
Java多线程学习笔记
平时记录
【搜索课程】极客时间 网络编程实战
※,IO多路复用、同步、异步、阻塞和非阻塞的区别 【清晰】
阻塞、非阻塞、多路IO复用,都是同步IO,异步必定是非阻塞的,所以不存在异步阻塞和异步非阻塞的说法。即使用select、poll、epool,都不是异步。IO多路复用只能表面上称为异步阻塞IO,而非真正的异步IO。所以一般划分为同步IO。
获取IO数据,分为两个阶段,一是套接字缓冲区准备阶段;二是数据拷贝阶段(内核将数据从socket缓冲区拷贝到用户空间)。阻塞IO和非阻塞IO,主要区别在于第一个阶段。也即是阻塞IO,在套接字缓冲区没准备好的情况下,会一直等待。而非阻塞IO,在套接字缓冲区没准备好时,会立即返回。
※,同步vs异步,阻塞vs非阻塞 https://www.jianshu.com/p/73661ad3513d
(1)同步和异步
同步和异步描述的是一种消息通知的机制,主动等待消息返回还是被动接受消息。同步io指的是调用方通过主动等待获取调用返回的结果来获取消息通知,而异步io指的是被调用方通过某种方式(如,回调函数)来通知调用方获取消息。
(2)阻塞非阻塞
阻塞和非阻塞描述的是调用方在获取消息过程中的状态,阻塞等待还是立刻返回。阻塞io指的是调用方在获取消息的过程中会挂起阻塞,知道获取到消息,而非阻塞io指的是调用方在获取io的过程中会立刻返回而不进行挂起。
教程:参考此视频
※,多线程:
卍,进程与线程:
- 进程:程序的基本执行实体。
- 线程: 操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
多进程与多线程的区别:本质的区别在于每个进程都拥有自己的一整套变量,而线程则共享数据。共享数据会导致不安全,但好处就是线程间的通信更有效,更容易。
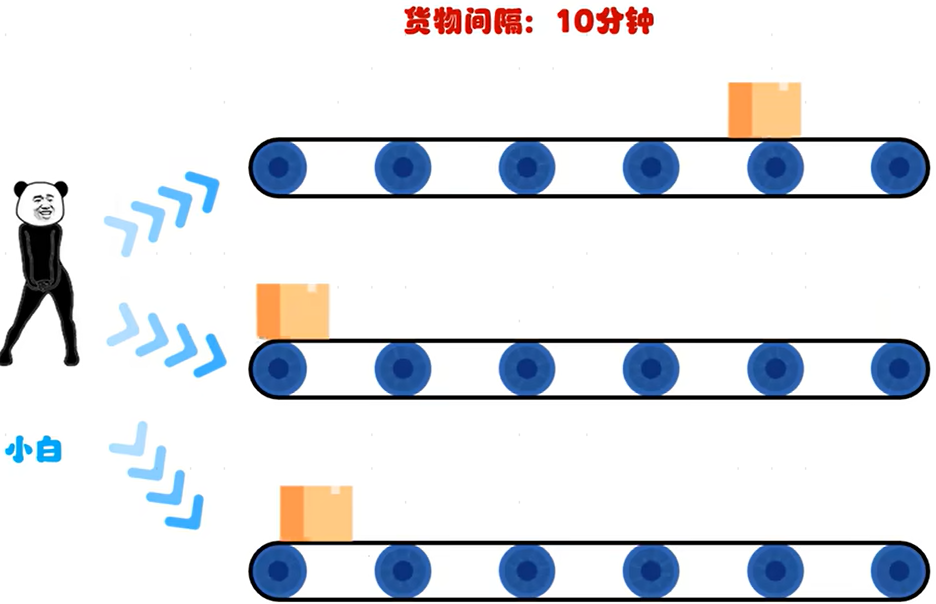
多线程如何提高工作效率:参考下图....把本来可以摸鱼的10分钟利用起来
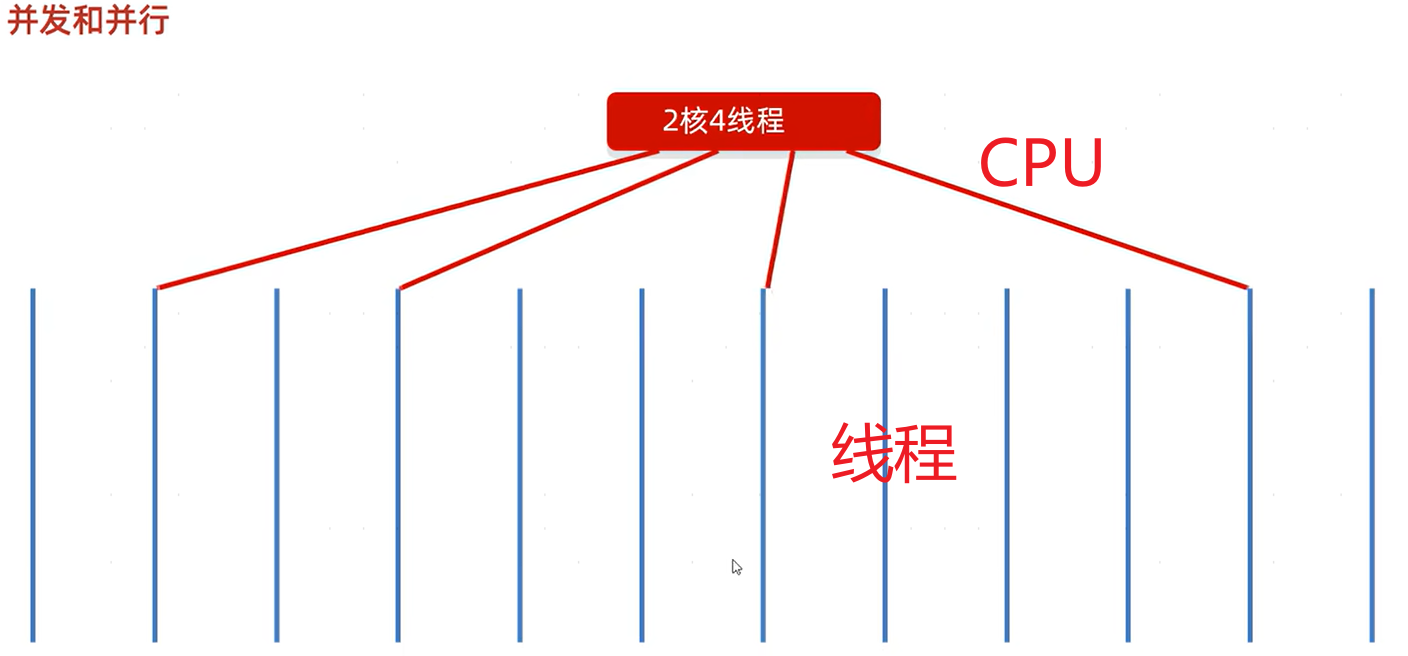
卍,并发与并行:
并发:在同一时刻,有多个指令在单个CPU上交替执行。
并行:在同一时刻,有多个指令在多个CPU上同时执行。
并发和并行可以同时存在,如下图:
卍,多线程的实现方式:三种
- 继承Thread类的实现方式
public class Test { public static void main(String[] args) { /** * 多线程的第一种启动方式:继承Thread类 * 1. 自定义一个类继承Thread * 2. 重写run方法 * 3. 创建子类对象,并启动线程 */ MyThread myThread1 = new MyThread(); MyThread myThread2 = new MyThread(); myThread1.setName("线程1"); myThread2.setName("线程2"); // 两个线程会随机交替执行 myThread1.start(); myThread2.start(); } } class MyThread extends Thread { @Override public void run() { // 书写线程要执行的代码 String name = this.getName();//继承的Thread的方法 for (int i = 0; i < 10; i++) { System.out.println(name + " HelloWorld"); } } } - 实现Runnable接口的方式进行实现
public class Test { public static void main(String[] args) { /** * 多线程的第二种启动方式:实现Runnable接口 * 1. 自定义一个类实现Runnable接口 * 2. 重写run方法 * 3. 创建自己的类的对象 * 4. 创建一个Thread类的对象,并开启线程 */ // 创建MyRunTask对象,表示多线程要执行的任务 MyRunTask myRunTask = new MyRunTask(); // 创建线程对象 Thread t1 = new Thread(myRunTask); Thread t2 = new Thread(myRunTask); t1.setName("线程1"); t2.setName("线程2"); //开启线程,两个线程会随机交替执行 t1.start(); t2.start(); } } class MyRunTask implements Runnable { //书写线程要执行的代码 @Override public void run() { //想要用Thread类中的方法首先要获取到Thread对象 Thread thread = Thread.currentThread(); for (int i = 0; i < 10; i++) { System.out.println(thread.getName() + " HelloWorld"); } } } - 利用Callable接口和Future接口方式实现
public class Test { public static void main(String[] args) throws ExecutionException, InterruptedException { /** * 多线程的第三种启动方式:利用Callable接口和Future接口 * 特点:可以获取到多线程运行的结果 * * 1. 创建一个类MyCallable实现Callable接口 * 2. 重写call方法(是有返回值的,表示多线程运行的结果) * * 3. 创建MyCallable的对象(表示多线程要执行的任务) * 4. 创建FutureTask的对象(作用:管理多线程运行的结果) * 5. 创建Thread类的对象,并启动(表示线程) * * 6. 使用FutureTask对象获取多线程运行结果 * */ // futureTasks用于存放每个线程的运算结果 List<FutureTask<Integer>> futureTasks = new ArrayList<>(); for (int i = 0; i < 5; i++) { /** * 创建MyCallable对象,表示多线程要执行的任务 * * 这里把Callable的初始化放在循环里,则每次都会创建一个新的Callable对象,多个线程操作的是各自的不同的Callable对象 * 如果放在循环外,则多个线程操作的是同一个Callable对象。 * 可以通过Callable的方法call()中打印this对象看到结果 */ MyCallable myCallable = new MyCallable(i + 10); /** * 创建FutureTask对象,用于管理多线程的运行结果 * 注意:这行代码只有main线程会执行,并不涉及到多线程。又因为ArrayList是有序的,存的时候和取的时候元素顺序是一致的 * 所以最终从futureTasks中获取结果的时候,肯定是依次打印sum(10), sum(11),...,sum(14)的结果 */ FutureTask<Integer> futureTask = new FutureTask<>(myCallable); futureTasks.add(futureTask); // 创建线程的对象 Thread t = new Thread(futureTask); t.start(); System.out.println(Thread.currentThread().getName()); } // 获取多线程运行的结果 for (FutureTask<Integer> futureTask : futureTasks) { Integer sum = futureTask.get(); System.out.println(sum);// 结果肯定是依次打印55 66 78 91 105 } } }
多线程三种实现方式对比:
| 实现方式 | 优点 | 缺点 |
| 继承Thread类 | 编程比较简单,可以直接使用Thread类中的方法 | 可扩展性较差,不能再继承其他的类 |
| 实现Runnable接口 | 扩展性强,实现该接口的同时还可以继承其他的类 | 编程相对复杂,不能直接使用Thread类中的方法 |
| 实现Callable接口(可以获取多线程运行结果) |
卍,Thread类中的常见成员方法:
| 方法名称 | 说明 |
| String getName() | 返回此线程的名称 |
| void setName(String name) | 设置线程的名称(构造方法也可以设置线程名称) |
| static Thread currentThread() | 获取当前线程的对象 |
| static void sleep(long millis) | 让线程休眠指定的时间,单位为毫秒 |
| void setPriority(int newPriority) | 设置线程的优先级。 |
| final int getPriority() | 获取线程的优先级 |
| final void setDaemon(boolean on) | 设置为守护线程 |
| public static void yield() | 出让线程/礼让线程 |
| public void join() | 插入线程/插队线程 |
Thread.currentThread() //当Java虚拟机启动之后,会自动的启动多条线程。其中一条线程就叫做main线程。他的作用就是去调用main方法,并执行里面的代码。
设置线程优先级:
- 计算机当中,线程的调度有两种方式
- 抢占式调度:多个线程抢夺CPU的执行权。CPU执行哪个线程是不确定的,执行多长时间也是不确定的。提现一个随机性。
- 非抢占式调度:所有线程轮流执行,执行时间也差不多。
- Java中采用的是抢占式调度。线程优先级从1-10,默认为5.优先级越高,抢占到CPU的概率是越高的。运行同样任务的两个线程,设置了优先级后也不能保证优先级高的一定比优先级低的先执行完毕,但是优先级高的线程先运行完的概率是高的。
守护线程:当其他的非守护线程执行完毕之后,守护线程会陆续结束(不会立即结束)。应用场景举例:qq聊天过程中发送文件,聊天是一个线程,发送文件是一个线程。当聊天窗口关闭后,发送文件的线程也没必要继续了,这时可以把发送文件的线程设置为守护线程。
出让线程:出让当前CPU的执行权,但是出让之后当前线程可能又抢到了CPU的执行权。所以这个方法也是概率性的,尽可能让两个线程均匀分布。
插入线程:thread.join() //表示把 thread这个线程插入到当前线程之前,也就是thread线程中的任务全部执行完毕后才会执行当前线程的任务。可以使用Thread.sleep()方法模拟测试。
卍,线程的生命周期:如下图
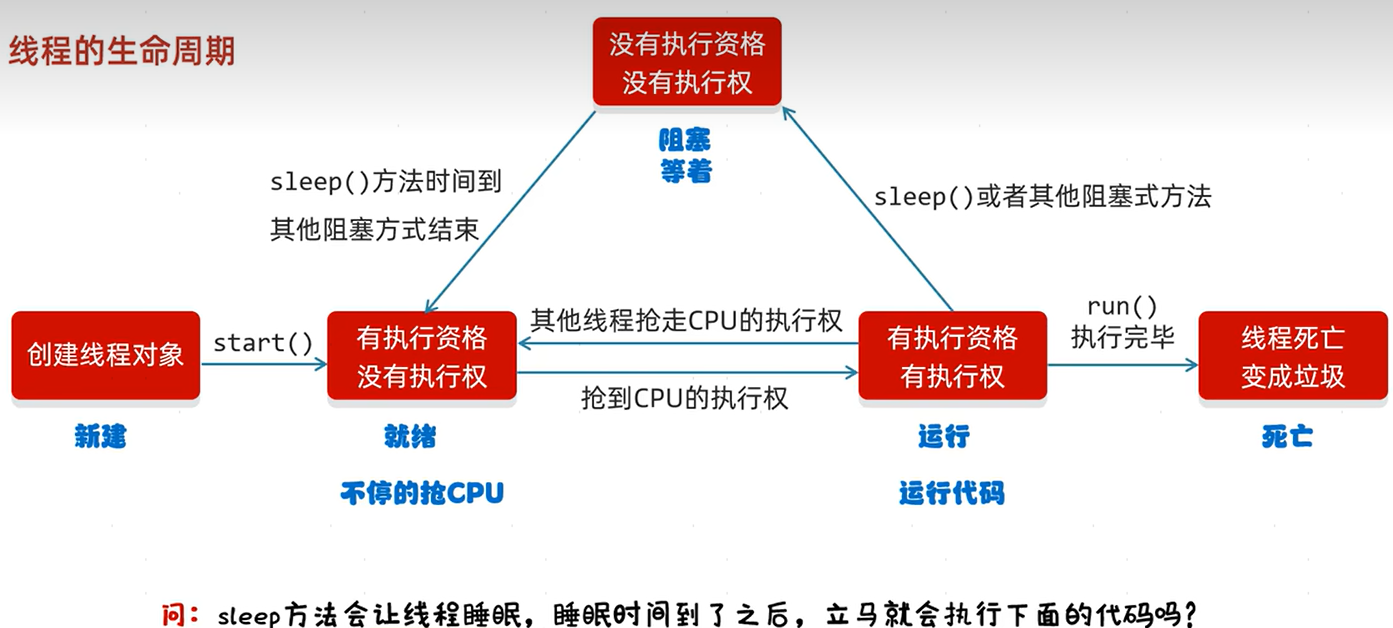
解释图中的一些信息:
- 创建线程对象,运行start()方法之后,变为就绪状态。就绪状态含义是:可以抢夺CPU了,但是因为还没抢到CPU,所以没有执行代码的权限。
- 问题答案:不会立即执行,因为sleep睡眠时间到了之后变为就绪状态,需要去抢CPU,只有抢到CPU之后才会执行代码。
卍,线程安全问题:参考此视频。
多线程可以提高效率,但是提高效率的同时,也会带来一个问题:不安全。因为线程之间是共享数据的,所以可能会导致共享数据和期望的不一样。
CPU执行每一句代码都需要时间,在此行代码实际生效的过程中,CPU可能处于等待时间(比如等待IO,等待内存中创建对象等等),等待的过程中CPU的执行权就有可能被别的线程抢夺!总结就是:线程在执行代码的时候,CPU的执行权随时可能会被其他的线程抢走!线程执行时,具有随机性。
示例:三个窗口共同销售100张票,模拟窗口卖票程序。对于共享数据staticTicket的操作就出现了问题。
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//三个窗口共同销售100张票,模拟窗口卖票程序
TicketThread ticketThread1 = new TicketThread("窗口1");
TicketThread ticketThread2 = new TicketThread("窗口2");
TicketThread ticketThread3 = new TicketThread("窗口3");
ticketThread1.start();
ticketThread2.start();
ticketThread3.start();
}
}
class TicketThread extends Thread {
private int ticket;
// 表示这个类的所有对象都共享staticTicket数据。
private static int staticTicket;
TicketThread() {
}
public TicketThread(String name) {
super(name);
}
@Override
public void run() {
/**
* Thread[窗口1,5,main]
* Thread[窗口3,5,main]
* Thread[窗口2,5,main]
* 这里的this指的就是各个ticketThread线程
*/
System.out.println(this);
// sellTicket();
sellStaticTicket();
}
/**
* 此种卖票方式会出现如下现象:两种现象出现的原因是相同的
* 1. 相同的票出现多次:线程在执行代码的时候,CPU的执行权随时可能会被其他的线程抢走
* 2. 出现了超出范围的票
*/
private void sellStaticTicket() {
for (; ; ) {
if (staticTicket < 100) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
/**
* 第一个线程自增后还没来的及执行下一行打印,CPU的执行权就被另一个线程给抢走了,第二个线程又将staticTicket自增了一次,
* 下次第一个线程再次抢到CPU执行权时就会打印自增2次后的值。所以就出现了重复票和超出范围的票
*/
staticTicket++;
System.out.println(String.format("%s正在卖%s张票", getName(), staticTicket));
} else {
break;
}
}
}
/**
* 此种卖票方式:三个窗口各自卖100张,总共卖了300张票!
* 原因:因为这里没有涉及到多个线程共享的数据,ticket是每个线程独有的数据,所以每个线程各自运行,互不影响!
*/
private void sellTicket() {
for (; ; ) {
if (ticket < 100) {
ticket++;
System.out.println(String.format("%s正在卖%s张票", getName(), ticket));
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
break;
}
}
}
}线程安全问题的解决方法:同步代码块:把操作共享数据的代码锁起来。
原理:把操作共享数据的代码加锁,锁默认是开的,当一个线程A进去之后锁就关闭。线程A在锁内部代码块中时,就算其他线程抢到了CPU的执行权也无法进入锁住的代码块(因为锁现在是关着的),只能在锁外面等着。只有当线程A把锁住的代码块执行完然后从锁中出来了,锁才会再次打开。这时候各个线程再次抢夺CPU的执行权,抢到的才能进入锁内部,进入后锁又锁住了。依次循环。
格式:synchronized (锁对象) {操作共享数据的代码/同步代码块}
- 锁默认打开,有一个线程A进去了,锁自动关闭。线程A将里面的代码全部执行完毕后从同步代码块中出来,锁自动打开。
- 锁对象很随意,但是一定要是唯一的的!这样不同的线程使用的才是同一把锁,才能实现 同步代码块中的代码是被各个线程轮流执行的 目的。如果锁不是唯一的,每个线程都用各自的锁,那么锁也就失去了意义!
- 比如锁可以是类中的一个静态成员变量 static Object object = new Object(); synchronized(object){...}
- 经常使用的是当前类的字节码对象,比如卖票例子中可以如下使用, synchronized (TicketThread.class){....}
使用同步代码块解决卖票问题的代码:
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//三个窗口共同销售100张票,模拟窗口卖票程序
TicketThread ticketThread1 = new TicketThread("窗口1");
TicketThread ticketThread2 = new TicketThread("窗口2");
TicketThread ticketThread3 = new TicketThread("窗口3");
ticketThread1.start();
ticketThread2.start();
ticketThread3.start();
}
}
class TicketThread extends Thread {
private int ticket;
private static int staticTicket;
TicketThread() {
}
public TicketThread(String name) {
super(name);
}
@Override
public void run() {
/**
* Thread[窗口1,5,main]
* Thread[窗口3,5,main]
* Thread[窗口2,5,main]
*/
System.out.println(this);
// sellTicket();
sellStaticTicket();
}
/**
* synchronized同步代码块的细节:
* 1. 同步代码块不能放到循环外面,否则就是一个线程(如线程A)进入同步代码块,锁关闭,
* 然后卖完100张票出来(此时线程A的代码全部执行完毕,此线程就会终止),锁打开,
* 然后其他线程(如线程B)再进入同步代码块,发现staticTicket=100,直接break,然后线程B的代码全部执行结束,线程终止。
* 然后线程C再进入,和B一样终止。所有线程都终止,main线程也会终止,程序结束!
* 2. 锁对象要是唯一的,通常是 类的字节码文件对象,也就是类的字节码文件在内存中的地址(也就是JVM内存中方法区中的一个地址)
*/
private void sellStaticTicket() {
// synchronized (TicketThread.class) { // 同步代码块不能放到循环外面
for (; ; ) {
synchronized (TicketThread.class) { // 同步代码块的正确位置
System.out.println(Thread.currentThread().getName());
if (staticTicket < 100) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
/**
* 第一个线程自增后还没来的及执行下一行打印,CPU的执行权就被另一个线程给抢走了,第二个线程又将staticTicket自增了一次,
* 下次第一个线程再次抢到CPU执行权时就会打印自增2次后的值。所以就出现了重复票和超出范围的票
*/
staticTicket++;
System.out.println(String.format("%s正在卖%s张票", getName(), staticTicket));
} else {
break;
}
}
}
}
/**
* 此种卖票方式:三个窗口各自卖100张,总共卖了300张票!
* 因为不涉及多个线程的共享数据,所以这种方式加不加锁结果都是一样,当然加锁会影响效率(更慢了)
*/
private void sellTicket() {
for (; ; ) {
synchronized (TicketThread.class) {
if (ticket < 100) {
ticket++;
System.out.println(String.format("%s正在卖%s张票", getName(), ticket));
try {
Thread.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
break;
}
}
}
}
}同步方法:就是把synchronized关键字加到方法上。
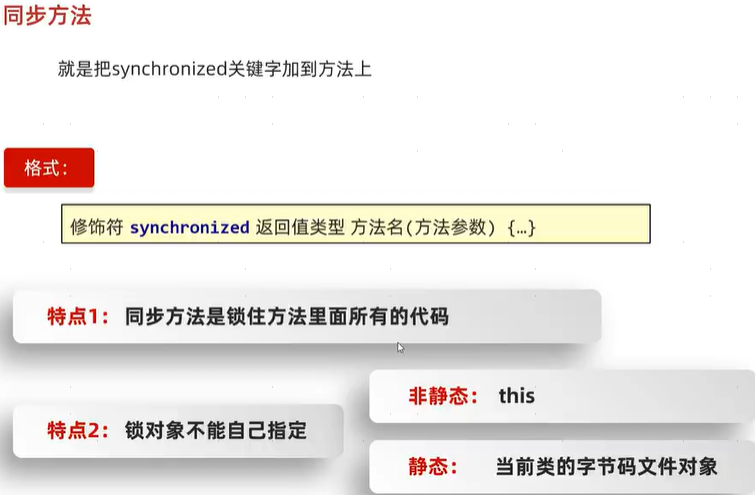
上图注释:
同步方法的锁对象有两种情况:
- 此同步方法是非静态的:锁对象为this。问题来了:锁对象要求是唯一的,为什么this可以作为锁对象?
- 原因是多线程的第二种使用方式(实现Runnable接口)和第三种使用方式(实现Callable接口)中,多线程需要运行的代码实际就是Runnable接口或Callable接口的实现类中书写的,然后把这个实现类对象传入不同的线程中(即new Thread(Runnable),其中Callable接口还需要通过Runnable的实现类FutureTask中转一下再传入Thread的构造方法中)。this指的是Runnable或Callable的实现类对象。如果这个Runnable和Callable接口的实现类只实例化了一次,那么this对于多个线程来讲就是唯一的!也就是说只有使用第二种或第三种方式的多线程同步方法才能生效,使用第一种继承Thread类的方式使用多线程同步方法是不生效的(因为这时this指的是Thread继承类的实例化对象,有多个!)
- 此同步方法是静态的:锁对象为当前类的字节码文件对象。
非静态同步方法的代码示例:
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyRunTask myRunTask = new MyRunTask();
Thread t1 = new Thread(myRunTask);
Thread t2 = new Thread(myRunTask);
Thread t3 = new Thread(myRunTask);
t1.setName("窗口1");
t2.setName("窗口2");
t3.setName("窗口3");
t1.start();
t2.start();
t3.start();
}
}
// 这里是先用同步代码块的方式书写
class MyRunTask implements Runnable {
/**
* 注意:这里不再需要使用静态变量了,因为MyRunTask只会被实例化一次
* 每个线程操作的都是这个ticket变量,所以这个ticket变量就是各个线程的共享数据。
*/
int ticket;
@Override
public void run() {
//书写线程要执行的代码
for (; ; ) {
synchronized (this) { //这里this只有一个,可以作为锁对象
if (ticket < 100) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
ticket++;
System.out.println(String.format("%s 正在卖第 %d 张票", Thread.currentThread().getName(), ticket));
} else {
break;
}
}
}
}
}
// 将上面的同步代码块变为同步方法
class MyRunTask implements Runnable {
/**
* 注意:这里不再需要使用静态变量了,因为MyRunTask只会被实例化一次
* 每个线程操作的都是这个ticket变量,所以这个ticket变量就是各个线程的共享数据。
*/
int ticket;
@Override
public void run() {
//书写线程要执行的代码
for (; ; ) {
if (m()) break;
}
}
// 非静态同步方法,锁对象为this。
private synchronized boolean m() {
if (ticket < 100) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
ticket++;
System.out.println(String.format("%s 正在卖第 %d 张票", Thread.currentThread().getName(), ticket));
} else {
return true;
}
return false;
}
}
经典面试题:String 和 StringBuilder和StringBuffer的区别
- String类对象是不可变字符串,因为源码中是用字节数组保存字符串的:private final byte[] value。private和final决定了String类对象的字符串不可变。每次对
String变量进行修改的时候其实都等同于生成了一个新的String对象。 - StringBuilder和StringBuffer对象是可变的字符串。
- StringBuilder是线程不安全的,JDK1.5之后出现的,StringBuffer是线程安全的。
- 单线程下StringBuilder的效率理论上讲应该也比StringBuffer要高,因为一个有synchronized修饰,一个没有,用synchronized就要加锁,获取锁和释放锁都需要时间。
- 单线程和多线程下StringBuffer的区别:考察的是synchronized的四种锁的状态。参考此文。
※,Lock锁:synchronized的锁是JVM虚拟机自动加和释放的。如果想手动添加和释放锁就需要使用JDK5提供的Lock锁。

public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread t1 = new TicketThread("窗口1");
Thread t2 = new TicketThread("窗口2");
Thread t3 = new TicketThread("窗口3");
t1.start();
t2.start();
t3.start();
}
}
class TicketThread extends Thread {
private static int staticTicket;
TicketThread() {
}
public TicketThread(String name) {
super(name);
}
/**
* 这里的锁必须使用static修饰,不然每个线程都会有自己的锁,就相当于没加锁。
*/
static Lock lock = new ReentrantLock(true);
@Override
public void run() {
for (; ; ) {
/**
* 抢夺到CPU执行权的线程A会拿到这把锁,然后进入锁内部执行代码。在线程A执行锁内部代码的时候,CPU的执行权被另外的线程B抢到了
* 但是线程B依然要在锁外面等着。等线程A执行完锁内部的代码就会从锁里出来,同时将锁释放。然后各个线程再次抢夺CPU执行权,抢到的拿到锁
* 不停循环。
*/
lock.lock();
try {
if (staticTicket < 100) {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
/**
* 第一个线程自增后还没来的及执行下一行打印,CPU的执行权就被另一个线程给抢走了,第二个线程又将staticTicket自增了一次,
* 下次第一个线程再次抢到CPU执行权时就会打印自增2次后的值。所以就出现了重复票和超出范围的票
*/
staticTicket++;
System.out.println(String.format("%s 正在卖 %s 张票", getName(), staticTicket));
} else {
break; //最后一次会执行break,在break之前还要去执行以下finally中的语句,这就保证了锁一定会被释放
}
} catch (Exception e) {
e.printStackTrace();
} finally {
/**
* 这里将释放锁的代码写在try catch finally里面是有原因的。
* 关键在于for循环中的break有可能直接跳过这行释放锁的代码,导致有线程始终无法拿到锁,导致程序无法停止。
* 为了保证释放锁的代码无论任何时候都可以被执行,所以将其写在finally中
*/
lock.unlock();
}
}
}
}卍,死锁
public class Test {
public static void main(String[] args) throws ExecutionException, InterruptedException {
Thread t1 = new TicketThread("线程A");
Thread t2 = new TicketThread("线程B");
t1.start();
t2.start();
}
}
class TicketThread extends Thread {
private static int staticTicket;
TicketThread() {
}
public TicketThread(String name) {
super(name);
}
static final Object objectA = new Object();
static final Object objectB = new Object();
@Override
public void run() {
for (; ; ) {
if ("线程A".equals(Thread.currentThread().getName())) {
synchronized (objectA) {
System.out.println("线程A拿到A锁,准备拿B锁");
synchronized (objectB) {
System.out.println("线程A拿到B锁,顺利执行完一轮");
}
}
}
if ("线程B".equals(Thread.currentThread().getName())) {
synchronized (objectB) {
System.out.println("线程B拿到了B锁,准备拿A锁");
synchronized (objectA) {
System.out.println("线程B拿到了A锁,顺利执行完一轮");
}
}
}
}
}
}卍,多线程中的生产者和消费者(又叫做等待唤醒机制)
生产者和消费者模式是十分经典的多线程协作机制。可以让多线程的运行打破随机运行的规则,让多个线程轮流执行。
生产者和消费者涉及到了2个线程,分别称为生产者(制造数据)和消费者(消费数据)。让两个线程打破随机运行规则的核心思想是:利用第三方来控制线程的运行。

| 方法名称 | 说明 |
| void wait() | 当前线程等待,直到被其他线程唤醒 |
| void notify() | 随机唤醒单个线程 |
| void notifyAll() | 唤醒所有线程 |
生产者和消费者(等待唤醒机制)代码实现方式一:
/**
* Desk的作用:控制生产者和消费者的执行
* TODO:可以优化的点:Desk中的变量都可以使用静态的,这样就不需要实例化Desk对象了
*/
public class Desk {
/**
* 0 代表桌子上无面条;1 代表桌子上有面条
* 定义为int类型方便扩展,可以控制2个以上的线程的运行
*/
int noodle;
// 总共10碗面条,消费完终止程序
int count = 10;
public Desk() {
}
public Desk(int noodle) {
this.noodle = noodle;
}
//
final Object lock = new Object();
}
public class Consumer extends Thread {
Desk desk;
public Consumer(Desk desk, String threadName) {
super(threadName);
this.desk = desk;
}
@Override
public void run() {
/**
* 多线程的代码书写套路
* 1. 循环
* 2. 同步代码块
* 3. 判断共享数据是否到了末尾(到了末尾)
* 4. 判断共享数据是否到了末尾(未到末尾,执行核心逻辑)
*/
for (; ; ) {
synchronized (desk.lock) {
// 共享数据即线程什么时候会停止,在这里是10碗面条:desk.count
if (desk.count == 0) {
break;
} else {
/**
* 先判断桌子上是否有面条
* 如果没有等待
* 如果有,开吃。
* 吃的总数-1
* 吃完之后唤醒生产者继续生产
* 修改面条的状态
*/
if (desk.noodle == 0) {
// 等待
// System.out.println(getName() + "在等待");
try {
/**
* 必须用锁来调用wait()方法。
* 将当前线程与锁进行绑定
*/
desk.lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
desk.noodle = 0;
/**
* 唤醒这把锁绑定的所有线程
* 位置随意
*/
desk.lock.notifyAll();
desk.count--;
System.out.println(getName() + "消费了一碗面条,还能再吃" + desk.count + "碗");
}
}
}
}
}
}
public class Producer extends Thread {
Desk desk;
public Producer(Desk desk, String threadName) {
super(threadName);
this.desk = desk;
}
@Override
public void run() {
for (; ; ) {
synchronized (desk.lock) {
if (desk.count == 0) {
break;
} else {
/**
* 判断桌子上是否有食物
* 如果有,等待
* 如果没有,生产食物
* 修改桌子上的食物状态
* 唤醒等待的消费者开吃
*/
if (desk.noodle == 1) {
//等待
// System.out.println(getName() + "线程在等待");
try {
/**
* 必须用锁来调用wait()方法。
* 将当前线程与锁进行绑定
*/
desk.lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
System.out.println(getName() + "线程生产了一碗面条");
desk.noodle = 1;
/**
* 唤醒这把锁绑定的所有线程
*/
desk.lock.notifyAll();
}
}
}
}
}
}
public class DemoTest {
public static void main(String[] args) throws InterruptedException {
Desk desk = new Desk(1);
new Producer(desk, "生产者").start();
new Consumer(desk, "消费者").start();
}
}生产者和消费者(等待唤醒机制)代码实现方式二:阻塞队列的方式,不需要利用第三方,也不需要自己加锁释放锁,也不需要手动唤醒或让线程等待。阻塞队列内部逻辑都有已经实现!
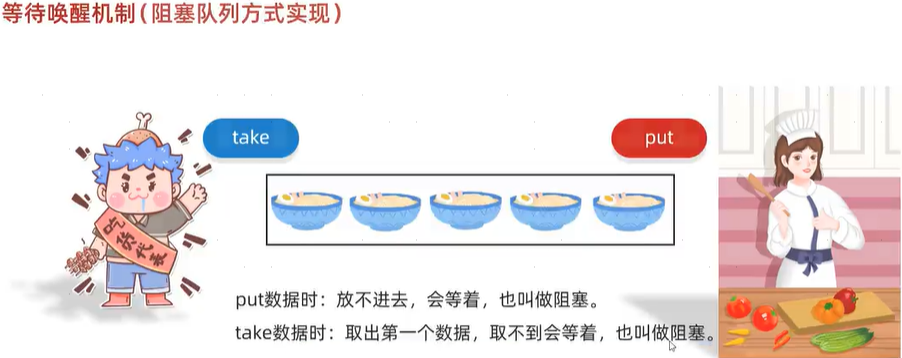
阻塞队列的继承结构:
实现了四个接口:Iterable, Collection,Queue,BlockingQueue
两个实现类:
- ArrayBlockingQueue: 底层是数组,有界。必须指定数组长度
- LinkedBlockingQueue:底层是链表,但不是真正的无界,最大为int的最大值。
使用阻塞队列成生产者和消费者(等待唤醒机制) 代码:
public class Consumer extends Thread {
ArrayBlockingQueue<Integer> arrayBlockingQueue;
public Consumer(String name, ArrayBlockingQueue<Integer> arrayBlockingQueue) {
super(name);
this.arrayBlockingQueue = arrayBlockingQueue;
}
@Override
public void run() {
/**
* 多线程代码套路:
* 1. 循环
* 2. 同步代码块
* 3. 判断共享数据是否到了末尾(到了)
* 4. 判断共享数据是否到了末尾(未到,执行核心逻辑)
*
* 这里因为使用了阻塞队列,已经有锁了,所以不需要自己加锁了
*/
for (int i = 0; i < 10; i++) {
try {
// 不断的从阻塞队列中消费数据
Integer take = arrayBlockingQueue.take();
System.out.println(Thread.currentThread().getName() + "消费了一条数据: " + take);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Producer extends Thread {
ArrayBlockingQueue<Integer> arrayBlockingQueue;
public Producer(String name, ArrayBlockingQueue<Integer> arrayBlockingQueue) {
super(name);
this.arrayBlockingQueue = arrayBlockingQueue;
}
@Override
public void run() {
/**
* 多线程代码套路:
* 1. 循环
* 2. 同步代码块
* 3. 判断共享数据是否到了末尾(到了)
* 4. 判断共享数据是否到了末尾(未到,执行核心逻辑)
*
* 这里因为使用了阻塞队列,已经有锁了,所以不需要自己加锁了
*/
for (int i = 0; i < 12; i++) {
try {
// 不断的把数据放到阻塞队列中
arrayBlockingQueue.put(1);
System.out.println(Thread.currentThread().getName() + "生产了一条数据");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class DemoTest {
public static void main(String[] args) {
/**
* 需求:使用阻塞队列成生产者和消费者(等待唤醒机制) 代码
* 细节:
* 生产者和消费者必须使用同一个阻塞队列!
*/
ArrayBlockingQueue<Integer> arrayBlockingQueue = new ArrayBlockingQueue<>(1);
Producer producer = new Producer("生产者", arrayBlockingQueue);
Consumer consumer = new Consumer("消费者", arrayBlockingQueue);
producer.start();
consumer.start();
}
}卍,线程的状态:
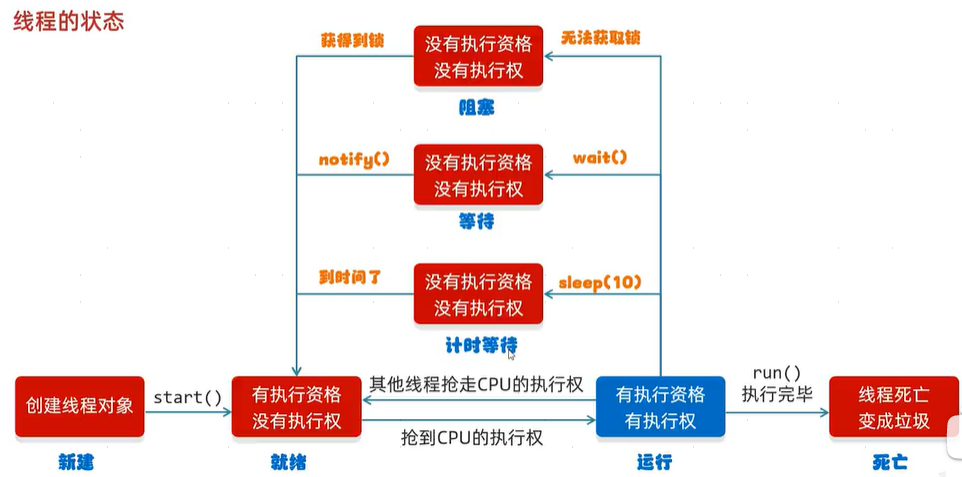
Thread.State内部枚举定义了线程的六种状态。


图解:Java的虚拟机当中没有定义线程的运行状态,此处是为了便于理解添加的。之所以不定义运行状态的原因如下:
- 当线程抢到多CPU的执行权时,JVM虚拟机就会把当前的线程交给操作系统去管理,虚拟机自己就不管了。既然不管了就没必要定义运行状态了。
卍,多线程练习
/**
* 同时开启2个线程,共同获取1-100之间的数字。
* 要求:输出所有的奇数。
*/
public class PrintOdd {
public static void main(String[] args) {
//注意这里使用了匿名内部类,不能用lambda表达式代替!lambda表达式只能用于函数式接口的**方法**!
Runnable runnable = new Runnable() {
int i = 1;
@Override
public void run() {
/**
* 多线程代码套路:
* 1. 循环
* 2. 同步代码块
* 3. 判断共享数据是否到了末尾(到了)
* 4. 判断共享数据是否到了末尾(未到,执行核心逻辑)
*
*/
for (; ; ) {
synchronized (this) {
if (i > 100) {
break;
} else {
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
if (i % 2 == 1) {
System.out.println(Thread.currentThread().getName() + ":" + i);
}
i++;
}
}
}
}
};
Thread t1 = new Thread(runnable, "线程1");
Thread t2 = new Thread(runnable, "线程2");
t1.start();
t2.start();
}
}※,线程池
卍,线程池的主要核心原理:
- 1. 创建一个池子
- 2. 提交任务时,池子会创建新的线程对象,任务执行完毕,线程归还给池子下回再次提交任务时,不需要创建新的线程,直接复用已有的线程即可
- 3. 但是如果提交任务时,池子中没有空闲线程,也无法创建新的线程,任务就会排队等待
卍,线程池的代码实现
JDK1.5提供了java.util.concurrent.Executors 工具类,通过调用方法返回不同类型的线程池对象。
| 方法名称 | 说明 |
| public static ExecutorService newCachedThreadPool() | 创建一个没有上限的线程池(上限是int的最大值) |
| public static ExecutorService newFixedThreadPool(int nThreads) | 创建有上限的线程池 |
/**
* 往线程池中提交任务,主要有两种方法,execute()和submit()。
* execute()用于提交不需要返回结果的任务。
* submit()用于提交一个需要返回果的任务。该方法返回一个Future对象,通过调用这个对象的get()方法,我们就能获得返回结果。
* get()方法会一直阻塞,直到返回结果返回。另外,我们也可以使用它的重载方法get(long timeout, TimeUnit unit),这个方法也会阻塞,但是在超时时间内仍然没有返回结果时,将抛出异常TimeoutException。
*
*/
ExecutorService pool = Executors.newFixedThreadPool(5);
for (int i = 0; i < 10; i++) {
pool.execute(() -> {
System.out.println("threadName: " + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
/**
* 在线程池使用完成之后,我们需要对线程池中的资源进行释放操作,这就涉及到关闭功能。我们可以调用线程池对象的shutdown()和shutdownNow()方法来关闭线程池。
* 这两个方法都是关闭操作,又有什么不同呢?
*
* shutdown()会将线程池状态置为SHUTDOWN,不再接受新的任务,同时会等待线程池中已有的任务执行完成再结束。
* shutdownNow()会将线程池状态置为SHUTDOWN,对所有线程执行interrupt()操作,清空队列,并将队列中的任务返回回来。
* 另外,关闭线程池涉及到两个返回boolean的方法,isShutdown()和isTerminated,分别表示是否关闭和是否终止。
*/
pool.shutdownNow();
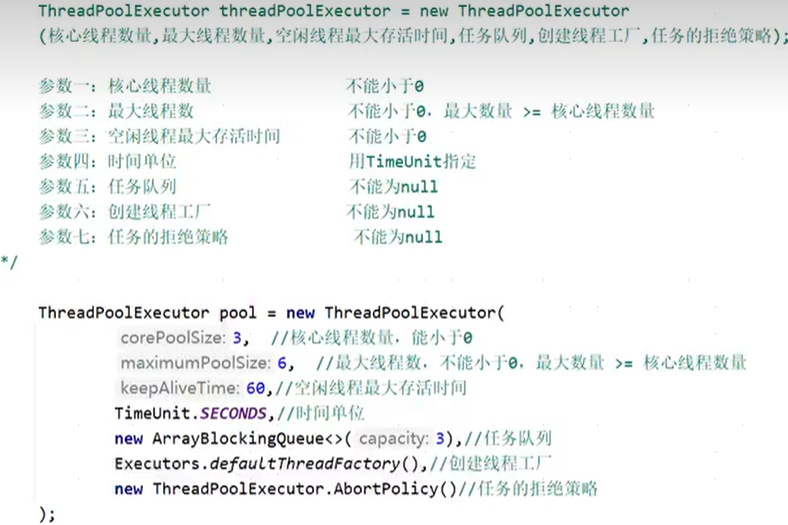
}卍,自定义线程池: 也就是Executors工具类封装方法的底层实现

卍,线程池设置为多大比较合适
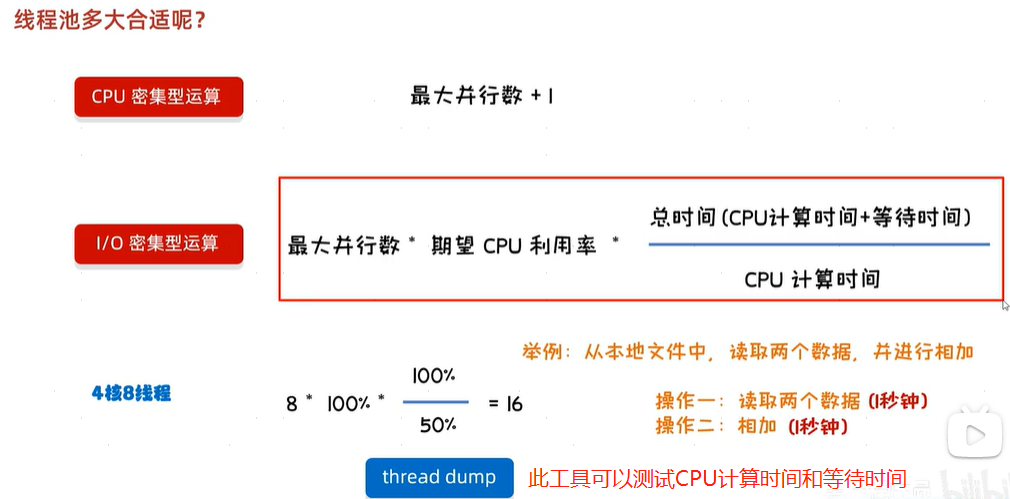
图解:
CPU密集型运算: 线程池大小 = 最大并行数 + 1 // 4核8线程的CPU最大并行数就是8。当然实际以下面Java代码得到的为准。
// 获取JVM可以利用的CPU线程数。有的操作系统不会把所有线程都给同一个软件使用
int processors = Runtime.getRuntime().availableProcessors();※,多线程中的其他扩展知识:参考百度网盘存储的黑马视频文件夹
- volatile
-
volatile与synchronized的区别:
-
volatile只能修饰实例变量和类变量,而synchronized可以修饰方法,以及代码块。
-
volatile保证数据的可见性,但是不保证原子性(多线程进行写操作,不保证线程安全);而synchronized是一种排他(互斥)的机制(因此有时我们也将synchronized这种锁称之为排他(互斥)锁),synchronized修饰的代码块,被修饰的代码块称之为同步代码块,无法被中断可以保证原子性,也可以间接的保证可见性。
-
-
- 原子性
- 原子类
-
CAS和Synchronized都可以保证多线程环境下共享数据的安全性。那么他们两者有什么区别?
Synchronized是从悲观的角度出发:总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程)。因此Synchronized我们也将其称之为悲观锁。jdk中的ReentrantLock也是一种悲观锁。
CAS是从乐观的角度出发: 总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据。CAS这种机制我们也可以将其称之为乐观锁。
- 并发工具类
- ConcurrentHashMap
- CountDownLatch
- CyclicBarrier
- Semaphore
- Exchanger
教程:Java多线程编程实战指南
卍,第11章:
11.1
※,Linux内核工具perf可以查看程序运行过程中的缓存未命中情况。
sudo perf stat -e cache-references,cache-misses java -jar test.jar※,·lscpu`查看处理器的高速缓存层次。
11.2
11.3
卍,第1章:
1.7. 线程的监视
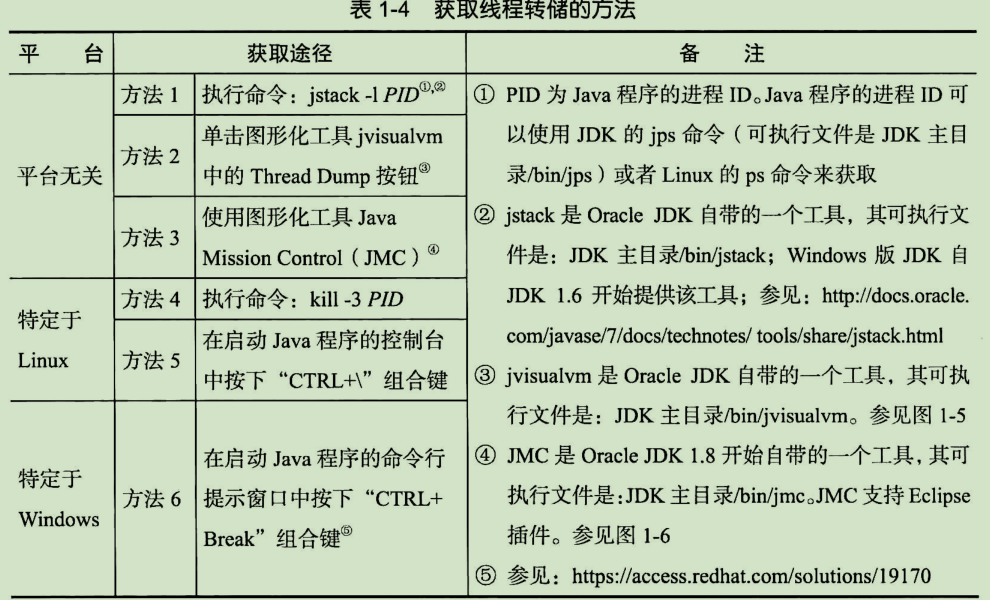
卍,第二章
※,共享变量的含义:共享变量一定是多个线程都会访问到的变量。例如:多个线程运行一个类的同一个实例时,这个实例的属性就是共享变量。多个线程运行同一个类的不同实例时,这个类的属性不是共享变量。
※,原子性保证 要么执行完毕,要么未执行。可见性保证可以获取执行完毕的值而不是未执行的值。
※,
卍,第三章
※,线程安全问题从根源上讲是硬件(如写缓冲器)和软件(编译器)问题。但是从应用程序的角度来看,线程安全问题的产生是由于多线程应用程序缺乏某种东西:线程同步机制。线程同步机制是一套用于协调线程间的数据访问(Data access)及活动(Activity)的机制,该机制用于保障线程安全以及实现这些线程的共同目标。第三章讲解协调线程间共享数据访问的相关关键字和api,第五章讲解协调线程间活动的相关api。从广义上讲,Java平台提供的线程同步机制包括:
- 锁
- volatile关键字
- final关键字
- static关键字
- 一些相关的api,如Object.wait(),Object.notify()等。
※,读锁和写锁
- 任何线程读取变量的时候,其他线程都无法更新这些变量。一个线程更新共享变量的时候,其他任何线程都无法访问该变量。
| 获得条件 | 排他性 | 作用 | |
| 读锁 | 相应的写锁未被任何线程持有 |
对读线程是共享的, 对写线程是排他的 |
允许多个多线程可以同时读取共享变量, 并保障读线程读取共享变量期间没有其他任何线程能够更新这些共享变量 |
| 写锁 |
该写锁未被其他任何线程持有, 并且相应的读锁未被任何线程持有 |
对读线程和写线程都是排他的 | 使得写线程能够以独占的方式访问共享变量。 |
- 读写锁内部实现比内部锁和其他显示锁要复杂的多,因此读写锁只有在以下两个条件同时满足时才适用,否则使用读写锁会得不偿失(开销)。
- 1. 只读操作比写(更新)操作要频繁的多。
- 2. 读线程持有锁的时间比较长。
※,
※,
※,
※,
※,
※,
※,
※,


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· AI与.NET技术实操系列(六):基于图像分类模型对图像进行分类