

013_生成器(yield)_列表推导式
1,生成器
只要含有yield关键字的函数都是生成器函数
yield不能和return共用且需要写在函数内
生成器函数的特点:
①调用函数之后函数不执行,返回该生成器
②每次调用__next__方法时会取到一个值
③直到取完最后一个,在执行__next__会报错
def generator(): #生成器函数
print(2)
yield 'a'
ret = generator() #调用生成器函数,但并不会执行,而是返回一个生成器及地址
print(ret) #>>><generator object generator at 0x000002582D4596D8>
2,简单生成器函数的使用
def generator():
print(2)
yield 'a' #yield与return在相同的位置,都会返回后面的值,
# 但是yield不会结束函数,return会结束函数
ret = generator()
g = ret.__next__()
print(g)

3,yield
yield作用暂停生成器函数但不结束,并将yield后面的返回到调用的地方(即使用了 “生成器.__next__()” 的地方),当再次使用 “生成器.__next__()” 时生成器函数就会从暂停位置继续执行。
4,生成器的使用
从生成器中取值的几个方法:
①__next__
②for循环
③数据类型的强制转换,但是占用内存大。如:把生成器转为列表 list(g)
def wa():
for i in range(100):
yield '娃哈哈%s'%i
g = wa()
for i in g:
print(i)
#只用其中的50个
g = wa()
count = 0
for i in g:
count += 1
print(i)
if count > 50:
break #for循环结束,生成器暂停并没有结束
# 继续索要接下来的值
print('**',g.__next__()) #随时可以索要接下来的值
5,监听文件输入的栗子:
#新输入的文本保存后才能被读取
def tail(filename):
f = open(filename,encoding='utf-8')
while True:
line = f.readline()
if line.strip():
yield line.strip()
g = tail('file')
for i in g:
print(i)
6,生成器中send()的使用
6.1,获取移动平均值
def average():
sum = 0
count = 0
avg = 0
while True:
num = yield avg
sum += num
count += 1
avg = sum/count
avg_g = average() #调用函数之后函数不执行,返回应该生成器
avg_g.__next__() #使用生成器,暂停在yield #使用send()时,第一次使用生成器必须先使用__next__()方法激活一次。
avg1 = avg_g.send(10) #使用send()发后一个值返回到上次暂停的yield,并执行__next__()的功能一次,
avg1 = avg_g.send(20) #生成器中最后一个yield不能接受外部的值
print(avg1)
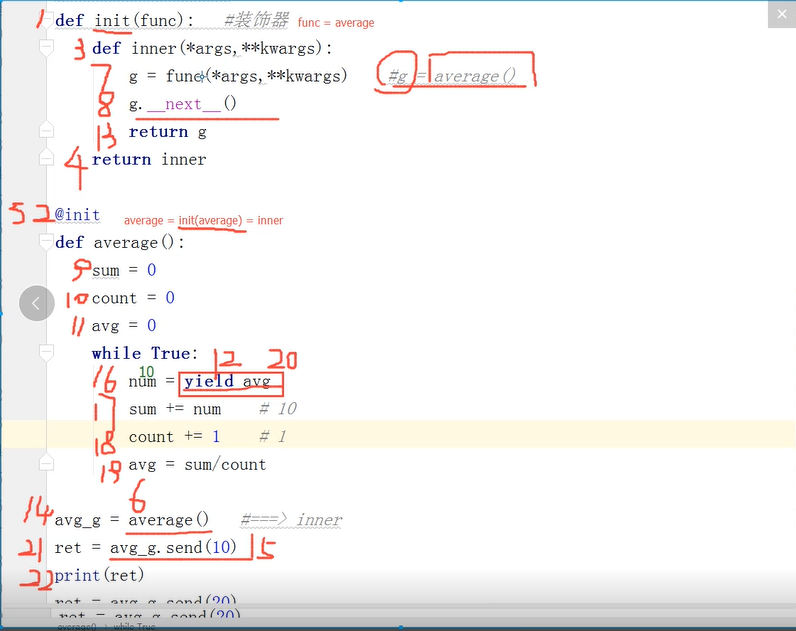
7,生成器的装饰器
def init(func):
def inner(*args,**kwargs):
g = func(*args,**kwargs)
g.__next__()
return g
return inner
@init
def average():
sum = 0
count = 0
avg = 0
while True:
num = yield avg
sum += num
count += 1
avg = sum/count
avg_g = average()
ret = avg_g.send(10)
print(ret)
8,想将分开一个一个的输出就用yield from
def generator():
a = 'abcde'
b ='12345'
yield from a
yield from b
g = generator()
for i in g:
print(i)
注意:yield from 是将yield from 后的遍历完,然后在执行其它的代码。
上例子中,先执行 yield from a 将a遍历完,让那后执行 yield from b 。
相当与下面的代码:
def generator():
a = 'abcde'
b = '12345'
for i in a:
yield i
for i in b:
yield i
g = generator()
for i in g:
print(i)
9,表达式
9.1,列表推导式
print(['鸡蛋%s'%i for i in range(10)])
结果:['鸡蛋0', '鸡蛋1', '鸡蛋2', '鸡蛋3', '鸡蛋4', '鸡蛋5', '鸡蛋6', '鸡蛋7', '鸡蛋8', '鸡蛋9']
相当于下面的代码:
egg_list = []
for i in range(10):
egg_list.append('鸡蛋%s'%i)
print(egg_list)
9.2,生成器表达式
g = (i for i in range(10))
print(g)
for i in g:
print(i)
9.3,列表推导式:
- [每个元素或者和元素相关的操作 for 元素 in 可迭代数据类型]
- [满足条件的元素相关的操作 for 元素 in 可迭代数据类型 if 元素相关条件]
9.3.1,栗子1:30以内所有能被整除的数
ret = [i for i in range(30) if i % 3 == 0]
print(ret)
9.3.2,栗子2:30以内所有能被整除的数的平方
ret = [i*i for i in range(30) if i % 3 == 0]
print(ret)
9.3.3,栗子3;找到嵌套列表中名字含有两个’e‘的所有名字
names = [['Tom','Billy','Jefferson','Steven'],['Jennifer','Eva']]
ret = [name for lst in names for name in lst if name.count('e') == 2]
print(ret)


names = [['Tom','Billy','Jefferson','Steven'],['Jennifer','Eva']] ret = [] for lst in names: for name in lst: if name.count('e') == 2: ret.append(name) print(ret)
9.4,字典推导式:
· 9.4.1,栗子1:将一个字典的key和value对调
mcase = {'a': 10, 'b': 34}
mcase_frequency = {mcase[k]: k for k in mcase}
print(mcase_frequency)
9.4.2,合并大小写对应的value值,将k统一成小写
mcase = {'a': 10, 'b': 34, 'A': 7, 'Z': 3}
mcase_frequency = {k.lower(): mcase.get(k.lower(), 0) + mcase.get(k.upper(), 0) for k in mcase.keys()}
print(mcase_frequency)
9.5,集合推导式:
9.5.1,栗子1:计算列表中每个值的平方,自带去重功能
squared = {x**2 for x in [1, -1, 2]}
print(squared)
10,练习
10.1,处理文件,用户指定要查找的文件和内容,将文件中包含要查找内容的每一行都输出到屏幕
def check_file(filename,aim):
with open(filename, encoding='utf-8') as f:
for i in f:
if aim in i:
yield i
g = check_file('文件','内容')
for i in g:
print(i.strip())
10.2,写生成器,将文件中读取内容,在每一次读取到的内容之前加上'***'之后再返回给用户。
def check_file(filename):
with open(filename,encoding='utf-8) as f:
for i in f:
yield '***'+i
for i in check_file('文件'):
print(i.strip())
10.3
def demo():
for i in range(4):
yield i
g = demo() #g,g1,g2都是生成器
g1 = (i for i in g)
g2 = (i for i in g1)
print(list(g1)) #这个时候才开始执行
print(list(g2)) #因为在执行上一句时,生成器g1,g都已经执行完了,
#所以g2就不会有值,一个生成器只能执行一次
#结果:
[0, 1, 2, 3]
[]
10.4,装饰器推导式与for的嵌套
def add(n,i):
return n+i
def test():
for i in range(4):
yield i
g = test()
for n in [1,10]:
g = (add(n,i) for i in g) #这两句等同于下面的内容
# n = 1
# g = (add(n,i) for i in g)
# n = 10
# g = (add(n,i) for i in (add(n,i) for i in test())) #此时 in g 的这个g是上一个赋值的东西
#到这为止,都还没有真正的执行,只是产生生成器
print(list(g)) #到这才开始真正的执行,且执行的结果就是上一句执行完的结果
