
解析ASPX网页__doPostBack分页的网页table数据
由于急于上线的功能要去客服系统里抓取数据进行验证,客服方面又没有时间开发EDI接口给到我,所以用了本办法:爬人家web系统上的数据进行分析。
由于客服的web系统用ASP.Net的__doPostBack控件进行数据分页。__doPostBack是通过__EVENTTARGET,__EVENTARGUMENT两个隐藏控件向服务端发送控制信息的。
这里我要分析的页面概况如下:
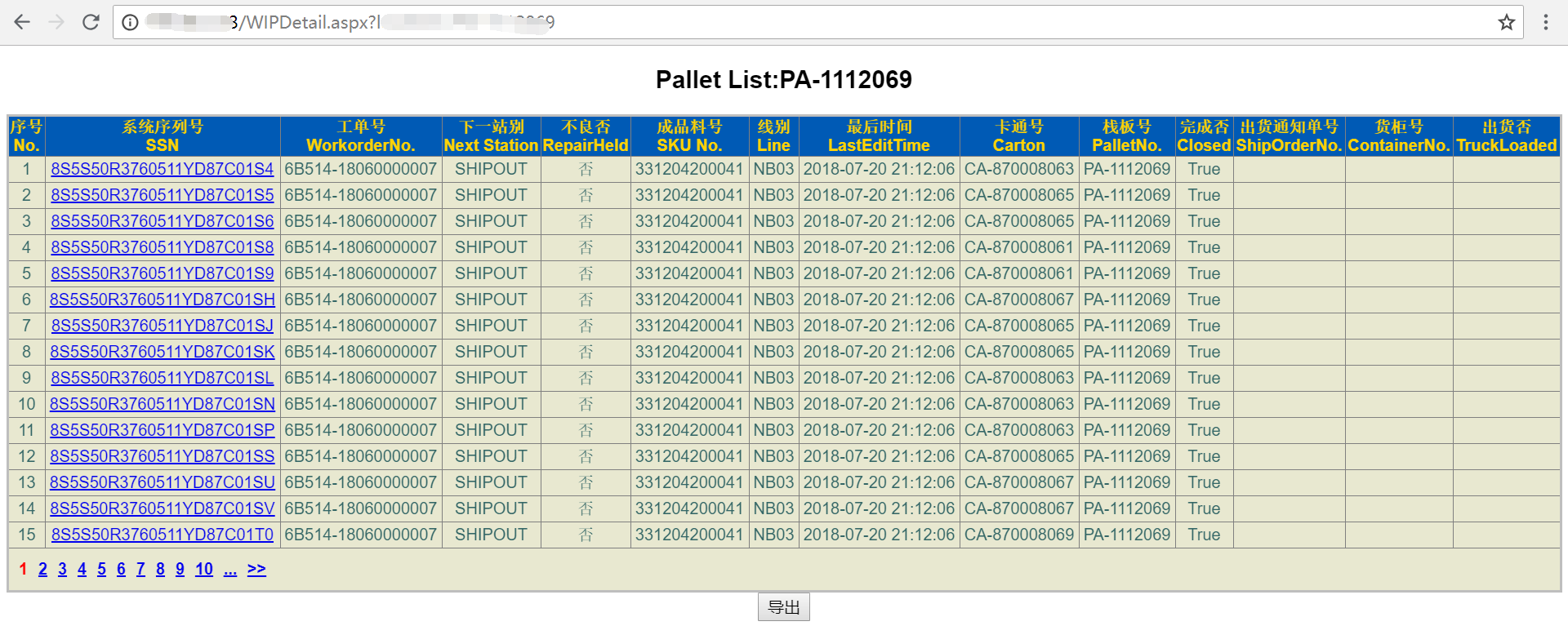
这里有个导出按钮,直接模拟导出按钮获取数据。模拟点击页面来获取我们要解析需要的参数:__VIEWSTATE、__EVENTVALIDATION
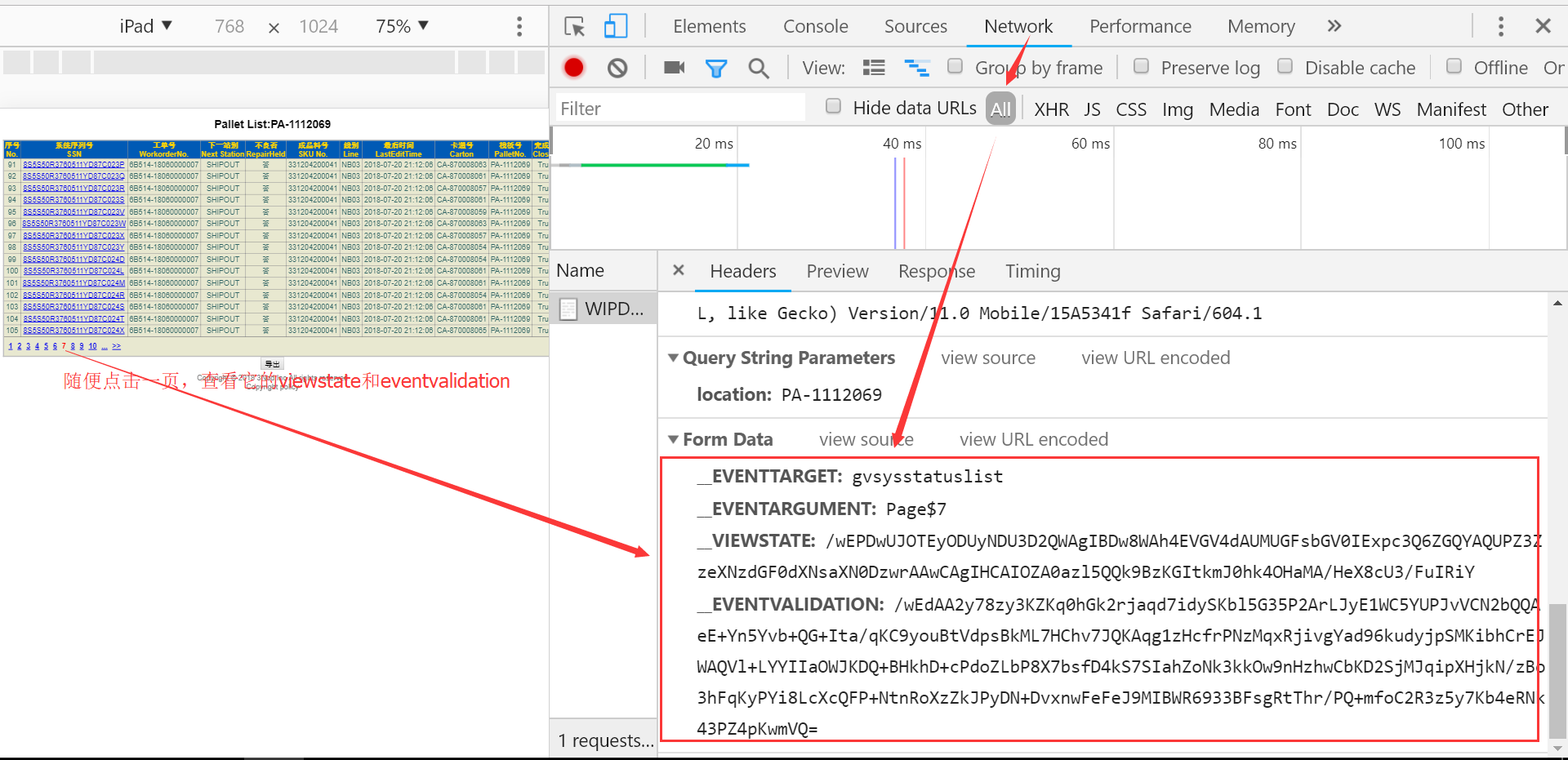
设计一个demo
private void button1_Click(object sender, EventArgs e) { string strViewState = System.Web.HttpUtility.UrlEncode("/wEPDwUJOTEyODUyNDU3D2QWAgIBDw8WAh4EVGV4dAUMUGFsbGV0IExpc3Q6ZGQYAQUPZ3ZzeXNzdGF0dXNsaXN0DzwrAAwBCAIOZOMeKZkMrWymOLPLpoGaeUA09JXcMmBeiapHUaN/Gi/F"); string strEventValidation = System.Web.HttpUtility.UrlEncode("/wEdAA0xoT8jJS8wSLBSnnngxJ11LlhQ8m9UI3ZtBAB4T5ifli9v5Ab4i1r+ooL3Ki4G1V2mwGQwvscKG/slAoCqDXMdx+s83MyrFGOK+Bhp33qS53KOlIwqJuEKsQlYBBWX4thggho5YkoND4EeSEP5w92hCXHcK3jw5s4JUgUUp9F6PJLbP8X7bsfD4kS7SIahZoNk3kkOw9nHzhwCbKD2SjMJqipXHjkN/zBo3hFqKyPYi8LcXcQFP+NtnRoXzZkJPyDN+DvxnwFeFeJ9MIBWR693WMHe4rn0nQ4UPheoLGOgfsnsDvJMKKjfZWVoPlnQzPA="); StringBuilder url = new StringBuilder(); url.Append("&__VIEWSTATE=" + strViewState); url.Append("&__EVENTVALIDATION=" + strEventValidation); url.Append("&Button1=导出"); byte[] data = System.Text.Encoding.ASCII.GetBytes(url.ToString()); Uri uri = new Uri(textBox1.Text.ToString()); System.Net.HttpWebRequest request = (System.Net.HttpWebRequest)System.Net.WebRequest.Create(uri); request.Method = "post"; request.ContentType = "application/x-www-form-urlencoded"; //request.ContentType = "application/json"; request.ContentLength = data.Length; Stream requestStream = request.GetRequestStream(); requestStream.Write(data, 0, data.Length); requestStream.Close(); System.Net.HttpWebResponse response = (System.Net.HttpWebResponse)request.GetResponse(); Stream responseStream = response.GetResponseStream(); StreamReader readStream = new StreamReader(responseStream, System.Text.Encoding.Default); string html = readStream.ReadToEnd().ToString(); readStream.Close(); var strReg = @"<table[^>]*>[\s\S]*</table>"; List<string> result = new List<string>(); MatchCollection mc = Regex.Matches(html, strReg); DataTable dt = new DataTable(); dt.Columns.Add("ID", typeof(string)); //序号 dt.Columns.Add("SN", typeof(string)); //系统序列号 dt.Columns.Add("WO", typeof(string)); //工单号 dt.Columns.Add("NextStation", typeof(string)); //下一站别 dt.Columns.Add("RepairHeld", typeof(string)); //不良否 dt.Columns.Add("SKUNo", typeof(string)); //成品料号 dt.Columns.Add("Line", typeof(string)); //线别 dt.Columns.Add("LastEditTime", typeof(string)); //最后时间 dt.Columns.Add("Carton", typeof(string)); //卡通号 dt.Columns.Add("PalletNo", typeof(string)); //栈板号 dt.Columns.Add("Closed", typeof(string)); //完成否 dt.Columns.Add("ShipOrderNo", typeof(string)); //出货通知单号 dt.Columns.Add("ContainerNo", typeof(string)); //货柜号 dt.Columns.Add("TruckLoaded", typeof(string)); //出货否 string strhead = string.Empty; Match m = mc[0]; int rowindex = 1; foreach (Match mtr in Regex.Matches(m.Value, "(?is)(?<=<tr>).+?(?=</tr>)")) { if (rowindex == 1) { rowindex++; continue; } DataRow dr = dt.NewRow(); MatchCollection tds = Regex.Matches(mtr.Value, "(?is)(?<=<td>).+?(?=</td>)"); MatchCollection tds2 = Regex.Matches(mtr.Value, "(?is)(?<=target=\"_blank\">).+?(?=</a></td>)"); MatchCollection tds6 = Regex.Matches(mtr.Value, "(?is)(?<=@\">).+?(?=</td>)"); MatchCollection ids = Regex.Matches(tds[0].Value, "(?is)(?<=\">).+?(?=</span>)"); dr["ID"] = FormatString(ids[0].Value); dr["SN"] = FormatString(tds2[0].Value); dr["WO"] = FormatString(tds[1].Value); dr["NextStation"] = FormatString(tds[2].Value); dr["RepairHeld"] = FormatString(tds[3].Value); dr["SKUNo"] = FormatString(tds6[1].Value); dr["Line"] = FormatString(tds[4].Value); dr["LastEditTime"] = FormatString(tds[5].Value); dr["Carton"] = FormatString(tds[6].Value); dr["PalletNo"] = FormatString(tds[7].Value); dr["Closed"] = FormatString(tds[8].Value); dr["ShipOrderNo"] = FormatString(tds[9].Value); dr["ContainerNo"] = FormatString(tds[10].Value); dr["TruckLoaded"] = FormatString(tds[11].Value); dt.Rows.Add(dr); rowindex++; } gridControl1.DataSource = dt; } /// <summary> /// 页面加载 /// </summary> /// <param name="sender"></param> /// <param name="e"></param> private void Form1_Load(object sender, EventArgs e) { this.textBox1.Text = @"http://172.16.1.13/WIPDetail.aspx?location=PA-1112069"; } private string FormatString(string str) { str = str.Replace("\r\n", "").Replace(" ", "").Trim(); return str; }
正则表达式分析解析出来的HTML文本即可。
其实针对上述既要分页又是隐藏控件分页的table不太好爬数据,如果解析不分页的table的话没那么复杂,可以直接获取整个页面的html元素然后进行解析
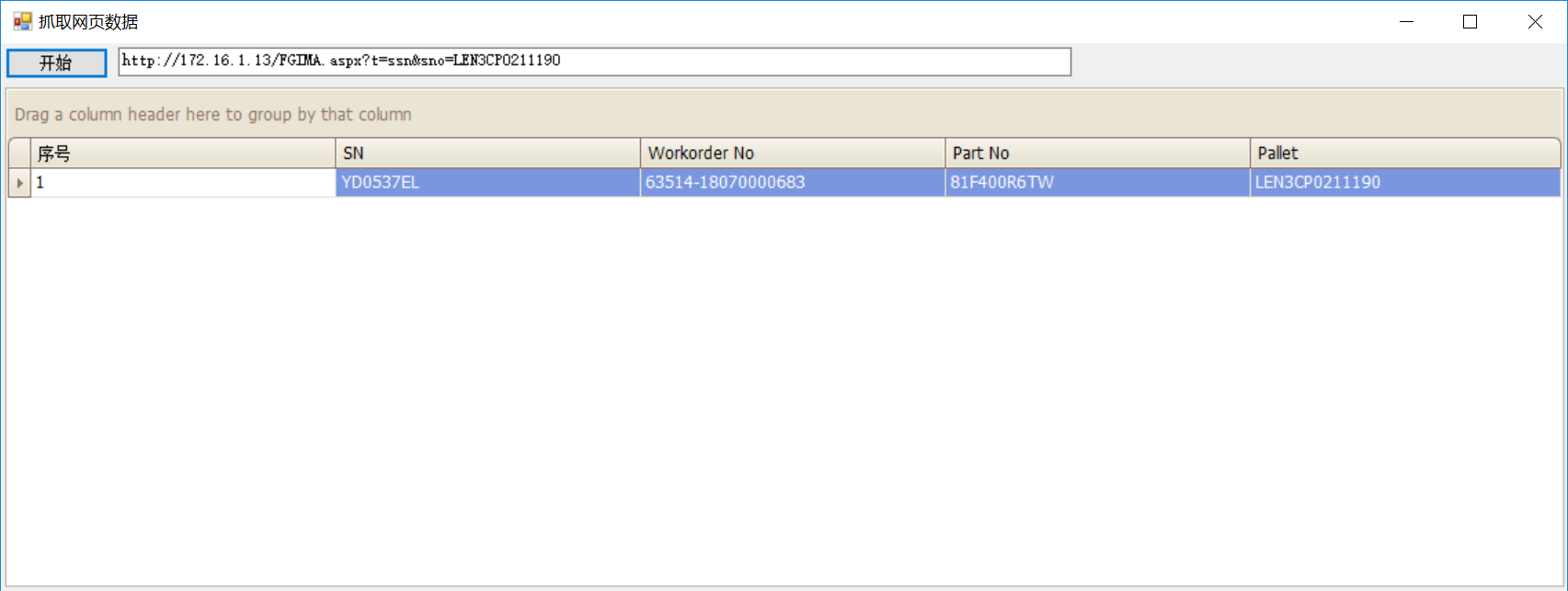
列如我需要知道如下页面的table表里面的数据:
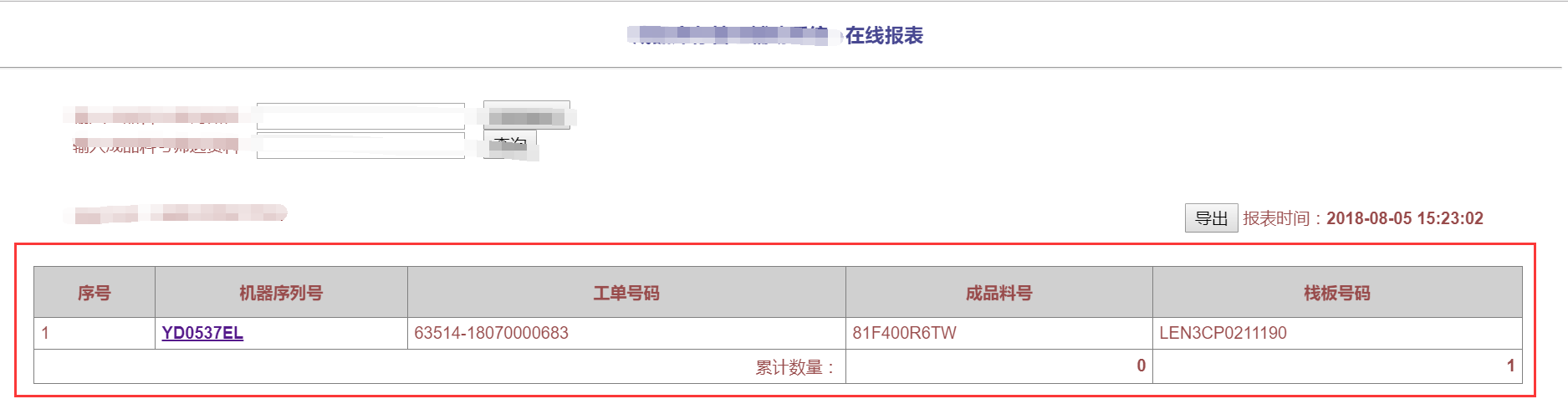
首先根据URL,WebRequest请求该页面,IO流读取整个页面的HTML元素,首先正则定位table,然后遍历这些元素,按照<tr>,<th>解析
WebRequest request = WebRequest.Create("http://172.16.1.13/FGIMA.aspx?t=ssn&sno=" + str_Pallet); WebResponse response = request.GetResponse(); StreamReader reader = new StreamReader(response.GetResponseStream(), Encoding.GetEncoding("utf-8")); var html = reader.ReadToEnd(); var strReg = @"(?is)(?<=<table>).+?(?=</table>)"; List<string> result = new List<string>(); MatchCollection mc = Regex.Matches(html, strReg); DataTable dt = new DataTable(); string strhead = string.Empty; foreach (Match m in mc) { int rowindex = 1; foreach (Match mtr in Regex.Matches(m.Value, "(?is)(?<=<tr>).+?(?=</tr>)")) { if (rowindex == 1) { strhead = mtr.Value; foreach (Match mtdh in Regex.Matches(mtr.Value, "(?is)(?<=<th>).+?(?=</th>)")) { if (!dt.Columns.Contains(mtdh.Value.Replace("\r\n", "").Trim())) { dt.Columns.Add(mtdh.Value.Replace("\r\n", "").Trim()); } } } else { DataRow dr = dt.NewRow(); if (mtr.Value.Contains("累计数量")) continue; if (mtr.Value.Contains("没有找到相关数据")) { return dt; } MatchCollection mtdds = Regex.Matches(mtr.Value, "(?is)(?<=<td>).+?(?=</td>)"); int colindex = 0; foreach (Match mtdh in Regex.Matches(strhead, "(?is)(?<=<th>).+?(?=</th>)")) { if (mtdh.Value.Contains("机器序列号")) { foreach (Match mtdhdd in Regex.Matches(mtr.Value, "(?is)(?<=target=\"_blank\">).+?(?=</a>)")) { dr["机器序列号"] = mtdhdd.Value.Replace("\r\n", "").Trim(); } } else dr[mtdh.Value.Replace("\r\n", "").Trim()] = mtdds[colindex].Value.Replace("\r\n", "").Trim(); colindex++; } dt.Rows.Add(dr); } rowindex++; } } if (dt.Columns.Contains("机器序列号")) { dt.Columns["机器序列号"].ColumnName = "SN"; } if (dt.Columns.Contains("工单号码")) { dt.Columns["工单号码"].ColumnName = "WorkorderNo"; } if (dt.Columns.Contains("成品料号")) { dt.Columns["成品料号"].ColumnName = "PartNo"; } if (dt.Columns.Contains("栈板号码")) { dt.Columns["栈板号码"].ColumnName = "Pallet"; } reader.Close(); reader.Dispose(); response.Close(); return dt;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号