出名称列中单元格值不等于“Tina”的所有行。
df[df.name != 'Tina']
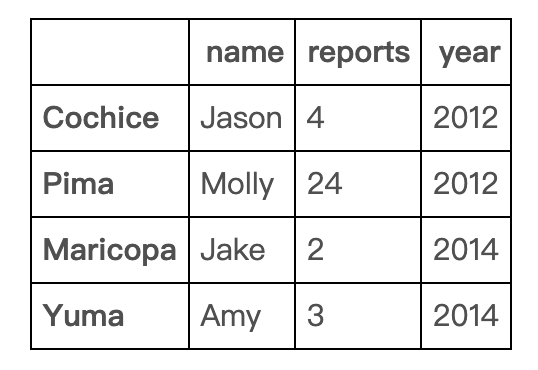
根据行号删除,
注意Pandas是从0开始计数,0是第一行,1是第二行。
df.drop(df.index[2])
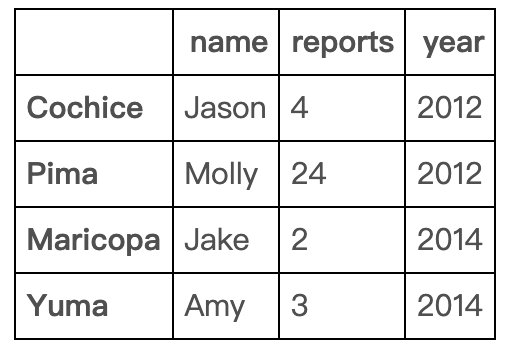
可以扩展为删除一系列范围
df.drop(df.index[[2,3]])
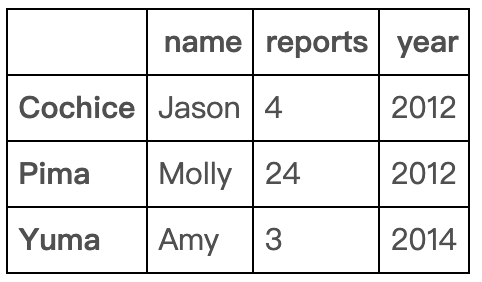
删除到相对于结尾的位置
df.drop(df.index[-2])

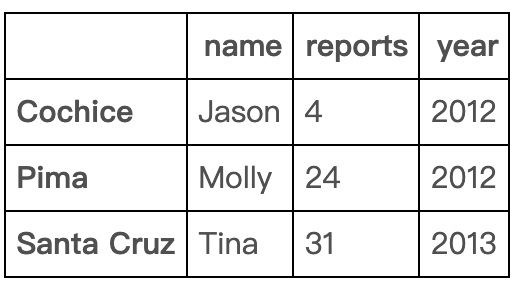
你可以选择相对top的范围,也可以删除相对于bottom的范围
df[:3] #保留top3
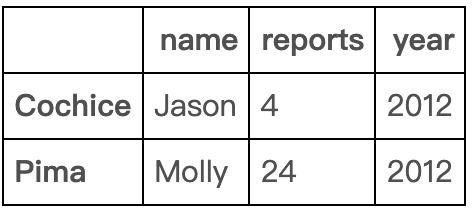
df[:-3] #删除bottom3
原文来源:https://chrisalbon.com/python/data_wrangling/pandas_dropping_column_and_rows/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号