eBPF 从入门到入门
eBPF 简介
什么是 BPF
BPF(Berkeley Packet Filter),中文翻译为伯克利包过滤器,是类 Unix 系统上数据链路层的一种原始接口,提供原始链路层封包的收发。BPF 在数据包过滤上引入了两大革新:
- 基于虚拟机 (VM) 设计,可以有效地工作在基于寄存器结构的 CPU 之上。
- 应用程序使用缓存只复制与过滤数据包相关的数据,不会复制数据包的所有信息。这样可以最大程度地减少BPF 处理的数据。
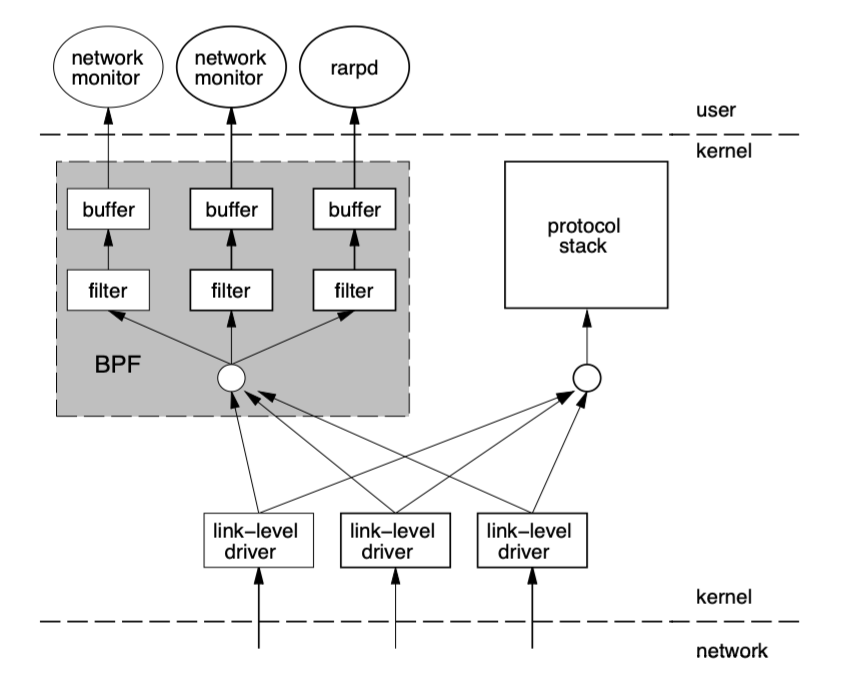
tcpdump就是采用 BPF 作为底层包过滤技术,我们可以在命令后面增加-d来查看tcpdump过滤条件的底层汇编指令。
$ tcpdump -d 'ip and tcp port 8080'
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 12
(002) ldb [23]
(003) jeq #0x6 jt 4 jf 12
(004) ldh [20]
(005) jset #0x1fff jt 12 jf 6
(006) ldxb 4*([14]&0xf)
(007) ldh [x + 14]
(008) jeq #0x1f90 jt 11 jf 9
(009) ldh [x + 16]
(010) jeq #0x1f90 jt 11 jf 12
(011) ret #262144
(012) ret #0
什么是 eBPF
2014 年初,Alexei Starovoitov 实现了 eBPF(extended Berkeley Packet Filter)。经过重新设计,eBPF 演进为一个通用执行引擎,可基于此开发性能分析工具、软件定义网络等诸多场景。eBPF 最早出现在 3.18 内核中,此后原来的 BPF 就被称为经典 BPF,缩写 cBPF(classic BPF),cBPF 虚拟机只在内核中可用,用于过滤网络数据包,与用户空间程序没有交互,因此被称为 “包过滤器”,而 eBPF 从内核空间扩展到用户空间,这也成为了 BPF 技术的转折点。
cBPF 已经基本废弃,现在,Linux 内核只运行 eBPF,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。没有特别说明,现在的 BPF 一般指的是 BPF 这项技术,而不再是任何首字母缩写词。
cBPF 和 eBPF 对比
eBPF 新的设计针对现代硬件进行了优化,所以 eBPF 生成的指令集比旧的 BPF 解释器生成的机器码执行得更快。扩展版本也增加了虚拟机中的寄存器数量,将原有的 2 个 32 位寄存器增加到 10 个 64 位寄存器。由于寄存器数量和宽度的增加,开发人员可以使用函数参数自由交换更多的信息,编写更复杂的程序。总之,这些改进使 eBPF 版本的速度比原来的 BPF 提高了 4 倍。
| 维度 | cBPF | eBPF |
|---|---|---|
| 内核版本 | Linux 2.1.75(1997年) | Linux 3.18(2014年)[4.x for kprobe/uprobe/tracepoint/perf-event] |
| 寄存器数目 | 2个:A,X |
10个:r0–r9,另外r10是一个只读的帧指针 |
| 寄存器宽度 | 32位 | 64位 |
| 存储 | 16 个内存位: M[0–15] | 512 字节堆栈,无限制大小的 “map” 存储 |
| 限制的内核调用 | 常有限,仅限于 JIT 特定 | 有限,通过 bpf_call() 指令调用 |
| 目标事件 | 数据包、 seccomp-BPF | 数据包、内核函数、用户函数、跟踪点 PMCs 等 |
eBPF 与内核模块对比
eBPF 相比于直接修改内核和编写内核模块提供了一种新的内核可编程的选项。eBPF 程序架构强调安全性和稳定性,看上去很像内核模块,但与内核模块不同,eBPF 程序不需要重新编译内核,并且可以确保 eBPF 程序运行完成,而不会造成系统的崩溃。
| 维度 | Linux 内核模块 | eBPF |
|---|---|---|
| kprobes/tracepoints | 支持 | 支持 |
| 安全性 | 可能引入安全漏洞或导致内核 Panic | 通过验证器进行检查,可以保障内核安全 |
| 内核函数 | 可以调用内核函数 | 只能通过 BPF Helper 函数调用 |
| 编译性 | 需要编译内核 | 不需要编译内核,引入头文件即可 |
| 运行 | 基于相同内核运行 | 基于稳定 ABI 的 BPF 程序可以编译一次,各处运行 |
| 与应用程序交互 | 打印日志或文件 | 通过 perf_event 或 map 结构 |
| 数据结构丰富性 | 一般 | 丰富 |
| 入门门槛 | 高 | 低 |
| 升级 | 需要卸载和加载,可能导致处理流程中断 | 原子替换升级,不会造成处理流程中断 |
| 内核内置 | 视情况而定 | 内核内置支持 |
eBPF 可以用来做什么
一个 eBPF 程序会附加到指定的内核代码路径中,当执行该代码路径时,会执行对应的 eBPF 程序。鉴于它的起源,eBPF 特别适合编写网络程序,将该网络程序附加到网络 socket,进行流量过滤、流量分类以及执行网络分类器的动作。eBPF 程序甚至可以修改一个已建链的网络 socket 的配置。XDP 工程会在网络栈的底层运行 eBPF 程序,高性能地处理接收到的报文。从下图可以看到 eBPF 支持的功能:
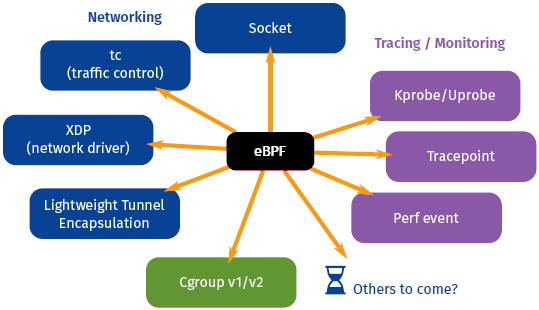
BPF 对调试内核和执行性能分析也具有很大的帮助,程序可以附加到跟踪点、kprobes 和 perf 事件。因为 eBPF 可以访问内核数据结构,开发者可以在不编译内核的前提下编写并测试代码。对于工作繁忙的工程师,通过该方式可以方便地调试一个在线运行的系统。此外,还可以通过静态定义的追踪点调试用户空间的程序(即 BCC 调试用户程序,如 MySQL)。
eBPF 是如何工作的
eBPF 程序在事件触发时由内核运行,所以可以被看作是一种函数挂钩或事件驱动的编程形式。这允许在内核和用户进程的指令中钩住和检查任何函数的内存、拦截文件操作、检查特定的网络数据包等等。
eBPF 架构
整体结构
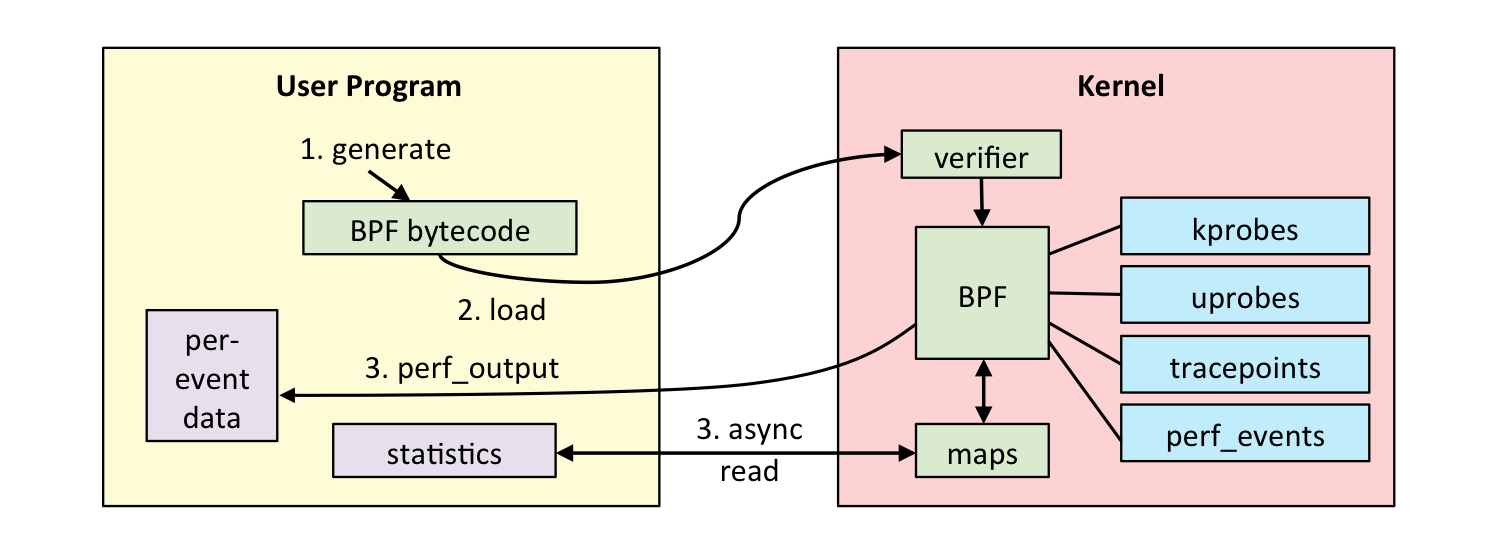
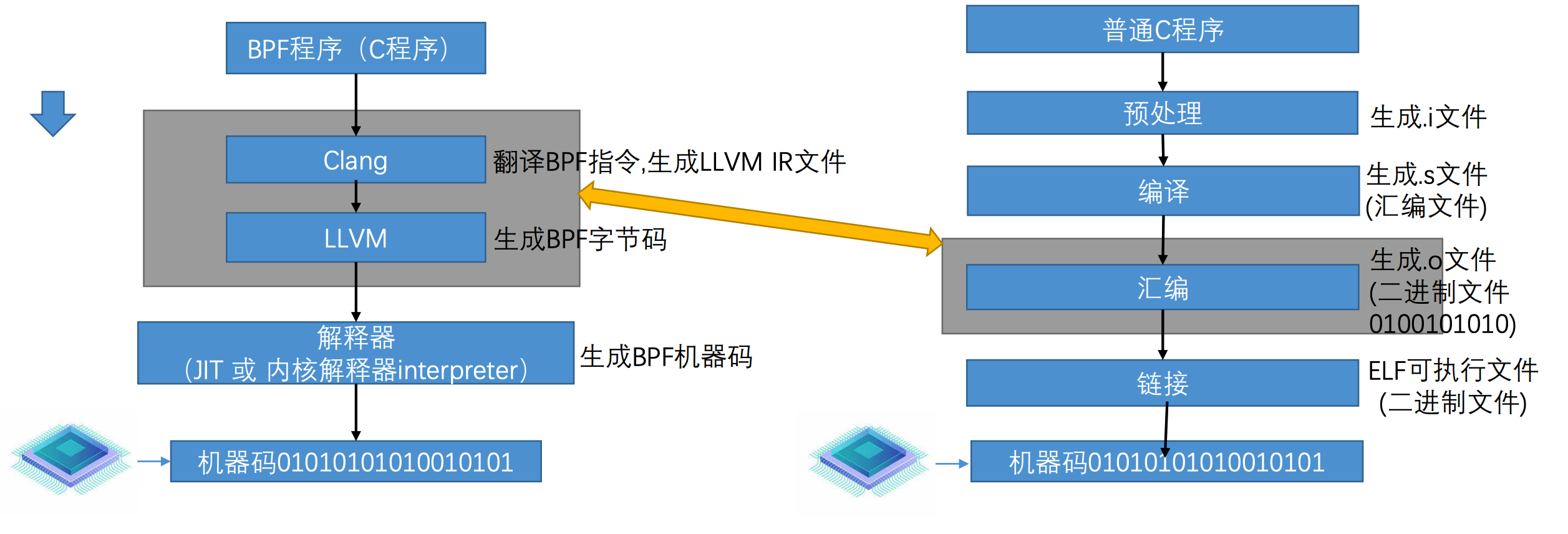
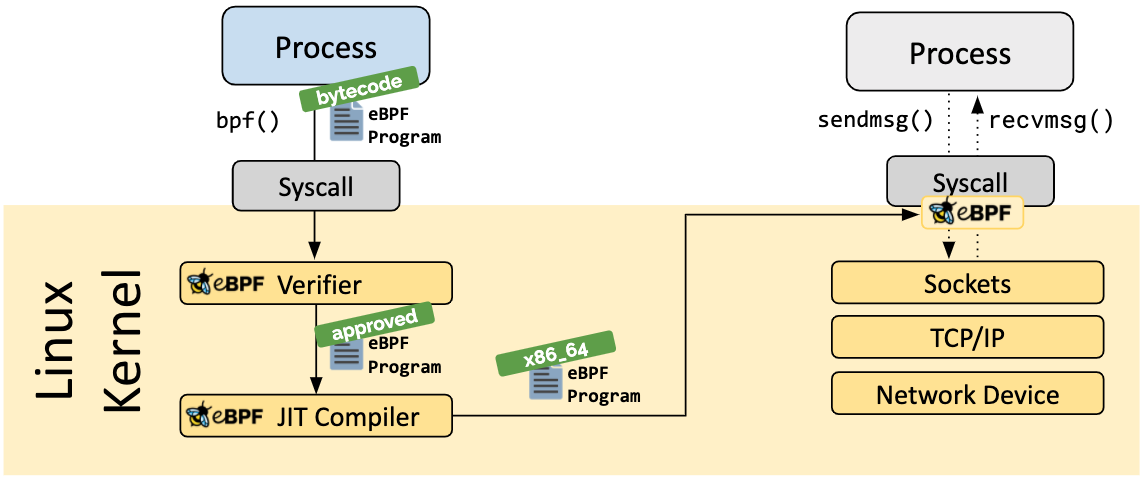
简述概括, eBPF 是一套通用执行引擎,提供了可基于系统或程序事件高效安全执行特定代码的通用能力,通用能力的使用者不再局限于内核开发者;eBPF 可由执行字节码指令、存储对象和 Helper 辅助函数组成,字节码指令在内核执行前必须通过 BPF 验证器 Verfier 的验证,同时在启用 BPF JIT 模式的内核中,会直接将字节码指令转成内核可执行的本地指令运行。
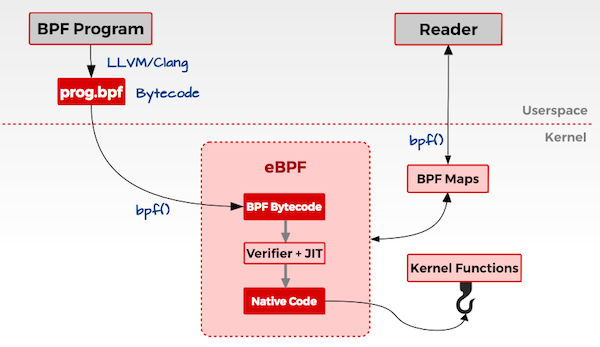
eBPF 分为用户空间程序和内核程序两部分,交互的流程主要如下:
- 使用 LLVM 或者 GCC 工具将编写的 BPF 代码程序编译成 BPF 字节码。
- 使用加载器(Loader)将字节码加载至内核。
- 内核使用验证器(Verfier)保证执行字节码的安全性,以避免对内核造成灾难,在确认字节码安全后将其加载对应的内核模块执行。
- 内核中运行的 BPF 字节码程序可以使用两种方式将数据回传至用户空间:
- maps 方式可用于将内核中实现的统计摘要信息(比如测量延迟、堆栈信息)等回传至用户空间。
- perf-event 用于将内核采集的事件实时发送至用户空间,用户空间程序实时读取分析。
eBPF 虚拟机
eBPF 是一个 RISC 寄存器机,共有 11 个 64 位寄存器,一个程序计数器和 512 字节的固定大小的栈。9 个寄存器是通用读写的,1 个是只读栈指针,程序计数器是隐式的,也就是说,我们只能跳转到它的某个偏移量。VM 寄存器总是 64 位宽,即使在 32 位 ARM 处理器内核中运行。
| 寄存器 | 用途 |
|---|---|
| r0: | 存储返回值,包括函数调用和当前程序退出代码 |
| r1-r5: | 作为函数调用参数使用,在程序启动时,r1 包含“上下文”参数指针 |
| r6-r9: | 这些在内核函数调用之间被保留下来 |
| r10: | 每个 eBPF 程序 512 字节栈的只读指针 |
在加载时提供的 eBPF 程序类型决定了哪些内核函数的子集可以被调用,以及在程序启动时通过 r1 提供的上下文参数。存储在 r0 中的程序退出值的含义也由程序类型决定。一种类型的 eBPF 程序可以挂到内核中不同的 Hook 点,这些不同的 Hook 点就是不同的附加类型。
每个函数调用在寄存器r1-r5中最多可以有 5 个参数;这适用于 ebpf 到 ebpf 的调用和内核函数调用。寄存器r1-r5只能存储数字或指向栈的指针(作为函数的参数),不能直接指向任意的内存。所有的内存访问必须在 eBPF 程序中使用之前首先将数据加载到 eBPF 栈。这一限制有助于 eBPF 验证器,它简化了内存模型,使其更容易进行内核检查。
eBPF 指令集
eBPF 指令集区别于通用的 X86 和 ARM 指令集。eBPF 指令集采用虚拟指令集规范,而 X86 和 ARM 指令集,每一条指令对应的是一条特定的逻辑门电路。
和 eBPF 虚拟机的寄存器一样,eBPF 指令也是固定大小的 64 位编码,目前大约有 100 条指令,被分组为 8 类。该虚拟机支持从通用内存进行 1-8 字节的加载/存储,前/后(非)条件跳转、算术/逻辑操作和函数调用。操作码格式格式深入研究的文档,请参考 Cilium 项目指令集文档,IOVisor 项目也维护了一个有用的指令规格。
eBPF 字节码
字节码是对指令的编码,是一种可以被执行的“机器码”,只不过被虚拟机执行。之所以称之为字节码,是指这里面的操作码(opcode)是一个字节长。一般机器指令由操作码和操作数组成,字节码(虚拟的机器码)也是由操作码和操作数组成。对于字节码,它是按照一套虚机指令集格式来组织。内核使用以下结构创建了一个 eBPF 字节码指令数组(所有指令都是这样编码),并定义了一些有用的 指令宏。
// code:8, dst_reg:4, src_reg:4, off:16, imm:32
struct bpf_insn {
__u8 code; /* opcode */
__u8 dst_reg:4; /* dest register */
__u8 src_reg:4; /* source register */
__s16 off; /* signed offset */
__s32 imm; /* signed immediate constant */
};
msb lsb
+------------------------+----------------+----+----+--------+
|immediate |offset |src |dst |opcode |
+------------------------+----------------+----+----+--------+
以BPF_JMP_IMM指令为例,它编码了一个针对立即值的条件跳转。操作码编码了指令类别BPF_JMP,操作(通过BPF_OP位域以确保正确)和一个标志BPF_K(表示是对立即数的操作)。根据注释,我们可以很容易理解 BPF_JMP_IMM(BPF_JEQ, BPF_REG_0, 0, 2) // 0x020015 表示如果r0 == 0,就会跳过接下来的 2 条指令。
/* Conditional jumps against immediates, if (dst_reg 'op' imm32) goto pc + off16 */
#define BPF_JMP_IMM(OP, DST, IMM, OFF) \
((struct bpf_insn) { \
.code = BPF_JMP | BPF_OP(OP) | BPF_K, \
.dst_reg = DST, \
.src_reg = 0, \
.off = OFF, \
.imm = IMM })
我们来分析一下内核源码中的示例 sock_example.c,这是一个简单的用户空间程序,使用 eBPF 来计算环回接口上统计接收到 TCP、UDP 和 ICMP 协议包的数量。代码所做的是从接收到的数据包中读取协议号,然后把它推到 eBPF 栈中,作为map_lookup_elem调用的索引,从而得到各自协议的数据包计数。map_lookup_elem函数在r0接收一个索引(或键)指针,在r1接收一个 map 文件描述符。如果查找调用成功,r0将包含一个指向存储在协议索引的 map 值的指针。然后我们原子式地增加 map 值并退出。
struct bpf_insn prog[] = {
// 当一个 eBPF 程序启动时,r1 中的地址指向 context 上下文(当前情况下为数据包缓冲区)。
// r1 将在函数调用时用于参数,所以我们也将其存储在 r6 中作为备份。
BPF_MOV64_REG(BPF_REG_6, BPF_REG_1),
// 这条指令从 context 上下文缓冲区的偏移量向 r0 加载一个字节(BPF_B),
// 当前情况下是网络数据包缓冲区,所以我们从一个 iphdr 结构 中提供协议字节的偏移量,以加载到 r0。
BPF_LD_ABS(BPF_B, ETH_HLEN + offsetof(struct iphdr, protocol) /* R0 = ip->proto */),
// 将包含先前读取的协议的字(BPF_W)加载到栈上(由 r10 指出,从偏移量 -4 字节开始)。
BPF_STX_MEM(BPF_W, BPF_REG_10, BPF_REG_0, -4), /* *(u32 *)(fp - 4) = r0 */
// 将栈地址指针移至 r2 并减去 4,所以现在 r2 指向协议值,作为下一个 map 键查找的参数。
BPF_MOV64_REG(BPF_REG_2, BPF_REG_10),
BPF_ALU64_IMM(BPF_ADD, BPF_REG_2, -4), /* r2 = fp - 4 */
// 将本地进程中的文件描述符引用包含协议包计数的 map 加载到 r1。
BPF_LD_MAP_FD(BPF_REG_1, map_fd),
// 执行 map 查找调用,将栈中由 r2 指向的协议值作为 key。
// 结果存储在 r0 中:一个指向由 key 索引的值的指针地址。
BPF_RAW_INSN(BPF_JMP | BPF_CALL, 0, 0, 0, BPF_FUNC_map_lookup_elem),
// 如果 map 查找没有成功,那么 r0 == 0,则我们跳过下面两条指令。
BPF_JMP_IMM(BPF_JEQ, BPF_REG_0, 0, 2),
// 递增 r0 所指向的地址的 map 值。
BPF_MOV64_IMM(BPF_REG_1, 1), /* r1 = 1 */
BPF_ATOMIC_OP(BPF_DW, BPF_ADD, BPF_REG_0, BPF_REG_1, 0),
// 将 eBPF 的 retcode 设置为 0 并退出。
BPF_MOV64_IMM(BPF_REG_0, 0), /* r0 = 0 */
BPF_EXIT_INSN(),
};
尽管这个示例的逻辑非常简单(只是在一个 Map 中增加一些数字),但通过原始字节码实现或理解它也是比较难的,如果是复杂的任务,那么在像这样的汇编程序中完成会变得非常困难。
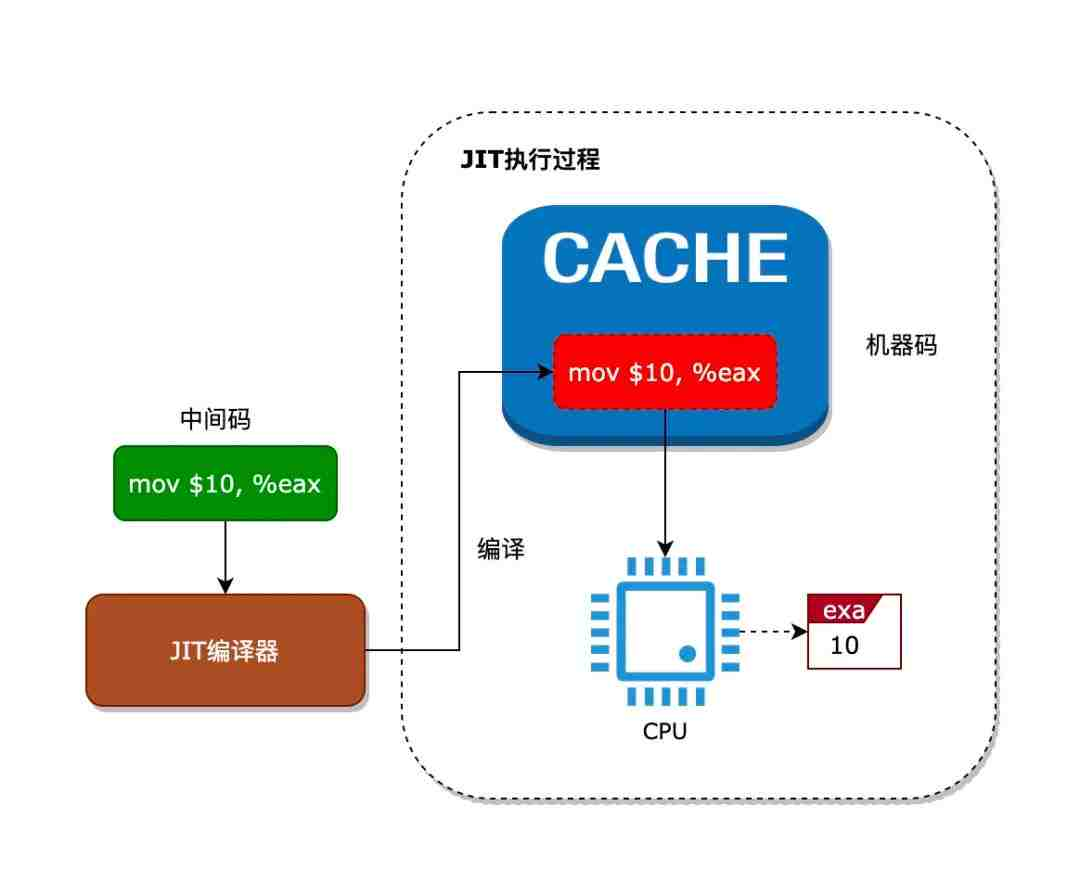
即时编译 (JIT)
由于 eBPF 是使用虚拟机解释字节码再生成机器码执行,因此相较于直接执行机器码效率要低很多。而 JIT 技术就是为了解决了解释字节码效率不高的问题,JIT 在执行中间码前,先把中间码编译成对应的机器码,然后缓存起来,运行时直接通过执行机器码即可。这样就解决了每次执行中间码都需要解析的过程。
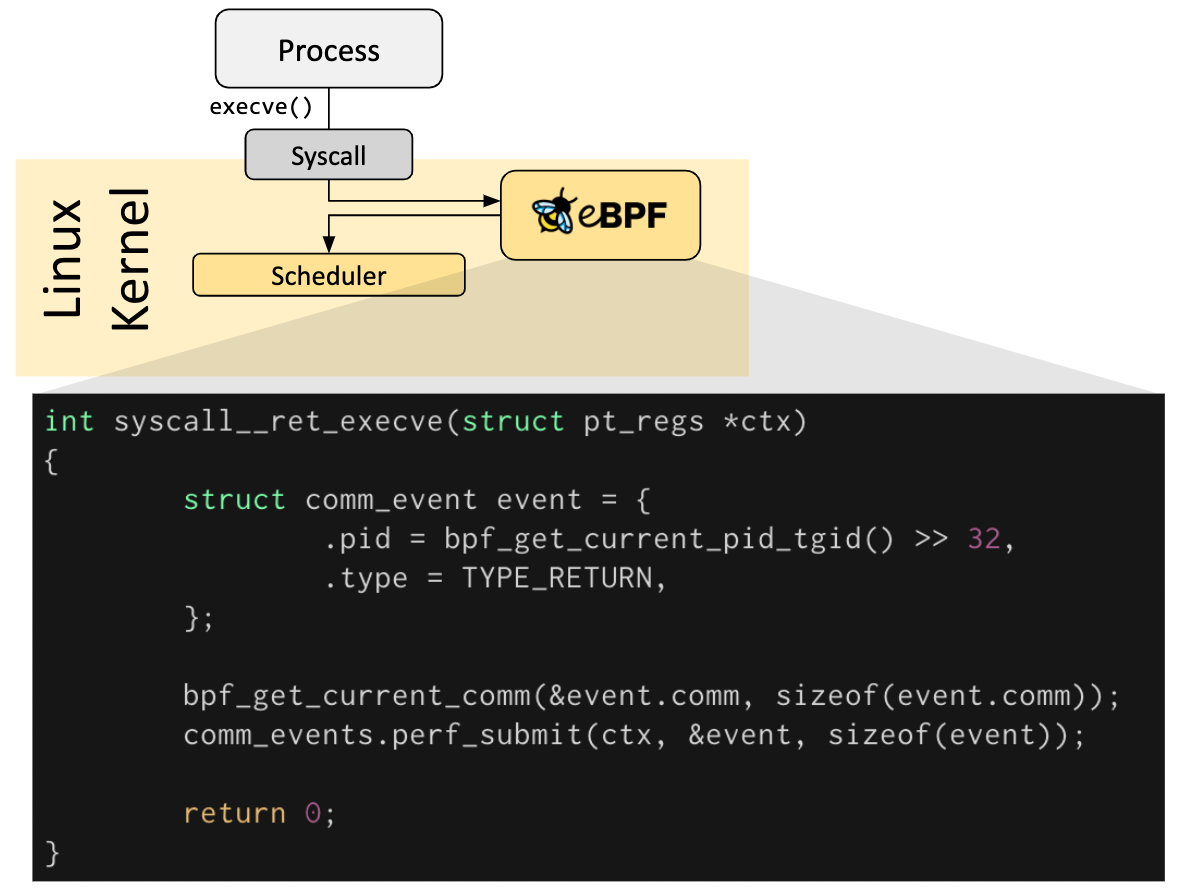
Hook
eBPF 程序都是事件驱动的,它们会在内核或者应用程序经过某个确定的 Hook 点的时候运行,这些 Hook 点都是提前定义的,包括系统调用、函数进入/退出、内核 tracepoints、网络事件等。
如果预定义 hook 不能满足需求,也可以创建内核探针(kprobe)或者用户探针(uprobe),在内核/用户应用程序的任何位置,把探针附加到 eBPF 程序上。
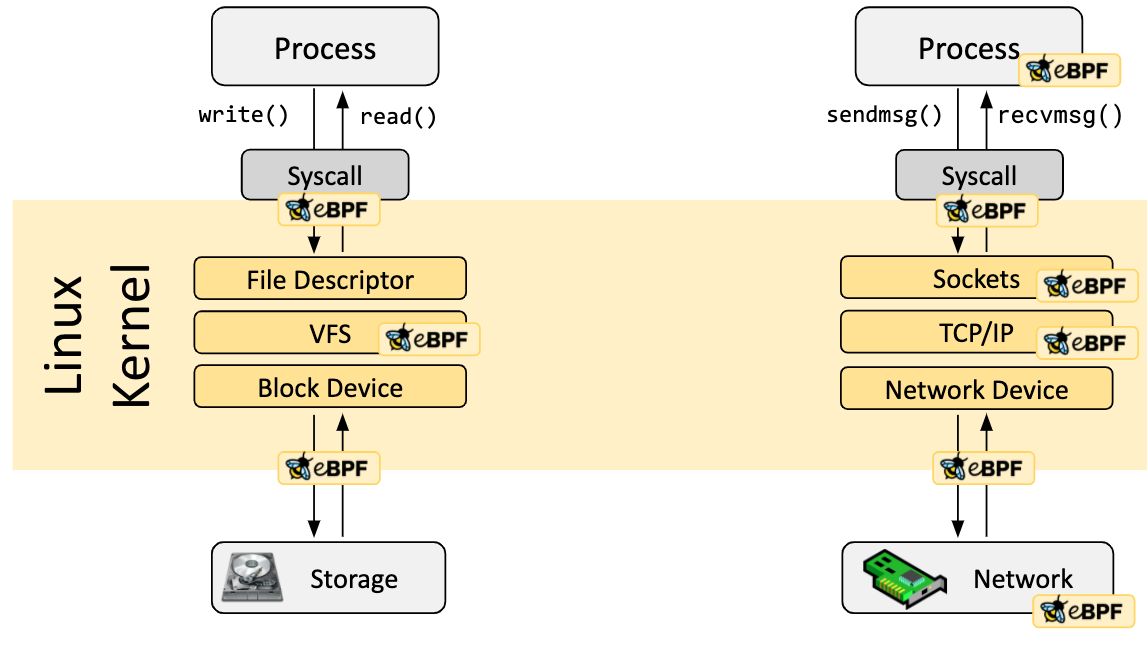
加载器和验证器
当所需的钩子被识别后,可以使用bpf()系统调用将 eBPF 程序加载到 Linux 内核中,再由验证器校验,以保证 eBPF 程序的安全性,主要包括:
- 加载 eBPF 程序的进程拥有所需的能力(特权)。除非启用非特权 eBPF,否则只有特权进程才能加载 eBPF 程序。
- 该程序不会崩溃或以其他方式损害系统。
- 程序总是运行到完成(即程序不会永远处于循环中,阻止进一步的处理)。
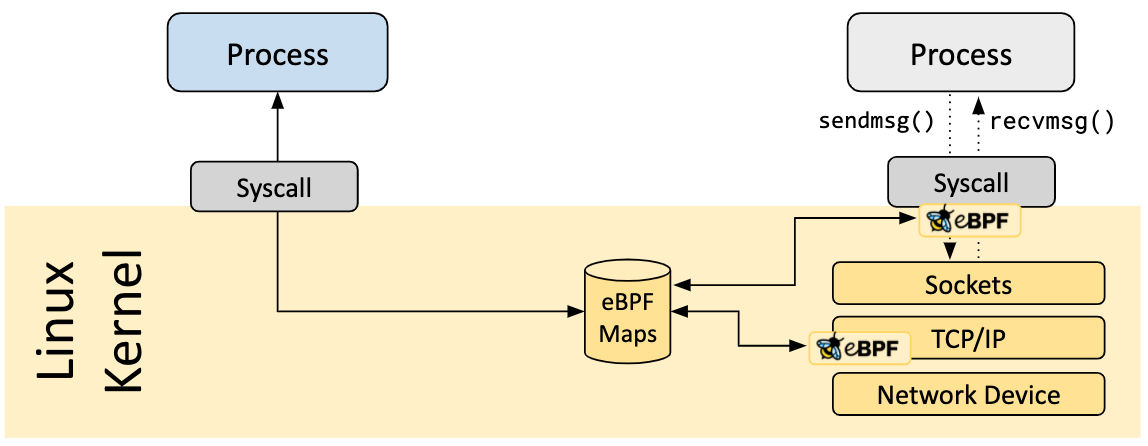
Map
eBPF 程序一个重要能力是:能够共享收集的信息,能够存储状态。为了实现该能力,eBPF 程序借用 Maps 来存储/获取数据,它是驻留在内核空间中的高效Key/Value store,支持丰富的数据结构。通过系统调用,可以从 eBPF 程序或者用户空间应用访问 maps。
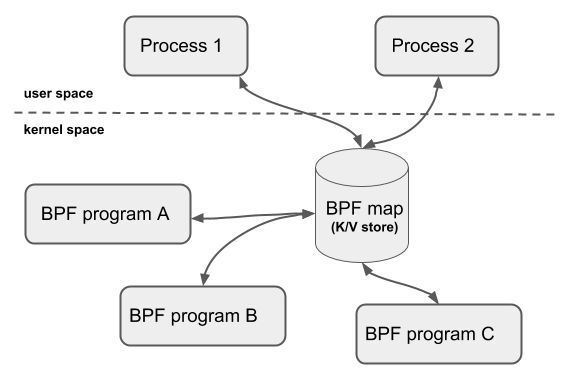
BPF Map 的交互场景有以下几种:
- BPF 程序和用户态程序的交互:BPF 程序运行完,得到的结果存储到 map 中,供用户态程序通过文件描述符访问。
- BPF 程序和内核态程序的交互:和 BPF 程序以外的内核程序交互,也可以使用 map 作为中介。
- BPF 程序间交互:如果 BPF 程序内部需要用全局变量来交互,但是由于安全原因 BPF 程序不允许访问全局变量,可以使用 map 来充当全局变量。
- BPF 尾调用:尾调用是一个 BPF 程序跳转到另一个 BPF 程序,BPF 程序通过
BPF_MAP_TYPE_PROG_ARRAY类型的 map 来知道另一个 BPF 程序的指针,然后执行。
共享 map 的 BPF 程序不要求是相同的程序类型,例如 tracing 程序可以和网络程序共享 map,单个 BPF 程序目前最多可直接访问 64 个不同 map。
辅助函数
eBPF 程序不能调用任意内核函数。允许这样做会将 eBPF 程序绑定到特定的内核版本,并使程序的兼容性复杂化。相反,eBPF 程序可以将函数调用到帮助函数中,这是内核提供的一个众所周知且稳定的 API。所有的 BPF 辅助函数都是核心内核的一部分,无法通过内核模块来扩展或添加。当前可用的 BPF 辅助函数已经有几十个,并且数量还在不断增加,可以在 Linux Manual Page: bpf-helpers 找到当前 Linux 支持的所有辅助函数。

可用辅助函数的示例:
- 生成随机数。
- 获取当前时间和日期。
- 访问 eBPF Maps。
- 获取 process/cgroup 上下文。
- 网络数据包处理和转发逻辑。
尾调用
eBPF 程序可以组合使用尾调用和函数调用(tail & function calls)。函数调用允许在 eBPF 程序中定义和调用函数。尾调用可以调用执行其他 eBPF 程序,并替换执行上下文,类似于 execve() 系统调用对常规进程的操作方式,也就是并且调用完成后不返回到原来的程序。
和普通函数调用相比,这种调用方式开销最小,因为它是用长跳转(long jump)实现的,另外相同类型的程序才可以尾调用,而且它们还要与 JIT 编译器相匹配,因此要么是 JIT 编译执行,要么是解释器执行,但不能同时使用两种方式。

eBPF 应用
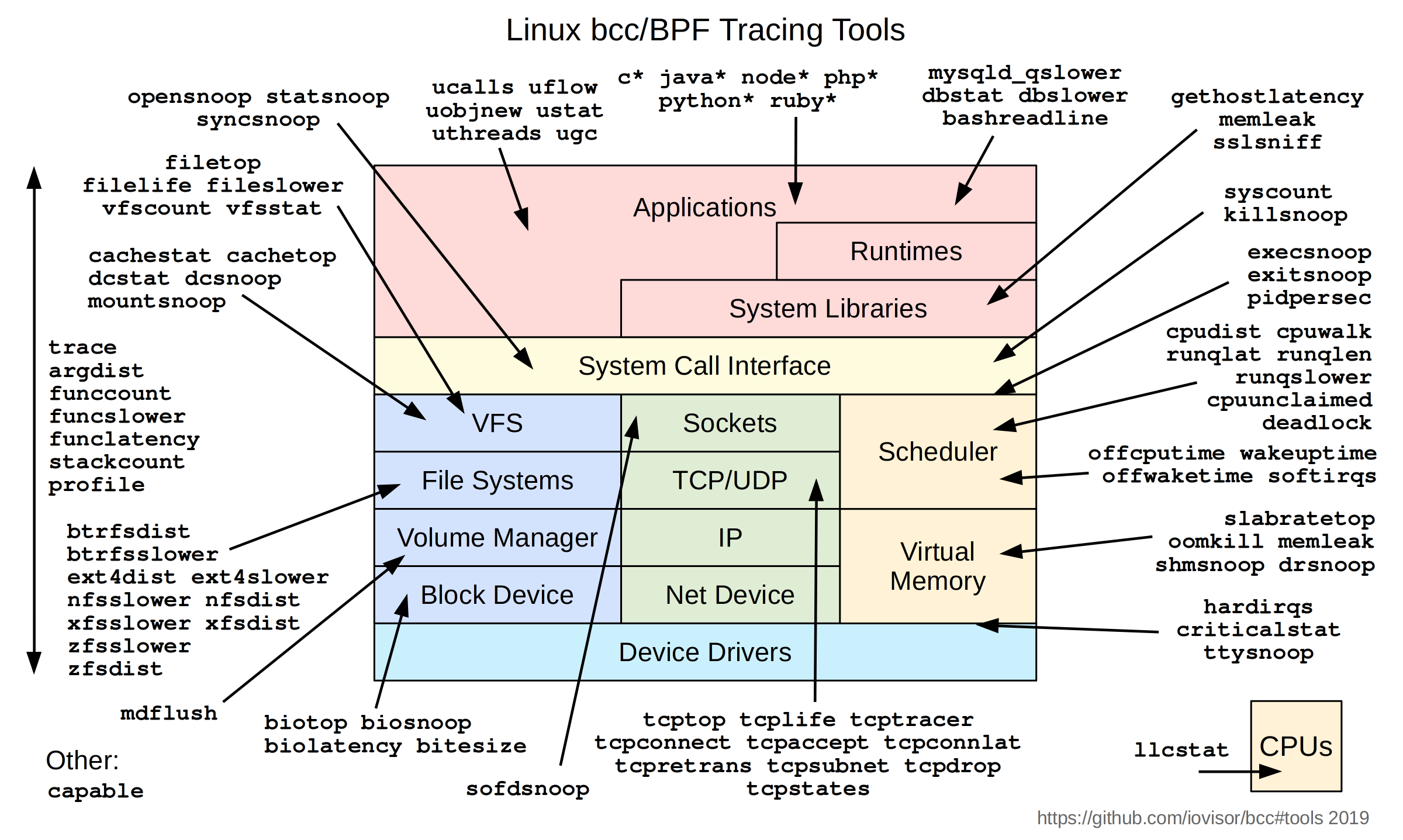
BCC Tools
BCC 是一个用于创建高效内核跟踪和操作程序的开发框架,而 BCC Tools 是 BCC 项目仓库中包含的一系列有用工具的集合,BCC Tools 示例:
opensnoop,在系统范围内跟踪open()系统调用,并打印各种详细信息。execsnoop,跟踪新进程。例如,跟踪调用时调用的命令。filetop,跟踪文件显示读取和写入,以及进程详细信息。gethostlatency,跟踪主机名查找相关的调用(getaddrinfo()、gethostbyname()和gethostbyname2())。
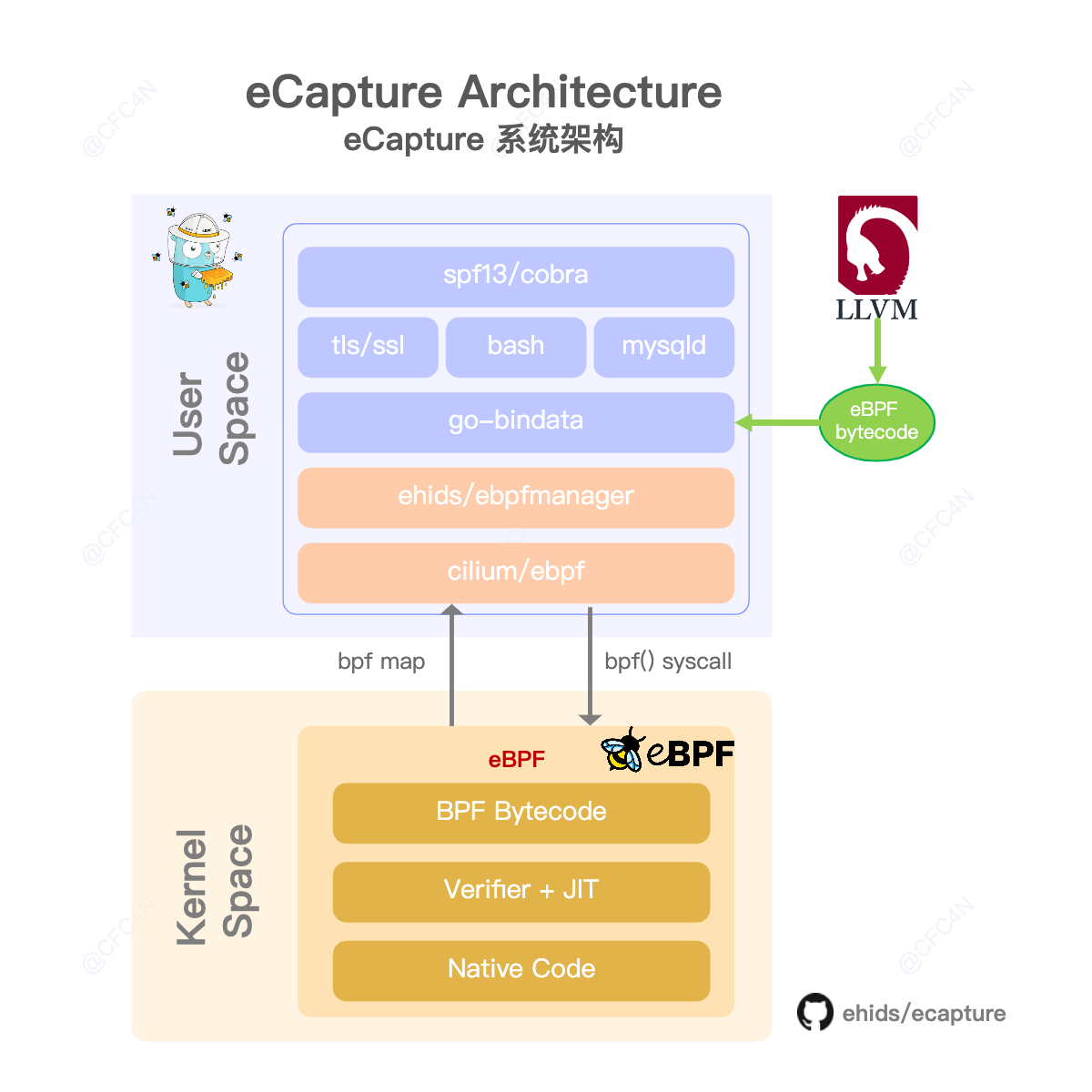
eCapture
eCapture 是一款基于 eBPF 技术实现的用户态数据捕获工具,其主要功能包括:
- 不需要 CA 证书,即可捕获 HTTPS/TLS 通信数据的明文。
- 在 bash 审计场景,可以捕获 bash 命令。
- 数据库审计场景,可以捕获 mysqld/mariadDB的SQL 查询。
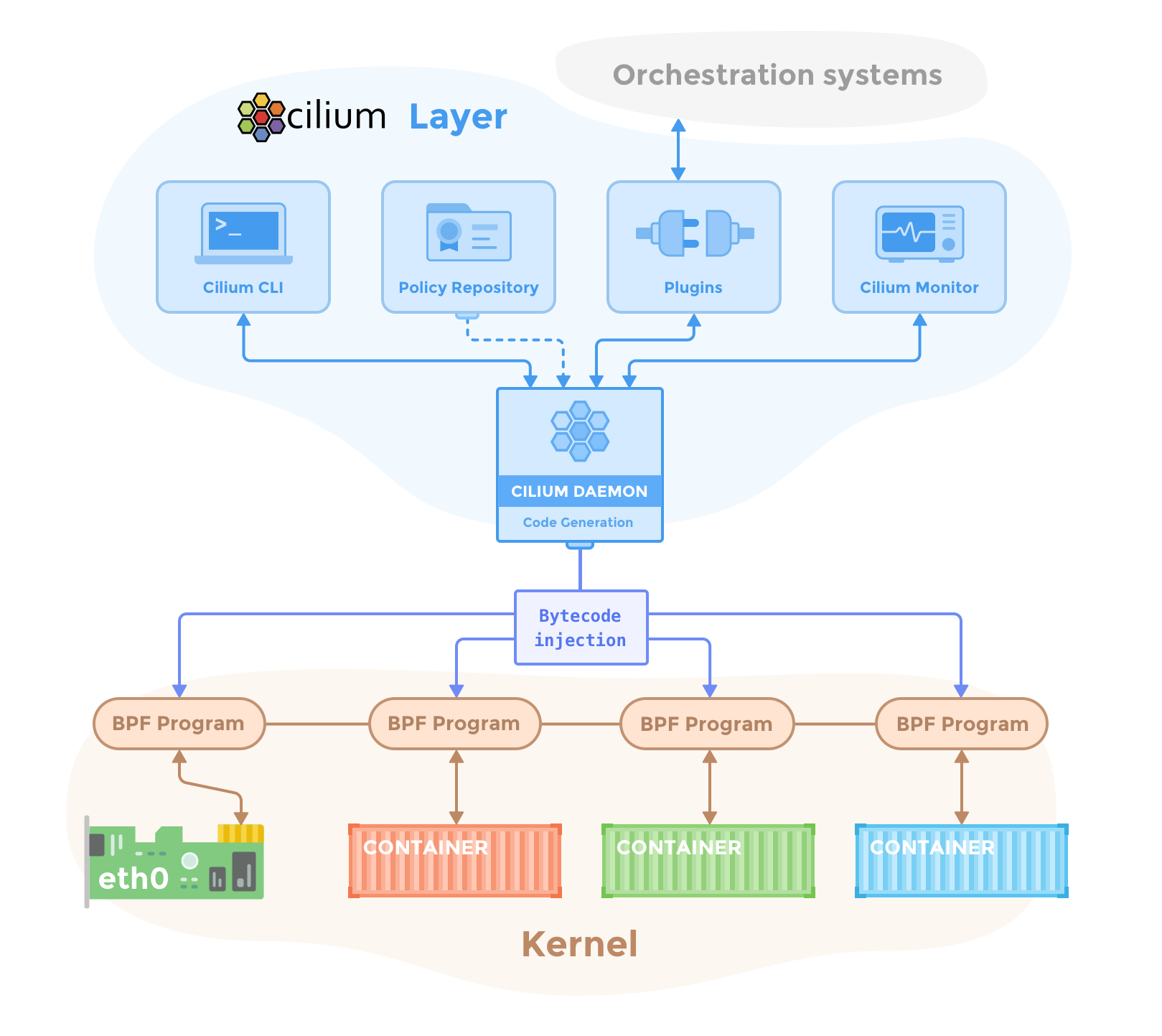
Cilium
Cilium 是一个基于 eBPF 的高性能容器网络方案。其主要功能特性包括:
- 安全上,支持 L3/L4/L7 安全策略,这些策略按照使用方法又可以分为:
- 基于身份的安全策略。
- 基于 CIDR 的安全策略。
- 基于标签的安全策略。
- 网络上,支持三层平面网络(flat layer 3 network),如:
- 覆盖网络(Overlay),包括 VXLAN 和 Geneve 等。
- Linux 路由网络,包括原生的 Linux 路由和云服务商的高级网络路由等。
- 提供基于 BPF 的负载均衡。
- 提供便利的监控和排错能力。
eBPF Exporter
eBPF Exporter 是一个将自定义 eBPF 跟踪数据导出到 Prometheus 的工具,它实现了 Prometheus 获取数据的 API,Prometheus 可以通过这些 API 主动拉取到自定义的 eBPF 跟踪数据。
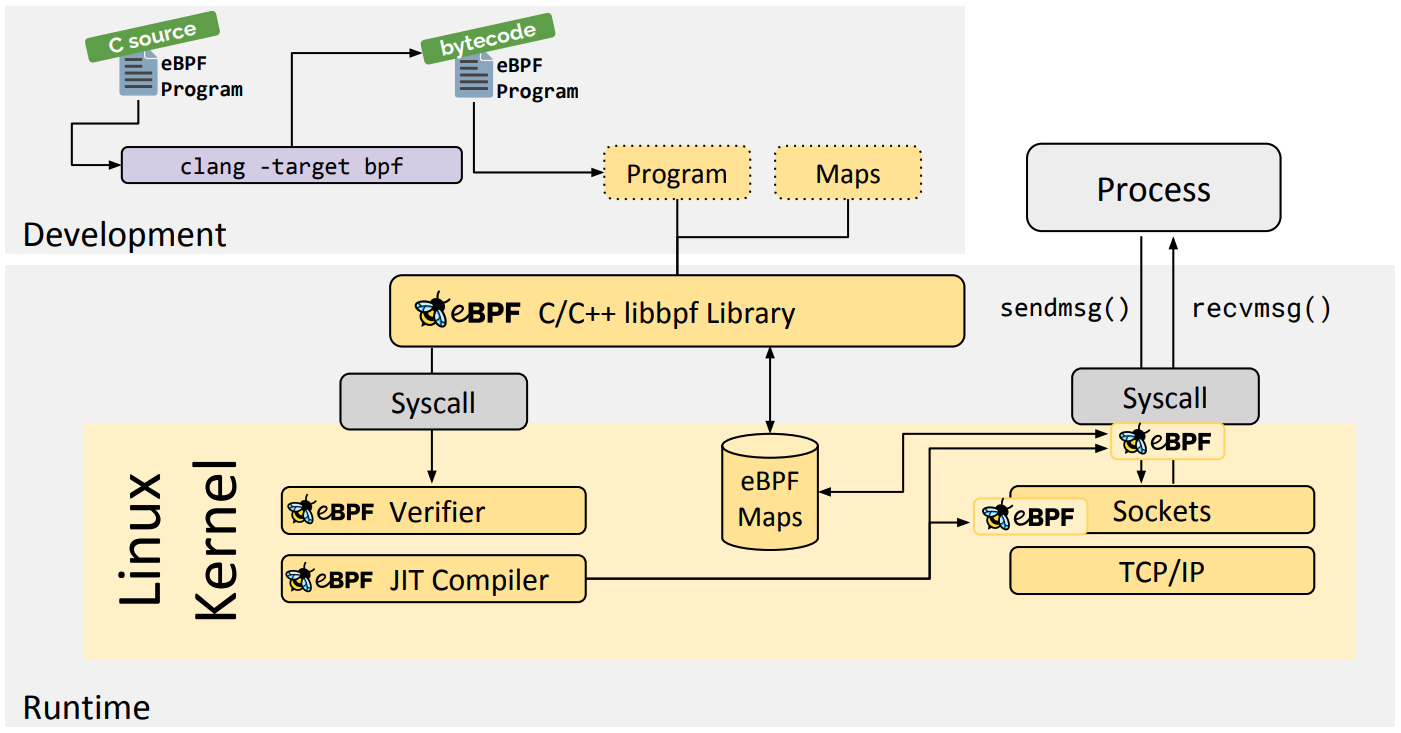
eBPF 编程
libbpf C/C++ Library
libbpf 是一个基于 C/C++ 的通用 eBPF 库。它提供给应用程序一种易用的 API 来抽象化 BPF 系统调用,并将 eBPF 字节码(clang/LLVM 编译器生成)加载到内核的过程与之分离。
我们再回过头看看之前的 sock_example.c,用这种方式分离后代码被分为了 sockex1_kern.c 和 sockex1_user.c 两个部分,之前晦涩难懂的汇编代码也变成了比较友好的 C 语言。
SEC("socket1")
int bpf_prog1(struct __sk_buff *skb)
{
int index = load_byte(skb, ETH_HLEN + offsetof(struct iphdr, protocol));
long *value;
if (skb->pkt_type != PACKET_OUTGOING)
return 0;
value = bpf_map_lookup_elem(&my_map, &index);
if (value)
__sync_fetch_and_add(value, skb->len);
return 0;
}
char _license[] SEC("license") = "GPL";
eBPF Go Library
eBPF Go 提供了一个通用的 eBPF 库,它将获取 eBPF 字节码的过程与 eBPF 程序的加载和管理分离。eBPF 程序通常是通过编写高级语言创建的,然后使用 clang/LLVM 编译器编译为 eBPF 字节码。

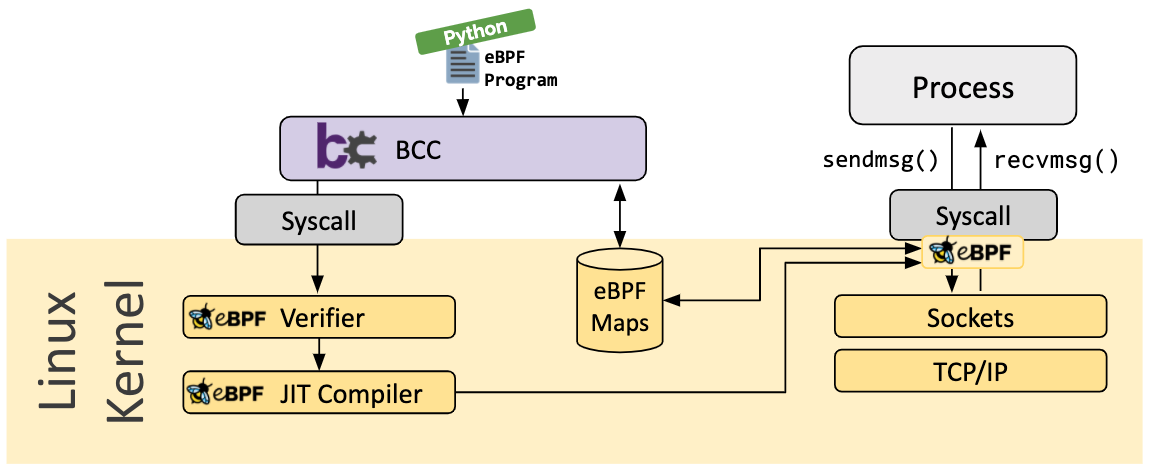
BCC
BCC 是一个框架,能够让用户编写嵌入了 eBPF 程序的 python 程序。该框架主要用来分析和跟踪应用/系统,eBPF 在其中主要负责收集统计数据或生成事件,然后,对应的用户空间程序会收集这些数据并以易读的方式进行展示。运行 python 程序会生成 eBPF 字节码并将其加载进内核。
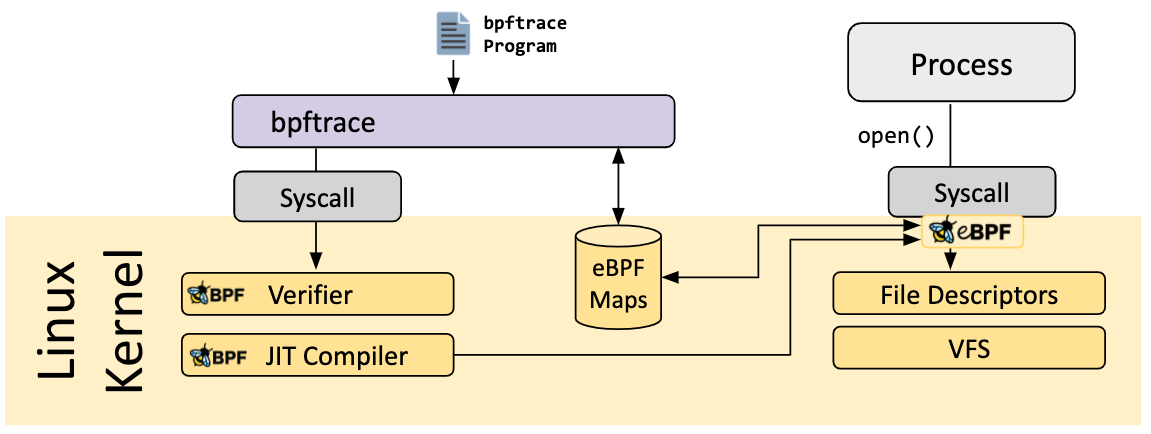
bpftrace
bpftrace 是 Linux eBPF 的高级跟踪语言。bpftrace 使用 LLVM 作为后端将脚本编译为 eBPF 字节码,并利用 BCC 与 Linux eBPF 子系统以及现有的 Linux 跟踪功能进行交互:内核动态跟踪(kprobes)、用户级动态跟踪(uprobes)和跟踪点(tracepoints)。bpftrace 语言的灵感来自 awk、C 和以前的跟踪器(如 DTrace 和 SystemTap)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号