数据包分析-抓到一只苍蝇
题目名称:
数据包分析-抓到一只苍蝇
题目描述:
题目:报告首长!发现一只苍蝇。。 在哪? here! 卧槽?!好大一坨苍蝇。。
感觉很有意思,所以写了篇记录
开局拿到数据包先看http协议的,题目描述说好大一只fly,那就分组字节流搜字符串fly。发现有多个,那就先拿最先的几个追踪流看看,可以看到post请求了个JSON格式内容
{
"path":"fly.rar",
"appid":"",
"size":525701,
"md5":"e023afa4f6579db5becda8fe7861c2d3",
"sha":"ecccba7aea1d482684374b22e2e7abad2ba86749",
"sha3":""
}
结合HTTP导出对象的主机名来看,猜测这可能是邮箱文件传输,传输了一个叫fly.rar的压缩包,大小是525701。
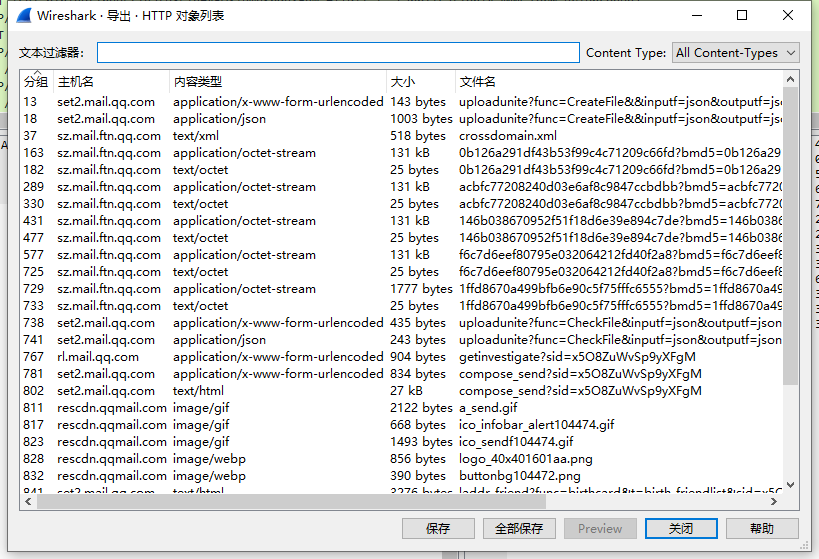
http传输文件那必然是使用post方法,使用过滤http.request.method ==POST,结合上图来看,他是经历了一次邮件传输分别向set2.mail.qq.com发送正文以及携带文件信息,sz.mail.ftn.qq.com发送附件。为什么这么讲呢?这是有推断过程的
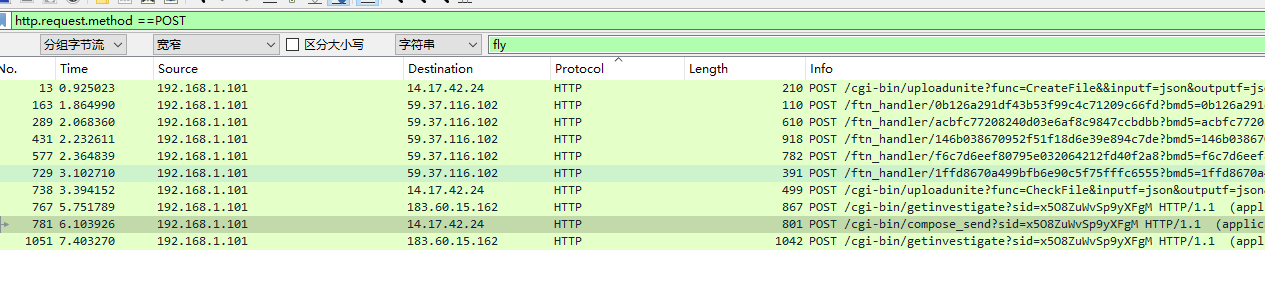
可以发现163、289、431、577、729这5个连续的post包data大小各为131436、131436、131436、131436、1777,合计大小为527521,附件原大小为525701,这是十分接近的。那到底多出来什么呢?拿去010来比较一下

发现任意文件之中都有一段相同的头部,那就是通信时候需要的头部,并不是文件本身的内容,但是从这里并不能很好判别出来头部结束在哪里。
但是通过整理之前的信息,原有数据包525701,5个合计数据包527521
(527521−525701)/5=364 即为头部文件大小
然后就是需要剔除加合并数据,使用linux的dd命令,这里参考了这篇文章
合成文件前先科普Linux/Unix语法:
语法:dd [选项]
if =输入文件(或设备名称)。
of =输出文件(或设备名称)。
ibs = bytes 一次读取bytes字节,即读入缓冲区的字节数。
skip = blocks 跳过读入缓冲区开头的ibs*blocks块。
obs = bytes 一次写入bytes字节,即写入缓冲区的字节数。
bs = bytes 同时设置读/写缓冲区的字节数(等于设置ibs和obs)
tee -a 输出追加
按顺序导出data,这里我分别命名为1.bin、2.bin ........
for i in {1..5}; do dd if=$i.bin bs=1 skip=364 2>/dev/null | tee -a fly.rar >/dev/null ; done
然后可以md5sum一下,文件完整性一致
md5sum fly.rar
e023afa4f6579db5becda8fe7861c2d3 fly.rar
但是解压会发现文件头出错,rar修复无效,那就剩下伪加密的玩法了
找到第24个字节,该字节尾数为4表示加密,0表示无加密,将尾数改为0即可破解伪加密
84改为80,解压出来一个txt,提示我们要运行此程序,顺手拖到尾部看到明显的IEND字样。先改为exe运行出来是苍蝇....,那就直接binwalk,foremost梭,foremost可以梭出来一堆图片,有二维码flag{m1Sc_oxO2_Fly}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号