

Mysql的整体架构设计
整体分层
- 连接层
- 服务层
- 存储引擎层
连接层
客户端要连接到服务器 3306 端口,必须要跟服务端建立连接,那么 管理所有的连接,验证客户端的身份和权限,这些功能就在连接层完成。
服务层
连接层会把 SQL 语句交给服务层,这里面又包含一系列的流程。
比如查询缓存的判断、根据 SQL 调用相应的接口,对SQL 语句进行词法和语 法的解析(比如关键字怎么识别,别名怎么识别,语法有没有错误等等)
然后就是优化器,MySQL 底层会根据一定的规则对我们的 SQL 语句进行优化,最 后再交给执行器去执行。
存储引擎
存储引擎就是数据真正存放的地方, 再往下就是内存或者磁盘
一个查询执行流程
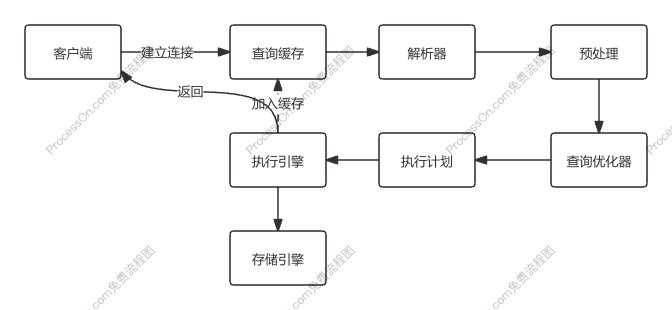
show global variables like 'wait_timeout';常见的连接池中连接等待时间
show global variables like 'interactive_timeout';可视化工具使用的非交互式超时时间
超时时间默认8小时,可以根据系统实际情况调整。
show global status like 'Thread%';查看当前的连接数量。
Threads_cached:缓存中的线程连接数。
Threads_connected:当前打开的连接数。
Threads_created:为处理连接创建的线程数。
Threads_running:非睡眠状态的连接数,通常指并发连接数。
每产生一个连接或者一个会话,在服务端就会创建一个线程来处理。
SHOW PROCESSLIST查看当前的连接状态
链接状态:https://dev.mysql.com/doc/refman/5.7/en/show-processlist.html
常见状态:https://dev.mysql.com/doc/refman/5.7/en/thread-commands.html
show variables like 'max_connections' 查看最大连接数
不是越多越好,这个需要进行基准测试后才能找到最优解
查询优化
优化器有很多优化手段,不在这里记录,后面专门更新一下。太多了。
我们可以通过explain查看优化后的执行计划
这里也只是一个执行计划,最终走那个索引,这里不能百分之百保证。
更新的sql执行过程
缓冲池 Buffer Pool
InnnoDB 的数据都是放在磁盘上的,InnoDB 操作数据有一个最小的逻辑单位,叫做页(索引页和数据页)。对于数据的操作,不是每次都直接操作磁盘,因为磁盘的速度太慢了。InnoDB 使用了一种缓冲池的技术,也就是把磁盘读到的页放到一块内存区域里面。这个内存区域就叫Buffer Pool。
下一次读取相同的页,先判断是不是在缓冲池里面,如果是,就直接读取,不用再次访问磁盘。
修改数据的时候,先修改缓冲池里面的页。内存的数据页和磁盘数据不一致的时候, 把它叫做脏页。InnoDB里面有专门的后台线程把Buffer Pool的数据写入到磁盘,每隔一段时间就一次性地把多个修改写入磁盘,这个动作就叫做刷脏。
内存结构
Buffer Pool 主要分为 3 个部分: Buffer Pool、Change Buffer、Adaptive Hash Index,另外还有一个(redo)log buffer。
Buffer Pool
Buffer Pool 缓存的是页面信息,包括数据页、索引页;
SHOW STATUS LIKE '%innodb_buffer_pool%';
当需要更新一个数据页时,如果数据页在 Buffer Pool 中存在,那么就直接更新好了。 否则的话就需要从磁盘加载到内存,再对内存的数据页进行操作。
Change Buffer 写缓冲
如果这个数据页不是唯一索引,不存在数据重复的情况,也就不需要从磁盘加载索引页判断数据是不是重复(唯一性检查)。这种情况下可以先把修改记录在内存的缓冲 池中,从而提升更新语句(Insert、Delete、Update)的执行速度。
最后把 Change Buffer 记录到数据页的操作叫做 merge。什么时候发生 merge? 有几种情况:在访问这个数据页的时候,或者通过后台线程、或者数据库 shut down、 redo log 写满时触发。
如果数据库大部分索引都是非唯一索引,并且业务是写多读少,不会在写数据后立刻读取,就可以使用 Change Buffer(写缓冲)。写多读少的业务,调大这个值:SHOW VARIABLES LIKE 'innodb_change_buffer_max_size';
Adaptive Hash Index
(redo)Log Buffer
为了避免这个问题,InnoDB 把所有对页面的修改操作专门写入一个日志文件,并且在数据库启动时从这个文件进行恢复操作(实现 crash-safe)——用它来实现事务的持久性。
SHOW VARIABLES LIKE 'innodb_log_buffer_size'; 保存即将写入日志的数据缓冲区大小。
log buffer 写入磁盘的时机,是由innodb_flush_log_at_trx_commit参数控制。
可以看官网说的:https://dev.mysql.com/doc/refman/5.7/en/innodb-parameters.html#sysvar_innodb_flush_log_at_trx_commit
binlog
binlog 以事件的形式记录了所有的 DDL 和 DML 语句(因为它记录的是操作而不是数据值,属于逻辑日志),可以用来做主从复制和数据恢复。
跟 redo log 不一样,它的文件内容是可以追加的,没有固定大小限制。
在开启了 binlog 功能的情况下,我们可以把 binlog 导出成SQL 语句,把所有的操作重放一遍,来实现数据的恢复。
binlog 的另一个功能就是用来实现主从复制,它的原理就是从服务器读取主服务器的 binlog,然后执行一遍。

- 先记录到内存,再写日志文件
- 记录 redo log 分为两个阶段。
- 存储引擎和 Server 记录不同的日志。
- 先记录 redo,再记录 binlog。
本文来自博客园,作者:Eular,转载请注明原文链接:https://www.cnblogs.com/euler-blog/p/18601213


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通