
Spark快速回顾汇总(1)
1 Spark 有几种部署方式
1)Local:运行在一台机器上,通常用于测试。Spark程序以多线程方式直接运行在本地
2)Standalone:Spark集群独立运行,不依赖于第三方资源管理系统,如:YARN、Mesos
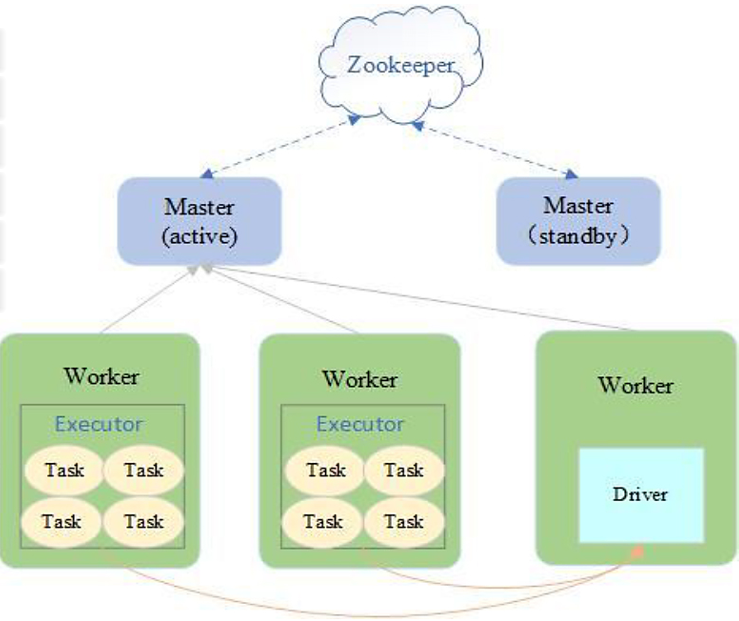
- 采用Master/Slaves架构
- Driver在Worker中运行,Master只负责集群管理
- ZooKeeper负责Master HA,避免单点故障
- 适用于集群规模不大,数据量不大的情况
![]()
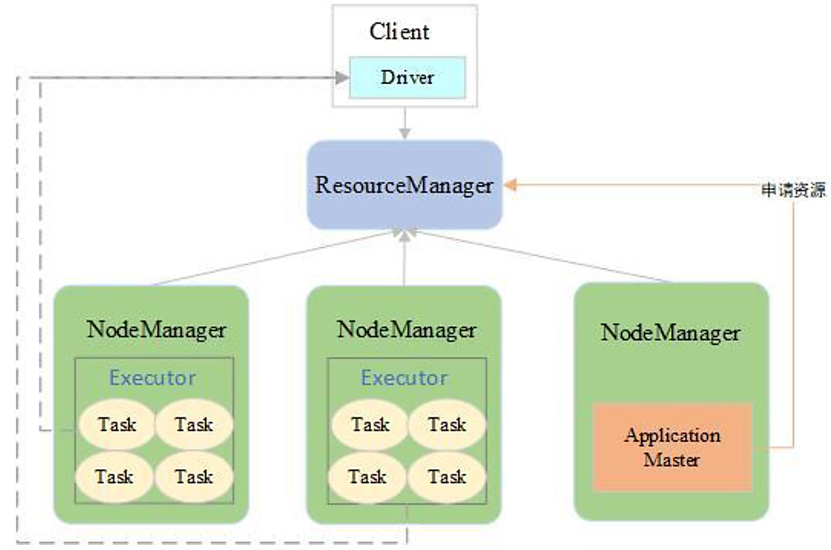
3)Yarn: Spark 客户端直接连接 Yarn,不需要额外构建 Spark 集群。有 yarn-client 和 yarn-cluster 两种模式,主要区别在于: Application Master进程的区别,即Driver 程序的运行节点。
YARN-Client模式:适用于交互和调试
Application Master仅仅向YARN请求executor,Client会和请求的container通信来调度他们工作,也就是说Client不能离开
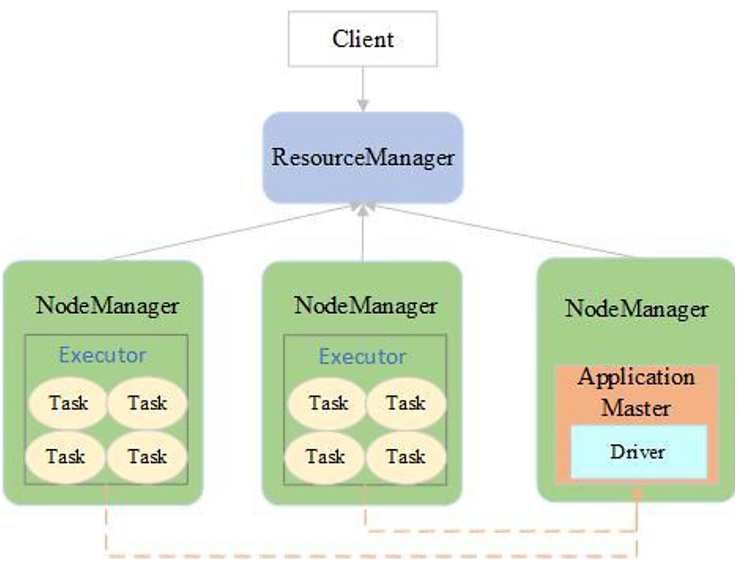
YARN-Cluster模式:适用于生产环境
driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行。
4)Mesos:比较少用。
2 Spark 提交作业参数
1)提交任务时的重要参数
executor-cores —— 每个 executor 使用的内核数,默认为 1,官方建议 2-5 个,企业是 4 个
num-executors —— 启动 executors 的数量,默认为 2
executor-memory —— executor 内存大小,默认 1G
driver-cores —— driver 使用内核数,默认为 1
driver-memory —— driver 内存大小,默认 512M
2) 提交任务的样式
spark-submit \
--master local[5] \
--driver-cores 2 \
--driver-memory 8g \
--executor-cores 4 \
--num-executors 10 \
--executor-memory 8g \
--class PackageName.ClassName XXXX.jar \
--name "Spark Job Name" \
InputPath \
OutputPath
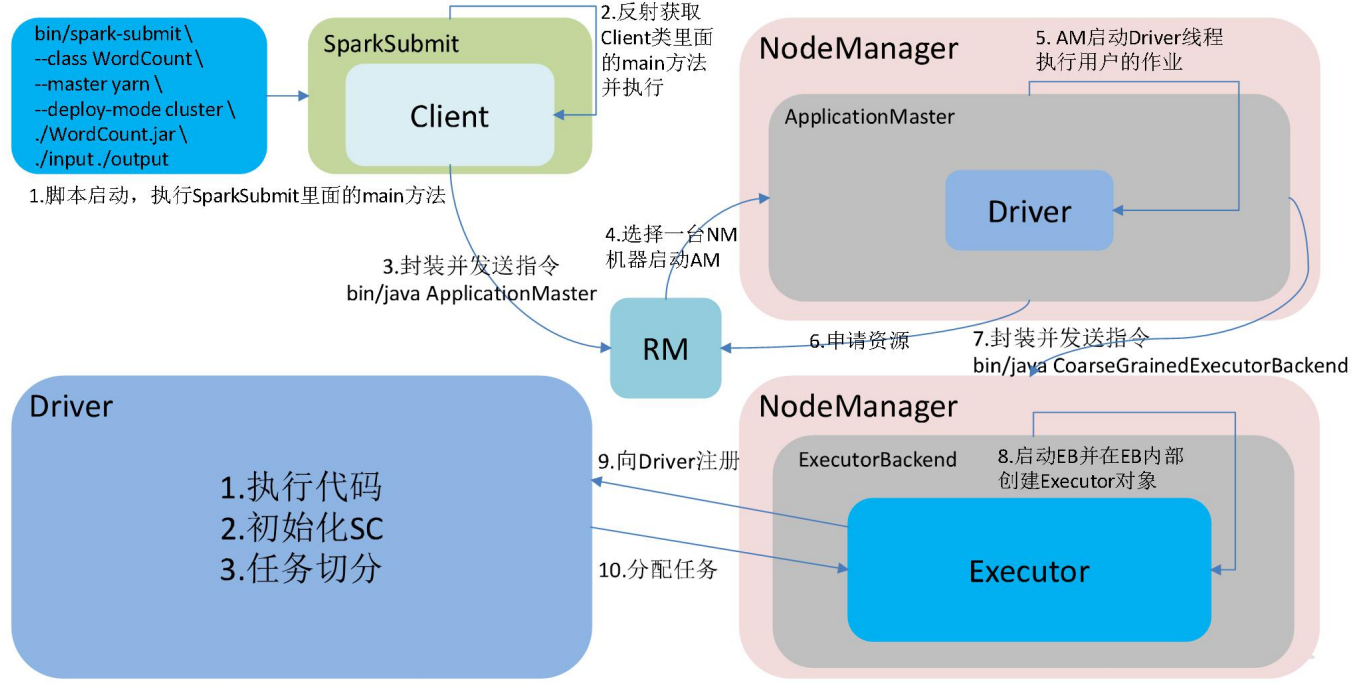
3 Spark 的架构与作业提交流程
YarnCluster模式
4 Spark 如何划分 stage,每个 stage 又根据什么决定 task 个数?
Stage:根据 RDD 之间的依赖关系的不同将 Job 划分成不同的 Stage,遇到一个宽依赖 则划分一个 Stage。
Task:Stage 是一个 TaskSet,将 Stage 根据分区数划分成一个个的 Task。
Spark学习笔记--stage和task的划分
5 列举 Spark 的 transformation 算子,并简述功能[重点]
- map(func):返回一个新的 RDD,该 RDD 由每一个输入元素经过 func 函数转换后组成.
- filter(func):返回一个新的数据集,由经过func函数处理后返回值为true的原元素组成.
- flatMap(func):类似于map,但是每一个输入元素,会被映射为0个或多个输出元素,因此,func函数的返回值是一个seq
- mapPartitions(func):类似于 map,但独立地在 RDD 的每一个分片上运行,因此在类型为T的 RDD 上运行时,func的函数类型必须是 Iterator[T] => Iterator[U]。假设有 N 个元 素,有 M 个分区,那么 map 的函数的将被调用N次,而 mapPartitions 被调用 M 次,一个函数一次处理所有分区
- groupByKey([numtasks]):在一个由(K,v)对组成的数据集上调用,返回一个(K,Seq[V])对组成的数据集。默认情况下,输出结果的并行度依赖于父RDD的分区数目,如果想要对key进行聚合的话,使用reduceByKey或者combineByKey会有更好的性能
- reduceByKey(func,[numTasks]):在一个(K,V)对的数据集上使用,返回一个(K,V)对的数据集,key相同的值,都被使用指定的reduce函数聚合到一起,reduce任务的个数是可以通过第二个可选参数来配置的 。推荐使用
- sortByKey([ascending],[numTasks]):在类型为(K,V)的数据集上调用,返回以K为键进行排序的(K,V)对数据集,升序或者降序有boolean型的ascending参数决定
6 列举Spark 的 action 算子,并简述功能[重点]
1)reduce: 通过函数func聚集数据集中的所有元素,这个函数必须是关联性的,确保可以被正确的并发执行
2)collect: 在driver的程序中,以数组的形式,返回数据集的所有元素,这通常会在使用filter或者其它操作后,返回一个足够小的数据子集再使用
3)first: 返回数据集的第一个元素(类似于take(1))
4)take: 返回一个数组,由数据集的前n个元素组成。注意此操作目前并非并行执行的,而是driver程序所在机器
5)countByKey: 对(K,V)类型的RDD有效,返回一个(K,Int)对的map,表示每一个可以对应的元素个数
6)foreach: 在数据集的每一个元素上,运行函数func,通常用于更新一个累加器变量,或者和外部存储系统做交互
7)saveAsTextFile:将数据集的元素,以textfile的形式保存到本地文件系统hdfs或者任何其他Hadoop支持的文件系统,spark将会调用每个元素的toString方法,并将它转换为文件中的一行文本
7 列举会引起Shuffle过程的Spark 算子,并简述功能[重点]
RDD有一种非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式。这种格式很像Python的字典类型。reduceByKey和groupByKey是典型pair RDD类型。
reduceBykey(func, numPartitions=None):写法等价于reduceBykey(func, [numTask]) 用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。用func作用在groupByKey产生的(K,Seq[v]),如求和 平均
groupByKey(numPartitions=None):写法等价于groupByKey([numTask]) groupByKey也是对每个key进行操作,但只生成一个sequence。如果需要对sequence进行aggregation操作(注意,groupByKey本身不能自定义操作函数),那么,选择reduceByKey/aggregateByKey更好。这是因为groupByKey不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作。返回(K,Seq[v])
8 Spark常用算子reduceByKey与groupByKey 的区别,哪一 种更具优势[重点]
reduceByKey:按照 key 进行聚合,在 shuffle 之前有 combine(预聚合)操作,返回结 果是 RDD[k,v]。
groupByKey:按照 key 进行分组,直接进行 shuffle。
开发指导:reduceByKey 比 groupByKey,建议使用。但是需要注意是否会影响业务逻辑
当采用reduceByKey时,Spark可以在每个分区移动数据之前将待输出数据与一个共用的key结合。注意在数据对被搬移前同一机器上同样的key是怎样被组合的(reduceByKey中的lamdba函数)。然后lamdba函数在每个区上被再次调用来将所有值reduce成一个最终结果。
当采用groupByKey时,由于它不接收函数,spark只能先将所有的键值对(key-value pair)都移动,这样的后果是集群节点之间的开销很大,导致传输延时。
因此,在对大数据进行复杂计算时,reduceByKey优于groupByKey。
另外,如果仅仅是group处理,那么以下函数应该优先于 groupByKey :
(1)、combineByKey 组合数据,但是组合之后的数据类型与输入时值的类型不一样。
(2)、foldByKey合并每一个 key 的所有值,在级联函数和“零值”中使用。
9 简述 Spark 的两种核心 Shuffl(e HashShuffle 与 SortShuffle) 的工作流程(包括未优化的 HashShuffle、优化的 HashShuffle、普通 的 SortShuffle 与 bypass 的 SortShuffle)[重点]
10 Repartition 和 Coalesce 关系与区别
1)关系: 两者都是用来改变 RDD 的 partition 数量的,repartition 底层调用的就是 coalesce 方法: coalesce(numPartitions, shuffle = true)
2)区别: repartition 一定会发生 shuffle,coalesce 根据传入的参数来判断是否发生 shuffle 一般情况下增大 rdd 的 partition 数量使用 repartition,减少 partition 数量时使用 coalesce
11 分 别 简 述 Spark 中 的 缓 存 机 制 ( cache 和 persist ) 与 checkpoint 机制,并指出两者的区别与联系
都是做 RDD 持久化的
cache:内存,不会截断血缘关系,使用计算过程中的数据缓存。
checkpoint:磁盘,截断血缘关系,在 ck 之前必须没有任何任务提交才会生效,ck 过程 会额外提交一次任务

 浙公网安备 33010602011771号
浙公网安备 33010602011771号