mysql两个重要的日志redolog和binlog
一.redo log
-
使用原因
在 MySQL 里有这个问题,如果每一次的更新操作都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,整个过程 IO 成本、查找成本都很高 其实就是 MySQL 里经常说到的 WAL 技术,WAL 的全称 是 Write-Ahead Logging,它的关键点就是先写日志,再写磁盘 当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做 -
原理

InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文 件的大小是 1GB,那么这块“粉板”总共就可以记录 4GB 的操作。从头开始写,写到末 尾就又回到开头循环写,如上面这个图所示。 write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件 开头。checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录 更新到数据文件。 write pos 和 checkpoint 之间的是“粉板”上还空着的部分,可以用来记录新的操作。如 果 write pos 追上 checkpoint,表示“粉板”满了,这时候不能再执行新的更新,得停下 来先擦掉一些记录,把 checkpoint 推进一下。 有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢 失,这个能力称为crash-safe。
二.binlog(归档日志)
-
与redo log的区别
1. redo log 是 InnoDB 引擎特有的;binlog 是 MySQL 的 Server 层实现的,所有引擎 都可以使用。 2. redo log 是物理日志,记录的是“在某个数据页上做了什么修改”,虽然没有保存整页数据,但是可以记录页面级别的变更。;binlog 是逻辑日 志,记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1 ”。 3. redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。“追加写”是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志。
三.两段提交
更新过程
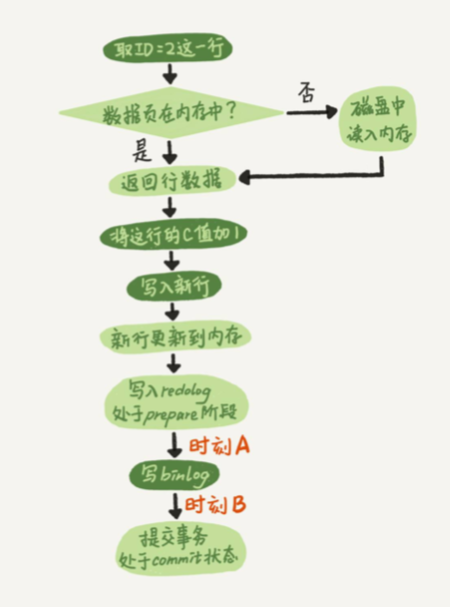
- update T set c=c+1 where ID=2;
- 执行器先找引擎取 ID=2 这一行。ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁 盘读入内存,然后再返回。
- 执行器拿到引擎给的行数据,把这个值加上 1,比如原来是 N,现在就是 N+1,得到 新的一行数据,再调用引擎接口写入这行新数据。
- 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态(处于prepare状态之后要写入磁盘中,但是redo log的commit得标识为没有commit)。然后告知执行器执行完成了,随时可以提交事务。
- 执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
-
浅色框表示是在 InnoDB 内部执行的, 深色框表示是在执行器中执行的。
-
必要性
如果不使用“两阶段提交”,那么数据库的状态就有可能和用它的日志恢复出来的库的状态不一致。 -
两段提交发生时机
我们单独写一个update语句的时候,就默认提交事务的,我们的两阶段,是发生在“提交阶段”的 如果是有begin...commit的语句序列,在执行“commit”这个语句的时候发生的提交阶段,两阶段也就在此时发生 -
在两阶段提交的不同时刻,MySQL 异常重启会出现什么现象。
-
如果在图中时刻 A 的地方,也就是写入 redo log 处于 prepare 阶段之后、写 binlog 之 前,发生了崩溃(crash),由于此时 binlog 还没写,redo log 也还没提交,所以崩溃恢复的时候,这个事务会回滚。这时候,binlog 还没写,所以也不会传到备库。
-
在时刻 B,也就是 binlog 写完,redo log 还没 commit 前发生 crash,那崩溃恢复的时候 MySQL 会怎么处理 ?
1. 如果 redo log 里面的事务是完整的,也就是已经有了 commit 标识,则直接提交; 2. 如果 redo log 里面的事务只有完整的 prepare,则判断对应的事务 binlog 是否存在并完整: a. 如果是,则提交事务; b. 否则,回滚事务。 协助理解: 当时刻B发生crash,重启后这部分redo log都丢失了,那么何谈判断redo log是否有完整的prepare还是commit标志呢? 答: 写binlog之前,就已经都写了盘并且fsync同步到磁盘了 -
时刻 B 发生 crash 对应的就是 2(a) 的情况,崩溃恢复过程中事务会被提交。
-
四.binlog写入机制
其实,binlog 的写入逻辑比较简单:事务执行过程中,先把日志写到 binlog cache,事 务提交的时候,再把 binlog cache 写到 binlog 文件中。
一个事务的 binlog 是不能被拆开的,因此不论这个事务多大,也要确保一次性写入。这 就涉及到了 binlog cache 的保存问题。
系统给 binlog cache 分配了一片内存,每个线程一个,参数 binlog_cache_size 用于控 制单个线程内 binlog cache 所占内存的大小。如果超过了这个参数规定的大小,就要暂 存到磁盘。
事务提交的时候,执行器把 binlog cache 里的完整事务写入到 binlog 中,并清空 binlog cache。状态如图 1 所示。
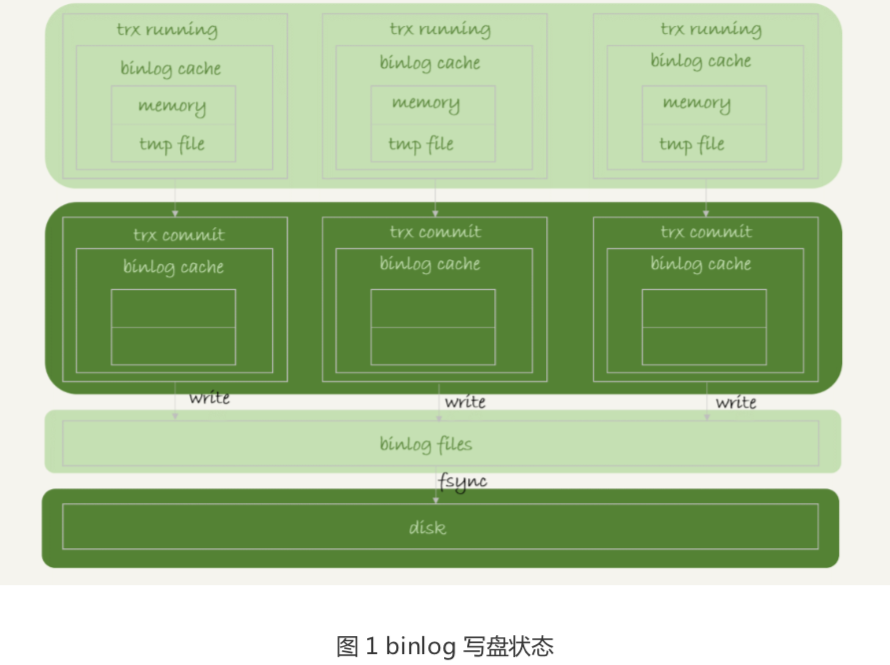
可以看到,每个线程有自己 binlog cache,但是共用同一份 binlog 文件。
图中的 write,指的就是指把日志写入到文件系统的 page cache,并没有把数据持久化 到磁盘,所以速度比较快。此时write步骤,写入操作系统维护的内存中,此内存是磁盘中文件系统申请的内存;
图中的 fsync,才是将数据持久化到磁盘的操作。一般情况下,我们认为 fsync 才占磁 盘的 IOPS。
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才fsync。
因此,在出现 IO 瓶颈的场景里,将 sync_binlog 设置成一个比较大的值,可以提升性 能。在实际的业务场景中,考虑到丢失日志量的可控性,一般不建议将这个参数设成 0, 比较常见的是将其设置为 100~1000 中的某个数值。
但是,将 sync_binlog 设置为 N,对应的风险是:如果主机发生异常重启,会丢失最近 N 个事务的 binlog 日志。
五.redo log写入机制
redo log buffer 里面的内容,是不是每次生成后都要直接持久化到磁 盘呢?
答案是,不需要。 如果事务执行期间 MySQL 发生异常重启,那这部分日志就丢了。由于事务并没有提交, 所以这时日志丢了也不会有损失。
那么,另外一个问题是,事务还没提交的时候,redo log buffer 中的部分日志有没有可能 被持久化到磁盘呢?
答案是,确实会有, 下面解释。
1.写入状态
这个问题,要从 redo log 可能存在的三种状态说起。这三种状态,对应的就是图 2 中的 三个颜色块。
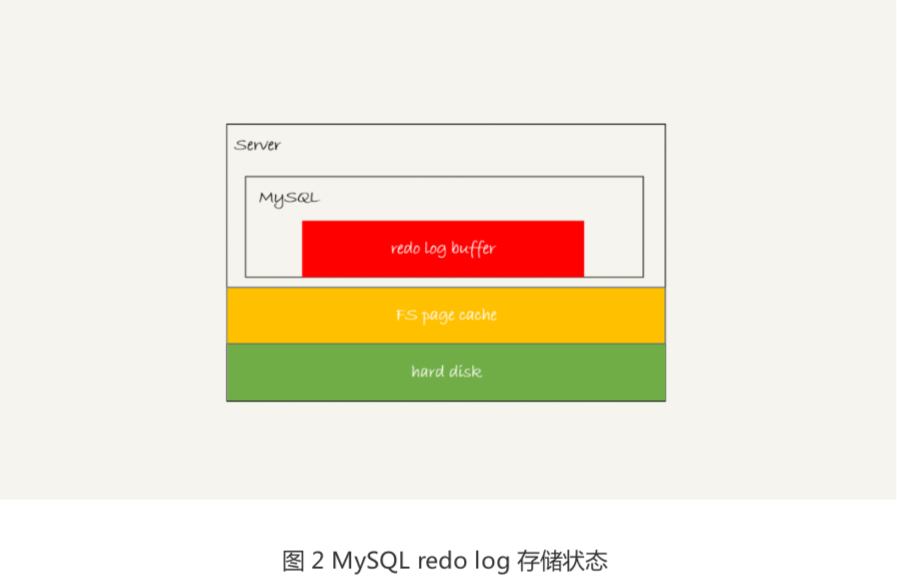
这三种状态分别是:
- 存在redo log buffer中,物理上是存在mysql进程内存中,就是图中红色部分
- 写到磁盘(write),但是没有持久化(fsync),物理上是在文件系统的page cache里面,也就是图中得黄色部分
- 持久化到磁盘,对应的是hard disk,也就是图中得绿色部分
日志写到 redo log buffer 是很快的,wirte 到 page cache 也差不多,但是持久化到磁盘 的速度就慢多了。
2.写入策略
为了控制 redo log 的写入策略,InnoDB 提供了 innodb_flush_log_at_trx_commit 参 数,它有三种可能取值:
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ;
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写 到文件系统的 page cache,然后调用 fsync 持久化到磁盘。
注意,事务执行中间过程的 redo log 也是直接写在 redo log buffer 中的,这些 redo log 也会被后台线程一起持久化到磁盘。也就是说,一个没有提交的事务的 redo log,也 是可能已经持久化到磁盘的。
实际上,除了后台线程每秒一次的轮询操作外,还有两种场景会让一个没有提交的事务的 redo log 写入到磁盘中。
- 一种是,redo log buffer 占用的空间即将达到 innodb_log_buffer_size 一半的时 候,后台线程会主动写盘。注意,由于这个事务并没有提交,所以这个写盘动作只是 write,而没有调用 fsync,也就是只留在了文件系统的 page cache。
- 另一种是,并行的事务提交的时候,顺带将这个事务的 redo log buffer 持久化到磁 盘。假设一个事务 A 执行到一半,已经写了一些 redo log 到 buffer 中,这时候有另 外一个线程的事务 B 提交,如果 innodb_flush_log_at_trx_commit 设置的是 1,那么 按照这个参数的逻辑,事务 B 要把 redo log buffer 里的日志全部持久化到磁盘。这时 候,就会带上事务 A 在 redo log buffer 里的日志一起持久化到磁盘。
3.两阶段提交详解
这里需要说明的是,我们介绍两阶段提交的时候说过,时序上 redo log 先 prepare, 再 写 binlog,最后再把 redo log commit。
如果把 innodb_flush_log_at_trx_commit 设置成 1,那么 redo log 在 prepare 阶段就 要持久化一次,因为有一个崩溃恢复逻辑是要依赖于 prepare 的 redo log,再加上 binlog 来恢复的。
每秒一次后台轮询刷盘,再加上崩溃恢复这个逻辑,InnoDB 就认为 redo log 在 commit 的时候就不需要 fsync 了,只会 write 到文件系统的 page cache 中就够了。
通常我们说 MySQL 的“双 1”配置,指的就是 sync_binlog 和 innodb_flush_log_at_trx_commit 都设置成 1。也就是说,一个事务完整提交前,需要等待两次刷盘,一次是 redo log(prepare 阶段),一次是 binlog。
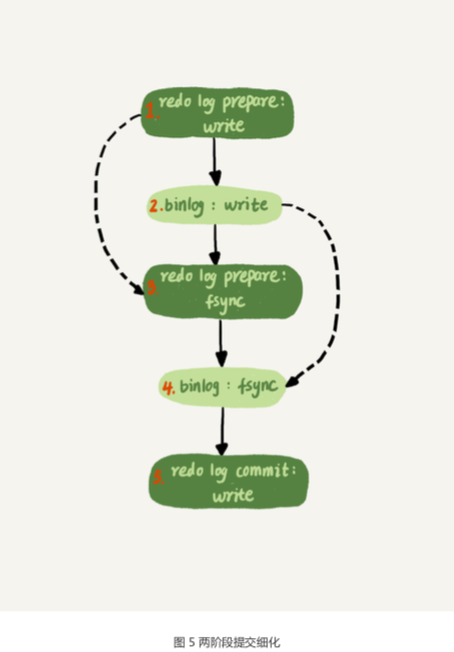
在“双 1”配置下,两阶段提交的详细流程
- redo log的prepare write阶段,写入到page cache 里(redo log prepare)
- 然后binlog进入write阶段,写入page cache里(binlog)
- 然后redo log 的prepare阶段,进行持久化fsync操作,持久化到磁盘(redo log prepare)
- binlog进行持久化阶段fsync阶段,持久化到磁盘(binlog)
- commit阶段,先将binlog添加commit标识,再将redo log添加commit标识,redo log进行write,写入page cache(commit)
六.组提交
1.redo log组提交
这里,我需要先和你介绍日志逻辑序列号(log sequence number,LSN)的概念。LSN 是单调递增的,用来对应 redo log 的一个个写入点。每次写入长度为 length 的 redo log, LSN 的值就会加上 length。
LSN 也会写到 InnoDB 的数据页中,来确保数据页不会被多次执行重复的 redo log。关 于 LSN 和 redo log、checkpoint 的关系,我会在后面的文章中详细展开。
如图 3 所示,是三个并发事务 (trx1, trx2, trx3) 在 prepare 阶段,都写完 redo log buffer,持久化到磁盘的过程,对应的 LSN 分别是 50、120 和 160。
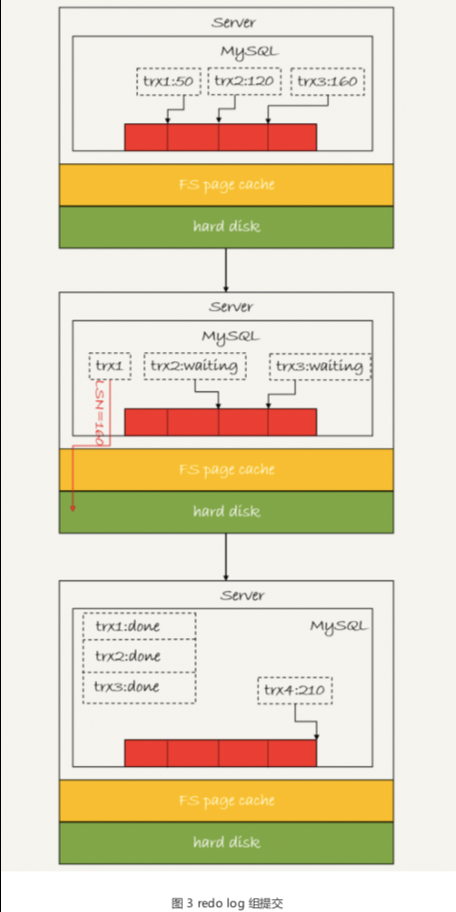
从图中可以看到,
- trx1 是第一个到达的,会被选为这组的 leader;
- 等 trx1 要开始写盘的时候,这个组里面已经有了三个事务,这时候 LSN 也变成了160;
- trx1 去写盘的时候,带的就是 LSN=160,因此等 trx1 返回时,所有 LSN 小于等于160 的 redo log,都已经被持久化到磁盘;
- 这时候 trx2 和 trx3 就可以直接返回了。
所以,一次组提交里面,组员越多,节约磁盘 IOPS 的效果越好。但如果只有单线程压 测,那就只能老老实实地一个事务对应一次持久化操作了。
在并发更新场景下,第一个事务写完 redo log buffer 以后,接下来这个 fsync 越晚调 用,组员可能越多,节约 IOPS 的效果就越好。
2.binlog组提交
为了让一次 fsync 带的组员更多,MySQL 有一个很有趣的优化:拖时间。在介绍两阶段 提交的时候,我曾经给你画了一个图,现在我把它截过来。
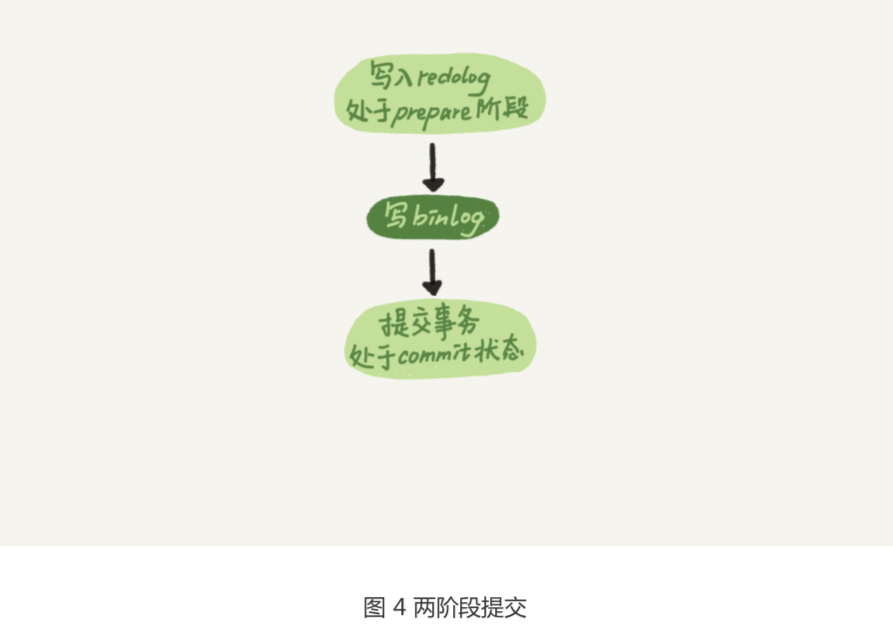
图中,我把“写 binlog”当成一个动作。但实际上,写 binlog 是分成两步的:
- 先把 binlog 从 binlog cache 中写到磁盘上的 binlog 文件,此时write步骤,写入操作系统维护的内存中,此内存是磁盘中文件系统申请的内存;
- 调用 fsync 持久化。
MySQL 为了让组提交的效果更好,把 redo log 做 fsync 的时间拖到了步骤 1 之后。也 就是说,上面的图变成了这样:
这么一来,binlog 也可以组提交了。在执行图 5 中第 4 步把 binlog fsync 到磁盘时,如 果有多个事务的 binlog 已经写完了,也是一起持久化的,这样也可以减少 IOPS 的消耗。
不过通常情况下第 3 步执行得会很快,所以 binlog 的 write 和 fsync 间的间隔时间短, 导致能集合到一起持久化的 binlog 比较少,因此 binlog 的组提交的效果通常不如 redo log 的效果那么好。
如果你想提升 binlog 组提交的效果,可以通过设置 binlog_group_commit_sync_delay 和binlog_group_commit_sync_no_delay_count 来实现。
binlog_group_commit_sync_delay 参数,表示延迟多少微秒后才调用 fsync;
binlog_group_commit_sync_no_delay_count 参数,表示累积多少次以后才调用fsync。
这两个条件是或的关系,也就是说只要有一个满足条件就会调用 fsync。
所以,当 binlog_group_commit_sync_delay 设置为 0 的时候, binlog_group_commit_sync_no_delay_count 也无效了。
之前有同学在评论区问到,WAL 机制是减少磁盘写,可是每次提交事务都要写 redo log 和 binlog,这磁盘读写次数也没变少呀?
现在你就能理解了,WAL 机制主要得益于两个方面:
- redo log 和 binlog 都是顺序写,磁盘的顺序写比随机写速度要快;
- 组提交机制,可以大幅度降低磁盘的 IOPS 消耗。
七.mysql提升IO性能
可以考虑以下三种方法:
- 设置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 参数,减少 binlog 的写盘次数。这个 方法是基于“额外的故意等待”来实现的,因此可能会增加语句的响应时间,但没有丢失数据的风险。
- 将 sync_binlog 设置为大于 1 的值(比较常见是 100~1000)。这样做的风险是,主 机掉电时会丢 binlog日志。
- 将 innodb_flush_log_at_trx_commit 设置为 2。这样做的风险是,主机掉电的时候会丢数据。
我不建议你把 innodb_flush_log_at_trx_commit 设置成 0。因为把这个参数设置成 0, 表示 redo log 只保存在没有生气啦申请的内存中,这样的话 MySQL 本身异常重启也会丢数据,风险太 大。而 redo log 写到文件系统的 page cache 的速度也是很快的,所以将这个参数设置 成 2 跟设置成 0 其实性能差不多,但这样做 MySQL 异常重启时就不会丢数据了(因为数据已经写入了磁盘中文件系统申请的内存中是操作系统维护的内存,而不是在mysql申请的内存中),相比之下风险会更小。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端