
人声提取工具Spleeter安装教程(linux)
在安装之前,要确保运行Spleeter的计算机系统是64位,Spleeter不支持32位的系统。如何查看?
因为在linux环境下安装spleeter相对要简单很多,这篇教程先以Ubuntu20.04系统介绍安装教程。(在win系统下可以使用VMware虚拟机安装Ubuntu,之前永恒君也写过教程。)
在安装好Ubuntu20.04系统之后,就可以开始下面的步骤了。
安装步骤
1、下载并安装Anaconda
1-1 下载
Spleeter是基于python语言的工具,而Anaconda就是可以便捷获取python包且对包能够进行管理,同时对环境可以统一管理的发行版本,可以大大减少因为包等依赖项的问题而造成的困扰,提升效率。可以简单理解,Anaconda可以更方便的进行安装Spleeter。
进入官网https://www.anaconda.com/products/individual

选择linux - Python 3.7 - 64-Bit (x86) Installer
如果上面的网站访问慢的话,可以试试这个清华大学的镜像站https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
选择linux的即可
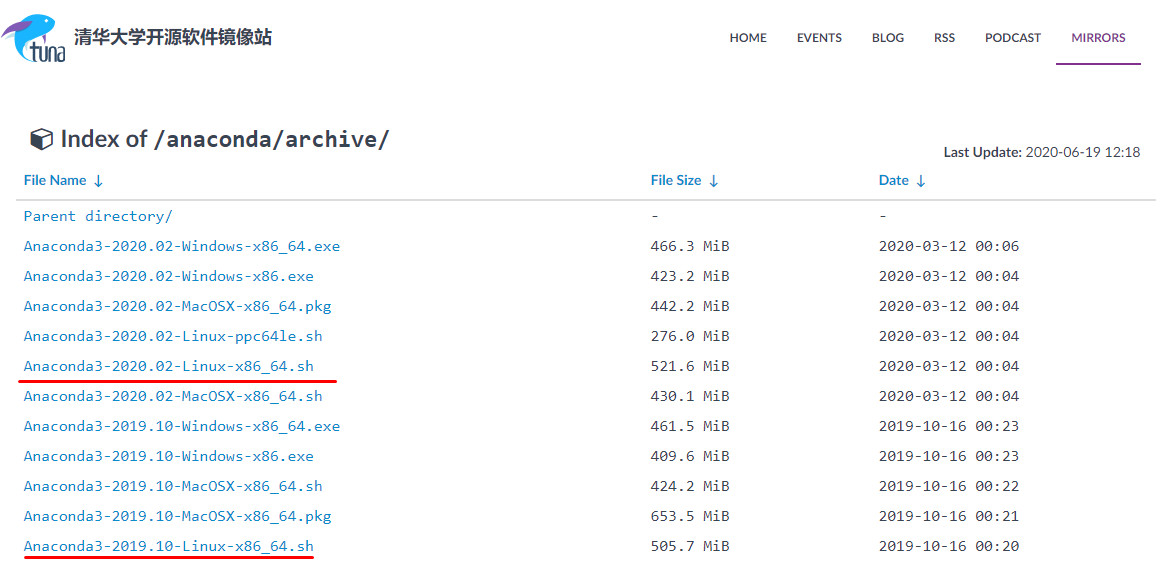
下载下来是一个以.sh结尾的文件,这个是在linux系统中的脚本文件,类似于windows系统中的.exe文件。

1-2 安装
1)在.sh所在的文件夹点击右键,打开终端,输入命令 bash + sh文件名,.sh文件名字要换成你自己的,如:
bash Anaconda3-2019.10-Linux-x86_64.sh

2)按照提示,需要看一些条款,一路回车即可。
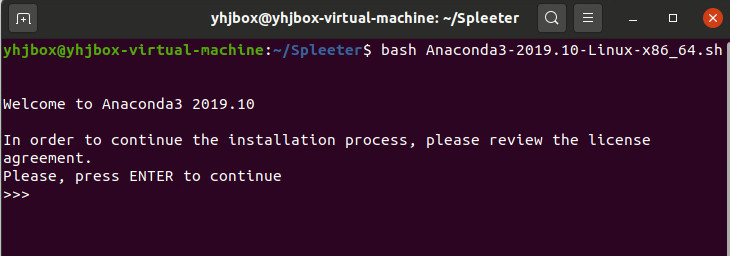
然后会问你是否同意条款,当然输入yes,不然呢?

系统提示安装的默认位置,一般直接回车即可
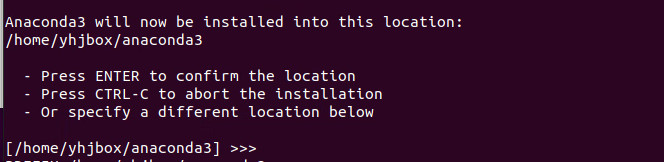
然后就进入安装的过程,稍等一会

接下来提示是否要初始化,一般输入yes

到这个界面,就说明安装成功了。

1-3 修改配置文件condarc
这样下载比较快。(因为源文件都在国外的服务器上,速度经常会不稳定)。
在终端里面输入命令:
sudo gedit ~/.condarc
或者在主目录下面,找到.condarc文件并打开

将下面的内容粘贴进去:
channels:
- defaults
show_channel_urls: true
channel_alias: https://mirrors.tuna.tsinghua.edu.cn/anaconda
default_channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud

2、安装Spleeter
2-1 建议为Spleeter创建单独的运行环境,名称取为music,并激活。(这一步非必须,可直接进行步骤2-2安装Spleeter)
为了程序的稳定性,建议先通过Anaconda创建一个环境专门用来运行Spleeter,这个永恒君命名为music,使用python3.7。
打开终端,输入
conda activate base
conda create -n music python=3.7 #创建一个python3.7的环境,名字为music

完成之后,激活music环境,终端输入
conda activate music

2-2 终端输入下面的命令,安装Spleeter,这个过程视网络情况,可能需要耐心等待一会。
conda install -c conda-forge spleeter
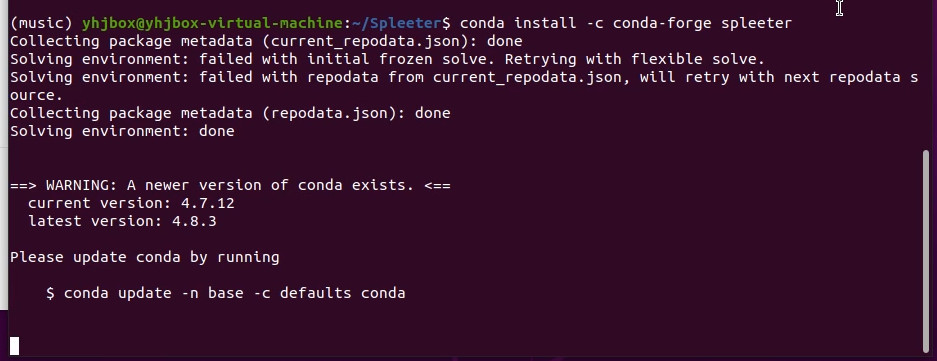
出现下面的提示,就说明安装完成了。

3、下载训练模型(一定要注意存放的路径)
第一次分离音轨前需要给Spleeter一个“示范”,需要有个pretrained models(预训练模块)。
下载地址:
https://github.com/deezer/spleeter/releases

下载图上2stems,分离人声的话一般只需要2轨即可。
在主目录下面新建pretrained_models\2stems路径文件夹,将下载的模型文件解压到文件夹里面。
如果你使用的是4stems、5stems,则要相对应的在pretrained_models文件夹下面建立4stems、5stems文件夹。
4、分离提取人声
把需要分离的原始音乐文件 ppxhn.mp3 放在主目录,然后终端键入命令运行:
spleeter separate -i ppxhn.mp3 -p spleeter:2stems -o output
使用的是4stems、5stems的话,只需要把上面命令2stems改成4stems或者5stems即可。
出现下面的字样就说明提取成功了,在主目录下面会生成一个output\ppxhn的文件夹


accompaniment.wav是提取的背景
vocals.wav是提取的人声

小结一下
1、安装Anaconda,修改配置文件condarc。
2、安装Spleeter
3、下载训练模型
4、分离提取人声
其它问题:
1、32位win系统无法使用,64位系统可以使用,建议搭配64位的Python程序或者Anaconda。
2、模型文件始终下载不下来,手动下载并放置到指定文件夹
模型下载地址:https://github.com/deezer/spleeter/releases
特别地,一般模型下载很慢而且不容易成功完成,可以建议使用GitHub文件加速下载地址转换:https://shrill-pond-3e81.hunsh.workers.dev/
转换后使用idm等下载即可。
下载成功后在主目录下依次建立文件夹 pretrained_models\2stems,将2stems.tar.gz解压缩后放置到这个文件夹中即可。
类似地也可建立文件夹并放置模型文件:
pretrained_models\2stems-finetune
pretrained_models\4stems
pretrained_models\4stems-finetune
pretrained_models\5stems
pretrained_models\5stems-finetune
-finetune这种是更为精确的高质量模型,使用方法也一样。
3、拆分类型选项
4stems、4stems、5stems三种分别对应分成2轨、4轨和5轨
人声(歌声)、伴奏分离 (2个音轨)
人声、鼓、贝斯、其他分离 (4个音轨)
人声、鼓、贝斯、钢琴、其他分离 (5个音轨)
4、支持的音频文件有mp3、wav、ogg
5、一次分离多个文件(比较费资源,不推荐)
spleeter separate \
-i <path/to/audio1.mp3> <path/to/audio2.wav> <path/to/audio3.ogg> \
-o audio_output

 浙公网安备 33010602011771号
浙公网安备 33010602011771号