图解B树及C#实现(1)
前言
B树(B-tree),也常被记作 B-树,其中“-”不发音。B树的发明者 Rudolf Bayer 和 Edward M. McCreight 并没有给B树中的 B 明确的定义,大家也不必对此纠结太多。
B+树是B树的变体,两者的适用场景是不一样的,以后也会给大家带来B+树的介绍。
本系列将用三篇文章讲解B树的设计理念及如何用 C# 实现一个内存版本的B树:
完整代码已放至github https://github.com/eventhorizon-cli/EventHorizon.BTree
或者安装 nuget 包进行体验
dotnet add package EventHorizon.BTree
完整代码中包含了debug辅助代码,可以通过调试来了解B树的内部结构。
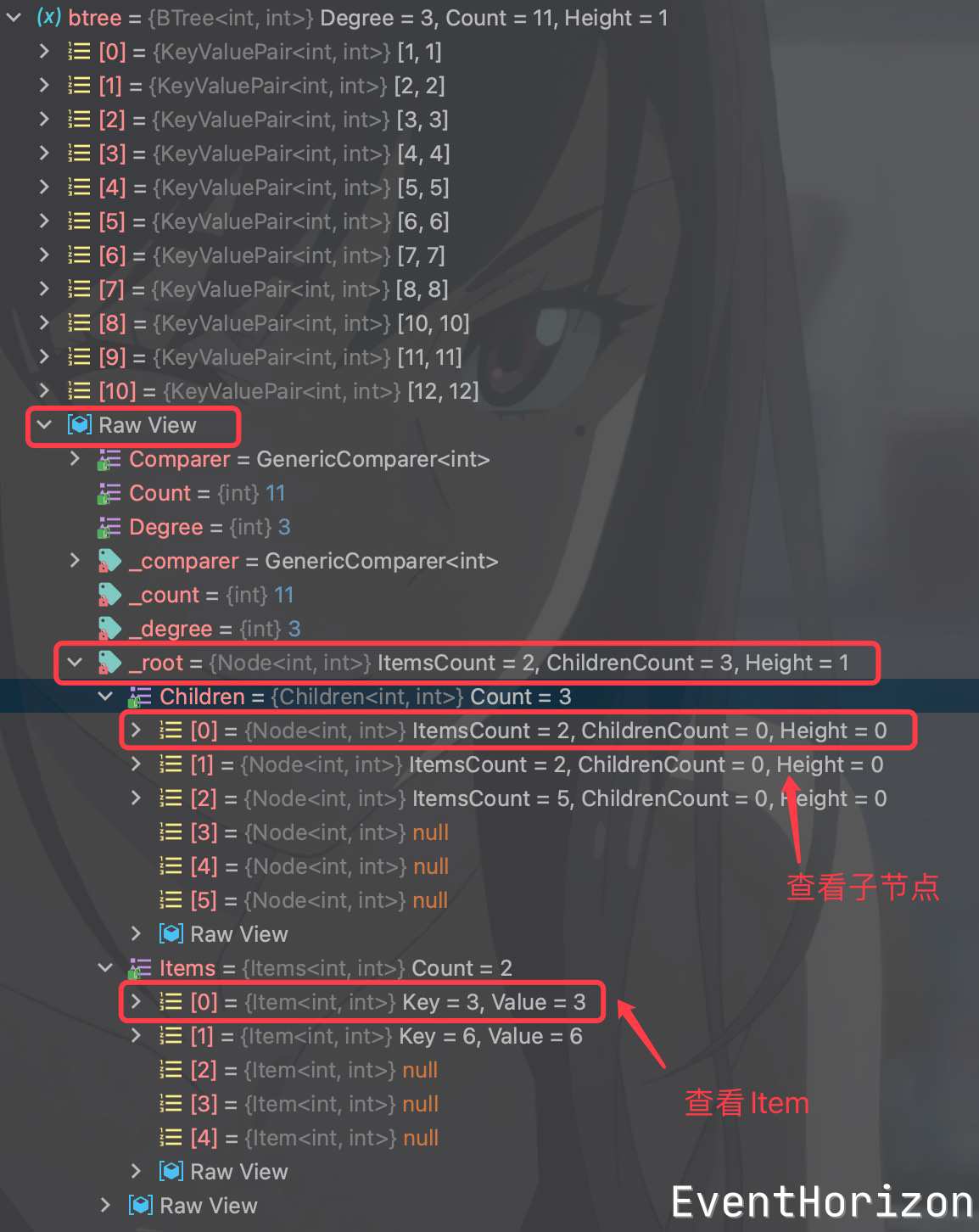
B树最早被设计出来,并不是作为一个单纯的内存数据结构,而是用作 磁盘存储引擎 的索引实现,以后也会单独写一篇文章来做说明。
本文部分说明引用自PingCAP 的公开ppt 宝宝床边故事集:存储引擎,强烈推荐给各位学习。
部分内容属于个人理解,若有不对之处,欢迎指正。
索引原理
局部性(Locality)#
硬件、操作系统等等系统,绝大部分时候,执行一次操作流程 有额外的开销(overhead)。
因此很多部件、模块都设计成:连续执行类似或相同的操作、访问空间相邻的内容时,则将多次操作合并为一次,或多次之间共享上下文信息。这样能极大提升性能。
这种时间、空间上的连续性,叫做局部性。
数据的局部性#
我们把数据的连续性及连续区域大小称为 局部性,连续存放的数据越多,局部性越好。
内存存储和磁盘存储#
IO的访问性能有两个重要的衡量指标:
- IOPS(Input/Output Operations Per Second): 每秒进行IO读写操作的次数
- IOBW(Input/Output Bandwidth): IO带宽
磁盘的IOPS和IOBW都低于内存,IOPS更为明显。
磁盘IO是以 页(page)为单位进行数据读取的,如果数据的局部性好,只加载一个磁盘页到内存就可以实现一组有序数据的连续访问。如果数据的局部性差,则每读取一次数据都有可能要加载一个磁盘页,性能较差。
当数据局部性差时:
- 需要更频繁地访问磁盘
- IOPS 比 IOBW 先达到上限,性能差
当数据局部性好时:
- IOBW 能达到硬件上限
- IOBW 达到上限是理想的最好性能
磁盘存储适合的索引结构#
综上所述,就磁盘存储而言,局部性的好坏对性能影响很大。
有序数组的局部性很好,用二分查找法查询数据的时间复杂度是O(log n)。但插入数据时,时间复杂度就成了O(n)。
二叉平衡树(Self-balancing binary search tree,常见的实现如 AVL树 和 红黑树)用二分查找法查询数据的时间复杂度是O(log n)。插入数据时也是先查询到具体位置,时间复杂度是O(log n)。
但二叉平衡树的局部性很差,这在内存中不是什么问题,因为内存访问随机数据的性能很高,但在磁盘中,不断加载不同的磁盘页,overhead 很高。
数据的局部性越好,读性能更好,但写性能会降低。
数据的局部性越差,读性能会变差,但写性能会更好。
B树则是在这两者之间寻求平衡点:
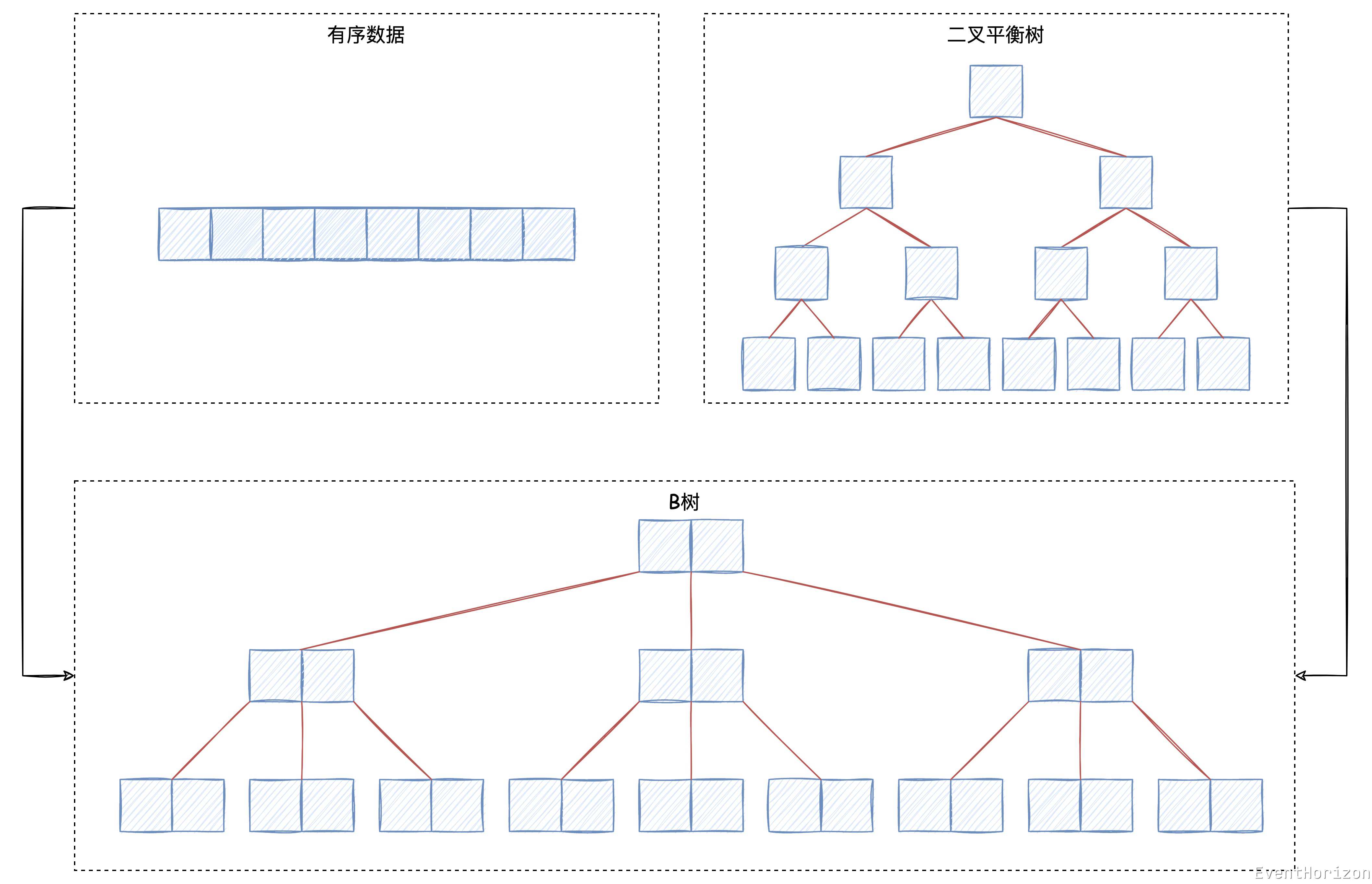
从有序数组的角度看,我们把大数组分割成了一个个小的有序数组,再用另一种有序结构把小数组组织起来,插入数据时,移动数据量减少并且可控。
从树的角度看,用一个个小的有序数组代替元素作为节点,大大增加了局部性,减少了存储 overhead。
B树简介
定义#
B树中的节点分为三种:
- 根节点(root node)
- 内部节点(internal node):存储数据以及指向其子节点的指针。
- 叶子节点(leaf node):叶子节点只存储数据,没有子节点。
B树只有一个节点时,根节点本身就是叶子节点。
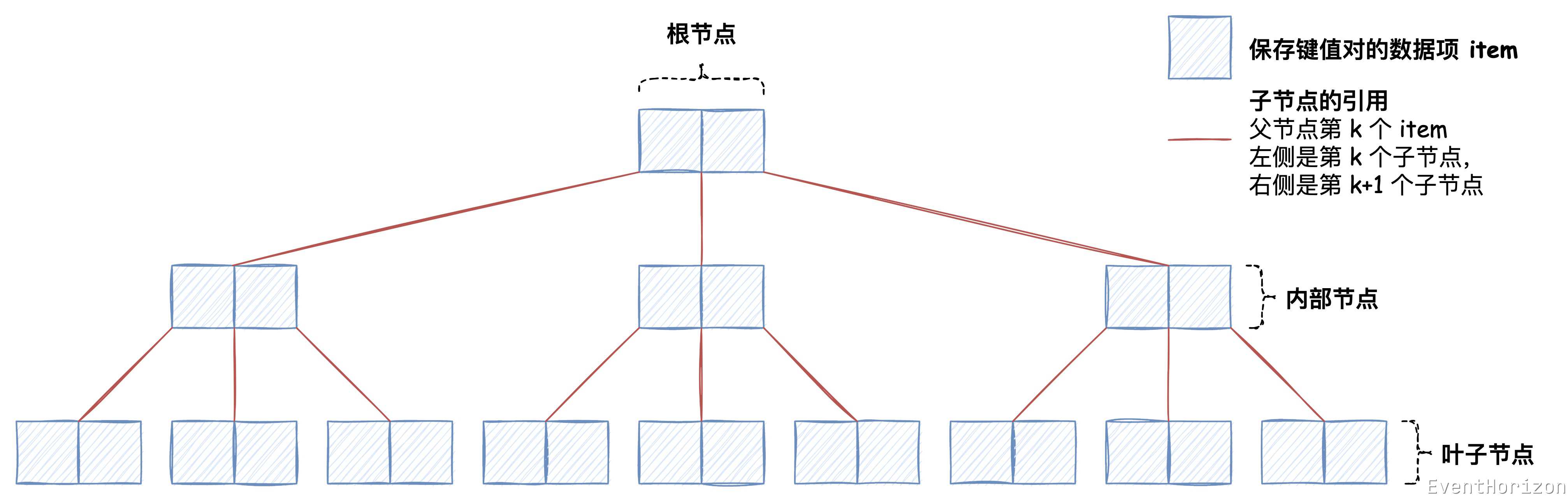
节点中每一个数据项(下文用 item 代替)都是一组键值对。item 的数量范围需要预定义,通常有以下两种定义方式:
- 度(degree):通常简写为 t,2t-1 代表 item 数量上限。
- 阶(order):通常简写为 m,m 代表 item 数量上限。
本文用 度(degree)进行描述,一个度是 t(t>=2) 的B树被设计为具有以下属性:
- 每一个非根节点拥有的键的数量在 [t-1, 2t-1] 之间。
- 每一个节点最多有 2t 个子节点。
- 每一个内部节点最少有 t 个子节点。
- 如果根节点不是叶子节点,那么它至少有两个子节点。
- 有 k 个子节点的非叶子节点拥有 k − 1 个键。
- 所有的叶子节点都在同一层。
这5个属性都是为了维持B树的平衡。其中前5个是在 度 被定义后就可以控制的,而第6个是源于B树新增数据的方式,稍后会做解释。
B树中数据的有序性#
- 每个 节点 中的 Item 按 Key 有序排列(规则可以是自定义的)。
- 升序排序时,每个 Item 左子树 中的 Item 的 Key 均小于当前 Item 的 Key。
- 升序排序时,每个 Item 右子树 中的 Item 的 Key 均大于当前 Item 的 Key。
用C#定义数据结构
开始算法讲解前,我们需要先定义下将会用到的数据结构。
虽然代码太多可能影响阅读体验,但考虑到 gayhub 可能访问不稳定,还是尽量贴全了。
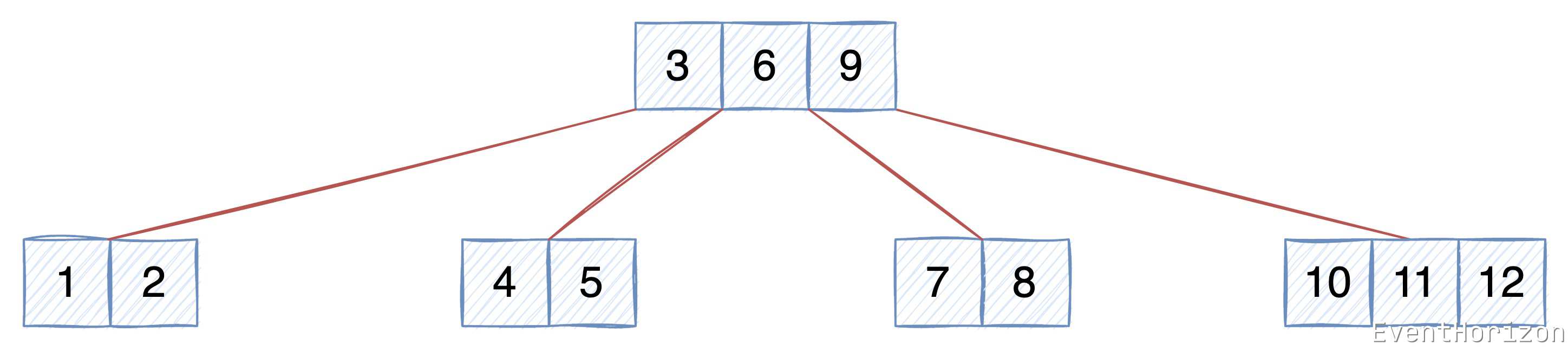
下图所示是一个 degree 是 3 的 B树,Key 按升序排序。
internal class Item<TKey, TValue>
{
#region Constructors
public Item(TKey key, TValue? value)
{
Key = key;
Value = value;
}
#endregion
#region Properties
public TKey Key { get; }
public TValue? Value { get; set; }
#endregion
}
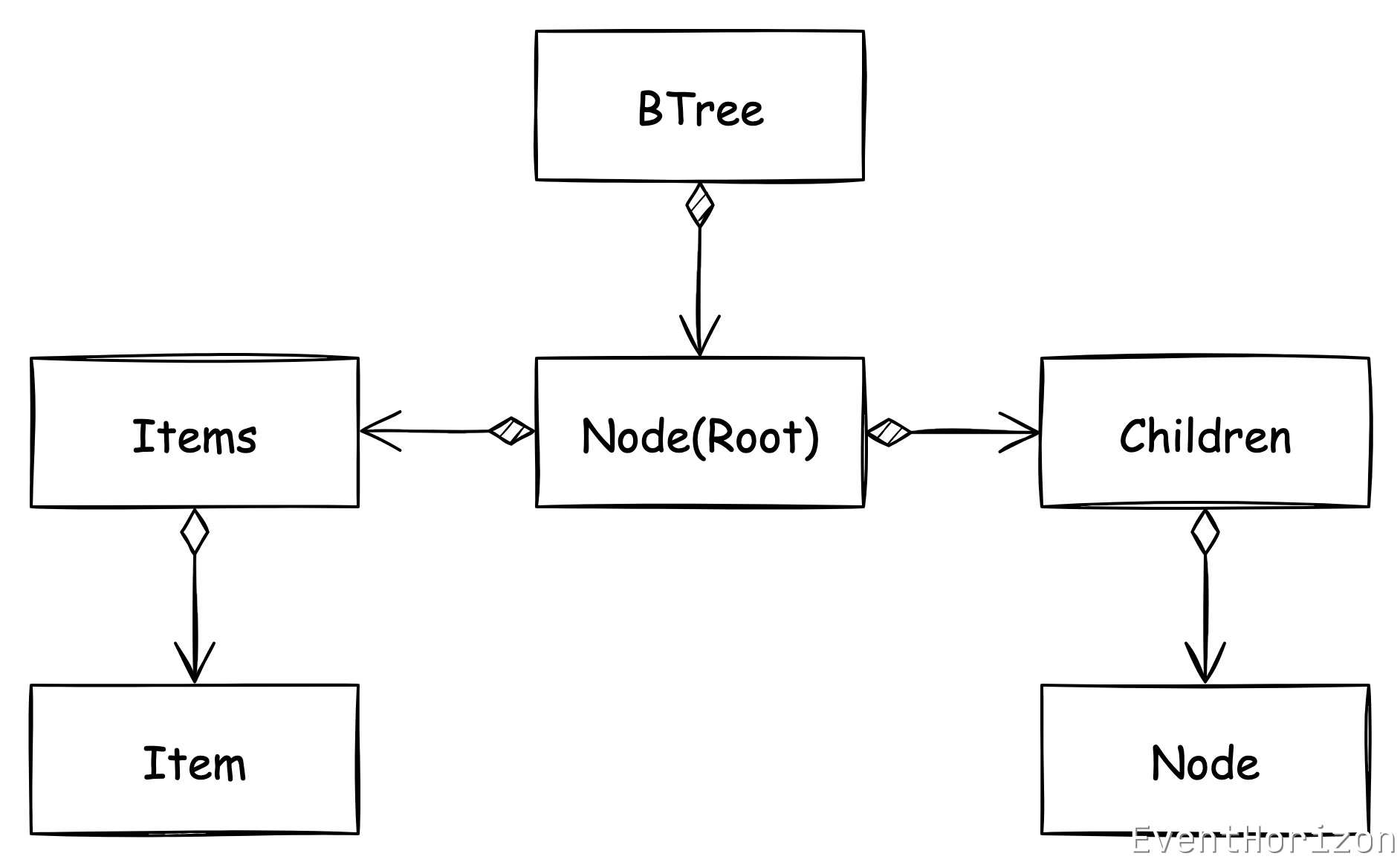
定义 Items 和 Children 两个类型分别用于存储 Item 集合和子节点集合。为了简化设计以及减少动态扩容带来的性能损失,作为数据实际容器的数组在第一开始就会按最大的 capacity 进行创建。同时也预先给 Items 和 Children 定义好后面会被用到的基本方法。
internal class Items<TKey, TValue>
{
#region Fields
private readonly Item<TKey, TValue?>?[] _items;
private readonly int _capacity;
private readonly IComparer<TKey> _comparer;
private int _count;
#endregion
#region Constructors
public Items(int capacity, IComparer<TKey> comparer)
{
_capacity = capacity;
_items = new Item<TKey, TValue?>[capacity];
_comparer = comparer;
}
#region Properties
public int Count => _count;
#endregion
#region Indexers
public Item<TKey, TValue?> this[int index]
{
get
{
if (index < 0 || index >= _count)
{
throw new IndexOutOfRangeException();
}
return _items[index]!;
}
set => _items[index] = value;
}
#endregion
#endregion
#region Public Methods
/// <summary>
/// 查找指定的键,并返回它的索引,如果找不到则返回key可以插入的位置
/// </summary>
/// <param name="key">指定的key</param>
/// <param name="index">key的索引或者其可以插入的位置</param>
/// <returns>指定的key是否存在</returns>
public bool TryFindKey(TKey key, out int index)
{
if (_count == 0)
{
index = 0;
return false;
}
// 二分查找
int left = 0;
int right = _count - 1;
while (left <= right)
{
int middle = (left + right) / 2;
var compareResult = _comparer.Compare(key, _items[middle]!.Key);
if (compareResult == 0)
{
index = middle;
return true;
}
if (compareResult < 0)
{
right = middle - 1;
}
else
{
left = middle + 1;
}
}
index = left;
return false;
}
public void InsertAt(int index, Item<TKey, TValue?> item)
{
if (_count == _capacity)
throw new InvalidOperationException("Cannot insert into a full list.");
if (index < _count)
Array.Copy(_items, index, _items, index + 1, _count - index);
_items[index] = item;
_count++;
}
public void Add(Item<TKey, TValue?> item) => InsertAt(_count, item);
public void AddRange(Items<TKey, TValue?> items)
{
if (_count + items.Count > _capacity)
throw new InvalidOperationException("Cannot add items to a full list.");
Array.Copy(items._items, 0, _items, _count, items.Count);
_count += items.Count;
}
public Item<TKey, TValue?> RemoveAt(int index)
{
if (index >= _count)
throw new ArgumentOutOfRangeException(nameof(index));
var item = _items[index];
if (index < _count - 1)
Array.Copy(_items, index + 1, _items, index, _count - index - 1);
_items[_count - 1] = null;
_count--;
return item!;
}
public Item<TKey, TValue?> RemoveLast() => RemoveAt(_count - 1);
public void Truncate(int index)
{
if (index >= _count)
throw new ArgumentOutOfRangeException(nameof(index));
for (int i = index; i < _count; i++)
{
_items[i] = null;
}
_count = index;
}
#endregion
}
internal class Children<TKey, TValue>
{
#region Fields
private readonly Node<TKey, TValue?>?[] _children;
private readonly int _capacity;
private int _count;
#endregion
#region Constructors
public Children(int capacity)
{
_capacity = capacity;
_children = new Node<TKey, TValue?>[_capacity];
}
#endregion
#region Properties
public int Count => _count;
#endregion
#region Indexers
public Node<TKey, TValue?> this[int index]
{
get
{
if (index < 0 || index >= _count)
{
throw new IndexOutOfRangeException();
}
return _children[index]!;
}
}
#endregion
#region Public Methods
public void InsertAt(int index, Node<TKey, TValue?> child)
{
if (_count == _capacity)
throw new InvalidOperationException("Cannot insert into a full list.");
if (index < _count)
Array.Copy(_children, index, _children, index + 1, _count - index);
_children[index] = child;
_count++;
}
public void Add(Node<TKey, TValue?> child) => InsertAt(_count, child);
public void AddRange(Children<TKey, TValue?> children)
{
if (_count + children.Count > _capacity)
throw new InvalidOperationException("Cannot add to a full list.");
Array.Copy(children._children, 0, _children, _count, children.Count);
_count += children.Count;
}
public Node<TKey, TValue?> RemoveAt(int index)
{
if (index >= _count)
throw new ArgumentOutOfRangeException(nameof(index));
var child = _children[index];
if (index < _count - 1)
Array.Copy(_children, index + 1, _children, index, _count - index - 1);
_children[_count - 1] = null;
_count--;
return child!;
}
public Node<TKey, TValue?> RemoveLast() => RemoveAt(_count - 1);
public void Truncate(int index)
{
if (index >= _count)
throw new ArgumentOutOfRangeException(nameof(index));
for (var i = index; i < _count; i++)
_children[i] = null;
_count = index;
}
#endregion
}
用 Node 来表示每个节点,支持传入 Comparer 用于实现自定义的排序方式。
internal class Node<TKey, TValue>
{
#region Fields
private readonly IComparer<TKey> _comparer;
private readonly int _degree;
private readonly int _minItems;
private readonly int _maxItems;
private readonly int _maxChildren;
private readonly Items<TKey, TValue?> _items;
private readonly Children<TKey, TValue?> _children;
#endregion
#region Constructors
public Node(int degree, IComparer<TKey> comparer)
{
_degree = degree;
_comparer = comparer;
_minItems = degree - 1;
_maxItems = 2 * degree - 1;
_maxChildren = 2 * degree;
_items = new Items<TKey, TValue?>(_maxItems, _comparer);
_children = new Children<TKey, TValue?>(_maxChildren);
}
#endregion
#region Properties
public int ItemsCount => _items.Count;
public int ChildrenCount => _children.Count;
public bool IsItemsFull => ItemsCount == _maxItems;
public bool IsItemsEmpty => ItemsCount == 0;
public bool IsLeaf => ChildrenCount == 0;
#endregion
// ...
}
public sealed class BTree<TKey, TValue> : IEnumerable<KeyValuePair<TKey, TValue?>>
{
#region Fields
private readonly int _degree;
private readonly IComparer<TKey> _comparer;
private int _count;
private Node<TKey, TValue?>? _root;
#endregion
#region Constructors
public BTree(int degree) : this(degree, Comparer<TKey>.Default)
{
}
public BTree(int degree, IComparer<TKey> comparer)
{
if (degree < 2)
{
throw new ArgumentOutOfRangeException(nameof(degree), "Degree must be at least 2.");
}
ArgumentNullException.ThrowIfNull(comparer);
_degree = degree;
_comparer = comparer;
}
#endregion
#region Properties
public int Count => _count;
public int Degree => _degree;
public IComparer<TKey> Comparer => _comparer;
#endregion
// ...
}
插入数据的过程
先重复一下上文提到的B树的顺序特性:
- 每个 节点 中的 Item 按 Key 有序排列(规则可以是自定义的)。
- 升序排序时,每个 Item 左子树 中的 Item 的 Key 均小于当前 Item 的 Key。
- 升序排序时,每个 Item 右子树 中的 Item 的 Key 均大于当前 Item 的 Key。
插入数据的过程就是在树中找到合适的位置插入数据,同时保证树的顺序特性不变。
寻找位置的过程是递归的,从根节点开始,如果当前节点是叶子节点,那么就在当前节点中插入数据;如果当前节点不是叶子节点,那么就根据当前节点中的 Item 的 Key 和要插入的数据的 Key 的大小关系,决定是向左子树还是右子树继续寻找合适的位置。
以下面这个图例来说明插入数据的过程:
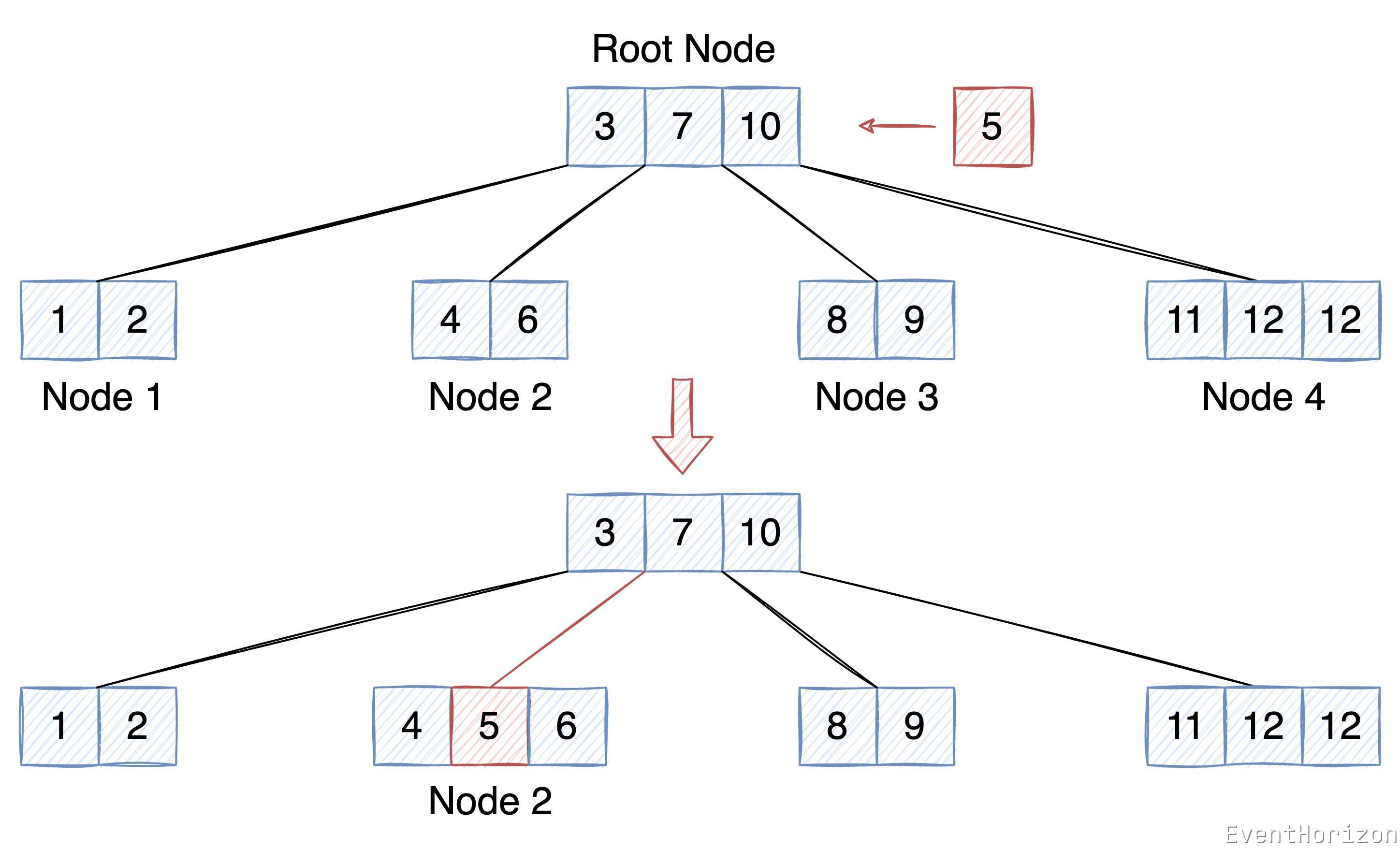
- 在 根节点 中,借助 二分查找法 找到 5 的位置应该在 3 和 7 之间,因为根节点不是叶子节点,所以不能在根节点直接插入,继续在 Node 2 中寻找合适的位置。Node 2 是 3 的右子树,7 的左子树,其中的 Key 都大于 3,小于 7。
- Node 2 是叶子节点,所以可以在 Node 2 中插入 5。按二分查找法找到 5 的位置应该在 4 和 6 之间,所以插入数据后 Node 2 中的 Item 应该是这样的:
[4, 5, 6]。
分裂:新节点诞生的唯一方式
上文提到单个节点最多只能有 2t-1 个 Item,如果节点已经满了,还有新 Item 需要插入的话,节点就需要进行分裂。
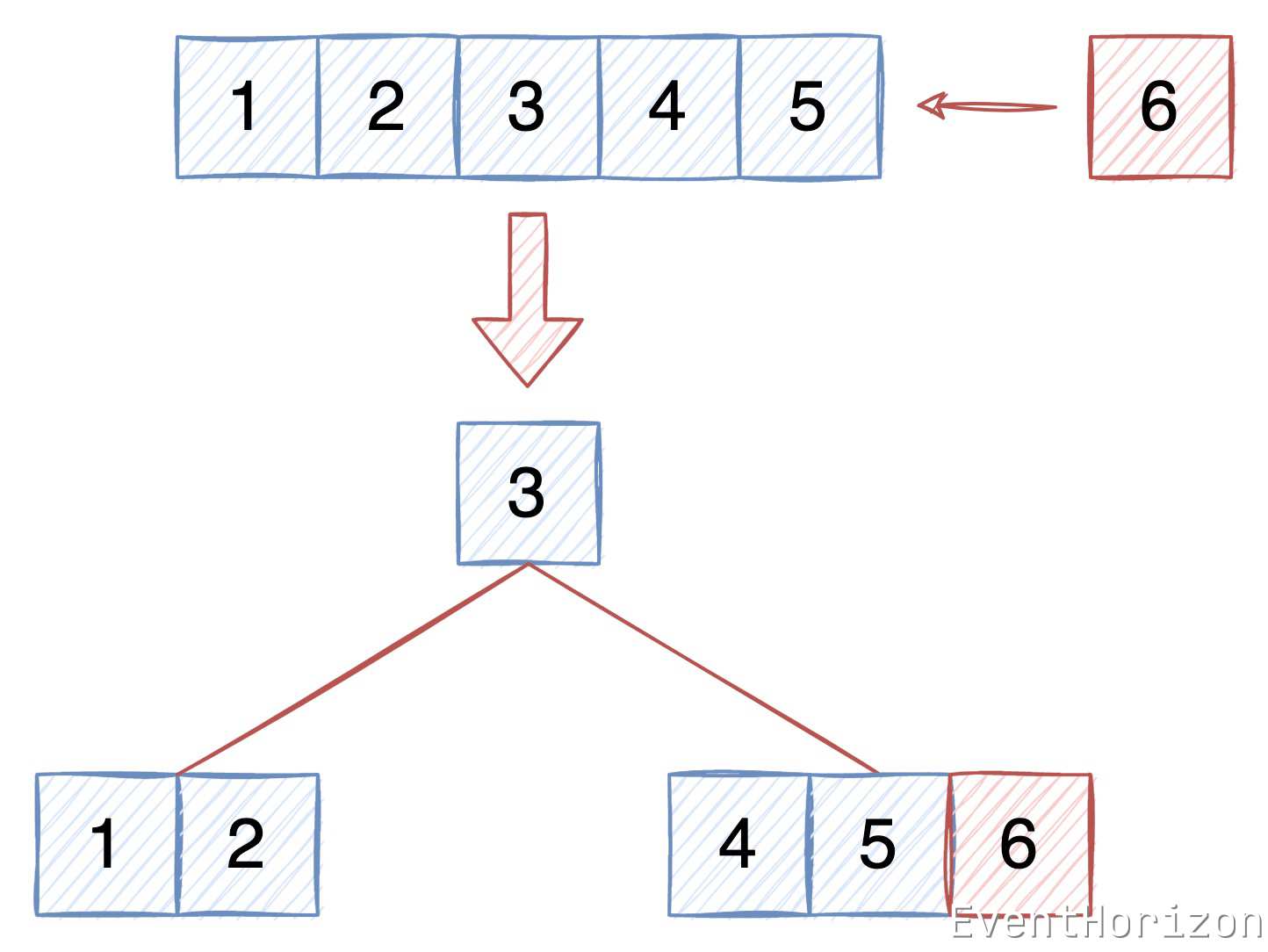
根节点的分裂#
如果根节点满了(Item的数量达到2t-1),有需要插入新 Item 的话,就需要对根节点进行分裂,分裂后的根节点会有两个子节点,分别是原来的根节点和新的节点。
分裂分为以下几个步骤(不一定要按这个顺序):
- 创建一个新的节点,作为新的根节点。
- 将原根节点作为新根节点的第一个子节点。
- 将原根节点中间(索引记为mid)的 Item 移动到新的根节点中,作为新根节点的第一个 Item。
- 创建一个新的节点。
- 将原根节点中间 Item 右边的 Item(mid+1开始)移动到新节点中。
- 将原根节点中间 Item 右边的 子节点(mid+1开始)移动到新节点中。
- 将新节点作为新根节点的第二个子节点。
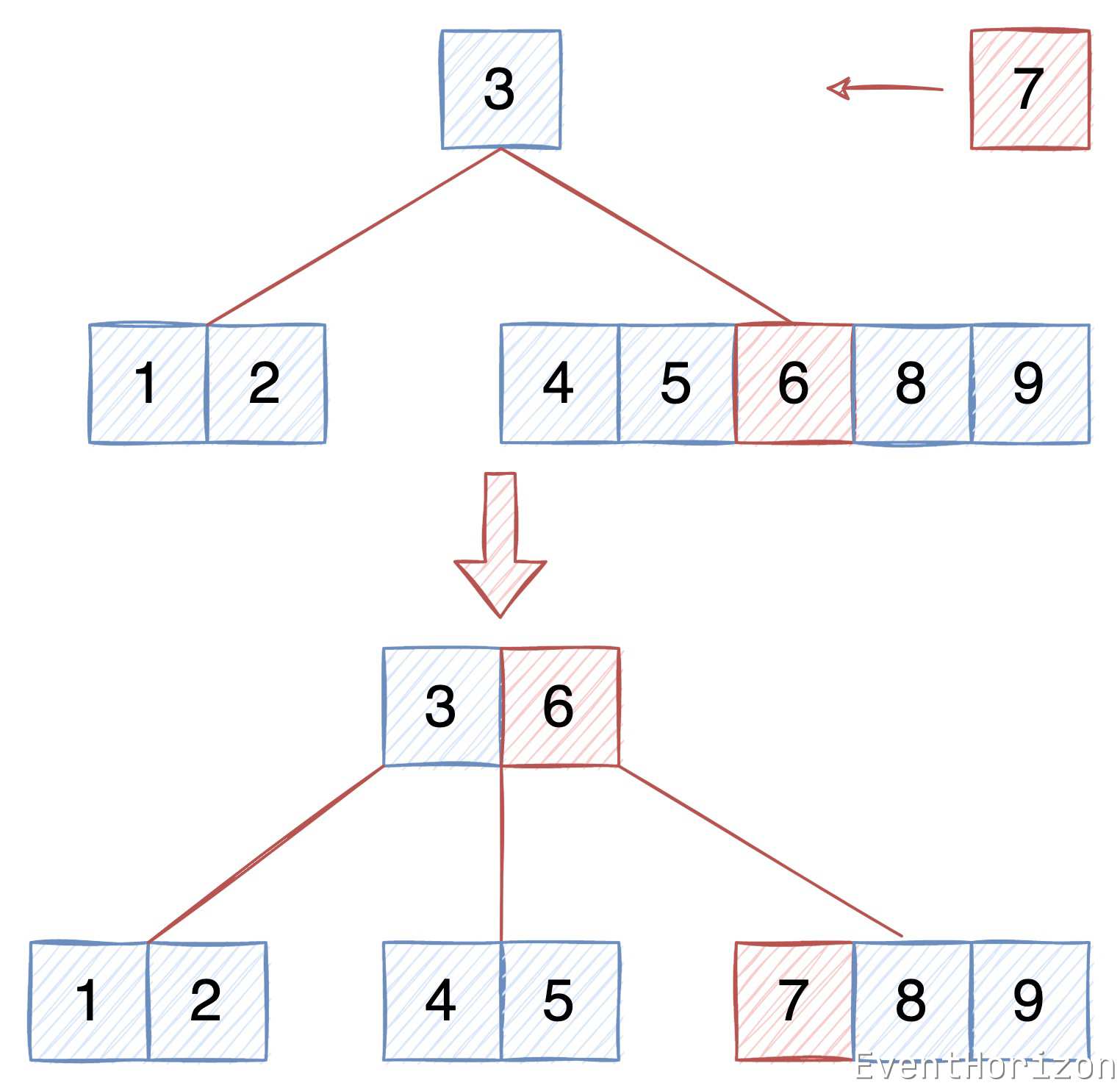
非根节点的分裂#
假设当前节点是父节点的第 k 个子节点,也就是父节点 Items[k](用PItems代指) 的左子节点,或者说是PItems[k-1] 的右子节点。当前节点中所有 Item 的 Key 都在 (PItems[k-1], PItems[k])区间内。
分裂分为以下几个步骤:
- 将中间(索引记为mid)的 Item (记作MItem)提升到父节点中,插入 PItems[k],原来的 PItems[k] 移动至 PItems[k+1],父节点中的 Item 依然保持有序。
- 创建新的节点。
- 将右半部分(mid+1开始)的 Item 移至新节点。
- 将右半部分(mid+1开始)的 子节点 移至新节点。
- 将新的节点 插入父节点的子节点的第 k+1 个位置,也就是作为刚改过位置的 MItem 的右子节点,MItem 的 Key 小于 其右子树中所有 Item,顺序性也不会遭到破坏。
新插入的 Item 会根据 Key 的大小,插入到分裂后的左节点或者右节点中。
下图所示B树 degree 为 3,每个 Node 最多有 5(2*3-1)个 Item,在[4,5,6,8,9]所在节点插入 7 需先进行分裂。6 将被提升到根节点中,原来的 6 所在节点将被分裂成两个节点,7 会被插入到右侧的新节点中。
分裂导致树的高度增加#
节点在分裂的时候,如果父节点已经满了,那么父节点也需要分裂,这样就会导致父节点的父节点也需要分裂,以此类推,直到根节点。
而根节点的分裂,会导致树的高度增加。
新 Item 的插入是发生在叶子节点的,分裂也是从叶子节点开始。如果一个节点一开始是叶子节点,随着数据的增加,它始终都是叶子节点,叶子节点分裂后,新的叶子节点也是同一高度的。
这其实解答了上文提到的问题:为什么B树的叶子节点都在同一层。
提前分裂#
B树中数据的插入过程,是一个从根节点不断 向下 寻找合适叶子节点的过程。
而分裂是一个从叶子节点不断 向上 的过程。
因此分裂算法的实际实现中,为了避免回溯性分裂(磁盘存储中,回溯带来的 overhead 很大),一般会在 向下 寻找的过程中提前去分裂已经满了的节点。
插入算法实现
在插入新 Item 的过程中,BTree 本质上只是一个入口,大部分的逻辑都是和 节点 相关的,因此我们会把主要的逻辑定义在 节点 中。
Key 已存在时的处理策略#
新插入的 Item 的 Key 可能已经存在了,针对已经存在的 Key 的处理方式,这边参考 Dictionary 的处理方式:
- 通过 Indexer 插入数据时新 Value 覆盖旧 Value。
- 通过 Add 插入数据时扔出异常。
- 通过 TryAdd 插入数据时不作任何处理。
对应枚举如下:
internal enum InsertionBehavior
{
/// <summary>
/// 默认操作,如果 key 已经存在,则不会更新 value
/// </summary>
None = 0,
/// <summary>
/// 如果 key 已经存在,则更新 value
/// </summary>
OverwriteExisting = 1,
/// <summary>
/// 如果 key 已经存在,则抛出异常
/// </summary>
ThrowOnExisting = 2
}
并定义对应的处理结果枚举
internal enum InsertionResult
{
None = 0,
Added = 1,
Updated = 2,
}
public sealed class BTree<TKey, TValue> : IEnumerable<KeyValuePair<TKey, TValue?>>
{
#region Indexers
public TValue? this[[NotNull] TKey key]
{
get
{
if (TryGetValue(key, out var value))
{
return value;
}
throw new KeyNotFoundException();
}
set => TryInsert(key, value, InsertionBehavior.OverwriteExisting);
}
#endregion
#region Public Methods
/// <summary>
/// 往B树中添加一个键值对
/// </summary>
/// <param name="key">要添加的元素的key</param>
/// <param name="value">要添加的元素的value</param>
/// <exception cref="ArgumentNullException">key是null</exception>
/// <exception cref="ArgumentException">key已经存在</exception>
public void Add([NotNull] TKey key, TValue? value) =>
TryInsert(key, value, InsertionBehavior.ThrowOnExisting);
/// <summary>
/// 尝试往B树中添加一个键值对
/// </summary>
/// <param name="key">要添加的元素的key</param>
/// <param name="value">要添加的元素的value</param>
/// <returns>true:添加成功;false:添加失败</returns>
public bool TryAdd([NotNull] TKey key, TValue? value) =>
TryInsert(key, value, InsertionBehavior.None);
#endregion
}
插入算法#
在 Node 中 定义分裂和判断是否要提前分裂的方法
internal class Node<TKey, TValue>
{
/// <summary>
/// 将当前<see cref="Node{TKey,TValue}"/>分裂成两个<see cref="Node{TKey,TValue}"/>。
/// </summary>
/// <returns>中间位置的<see cref="Item{TKey,TValue}"/>和分裂后的第二个<see cref="Node{TKey,TValue}"/></returns>
public (Item<TKey, TValue?> MiddleItem, Node<TKey, TValue?> SecnodNode) Split()
{
int middleIndex = ItemsCount / 2;
var middleItem = _items[middleIndex];
var secondNode = new Node<TKey, TValue?>(_degree, _comparer);
// 将中间位置后的所有Item移动到新的Node中
for (int i = middleIndex + 1; i < ItemsCount; i++)
{
secondNode._items.Add(_items[i]);
}
_items.Truncate(middleIndex);
if (!IsLeaf)
{
// 将中间位置后的所有子节点移动到新的Node中
for (int i = middleIndex + 1; i < ChildrenCount; i++)
{
secondNode._children.Add(_children[i]);
}
_children.Truncate(middleIndex + 1);
}
return (middleItem, secondNode);
}
/// <summary>
/// 如果指定的子节点已满,则将其分裂为两个子节点,并将中间的 <see cref="Item{TKey,TValue}"/>> 插入到当前节点中。
/// </summary>
/// <param name="childIndex">指定的子节点的索引</param>
/// <returns>True 表示已经分裂了子节点,False 表示没有分裂子节点</returns>
private bool MaybeSplitChildren(int childIndex)
{
var childNode = _children[childIndex];
if (childNode.IsItemsFull)
{
var (middleItem, secondNode) = childNode.Split();
_items.InsertAt(childIndex, middleItem);
// 将新node插入到当前node的children中
_children.InsertAt(childIndex + 1, secondNode);
return true;
}
return false;
}
}
在 BTree 中定义插入方法
public sealed class BTree<TKey, TValue>
private bool TryInsert([NotNull] TKey key, TValue? value, InsertionBehavior behavior)
{
ArgumentNullException.ThrowIfNull(key);
if (_root == null)
{
_root = new Node<TKey, TValue?>(_degree, _comparer);
_root.Add(new Item<TKey, TValue?>(key, value));
_count++;
return true;
}
if (_root.IsItemsFull)
{
// 根节点已满,需要分裂
var (middleItem, secondNode) = _root.Split();
var oldRoot = _root;
_root = new Node<TKey, TValue?>(_degree, _comparer);
// 将原来根节点中间的元素添加到新的根节点
_root.Add(middleItem);
// 将原来根节点分裂出来的节点添加到新的根节点
_root.AddChild(oldRoot);
_root.AddChild(secondNode);
}
// 从根节点开始插入,如果插入的 Key 已经存在,会按照 behavior 的值进行处理
var insertionResult = _root.TryInsert(key, value, behavior);
if (insertionResult == InsertionResult.Added) _count++;
return insertionResult != InsertionResult.None;
}
}
在 Node 中定义插入方法,递归调用直至找到叶子节点,然后在叶子节点中插入
internal class Node<TKey, TValue>
{
public InsertionResult TryInsert(TKey key, TValue? value, InsertionBehavior behavior)
{
// 如果当前key已经存在, 根据插入行为决定是否替换
if (_items.TryFindKey(key, out int index))
{
switch (behavior)
{
case InsertionBehavior.OverwriteExisting:
_items[index].Value = value;
return InsertionResult.Updated;
case InsertionBehavior.ThrowOnExisting:
throw new ArgumentException($"An item with the same key has already been added. Key: {key}");
default:
return InsertionResult.None;
}
}
// 如果当前节点是叶子节点,则直接插入
if (IsLeaf)
{
// index 是新的 item 应该插入的位置,items 按顺序排列
_items.InsertAt(index, new Item<TKey, TValue?>(key, value));
return InsertionResult.Added;
}
// 如果当前节点的子节点已经满了,则需要分裂
// 如果当前节点的子节点没有满,则不需要分裂
// 如果当前节点的子节点分裂了,则需要判断当前key是否大于分裂后的中间key
// 如果当前key大于分裂后的中间key,则需要向右边的子节点插入
// 如果当前key小于分裂后的中间key,则需要向左边的子节点插入
// index 是新的 item 应该插入的位置,如果当做children的索引,则代表应该插入的位置的右边的子节点
if (MaybeSplitChildren(index))
{
// rightmostItem 是子节点分裂后的中间的 item,被提升到当前节点的 items 中的最后一个位置了
var middleItemOfChild = _items[index];
switch (_comparer.Compare(key, middleItemOfChild.Key))
{
case > 0:
// 如果当前key大于分裂后的中间key,则需要向右边的子节点插入
index++;
break;
case < 0:
// 如果当前key小于分裂后的中间key,则需要向左边的子节点插入
break;
default:
// 如果当前key等于分裂后的中间key,根据插入行为决定是否替换
switch (behavior)
{
case InsertionBehavior.OverwriteExisting:
middleItemOfChild.Value = value;
return InsertionResult.Updated;
case InsertionBehavior.ThrowOnExisting:
throw new ArgumentException(
$"An item with the same key has already been added. Key: {key}");
default:
return InsertionResult.None;
}
}
}
// 往子节点插入
return _children[index].TryInsert(key, value, behavior);
}
}
总结
B树中的数据是按照顺序存储的,所以可以使用二分查找法来查找数据,时间复杂度为 O(log n)。
往B树插入数据的过程是一个寻找合适的叶子节点的过程,然后在叶子节点中插入数据,时间复杂度为 O(log n)。
B树的节点中存储的数据量是有限的,所以在插入数据时,可能会发生节点分裂,这样就会导致树的高度增加,所以在插入数据时,需要判断是否需要分裂,如果需要分裂,就需要将中间的数据提升到父节点中,以此类推,直到根节点,如果根节点也需要分裂,就需要新建一个根节点,然后将原来的根节点和分裂出来的节点作为新的根节点的子节点。
参考资料
渴望力量系列 《算法导论第三版》
欢迎关注个人微信公众号 EventHorizonCLI ,最新的原创技术文章将在优先这里发布。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)