

Quantitative Method 6
R6:Hypothesis Testing
Ⅰ、Concepts in Hypothesis Testing:假设检验的一些概念
1、Hypothesis Testing:假设检验




假设检验用于双重检查从样本估计的总体参数值。
这是一个典型的“反证”过程
首先对总体做出某种假设性陈述,然后通过对样本统计数据的测试来证明它是错误的

2、Null / Alternative Hypotheses:原假设和备择假设

原假设(H0)是要检验的假设。 这是我们想要通过检验来拒绝的假设 它总是包含等号(=/≥/≤) H0:全球股市平均回报率=10% H0:平均身高≥170cm 备择假设(Ha)与原假设相反。 这是我们想要接受的假设 它不包括等号(≠/</>) Ha:全球股市平均回报率≠10%(双向) Ha:平均身高<170cm(单向)

单向检验反映了研究员对检验结果已经有了一个明确的预判

3、Test Statistics:检验统计量

检验统计量是基于样本计算的数量,其值是决定是否拒绝原假设的基础。
4、Significance Level(α):显著水平
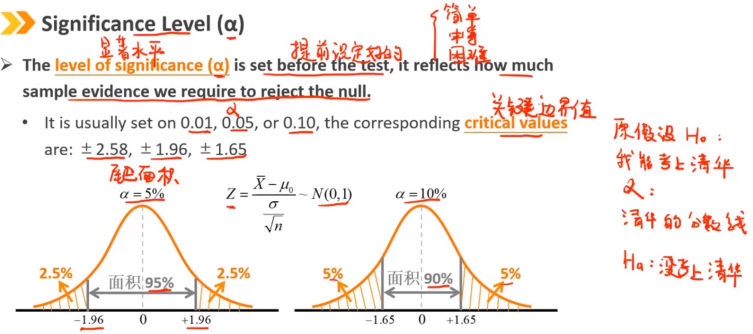
显著性水平(α)在检验之前设置的,它反映了我们需要多少样本证据来拒绝原假设。 通常设置为0.01、0.05或0.10,相应的临界值为:±2.58、±1.96、±1.65
5、Two-tailed Test / One-tailed Test:双尾检验和单尾检验


α越高,越容易拒绝原假设,接受备择假设

单尾监测,统计量的符号方向与备择假设的符号方向相同

6、Type Ⅰ Error / Type Ⅱ Error:Ⅰ类错误和Ⅱ类错误

Ⅰ类错误的出现是我们拒绝了一个为真的原假设(原假设是真的,但是我们拒绝了) Ⅱ类错误的出现是我们无法拒绝一个为假的原假设(原假设是假的,但是我们无法拒绝) 原假设为True时,对应的是α和1-α 原假设为False时,对应的是β和1-β

犯Ⅰ类错误的概率记为α,它等于显著水平。 犯Ⅱ类错误的概率记为β: (1-β)叫做检验力,它是当原假设为假时,拒绝了原假设的概率 β的值很难计算,但是α和β成反向关系 α↓—>减少犯Ⅰ类错误的概率—>增加犯Ⅱ类错误的概率—>β↑
7、p-value Decision Rules:p值判定原则

p值是原假设能被拒绝的最小显著水平 p值是检验统计量对应的尾巴面积 如果p值<α,拒绝原假设;如果p值≥α,不能拒绝原假设 p值可以提供更精准的信息和更有力的信心拒绝原假设 p值不区分单双尾

8、Statistical Significance:统计显著

统计检验结论: 如果拒绝原假设,我们称该结果在统计上显著 经济/投资结论: 统计显著不代表经济显著,因为现实中存在交易成本、税负、风险
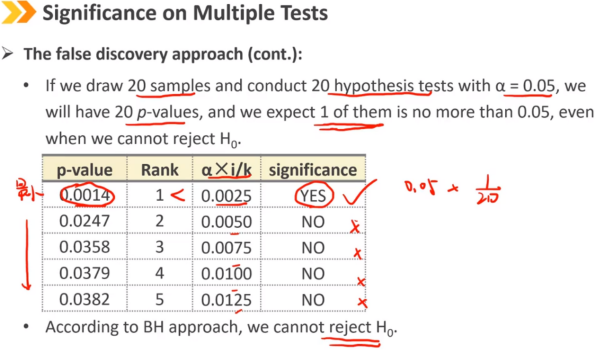
9、Significance on Multiple Tests:显著性的多次检验


Ⅱ、Tests Concerning Mean:关于均值的检验

关于单个总体均值的检验:用z检验或t检验


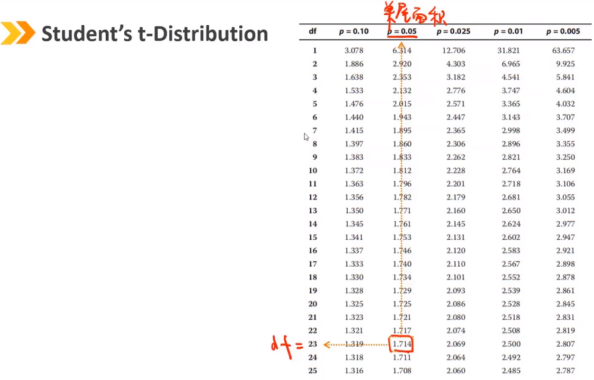

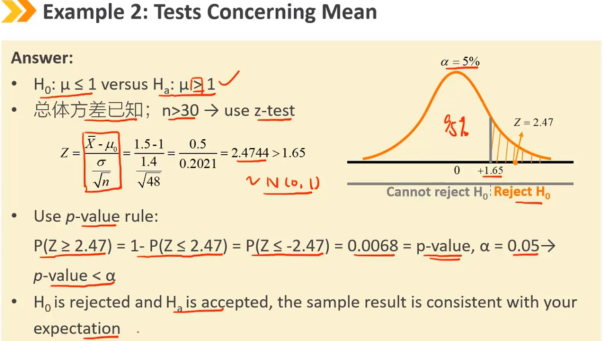

为了检验两个总体之间的平均值是否存在显著差异,我们通常使用t检验。
当总体近似满足正态分布,且样本彼此独立时,我们对均值之间的差进行检验。
先统计,后比较

如果两个总体的方差未知,假设它们相等的情况(例如来自同一个市场,不同时期的收益)
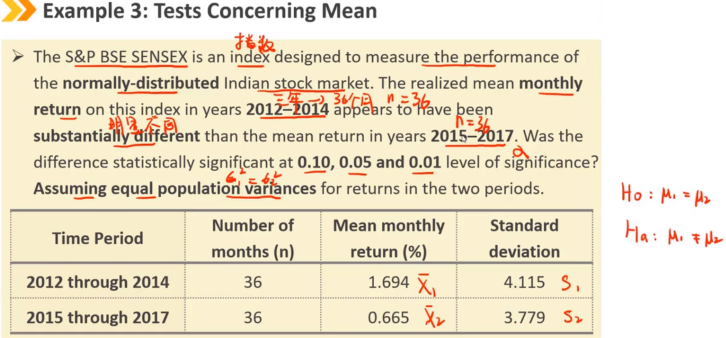

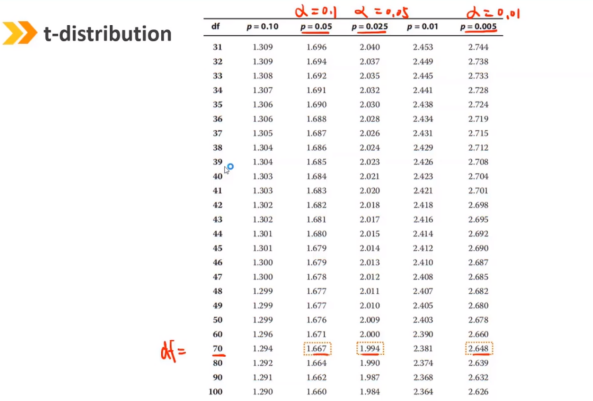

如果两个总体的方差未知,假设它们不相等的情况

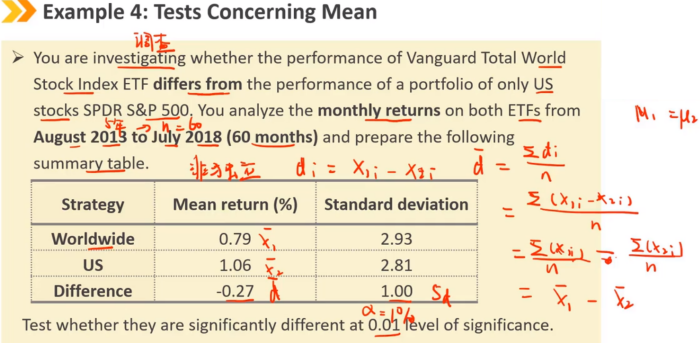
当两个总体近似满足正态分布,且样本之间不独立时,我们对均值差进行检验。
这里的t检验称为配对比较检验。
先比较,后统计,d是新样本数据,使用单个均值的t检验


Summary:

Ⅲ、Tests Concerning Variance:关于方差的检验
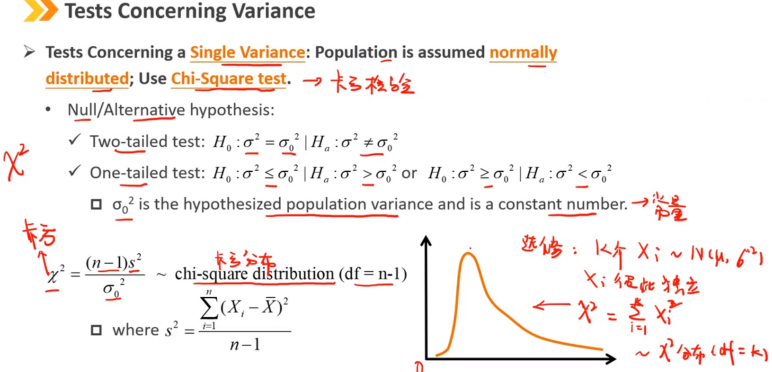
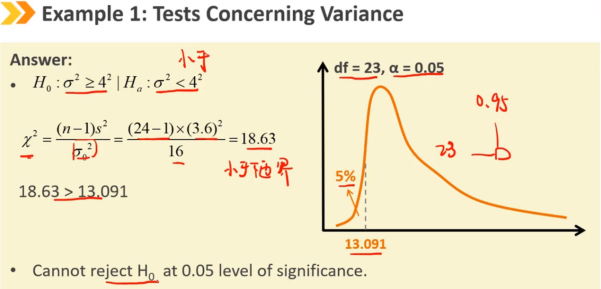
关于单个方差的检验,假设总体满足正态分布,使用卡方检验

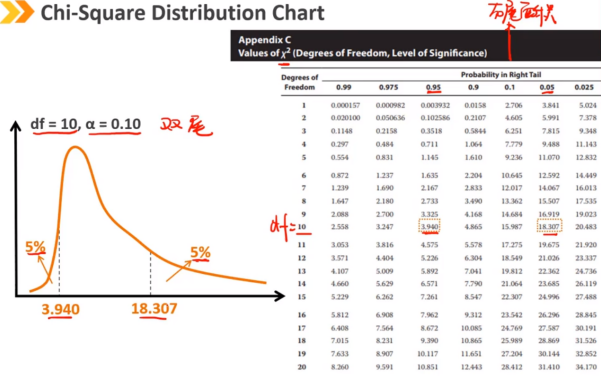


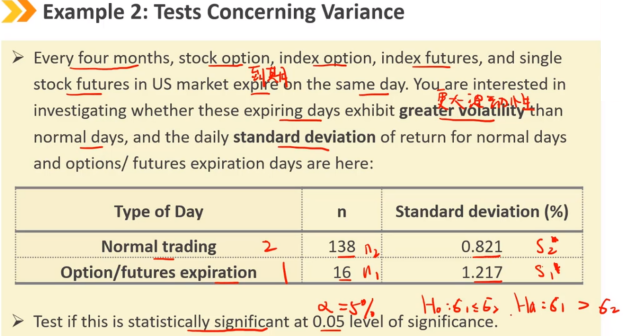
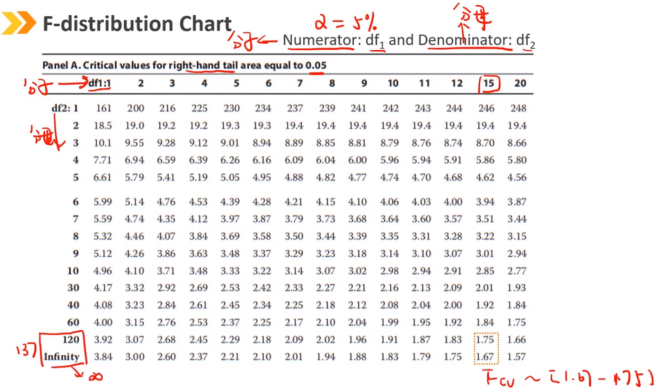
关于两个总体的方差检验,假设总体都满足正态分布,使用F检验
F检验永远使用较大的样本方差除以较小的样本方差
只需要看右侧的临界值即可,因为左边的临界值取不到

Summary:

Ⅳ、Parametric vs. Non-parametric Tests:参数检验和非参数检验

参数检验有两个特点:
它们与参数有关
它们的有效性取决于一组确定的假设
均值检验时,假设整体满足正态分布
非参数检验:
与参数无关或对总体进行最少的假设

使用非参数检验的情况: 1、数据不满足分布假设 总体的分布情况未知 2、存在极端值 对中位数使用非参数检验替代对均值的检验 3、数据是序数 4、原假设和备择假设不是关于参数的 原假设:某个策略是能带来最高年收益率的

Ⅴ、Tests Concerning Correlation:关于相关系数的检验

通过检验两个变量的相关系数显著不等于0来评估它们之间的线性关系的程度
参数检验:皮尔森相关系数检验



非参数检验:斯皮尔曼相关系数检验 样本数据排序: 将数据从最大值排序到最小值,最大值为1,第二大值为2; 当值相等时,排名=平均数(如果第二大值和第三大值相等,则两者的秩均为1.5) 设d为每对数据排名之间的差 样本容量为n的斯皮尔曼相关系数公式如下:
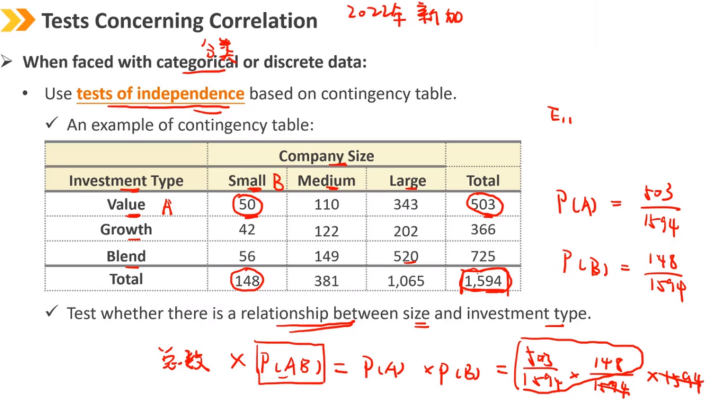
当面对分类或离散数据时:
使用基于列联表的独立性检验
例如:检验公司规模和投资策略之间的关系

Oij是表中观察值,Eij是假设两个变量独立时的共同发生概率
原假设是变量之间独立,independent
拒绝域是单侧检验


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」