Spark Streaming的优化之路—从Receiver到Direct模式

作者:个推数据研发工程师 学长
1 业务背景
随着大数据的快速发展,业务场景越来越复杂,离线式的批处理框架MapReduce已经不能满足业务,大量的场景需要实时的数据处理结果来进行分析、决策。Spark Streaming是一种分布式的大数据实时计算框架,他提供了动态的,高吞吐量的,可容错的流式数据处理,不仅可以实现用户行为分析,还能在金融、舆情分析、网络监控等方面发挥作用。个推开发者服务——消息推送“应景推送”正是应用了Spark Streaming技术,基于大数据分析人群属性,同时利用LBS地理围栏技术,实时触发精准消息推送,实现用户的精细化运营。此外,个推在应用Spark Streaming做实时处理kafka数据时,采用Direct模式代替Receiver模式的手段,实现了资源优化和程序稳定性提升。
本文将从Spark Streaming获取kafka数据的两种模式入手,结合个推实践,带你解读Receiver和Direct模式的原理和特点,以及从Receiver模式到Direct模式的优化对比。
2 两种模式的原理和区别
Receiver模式
1. Receiver模式下的运行架构
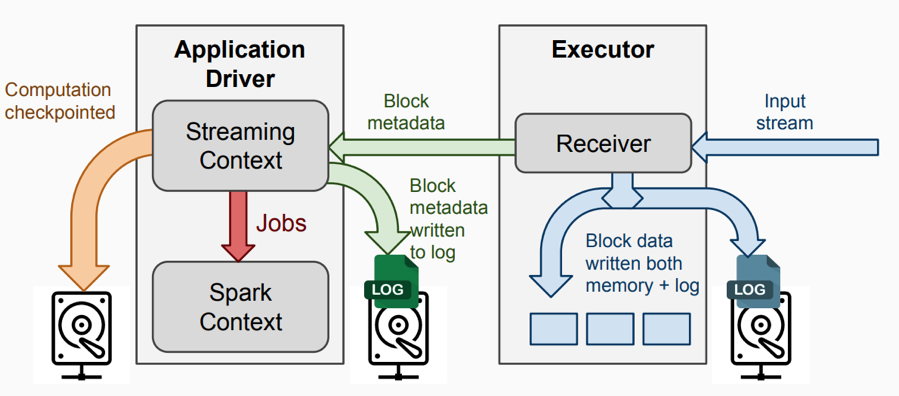
1)InputDStream: 从流数据源接收的输入数据。
2)Receiver:负责接收数据流,并将数据写到本地。
3)Streaming Context:代表SparkStreaming,负责Streaming层面的任务调度,生成jobs发送到Spark engine处理。
4)Spark Context: 代表Spark Core,负责批处理层面的任务调度,真正执行job的Spark engine。
2. Receiver从kafka拉取数据的过程
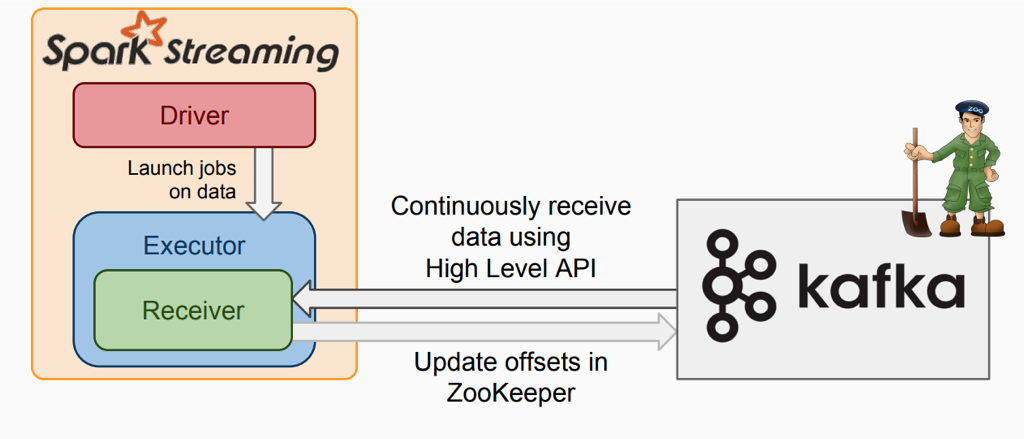
该模式下:
1)在executor上会有receiver从kafka接收数据并存储在Spark executor中,在到了batch时间后触发job去处理接收到的数据,1个receiver占用1个core;
2)为了不丢数据需要开启WAL机制,这会将receiver接收到的数据写一份备份到第三方系统上(如:HDFS);
3)receiver内部使用kafka High Level API去消费数据及自动更新offset。
Direct模式
1. Direct模式下的运行架构
与receiver模式类似,不同在于executor中没有receiver组件,从kafka拉去数据的方式不同。
2. Direct从kafka拉取数据的过程
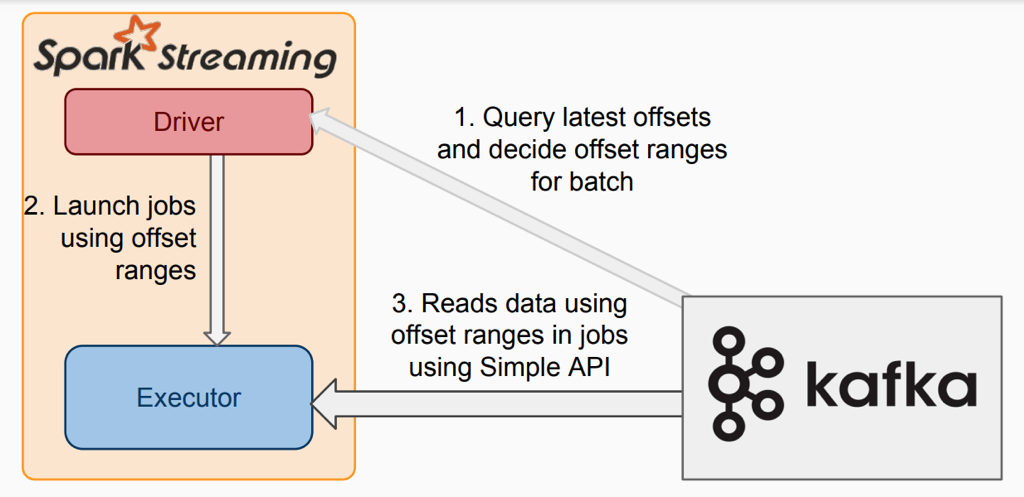
该模式下:
1)没有receiver,无需额外的core用于不停地接收数据,而是定期查询kafka中的每个partition的最新的offset,每个批次拉取上次处理的offset和当前查询的offset的范围的数据进行处理;
2)为了不丢数据,无需将数据备份落地,而只需要手动保存offset即可;
3)内部使用kafka simple Level API去消费数据, 需要手动维护offset,kafka zk上不会自动更新offset。
Receiver与Direct模式的区别
1.前者在executor中有Receiver接受数据,并且1个Receiver占用一个core;而后者无Receiver,所以不会暂用core;
2.前者InputDStream的分区是 num_receiver *batchInterval/blockInteral,后者的分区数是kafka topic partition的数量。Receiver模式下num_receiver的设置不合理会影响性能或造成资源浪费;如果设置太小,并行度不够,整个链路上接收数据将是瓶颈;如果设置太多,则会浪费资源;
3.前者使用zookeeper来维护consumer的偏移量,而后者需要自己维护偏移量;
4.为了保证不丢失数据,前者需要开启WAL机制,而后者不需要,只需要在程序中成功消费完数据后再更新偏移量即可。
3 Receiver改造成Direct模式
个推使用Spark Streaming做实时处理kafka数据,先前使用的是receiver模式;
receiver有以下特点:
1.receiver模式下,每个receiver需要单独占用一个core;
2.为了保证不丢失数据,需要开启WAL机制,使用checkpoint保存状态;
3.当receiver接受数据速率大于处理数据速率,导致数据积压,最终可能会导致程序挂掉。
由于以上特点,receiver模式下会造成一定的资源浪费;使用checkpoint保存状态, 如果需要升级程序,则会导致checkpoint无法使用;第3点receiver模式下会导致程序不太稳定;并且如果设置receiver数量不合理也会造成性能瓶颈在receiver。为了优化资源和程序稳定性,应将receiver模式改造成direct模式。
修改方式如下:
1. 修改InputDStream的创建
将receiver的:
val kafkaStream = KafkaUtils.createStream(streamingContext,
[ZK quorum], [consumer group id], [per-topic number of Kafka partitions to consume])
改成direct的:
val directKafkaStream = KafkaUtils.createDirectStream[
[key class], [value class], [key decoder class], [value decoder class] ](
streamingContext, [map of Kafka parameters], [set of topics to consume])
2. 手动维护offset
receiver模式代码:
(receiver模式不需要手动维护offset,而是内部通过kafka consumer high level API 提交到kafka/zk保存)
kafkaStream.map {
...
}.foreachRDD { rdd =>
// 数据处理
doCompute(rdd)
}
direct模式代码:
directKafkaStream.map {
...
}.foreachRDD { rdd =>
// 获取当前rdd数据对应的offset
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// 数据处理
doCompute(rdd)
// 自己实现保存offset
commitOffsets(offsetRanges)
}
4 其他优化点
1. 在receiver模式下:
1)拆分InputDStream,增加Receiver,从而增加接收数据的并行度;
2)调整blockInterval,适当减小,增加task数量,从而增加并行度(在core的数量>task数量的情况下);
3)如果开启了WAL机制,数据的存储级别设置为MOMERY_AND_DISK_SER。
2.数据序列化使用Kryoserializationl,相比Java serializationl 更快,序列化后的数据更小;
3.建议使用CMS垃圾回收器降低GC开销;
4.选择高性能的算子(mapPartitions, foreachPartitions, aggregateByKey等);
5.repartition的使用:在streaming程序中因为batch时间特别短,所以数据量一般较小,所以repartition的时间短,可以解决一些因为topicpartition中数据分配不均匀导致的数据倾斜问题;
6.因为SparkStreaming生产的job最终都是在sparkcore上运行的,所以sparkCore的优化也很重要;
7.BackPressure流控
1)为什么引入Backpressure?
当batch processing time>batchinterval 这种情况持续过长的时间,会造成数据在内存中堆积,导致Receiver所在Executor内存溢出等问题;
2)Backpressure:根据JobScheduler反馈作业的执行信息来动态调整数据接收率;
3)配置使用:
spark.streaming.backpressure.enabled
含义: 是否启用 SparkStreaming内部的backpressure机制,
默认值:false ,表示禁用
spark.streaming.backpressure.initialRate
含义: receiver 为第一个batch接收数据时的比率
spark.streaming.receiver.maxRate
含义: receiver接收数据的最大比率,如果设置值<=0, 则receiver接收数据比率不受限制
spark.streaming.kafka.maxRatePerPartition
含义: 从每个kafka partition中读取数据的最大比率
8.speculation机制
spark内置speculation机制,推测job中的运行特别慢的task,将这些task kill,并重新调度这些task执行。
默认speculation机制是关闭的,通过以下配置参数开启:
spark.speculation=true
注意:在有些情况下,开启speculation反而效果不好,比如:streaming程序消费多个topic时,从kafka读取数据直接处理,没有重新分区,这时如果多个topic的partition的数据量相差较大那么可能会导致正常执行更大数据量的task会被认为执行缓慢,而被中途kill掉,这种情况下可能导致batch的处理时间反而变长;可以通过repartition来解决这个问题,但是要衡量repartition的时间;而在streaming程序中因为batch时间特别短,所以数据量一般较小,所以repartition的时间短,不像spark_batch一次处理大量数据一旦repartition则会特别久,所以最终还是要根据具体情况测试来决定。
5 总结
将Receiver模式改成Direct模式,实现了资源优化,提升了程序的稳定性,缺点是需要自己管理offset,操作相对复杂。未来,个推将不断探索和优化Spark Streaming技术,发挥其强大的数据处理能力,为建设实时数仓提供保障。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号