
爬虫初试
1.下载谷歌浏览器
2.在谷歌浏览器内打开百度
3.打开百度的开发者工具:ctrl+shift+I
4.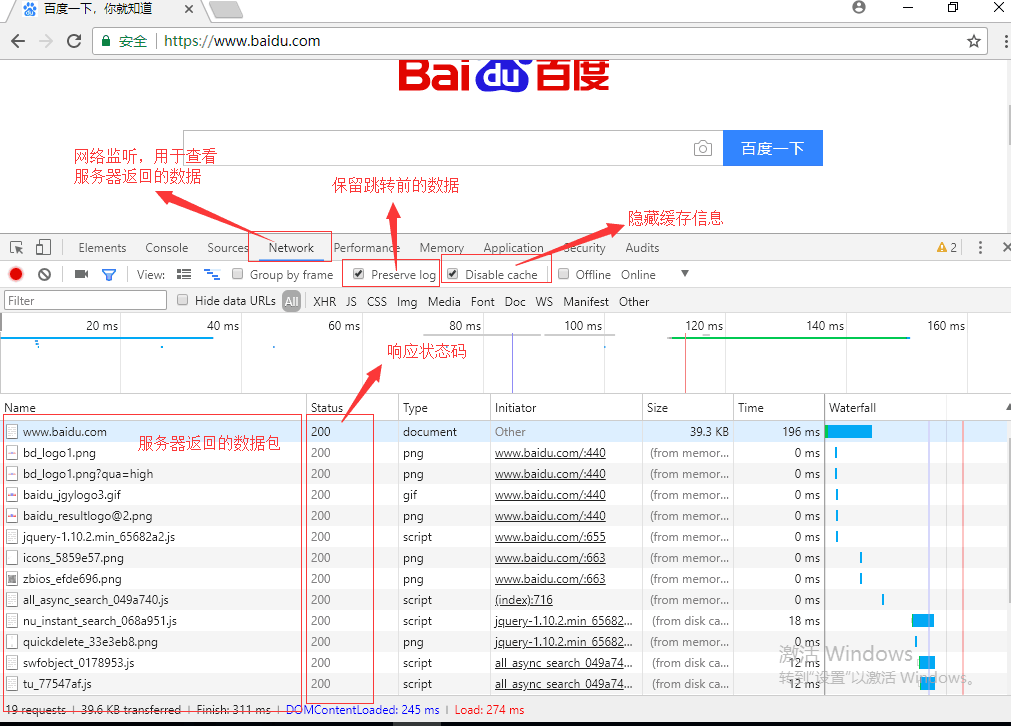
5.关注内容解释:
headers:
general内:
http 协议
请求url:https://www.baidu.com/
请求方式:get
响应状态码:
request headers :请求头部
cookie:缓存数据,用来保存用户的浏览信息)(如用于避免登录的,跳开登录验证)
user-Agent: 他是用来证明你是否是浏览器,
6. requests模块的使用
#pip install -i 清华源地址 模块名 ##可以改变下载源,从默认的国外网站到国内的想去的网址
#也可以永久修改
##修改sit-package ,下面的models 里面的index.py 修改里面的PyPI即可
import requests ##载入requests模块
以下代码用于保存当前打开的baidu的页面,并保存在对应文件中
import requests
response =requests.get(url='https://www.baidu.com/') #往百度发送请求
response.encoding='utf-8'
print(response) #返回对象<Response [200]>
print(response.status_code) #拥于返回响应状态码
print(response.text) #拥于返回响应文本,返回str类型
with open('baidu.html','w',encoding='utf-8') as f :
f.write(response.text)
7.网上爬取视频:
import requests
res = requests.get('https://video.pearvideo.com/mp4/adshort/20190613/cont-1565846-14013215_adpkg-ad_hd.mp4')
print(res.content)
with open ('aa.mp4','wb') as f:
f.write(res.content)
说明:获取视频源的办法:用谷歌浏览器打开梨视频,然后打开开发者模式,然后点开element ,然后选择相应的视频,然后点击工具中的箭头,然后点一下相关位置,然后对应的视频源就会出现。然后双击后即可复制。
https://www.cnblogs.com/kermitjam/p/10863913.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号