
【机器学习算法应用与学习_3_代码API篇】3.9模型性能评估
1. 分类模型评估
sklearn有三种方式评估一个模型的预测质量,
1)各模型模块都有一个score方法;
2)cross-validation模块有评估工具;
3)metrics模块有一些评估函数。
这里提供metrics模块API,其他参见参考资料。


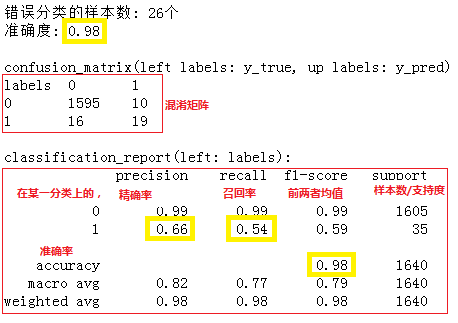
#对测试集进行预测 y_predict = clf.predict(X_test) #----输出分类错误数和准确度 print('错误分类的样本数: %d' % ( y_test!= y_predict).sum() + '个') from sklearn.metrics import accuracy_score print('准确度: %.2f' % accuracy_score(y_test, y_predict)) print() #----输出分类结果混淆矩阵 def my_confusion_matrix(y_true, y_pred): from sklearn.metrics import confusion_matrix labels = list(set(y_true)) conf_mat = confusion_matrix(y_true, y_pred, labels = labels) print("confusion_matrix(left labels: y_true, up labels: y_pred)") print("labels",'\t',end='') for i in range(len(labels)): print(labels[i],'\t',end='') print() for i in range(len(conf_mat)): print(i,'\t',end='') for j in range(len(conf_mat[i])): print(conf_mat[i][j],'\t',end='') print() my_confusion_matrix(y_test,y_predict) print() #----输出分类报告 from sklearn.metrics import classification_report print("classification_report(left: labels):") print(classification_report(y_test, y_predict))
参考资料:
机器学习常用性能指标及sklearn中的模型评估
https://blog.csdn.net/sinat_36972314/article/details/82734370
Without summary,you can't master it.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号