
python字符编码
字符编码的转换
编码问题一直是个难以理解的问题,莫名其妙转换来转换去的,程序的结果就能正确输出,最后还是留出一点时间开始理解这个棘手的问题。
python有两种字符串类型,str、unicode,这两者都是basestring的子类
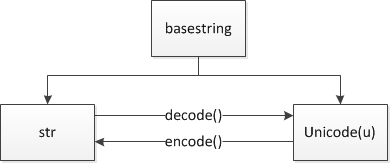
str是字节串,而unicode则是真正意义上的字符串
str可以通过decode()函数转换成unicode;
unicode可以通过encode()函数转换成str。
unicode是支持所有文字的统一编码,但一般只用作文字的内部表示,文件、网页(也是文件)、屏幕输入输出等处均需使用具体的外在编码,如GBK、UTF-8等
unicode是一种二进制编码,所有的utf-8和gbk编码都得通过unicode编码进行转译,utf-8和gbk编码之间不能直接转换,要在unicode之间过个场才能转换。
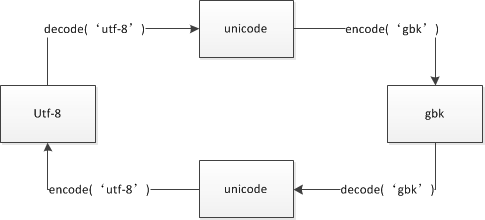
#假如我知道一串编码是用utf-8编写的,怎么转成gbk呢
u = s.decode("utf-8") # 将utf-8的str转换为unicode
g = u.encode('GBK') # 将unicode转换为str,编码为GBK
#或
s.decode('utf-8').encode('gbk')
根据图形进行转换即可
如何查看字符的编码格式?
下载第三方模块chardet
import chardet s = '汉字' print chardet.detect(s)
>>> {'confidence': 0.99, 'encoding': 'utf-8'} #chardet.detect()返回字典,其中confidence是检测精确度,encoding是编码形式
博客园暂时不更新,更多知识请移步微信公众号“测试媛学渣笔记”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号