

web scraper无法解决爬虫问题?通通可以交给python!
今天一位粉丝的需求所涉及的问题值得和大家分享分享~~~
背景问题
是这样的,他看了公号里的关于web scraper的系列文章后,希望用它来爬取一个网站搜索关键词后的文章标题和链接,如下图

按照教程,复制网页地址、写选择器、运行调试,发现无论怎样修改都无法提取到任何的信息。
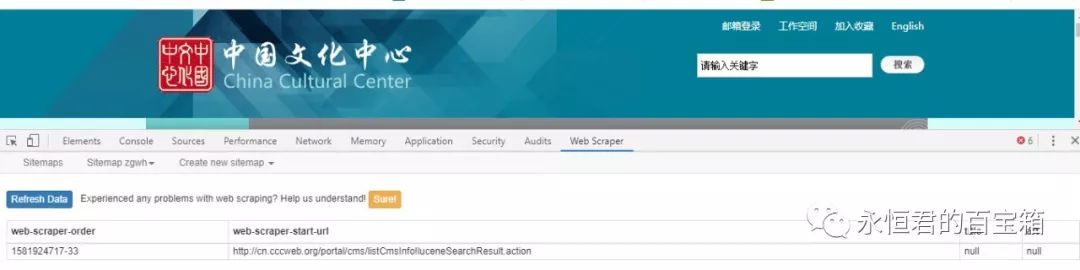
问题分析
这个网站网址是:
http://cn.cccweb.org/portal/cms/listCmsInfo!luceneSearchResult.action
通过观察发现一些特征:
1、无论你点击那一页,这个网址都是一样的。
2、当你把这个网址复制到新的标签页里打开是,发现是空白的内容。

也就意味着这个网址搜索的时候提交的关键词等参数不会在地址栏当中显示,通过burp抓包也证实了我的猜测,是post请求。

那这样的话,web scraper是无法处理、爬取这类网址不变的页面。
那就没法爬了吗?
No!!!这不是还有万能的python啊

问题解决
简单上手的话,就用python+selenium库来搞定好了。。之前也写过文章介绍过:python实现浏览器自动化操作
selenium是一个用来自动化测试的庞大家族。

python中的selenium库可以简单理解为借助计算机来模拟人工的一些操作,借助这个我们可以实现让浏览器模拟我们人类,打开浏览器和网址,搜索关键词,提取并保存数据。
基本用法如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('http://www.baidu.com/')#打开百度
print(browser.title)#打印标题
browser.quit() #退出
以及
browser.find_element_by_id("searchContents").click()#点击搜索栏
browser.find_element_by_id("searchContents").send_keys("法国")#输入法国
browser.find_element_by_name("submit1").click()#点击搜索
browser.find_element_by_link_text("下一页>>").click()#点击下一页
使用效果如下:

最后保存的数据文件效果如下:

小结一下
1、web scraper爬虫工具小巧简单方便,但是功能有限,遇到像上面这种网址不变的情况,就不适用了。
2、python的selenium库,模拟操作浏览器、鼠标、键盘等爬取数据,简单直观。
3、爬虫入门python最适合不过了。
你可能还会想看:
爬虫系列教程: python爬虫系列(5)- 看了这篇文章你也可以一键下载网络小说 python爬虫系列(4)- 提取网页数据(正则表达式、bs4、xpath) python爬虫系列(3)- 网页数据解析(bs4、lxml、Json库) python爬虫系列(2)- requests库基本使用 python爬虫系列(1)- 概述
python实例: python帮你定制批量获取你想要的信息 python帮你定制批量获取智联招聘的信息 用python定制网页跟踪神器,有信息更新第一时间通知你(附视频演示) 用python助你一键下载在线小说 教你制作一个微信机器人陪你聊天,只要几行代码 Google图片搜索出了大量满意图片,批量下载它们! 带你看看不一样的微信!
Web Scraper系列教程: Web Scraper 使用教程(一)- 安装 Web Scraper 使用教程(二)- 基本用法之安装、配置、运行 Web Scraper 使用教程(三)- 基本用法(常用选择器类型) Web Scraper 使用教程(四)- 进阶用法(同一个页面爬取多个类型内容) Web Scraper 使用教程(五)- 进阶用法(爬取向下滚动加载页面) Web Scraper 使用教程(六)- 进阶用法(网址有规律变化进行翻页) Web Scraper 使用教程(七)- 进阶用法(点击「翻页器」进行翻页)
欢迎交流!

