NLP语义情感分析 | 10行代码帮你判断TA是否生气了
想必大家都听说过这样一句话,“男人来自火星,女人来自金星”。男女之间确实存在一定的思维差异。比如就在今年的“女神节”,可能女生明明心里也很想收到一份小礼物,隐晦地表达了自己的心声,但男生就是意识不到;再比如,男生也许真的只是有事儿在忙,但女生看到简单的“在忙”两个字后可能会想多……
怎么样才能更准确地GET到TA的真实想法和情绪,不至于和心仪的TA越走越远呢?也许可以试试技术的方式。
正文
随着AI的日益普及和在各个领域的加速落地,很多企业不断尝试将自然语言处理、语义情感分析等技术应用到智能客服、交互机器人等领域。个推也在自然语言处理及人工智能领域拥有丰富的实践经验。
本文主要借这个有趣的实操案例,为大家分享如何基于NLP进行语义情感分析。
一、准备数据
本次实验,我们使用的是从GitHub下载的开源数据集:数据集来自新浪微博,一共361744行数据,并且已经有“喜悦” “愤怒” “厌恶” “低落”等四类标签的label标记。
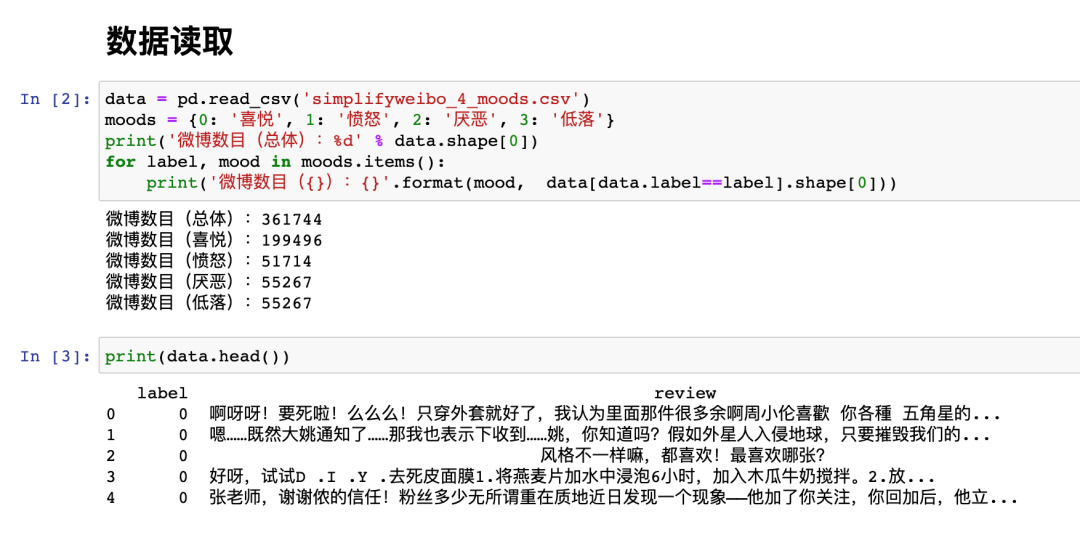
使用Python进行数据读取
二、数据预处理
我们知道,文本数据是一种非结构化的数据,且数据内部存在许多像标点、表情符号等类型的特殊字符。因此,我们要先对数据进行一些预处理。
首先,我们先剔除了文本中的一些特殊字符,并对文本进行了中文分词。

在该步骤,为了提升模型效果,我们一般需要建立停用词库,并在文本中将停用词予以剔除。但是考虑到在情感分析中,许多停用词其实有可能会对分类结果产生影响。例如对话时的“呀”,往往带有喜悦的情感色彩。因此在这里,我们并未将这一类的词汇进行剔除。
当然你也可以尝试自定义一个停用词库,并比较一下最后的分类效果。

接下来,我们进入第二步。我们按照7:3的比例将数据集分成了训练集和测试集这两个数据集。同时,我们也对每个词进行了编码,并将文本的序列调整成为相同的长度。

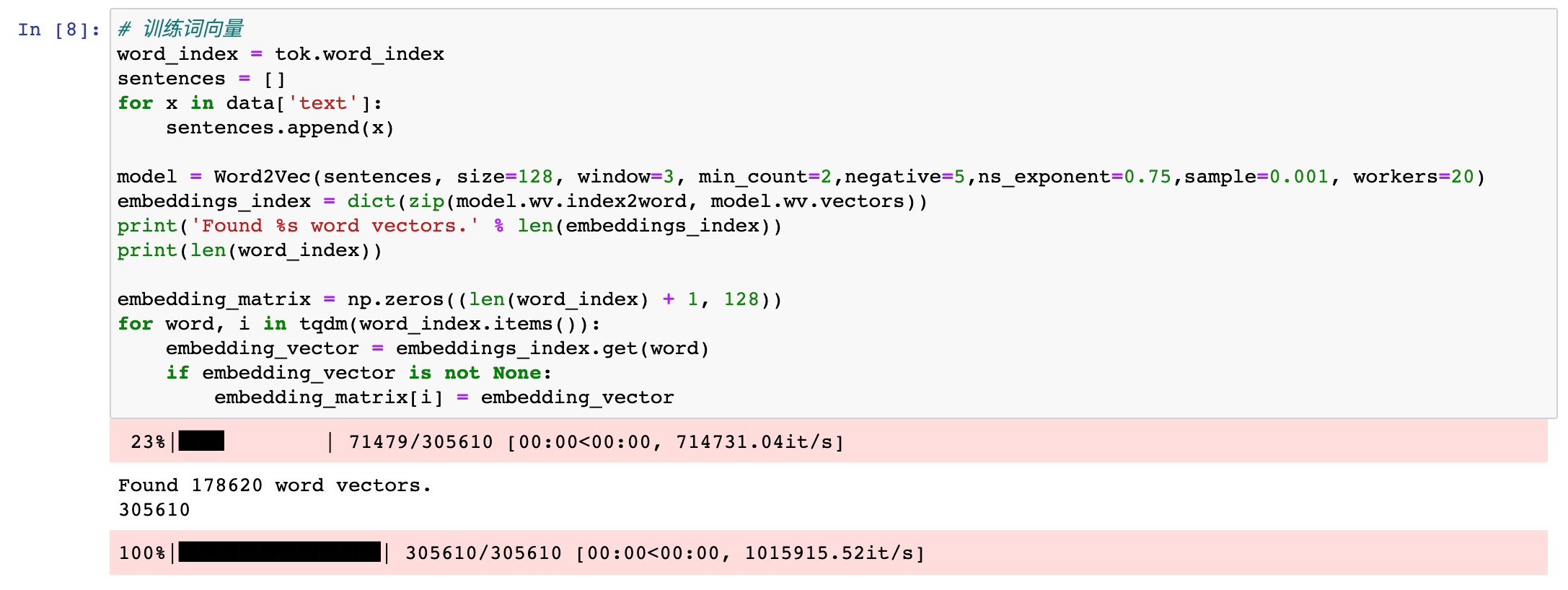
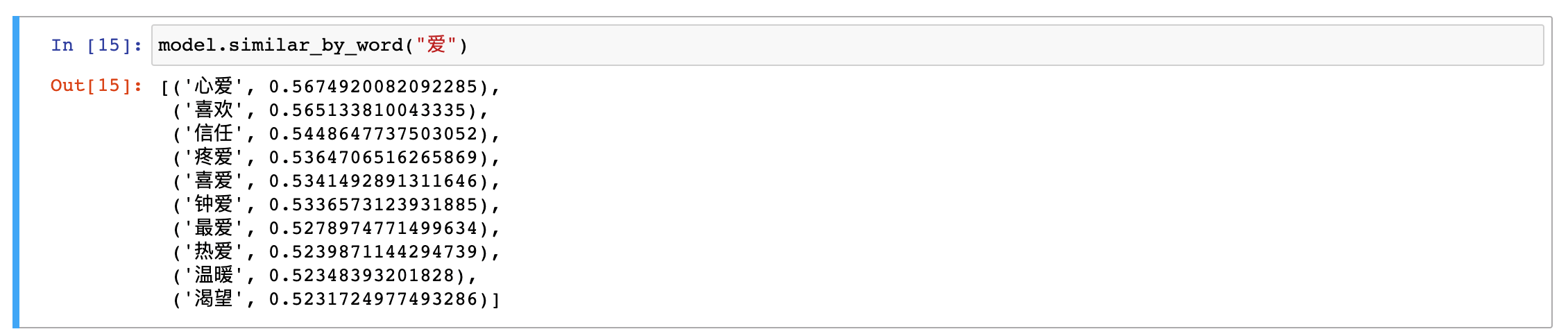
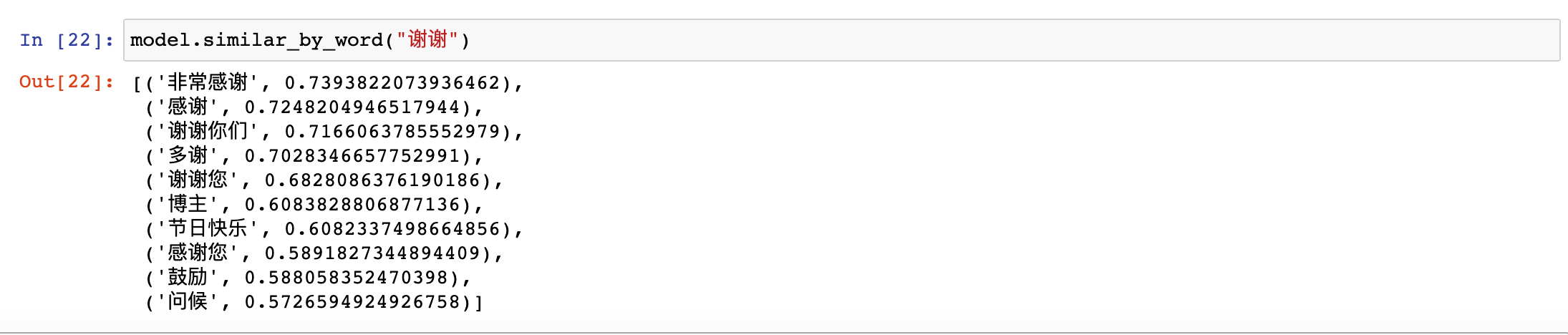
再接着,我们通过word2vec预训练来得到词向量,并且通过观察单词的相似度,对词向量的质量进行了检验。
从下图,可以看到,相似的单词还是基本符合预期的。
三、模型训练
将数据进行预处理之后,我们就可以将数据“喂入”到分类模型中。业内常用的经典文本分类模型有FastText(一种快速文本分类器)、TextCNN(利用卷积神经网络对文本进行分类的算法)、R-CNN(Region-CNN,用于实现目标检测)、Han(关键词提取算法)等。
下图是我们基于最简单的FastText算法进行文本分类的过程:

我们对该算法模型进行了10轮的持续迭代。在测试集上,该模型的准确率达到了0.582。然后,我们将FastText模型结果作为我们此次实验的baseline模型结果。
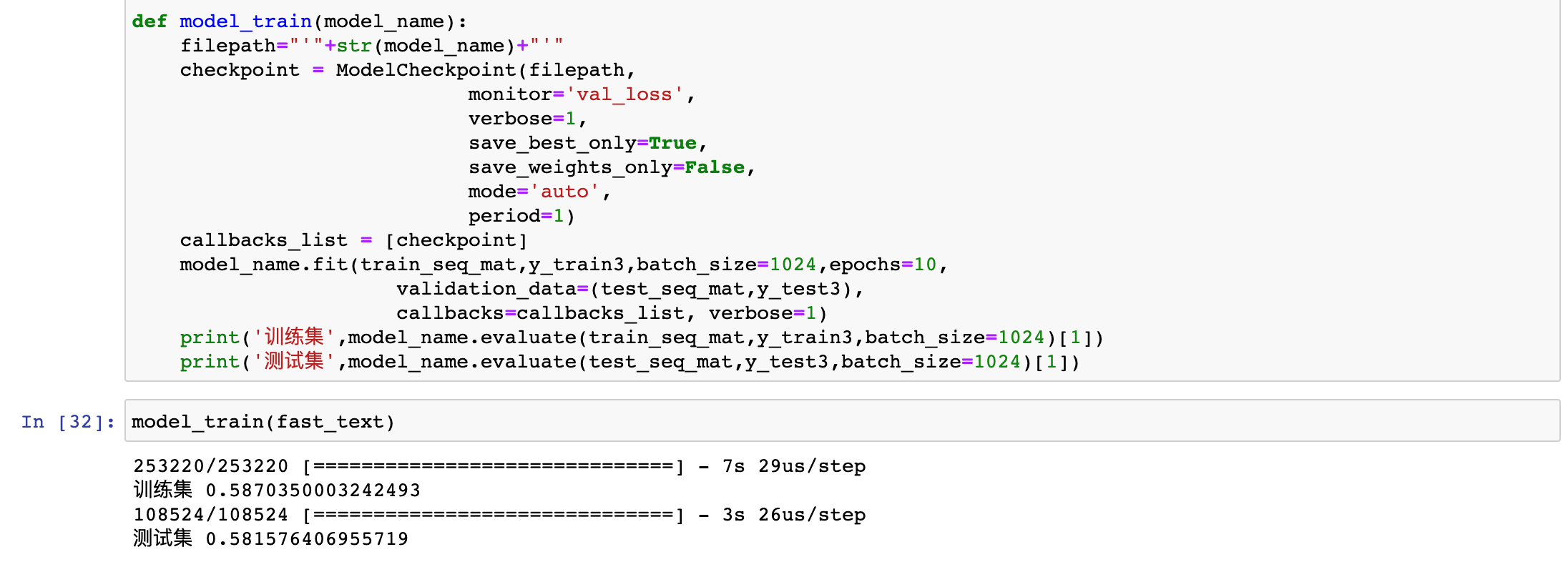
我们又分别对TextCNN、R-CNN、BiLSTM + Attention进行了测试,下表对不同算法模型的效果进行了梳理和对比:
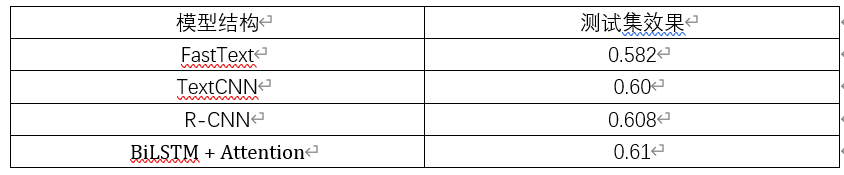
由上表我们可以看到,相较而言,还是BiLSTM + Attention的预测效果更好。
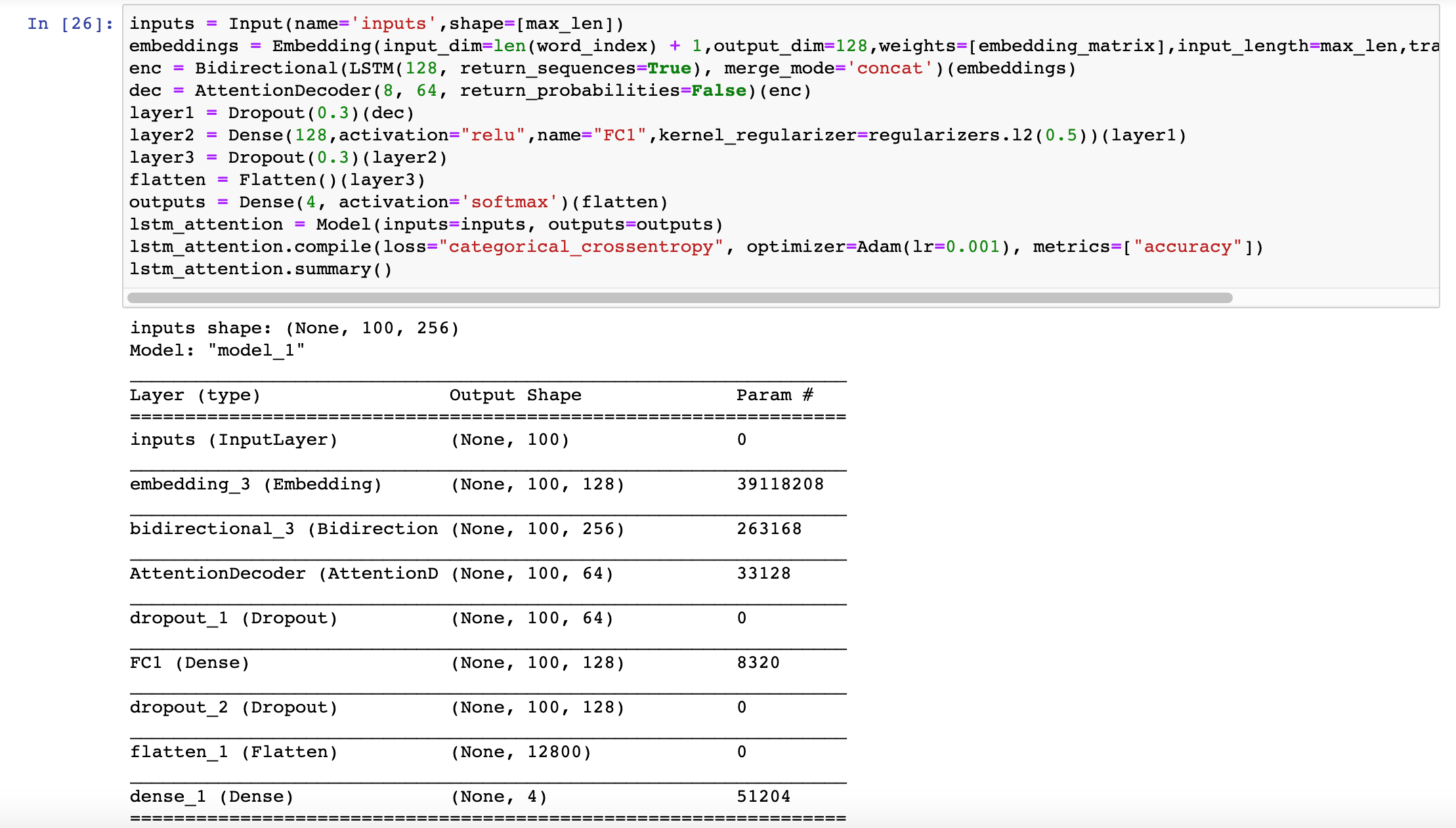
下图是我们使用BiLSTM + Attention进行模型预测的代码结构:
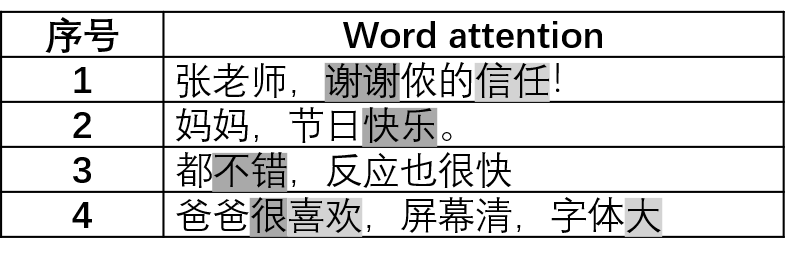
Attention的结构和加权池化层类似,我们其实可以将权重提取出来并且进行可视化:

四、模型预测
接下来,我们将训练好的BiLSTM + Attention模型进行封装,并看一下该模型的预测效果。
通过下表,可以看到,模型的训练效果还是比较令人满意的,对于“呵呵”和“哈哈哈”、“了”和“啦”这些语气词之间的微妙情绪差别都能进行相对准确的判断:
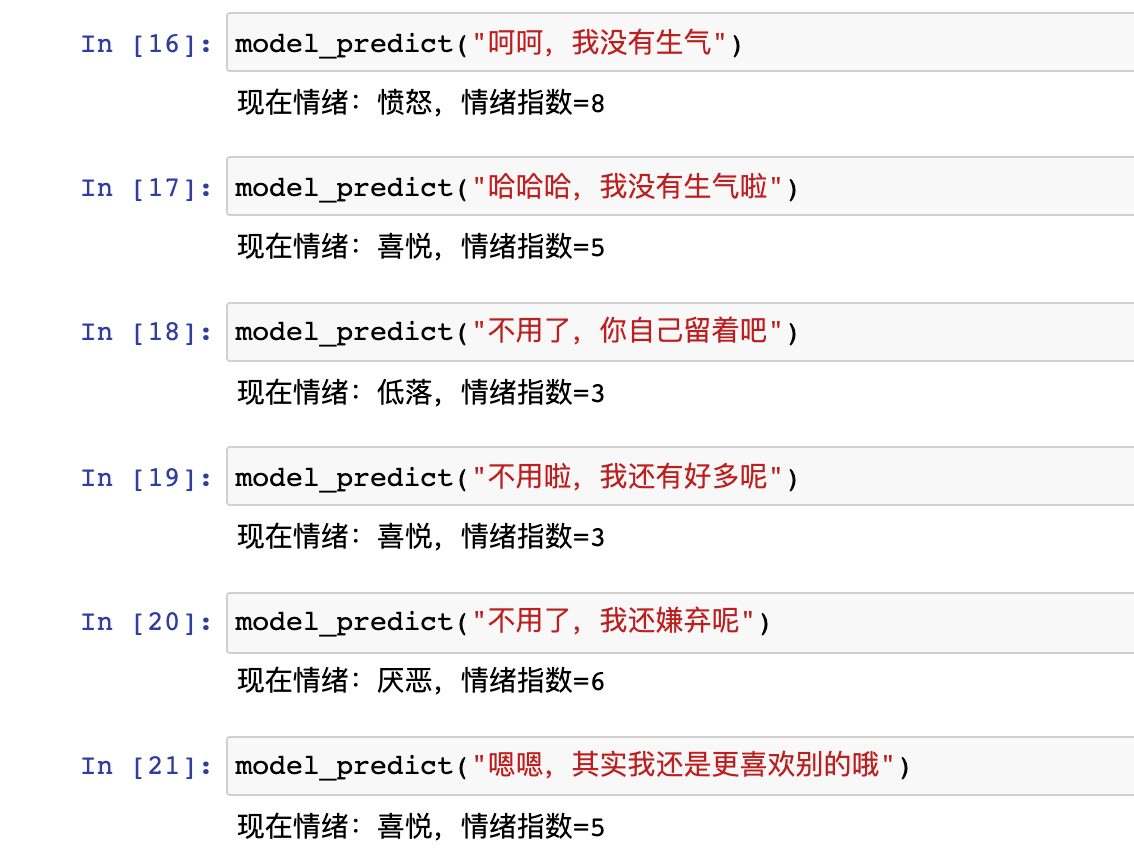
至此,本次基于NLP进行情感分析的模型训练实验也就基本完成了。
这其中其实还有许多可以优化的点,例如:针对每个标签类别占比不均衡的情况,可以进行loss修改;不仅仅可以对每个类别的标签做onehot处理,还可以将label本身的文字信息做embedding等等。感兴趣的童鞋可以在自己的实操中尝试进行更多的优化。
总结
目前,虽然AI技术的应用已经越来越成熟和普遍,算法模型也一定程度上能够对文本的情感进行判断。但是Mr.Tech也要温馨提醒大家,在现实的人际交往中,我们彼此之间还是要真诚沟通、用心交流哦。
未来,个推将不断在自然语言处理、机器视觉等前沿技术领域开展实践,也会持续将其中有价值的内容分享给大家。我们相信技术的飞速发展一定会给我们的生活带来很多有意义、有趣的改变。我们也期待读者朋友们,多多和我们交流自己的前沿实战和趣味实操案例。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号