Continue+LLM打造本地运行的Copilot服务
简介
GitHub Copilot 已经出来很长时间了。该服务收费且在国内连接不够稳定,延迟也比较高。目前大语言模型生态蓬勃发展,已经诞生了一批专精于代码生成的大模型,例如:
- https://huggingface.co/mistralai/Codestral-22B-v0.1
- https://huggingface.co/mistralai/Mamba-Codestral-7B-v0.1
- https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-base
- https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-base
- https://huggingface.co/deepseek-ai/deepseek-coder-33b-base
- https://huggingface.co/bigcode/starcoder2-3b
- https://huggingface.co/Qwen/CodeQwen1.5-7B
而 Continue 这个扩展能够接入各类大模型的 API,提供编辑器内的代码分析和补全功能。本文将简单介绍使用 vLLM 部署 Codestral-22B 模型并使用 Continue 接入服务的步骤。
模型部署
我们此次选择的是来自这个链接的 GPTQ 量化版本。该版本的模型在推理时需要大约显存。
找一处空闲空间足够大的地方下载该模型,下载方法可以参考这篇文章。需要大约 12 GB 的空闲空间来容纳 INT4 量化的模型权重。
新建一个虚拟环境,并安装 vllm 包:
pip install vllm
其他依赖应当会自动安装。
然后,可以使用以下命令来启动一个 OpenAI 风格的 API 服务:
vllm serve ./Codestral-22B-v0.1-FIM-Fix-GPTQ \
--host 127.0.0.1 \
--port 6006 \
--served-model-name Codestral-22B \
--api-key xxxx \
--max_model_len 16384 \
--quantization gptq
其中 Codestral-22B-v0.1-FIM-Fix-GPTQ 是存放下载好的模型权重的目录。端口可以根据自己的需要进行修改。API key 可以是任意字符串。
预计运行此模型需要不少于 16 GB 的显存。
Continue 配置
Continue 目前支持 VS Code 和 JetBrains 系列 IDE。本文以相对比较成熟的 VS Code 的扩展为例进行说明。
在 VS Code 中安装 Continue 扩展。在安装之后,你的用户主目录中会自动生成一个 .continue 目录,其中存放了必要的配置文件。可以按照如下的模式配置其中的 config.json:
{
"models": [
{
"title": "gpt-4o-mini",
"provider": "openai",
"model": "gpt-4o-mini",
"apiKey": "sk-xxxxxx",
"apiBase": "https://api.openai.com/v1"
}
],
"customCommands": [
// 略
],
"tabAutocompleteModel": {
"model": "Codestral-22B",
"title": "vLLM-Completion",
"apiBase": "http://127.0.0.1:6006/v1",
"provider": "openai",
"apiKey": "xxxx"
},
"contextProviders": [
// 略
],
"slashCommands": [
// 略
]
}
其中,models 中存放了 Continue 扩展的对话模型。你可以将代码作为上下文附加到对话框,并与这里面的模型进行对话。此处的模型可以选择任意的通用大语言模型。详见 此处。
而 tabAutocompleteModel 就是代码自动补全使用的模型了。在这里我们使用刚刚通过 vLLM 部署的 Codestral-22B 模型。保存配置之后,代码自动补全应当立即开始工作,补全的延迟可能取决于推理使用的 GPU 算力。
现有的 CPU 性能不足以支持该模型接近实时地响应请求,而这对于代码的自动补全是至关重要的。因此 GPU 是必要的。
使用
对话的使用
选中一段代码后,按下 Ctrl+L 可以将代码附加到对话的上下文并向模型提问。
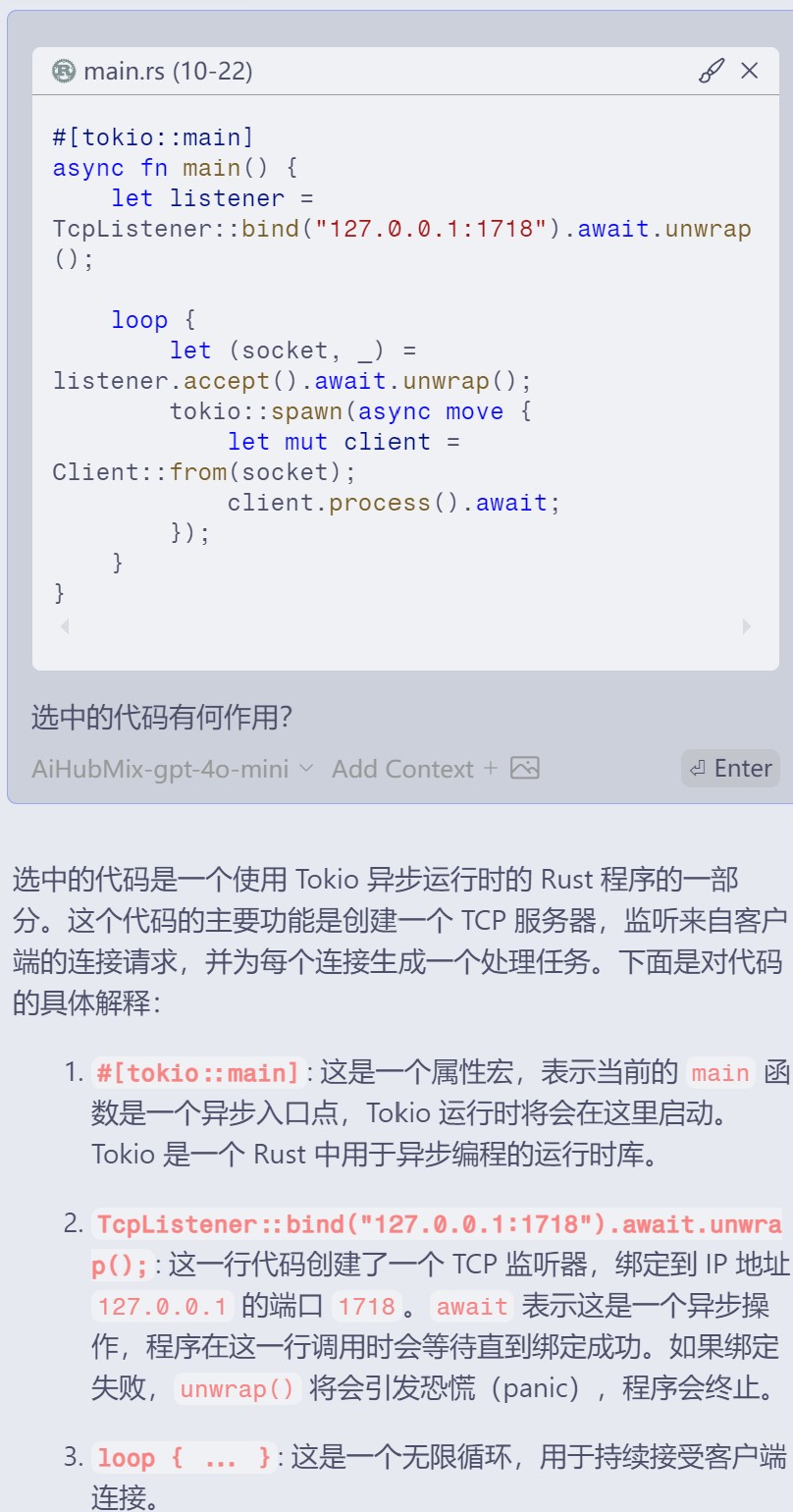
完整回答:
选中的代码是一个使用 Tokio 异步运行时的 Rust 程序的一部分。这个代码的主要功能是创建一个 TCP 服务器,监听来自客户端的连接请求,并为每个连接生成一个处理任务。下面是对代码的具体解释:
#[tokio::main]: 这是一个属性宏,表示当前的main函数是一个异步入口点,Tokio 运行时将会在这里启动。Tokio 是一个 Rust 中用于异步编程的运行时库。
TcpListener::bind("127.0.0.1:1718").await.unwrap();: 这一行代码创建了一个 TCP 监听器,绑定到 IP 地址127.0.0.1的端口1718。await表示这是一个异步操作,程序在这一行调用时会等待直到绑定成功。如果绑定失败,unwrap()将会引发恐慌(panic),程序会终止。
loop { ... }: 这是一个无限循环,用于持续接受客户端连接。
let (socket, _) = listener.accept().await.unwrap();: 这行代码在循环中等待客户端连接。一旦有连接到来,它会接受该连接,并返回一个 TCP 套接字(socket)和客户端的地址(用_忽略)。同样,await表示这是一个异步操作。
tokio::spawn(async move { ... });: 这个函数会启动一个新的异步任务。新任务是通过async move创建的,这意味着它会捕获并移动(own)在其环境中使用的变量。在这里,它将捕获socket变量,做到为每个客户端连接创建一个独立的处理。
let mut client = Client::from(socket);: 在新的异步任务中,创建了一个Client实例,它使用刚刚接受的socket。假定Client::from是一种将套接字转换为Client对象的方式。
client.process().await;: 这里调用Client实例的方法process(), 这个方法可能会处理与客户端的交互。await表示在process方法的异步操作完成之前,任务不会继续执行。总的来说,这段代码实现了一个简单的异步 TCP 服务器,能够同时处理多个客户端连接。每当有新的连接到来,它就会为该连接创建一个新的
Client处理实例,允许服务器进行高效的并发处理。
这种显式附加上下文的操作方法,我个人认为要比 Copilot 好一点。
Tab 自动补全的使用
使用方法和 Copilot 类似,通过 Tab 键来同意扩展给出的代码建议。
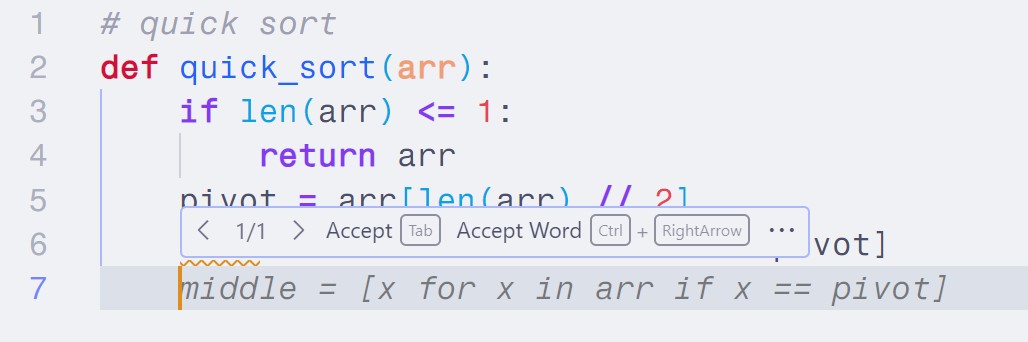
Codestral-22B 的表现当然不如 Copilot。此外,Continue 插件的 Tab 自动补全功能还处于开放的早期,目前使用下来也遇到一些 bug。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号