SpringBoot集成Jpa对数据进行排序、分页、条件查询和过滤
之前介绍了SpringBoot集成Jpa的简单使用,接下来介绍一下使用Jpa连接数据库对数据进行排序、分页、条件查询和过滤操作。首先创建Springboot工程并已经继承JPA依赖,如果不知道可以查看我的另一篇文进行学习,这里不做介绍。文章地址(https://www.cnblogs.com/eternality/p/17391141.html)
1、排序查询
通过findAll方法的Sort类进行排序,根据实体类字段进行排序。descending降序,ascending升序,默认不填为ascending升序。
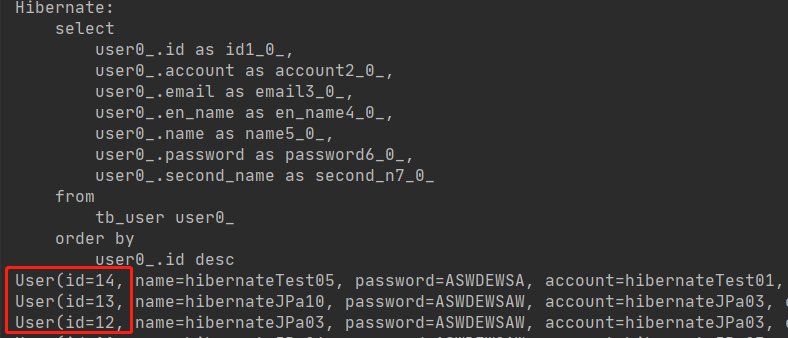
List<User> mapperAll = userMapper.findAll(Sort.by("id").descending());
mapperAll.forEach(System.out::println);
查询结果:
![]()
Sort.by() 里面是一个可变参数,可以传入一个或多个值。
//先根据状态进行排序,然后在根据ID进行排序 List<User> statusAll = userMapper.findAll(Sort.by("status","id").descending()); statusAll.forEach(System.out::println);

设置第一个属性降序,第二个属性升序
Sort sort = Sort.by("status").descending().and(Sort.by("id").ascending());
List<User> diffOb= userMapper.findAll(sort);
diffOb.forEach(System.out::println);
如果传入的字段信息,实体类中没有,代码访问会报错。如:
List<User> exceptionAll = userMapper.findAll(Sort.by("en_name").descending());
exceptionAll.forEach(System.out::println);
会报找不到该字段信息异常:
org.springframework.data.mapping.PropertyReferenceException: No property en found for type User! Did you mean 'id'?
2、分页查询
JPA为我们提供了分页的方法,我们可以查看接口集成的JpaRepository接口的关系图。发现有一个PagingAndSortingRepository接口。
![]()
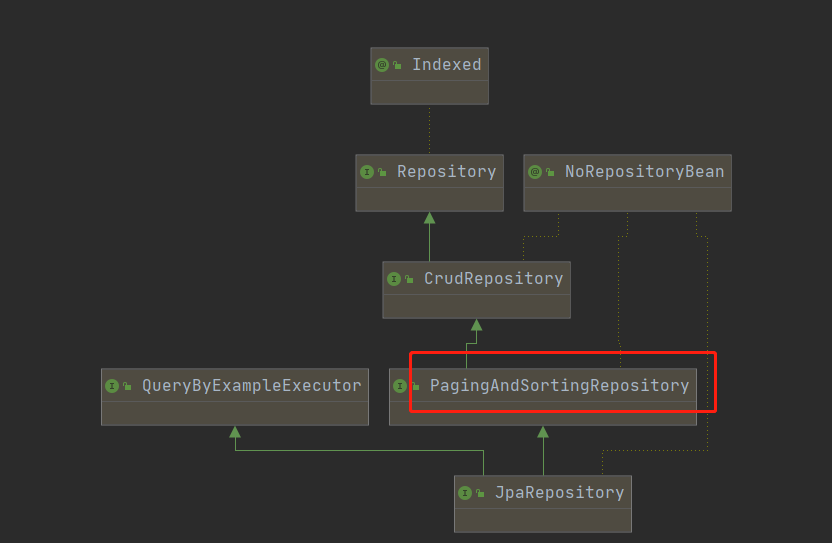
点击该接口进行查看:

使用这个接口方法就可以实现分页查询了。我们发现这个方法需要传入一个Pageable,点击Pageable查看发现它也是一个接口我们点击查看它的实现类。

使用PageRequest类就可以实现分页了,PageRequest有个静态的of方法,page参数为显示当前页数,size为显示当前显示多少数据.
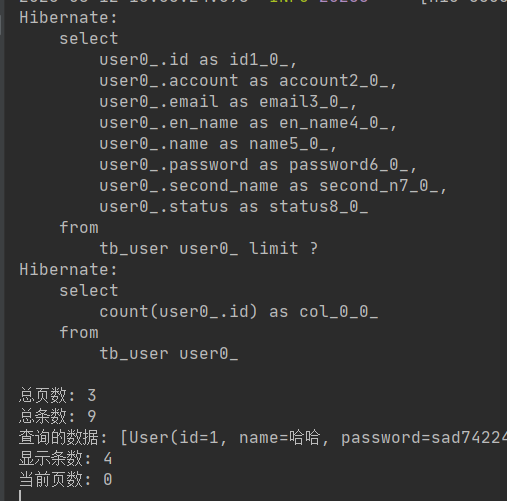
//第一页,显示4条数据 0为一页 1为二页 输入页数大于总页数则输出内容为空 PageRequest request = PageRequest.of(0, 4); Page<User> userPage = userMapper.findAll(request); System.out.println(); System.out.println("总页数: "+userPage.getTotalPages()); //总页数 System.out.println("总条数: "+userPage.getTotalElements()); //总条数 System.out.println("查询的数据: "+userPage.getContent());//查询的数据 System.out.println("显示条数: "+userPage.getSize()); //显示条数 System.out.println("当前页数: "+Integer.valueOf(Integer.valueOf(userPage.getNumber())+1)); //当前页数
查询结果为:
还可以给分页查询进行排序,根据主键进行降序排序
PageRequest pageRequest = PageRequest.of(0, 4, Sort.by("id").descending());
Page<User> orderPAge = userMapper.findAll(pageRequest);
System.out.println("查询的数据: "+orderPAge.getContent());//查询的数据
orderPAge.getContent().forEach(System.out::println);
分页进行多个字段的排序同一排序
PageRequest pageRequest1 = PageRequest.of(0, 4, Sort.Direction.DESC, "status","id"); Page<User> orde = userMapper.findAll(pageRequest1); System.out.println("查询的数据: "+orde.getContent());//查询的数据 orde.getContent().forEach(System.out::println);
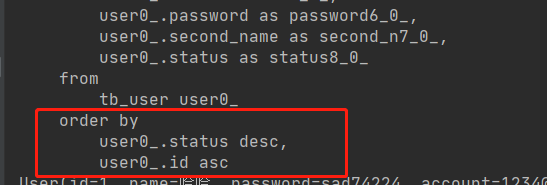
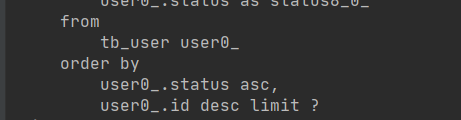
分页进行多个字段的不同排序 根据status 升序,id降序排序
PageRequest of = PageRequest.of(0, 4, Sort.by("status").ascending().and(Sort.by("id").descending()));
Page<User> ord = userMapper.findAll(of);
ord.getContent().forEach(System.out::println);
查看查询输出sql结果:
3、条件查询
下面我们来看使用JPA进行条件查询。在JPA中JPA使用findBy方法自定义查询。也可以使用findAllBy。这两个没有区别实际上还是使用的finBy...进行查询的。
//根据账号名称进行查询,有信息放回该条数据,没有查询到则放回null,如果查询多条数据则会报错 User user=userMapper.findByAccount("hibernateTest");
//Dao层
User findByAccount(String account);
如果查询多条会报错javax.persistence.NonUniqueResultException: query did not return a unique result: 4,把接收参数改为List,就可以查询多条数据了。
List<User> findByAccount(String account);
findBy后面还可以支持多种关键词进行查询:
And:等价于SQL中的 and 关键字, findByAccountAndPassword(String account, String password);
And:等价于SQL中的 and 关键字,findByAccountAndPassword(String account, String password);
Or:等价于SQL中的 or 关键字, findByAccountOrName(String account, String name);
Between:等价于SQL中的 between 关键字,findByIdBetween(int min, int max);
LessThan:等价于 SQL 中的 "<",findByIdLessThan(int id);
GreaterThan:等价于 SQL 中的">",findByIdGreaterThan(int id);
IsNull:等价于 SQL 中的 "is null",findByNameIsNull();
IsNotNull:等价于 SQL 中的 "is not null",findByNameIsNotNull();NotNull:与 IsNotNull 等价;
Like:等价于 SQL 中的 "like",findByNameLike(String name);这样传值需要加 %name%,可以使用Containing,这个方法会在字符串两边都加上%,
除此之外还有StartingWith 和EndingWith,分别为 ?%,%?
NotLike:等价于 SQL 中的 "not like",findByNameNotLike(String name);传值需要加 %name%
Not:等价于 SQL 中的 "!=",findByUsernameNot(String user);
OrderBy:等价于 SQL 中的 "order by",findByNameOrderByStatusAsc(String name);
In:等价于 SQL 中的 "in",findByIdIn(Collection userIdList) ,方法的参数可以是 Collection 类型,也可以是数组或者不定长参数;
NotIn:等价于 SQL 中的 "not in",findByNameNotIn(Collection userList) ,方法的参数可以是 Collection 类型,也可以是数组或者不定长参数;
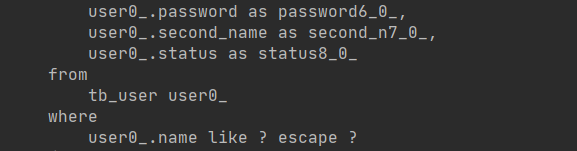
这里介绍一下模糊查询使用方法:
List<User> userList2=userMapper.findByNameLike("%hibernateTest%");
userList2.forEach(System.out::println);
List<User> userList3=userMapper.findByNameContaining("hibernateTest");
userList3.forEach(System.out::println);
//dao层
List<User> findByNameLike(String name);
List<User> findByNameContaining(String name);
![]()
上面的findBy规则介绍完毕后,接下来我们结合上面的分页和排序,查询出过滤后的数据。条件+分页+排序查询使用:
Page<User> userPage = userMapper.findByNameLike("%hibernateJPa%", PageRequest.of(0, 2, Sort.by("id").descending()));
System.out.println("总页数: "+userPage.getTotalPages()); //总页数
System.out.println("总条数: "+userPage.getTotalElements()); //总条数
System.out.println("查询的数据: "+userPage.getContent());//查询的数据
System.out.println("显示条数: "+userPage.getSize()); //显示条数
System.out.println("当前页数: "+Integer.valueOf(Integer.valueOf(userPage.getNumber())+1)); //当前页数
//dao层
Page<User> findByNameLike(String name, Pageable pageable);
查询结果:

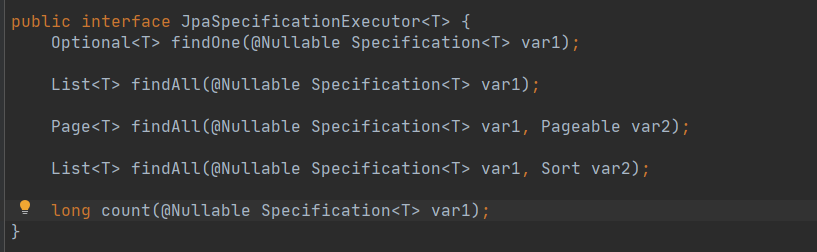
使用JPA进行查询、排序和分页我们就介绍完毕了。关于JPA后面还有复杂的sql条件查询,需要继承JpaSpecificationExecutor接口。JpaSpecificationExecutor接口方法不多但是很好用,推荐大家有时间可以学习一下。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号