如何保障系统稳定?Grafana+Prometheus监控系统搭建
一个好的管理系统可以为服务的高可用、高并发提供重要的保障。以下我们将为大家介绍如何通过一套完备的监控系统,帮助我们快速解决问题,保障系统服务的稳定运行:
一、影响系统稳定性的常见问题及排查方案:
• 网络超时
这种情况有两种方式可以进行排查。
方式一:
查看反馈的那段时间内外部网络情况,比如查看运营商网络的PING监控和出口网络流量情况,确认是否出现网络抖动的情况;
继续查看Nginx网关监控的请求耗时情况与 access log 日志,确认服务接口是否存在不稳定的情况;
最后查看内部服务执行情况、服务的请求量、线程池队列大小以及是否存在慢日志,确定网络超时是否由业务请求量过大或者服务不够稳定造成的;
方式二:
通过网络抓包,分析抓包文件来排查网络超时原因。具体操作大家可以自行搜索wireshark教程。
• 业务请求失败
这种情况基本上是由客户触发了系统异常的业务逻辑所导致的,具体原因我们可以在日志监控系统中查看。在一定时间内推送系统中某个异常出现次数超过阈值,会触发日志监控系统的告警机制,系统会自动通知其开发人员去查看具体原因,并联系客户告知异常原因和解决方案。比如客户的出口IP发生变化,没有在我们开发者中心及时更新IP白名单,会导致客户的请求被系统拦截,返回请求失败结果。
• 消息下发延迟
这种情况的出现存在多种原因,一般情况下,我们排查的思路是首先通过查看全链路监控中哪个服务的耗时特别严重,再通过主机监控推送系统查看这个服务所在主机的CPU使用率是否过高,以此判断是否是某个线程异常引起的。接着,我们查看磁盘读写性能是否过低,是否存在主机内存剩余过低或者磁盘损坏的情况。最后,我们查看服务的old区监控,是否存在频繁的垃圾回收现象,以及是否存在服务内存溢出或服务线程异常情况,结合服务的dump和jstack文件,进一步分析排查具体的原因。
除了上述提到的内部系统监控,我们也会在第三方机房的环境下模拟客户行为,主动调用消息推送API接口,根据返回的结果,来监控推送系统的运行情况是否正常。当出现服务异常反馈时,我们会在第一时间告警并快速响应和处理,确保客户的业务不受影响。
由此可见,监控系统在保障推送系统的高并发和高可用中发挥了重要的作用。想要了解更多关于监控系统搭建的同学可以看下文的介绍,我们通过开源组件Prometheus、Grafana和docker容器,教大家快速搭建一套完善的监控系统。
二、落地方案
关于监控相关数据,这里以JMX的Metrics数据展示作为demo样例:
- 通过JMX Exporter第三方jar,demo以agent运行方式对外展示数据,方便Prometheus采集数据;
- 开源系统Prometheus采集并存储数据;
- 开源系统Grafana,以图表形式展现相关性能指标;
三、落地步骤
• 启动程序
java -javaagent:./jmx_prometheus_javaagent-0.12.0.jar=8085:config.yaml -jar demo.jar
• 运行Prometheus
1、配置prom-jmx.yml
scrape_configs:
-
job_name: 'java'
scrape_interval: 1mmetrics_path defaults to '/metrics'
scheme defaults to 'http'.
static_configs:
- targets:
- 'host.docker.internal:8085'
2、运行容器
docker run -d --name prometheus -p 9090:9090
-v $PWD/prom-jmx.yml:/etc/prometheus/prometheus.yml
prom/prometheus
3、检测状态
浏览器输入:http://localhost:9090/targets,state为UP,则说明配置没有问题。
![]()
- 'host.docker.internal:8085'
浏览器输入:http://localhost:9090/graph,验证数据抓取是否成功。
4、查询IP,后续步骤会用到,具体可参考以下代码:
docker ps -a | grep prometheus | awk '{print $1}' | xargs -o -I {} docker exec -it {} sh
ifconfig - targets:

• 运行Grafana
1、配置grafana.ini(以邮件告警为例)
[smtp]
enabled = true
host = smtp.gmail.com:587
user = example@gmail.com
password = <邮箱密码>
skip_verify = true
from_address = example@gmail.com
from_name = Grafana
2、运行容器
docker run -d --name=grafana -p 3000:3000
-v $PWD/grafana.ini:/etc/grafana/grafana.ini
grafana/grafana
浏览器输入:http://localhost:3000,用户名和密码初始均为admin
浏览器输入:http://localhost:3000/alerting/notification/new,验证邮件告警配置是否正确
3、配置数据源
浏览器输入:http://localhost:3000/datasources
a. 点击添加数据源按钮;
b. 选择Prometheus作为数据源;
c. 编辑数据源
- 修改数据源名字
- URL中填写Prometheus在Docker中的IP和端口号
- 点击「保持和测试」按钮
4、配置dashboard
浏览器输入:http://localhost:3000/dashboards,点击新建Dashboard按钮。
5、添加自定义系统指标
a. 选择添加查询语句;
b. 在Query配置查询语句,需要使用PromQL格式。具体可参考:https://prometheus.io/docs/prometheus/latest/querying/basics/;
c. 在visualization选择自己喜欢的表格展示形式;
d. 在General配置监控的属性信息等;
e. 配置告警信息;
f. 最后点击保存按钮;
四、效果展示
上述步骤完成后,我们就可以在Grafana中查看相关监控信息,效果如下:
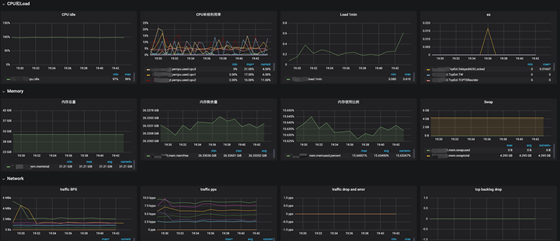
五、总结
以上我们介绍了如何通过开源组件和docker容器,快速搭建一套完善的监控系统的方法。监控系统不仅需要监控我们所关注的服务性能指标,还需要自主监控系统的各种异常日志、慢日志等。多个维度的系统监控,可以为发现、定位、解决、总结问题等提供帮助,为后续服务的性能优化、缩扩容以及维持系统的稳定等提供重要依据。
针对重要的监控项,我们需要添加告警信息。监控的指标设置可以包含多方面,但选择需要告警的监控项时则要谨慎,应保证设置的阈值合理。
重点监控项总结:
结合我们平时系统服务的维护情况,我们将需要重点关注的监控项总结如下:
1、网络环境:运营商网络、主机网卡的traffic、Nginx网关总请求耗时、Nginx后端请求耗时;
2、主机性能:CPU使用率、Load最近1分钟情况、内存使用率、内存剩余容量、磁盘使用量和剩余比例、磁盘IO速率;
3、服务性能:业务相关的QPS与TPS、线程空闲比例、线程队列大小、old区GC情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号