
中学生都喜欢什么样的老师?抓取知乎高赞回答告诉你
今天一位学校老师提了这么一个需求:想知道当前初中学生都喜欢什么样的老师,并可以用词云的方式直观展示出来。
要制作词云呢,需要有一定数量的关键词,以及权重值(或者出现频率)。而要得到这些关键词、权重值,必须要有一定量的内容信息,总不能我们自己瞎编瞎写吧~~
那今天就来和大家分享一下永恒君的整个操作过程,希望对大家能有启发和帮助。
1、获取内容信息
这一步是基础,获取的方式有很多样,但无外乎就是两类
直接内容,如给学生调查问卷,整理成稿
间接内容,如网上搜集相关资料文章、相关问答
永恒君采取的是第二种,直接从知乎上面找到相关内容的高赞回答的问题,然后将该问题的所有答案都抓取下来。

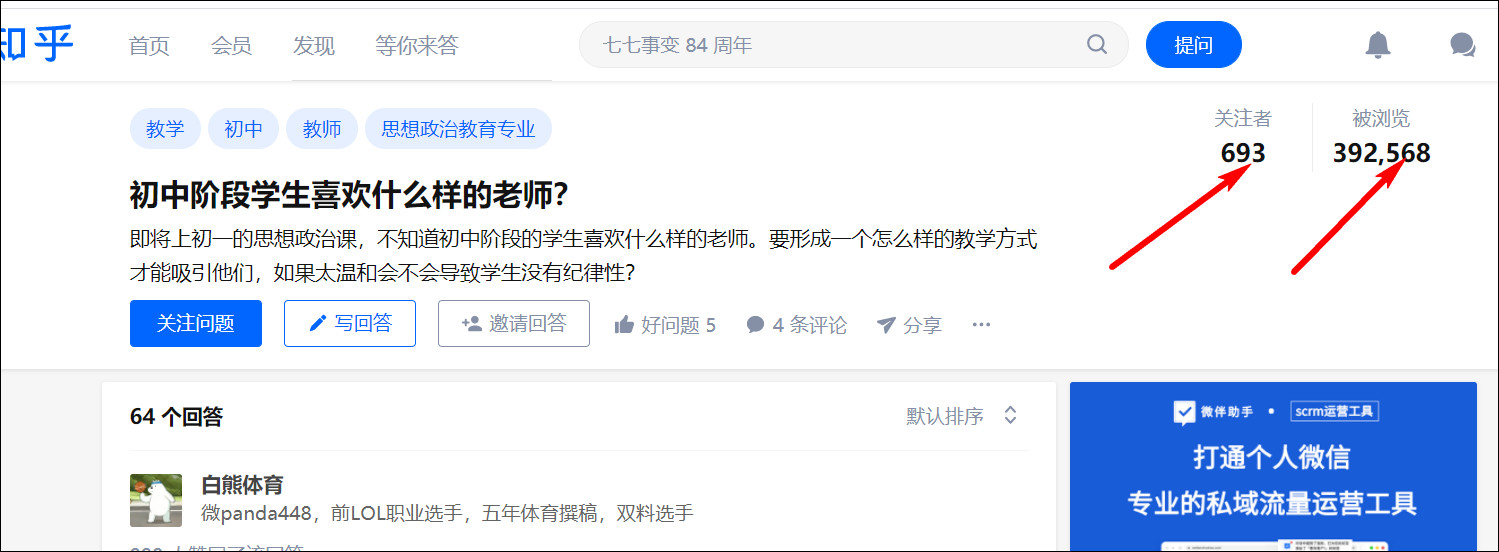
如这个问题,相关性就比较高,浏览量和回答人数也还算可以。(当然你也可以选择其他你认为更合适的问题。)
接下来就要使用我们的web scraper来抓取数据了,配置很简单,主要就是配置Element Scroll down就好了。

完整的sitemap参考这里:
{"_id":"zhihu_answers","startUrl":["https://www.zhihu.com/question/24601413"],"selectors":[{"id":"articles","type":"SelectorElementScroll","parentSelectors":["_root"],"selector":"div.List-item","multiple":true,"delay":2000},{"id":"name","type":"SelectorText","parentSelectors":["articles"],"selector":"#Popover34-toggle a","multiple":false,"regex":"","delay":0},{"id":"text","type":"SelectorText","parentSelectors":["articles"],"selector":"span[itemprop='text']","multiple":false,"regex":"","delay":0}]}
抓取到的数据,经过整理得到想要的回答内容如下:
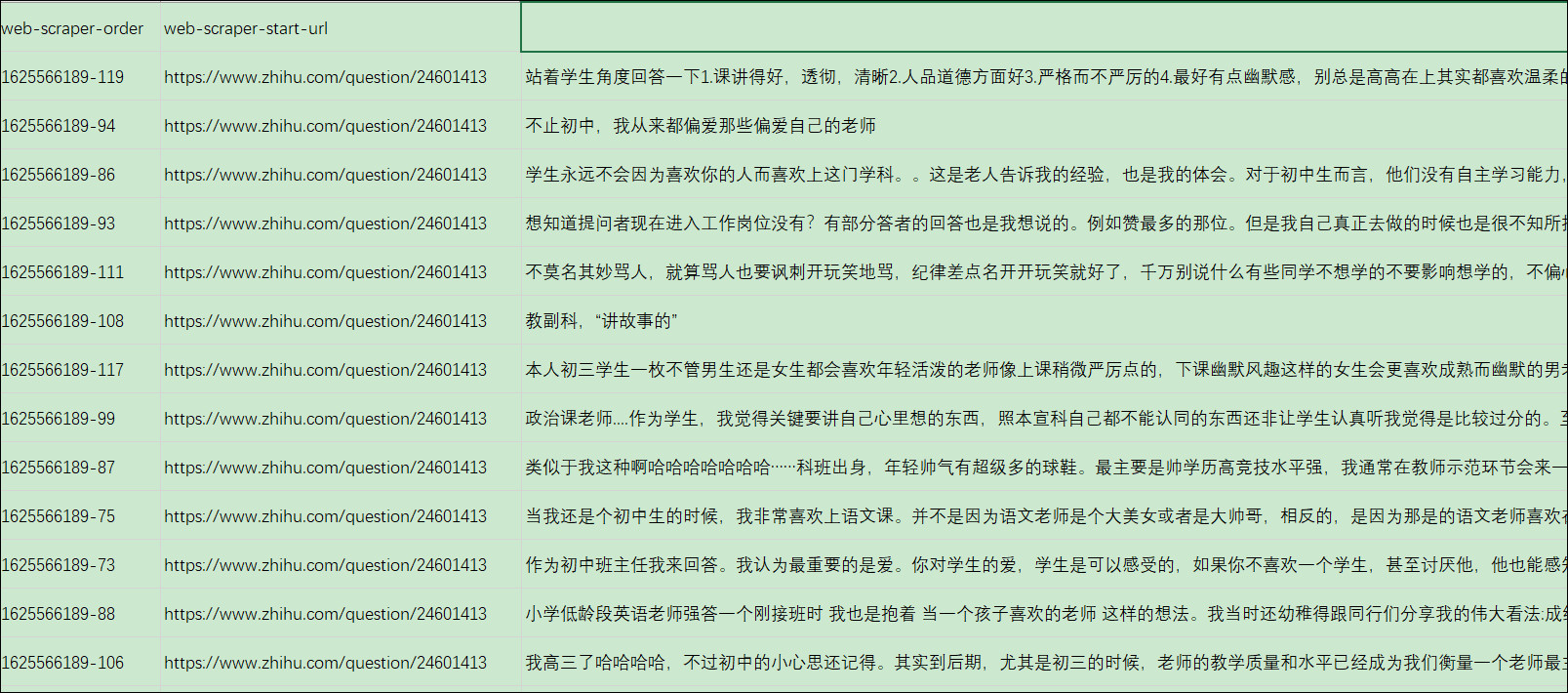
将上述抓取到的数据内容保存到goodteacher.txt备用,这样我们就得到了最重要的基础数据。
2、获取关键词和权重(词频)
这一步需要有一点编程的能力,永恒君这里使用python的jieba库,完整代码如下:
点击查看代码
##20210708 从txt文档中读取文章,自动分词,计算词频
import jieba.analyse
import numpy as np
from wordcloud import WordCloud
from PIL import Image
import pandas as pd
image= Image.open('teacher.jpg')#打开背景图
graph = np.array(image)#读取背景图
f=open('goodteacher.txt','r')
contents=f.read()
jieba.analyse.set_stop_words('stop.txt')#设置停用词
result=jieba.analyse.extract_tags(contents,topK=2000,withWeight=True,allowPOS=("a","an","ad","v"))
keywords = dict()
for i in result:
keywords[i[0]]=i[1]
print(keywords)
df=pd.DataFrame([keywords]).T.reset_index()
df.columns=['key','value']
df.to_excel("keywords.xlsx") 
提取goodteacher.txt内容的动词、形容词之后,经过简单的统计整理,生成keywords.xlsx,得到如下的结果:
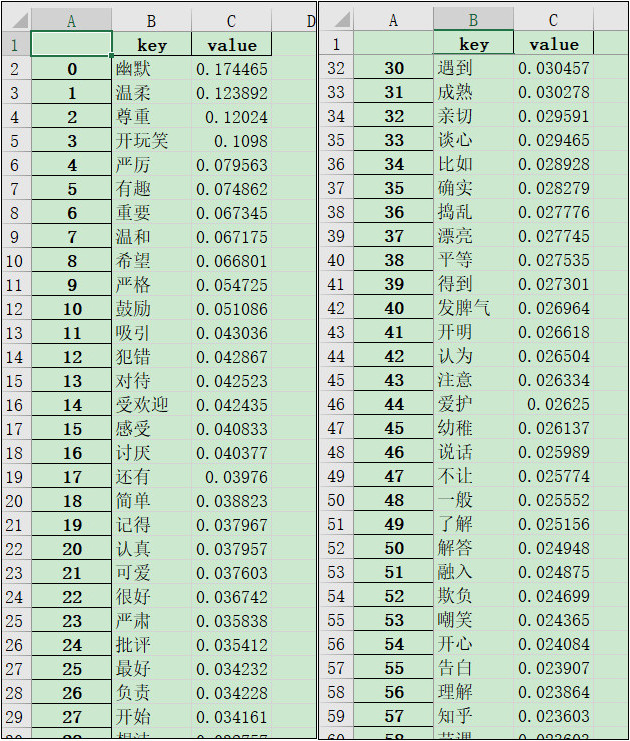
当然,这其中还包含了一些无效、或者对主题无意义的词,可以按需求进行适当的修改。
3、生成词云
有了上述的关键词文件keywords.xlsx之后,生成词云的方式就有很多了,网上能搜到许多的在线词云网站,但是一般都会有这样那样的限制,感觉不方便。
永恒君这里依然使用的是python,通过调用wordcloud库,可以非常方便的生成想要的词云,没有这样那样的限制。
完整代码:
点击查看代码
##20210708 从直接从excel中词频,生成词云
import numpy as np
from wordcloud import WordCloud
from PIL import Image
import pandas as pd
image= Image.open('teacher2.jpg')#打开背景图
graph = np.array(image)#读取背景图
df=pd.read_excel("keywords.xlsx")
keywords=df.set_index("key").to_dict()['value']
wc = WordCloud(font_path=r'C:\Windows\Fonts\simhei.ttf',
background_color='White',
max_words=1000,
width=1000,
height=500,
mask=graph,
scale=4,
)
#font_path:设置字体,max_words:出现的最多词数量
wc.generate_from_frequencies(keywords)#按词出现的频率
wc.to_file("myfavteacher.jpg")
最后生成的两种词云图如下:


可以看到,初中学生喜欢的老师大致画像是幽默、温柔、尊重人、能开玩笑、有趣等等。
其中温柔排这么前,是否说明现在的初中女老师居多呢?
你可能还会想看:
不写代码玩转爬虫实例(6) – 抓取知乎搜索的数据
用Python爬取28010条《隐秘的角落》评论,我发现了这些…
python助你快速读懂文字内心!
什么情况?python这次居然被web scraper比下去了
那些高大上的词云图,可以这样快速做!
欢迎交流!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号