
java中的数据结构
java中有几种常用的数据结构,主要分为Collection和map两个主要接口(接口只提供方法,并不提供实现),而程序中最终使用的数据结构是继承自这些接口的数据结构类。其主要的关系(继承关系)有:
Collection---->Collections
Map----->SortedMap------>TreeMap
Collection---->List----->(Vector\ArryList\LinkedList)
Map------>HashMap
Collection---->Set------>(HashSet \ LinkedHashSet \ SortedSet)
java.util包中三个重要的接口及特点:List(列表)、Set(保证集合中元素唯一)、Map(维护多个key-value键值对,保证key唯一)。其不同子类的实现各有差异,如是否同步(线程安全)、是否有序。
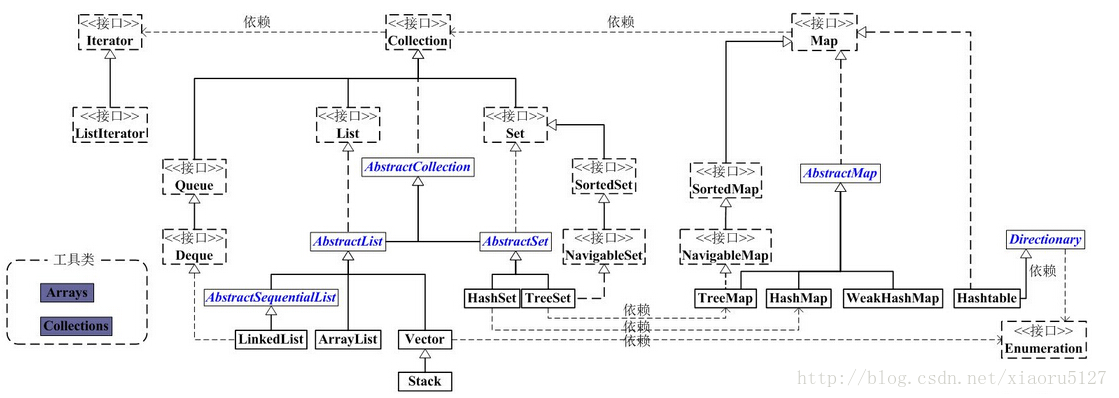
Collection (所有集合类的接口)
List、Set都继承自Collection接口,查看JDK API,操作集合常用的方法大部分在该接口中定义了。


Collections (操作集合的工具类)
对于集合类的操作不得不提到工具类Collections,它提供了许多方便的方法,如求两个集合的差集、并集、拷贝、排序等等。
由于大部分的集合接口实现类都是不同步的,可以使用Collections.synchronized*方法创建同步的集合类对象。
如创建一个同步的List:
List synList = Collections.synchronizedList(new ArrayList());
其实现原理就是重新封装new出来的对象,操作对象时用关键字synchronized同步。
List (列表)
ArrayList、Vector是线性表,使用Object数组作为容器去存储数据的,添加了很多方法维护这个数组,使其容量可以动态增长,极大地提升了开发效率。它们明显的区别是ArrayList是非同步的,Vector是同步的。不用考虑多线程时应使用ArrayList来提升效率。
ArrayList:底层是数组(动态数组,新增时数组不够会动态扩容),线程不同步
通过下标索引直接查找到指定位置的元素,因此查找、修改效率高,但每次插入或删除元素,就要大量地移动元素,因此插入删除元素的效率低。
LinkedList:底层是链表(其实就是一个双向循环链表),线程不同步,链表随机位置插入、删除数据时比线性表快,遍历比线性表慢,查询效率低。
Queue:队列,先进先出,底层单向链表或数组
Stack:栈,后进先出, 底层单向链表或数组操作有:建栈(建立空栈)、入栈、出栈、取栈顶元素
Map(存储键值对,key唯一)
HashMap结构的实现原理是将put进来的key-value封装成一个Entry对象存储到一个Entry数组中,位置(数组下标)由key的哈希值与数组长度计算而来。如果数组当前下标已有值,则将数组当前下标的值指向新添加的Entry对象。
Hashtable:底层是哈希表,线程安全(synchronized),键和值均不可为null
HashMap:底层是数组+链表(key-value保存在一个Entry中,Entry为单向链表结构,通过key算出hash值,hash值即数组下标可得Entry,如果Entry这个链表不止一个则遍历这个链表),使用哈希算法,线程不安全,键值可为null;多线程可使用ConcurrentHashMap 线程安全的
性能影响因素:初始容量(即HashMap数组的初始化容量大小)和加载因子(用以判断HashMap是否扩容,当前数组大小 >= 当前容量*加载因子)。加载因子默认0.75,过大则冲突增加,链表加长,查询效率降低;过小则空间浪费
PS:Hash地址的产生用位运算,这样效率较高
TreeMap:底层是二叉树,可排序
Android集合
ArrayMap:替代HashMap,使用Hash算法,底层是两个数组,mHash数组保存每个key的Hash值,mArray数组用连续的两个元素保存key-value。利用key的hash值计算其所在数组的下标index,如存在冲突则index往下移。key 不为null。
性能方面,查找使用二分法,增删时会对数据进行重新整理,清除数据后会自动收缩数据,释放空间。以时间换空间,消耗小,但效率没HashMap高SparseArray:替代HashMap,SparseArray并不是用Hash算法来做的,底层采用两个数组来存储key-value,适用于数据量在千级以下。性能方面,key只能是int类型,避免了自动装箱内部对数据还采取了压缩的方式来表示稀疏数组的数据在存储和读取数据时候,使用的是二分查找法
Set(保证容器内元素唯一性):只能通过迭代器Iterator取出
之所以先讲Map是因为Set结构其实就是维护一个Map来存储数据的,利用Map结构key值唯一性。
HashSet:底层是哈希表,线程不安全,无序,高效,元素唯一
LinkedHashSet:有序
TreeSet:底层是二叉树,有序,线程不安全
参考作者:xiaoru5127 原文:https://blog.csdn.net/xiaoru5127/article/details/81112820 作者:偏偏一叶扁舟原文:https://blog.csdn.net/qq_29631809/article/details/72599708

 浙公网安备 33010602011771号
浙公网安备 33010602011771号