

Pandas之数据分析
-
一、常用聚合函数
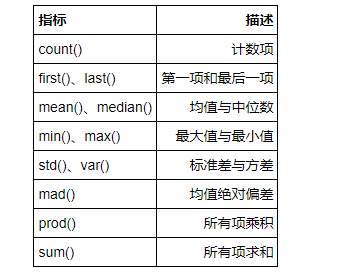
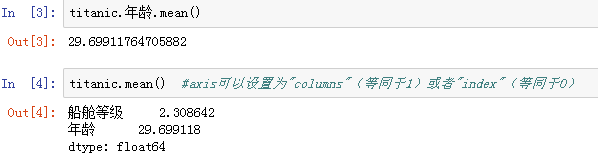
-
二、groupby分组
-
1、分组与聚合
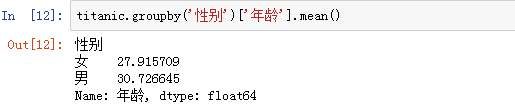
groupby操作是实现过程:
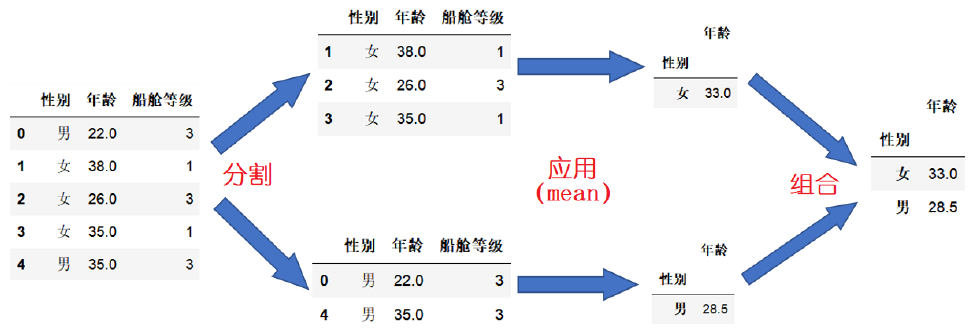

注:DataFrame和Series的方法都可以由GroupBy方法调用
-
2、探究groupby对象
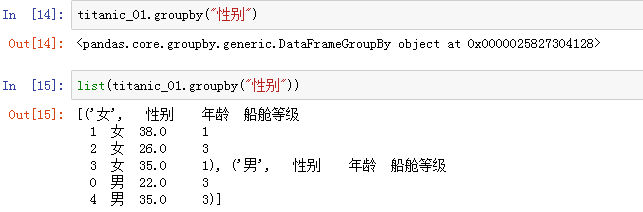
groupby对象其实是可以直接按组进行迭代的,每一组都是 Series 或 DataFrame:
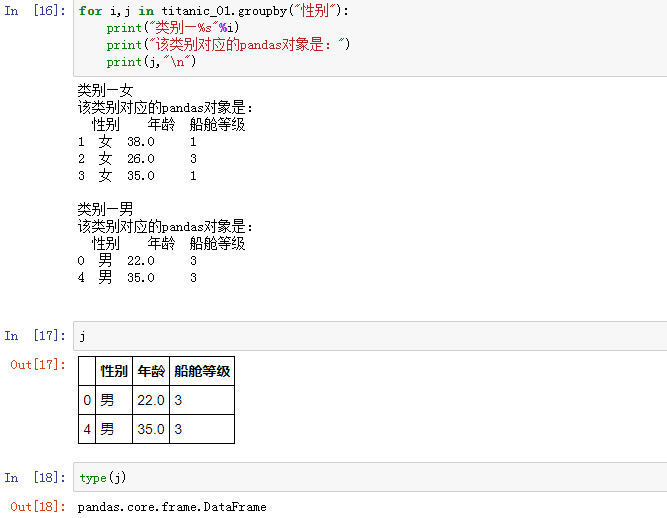
-
3、依据多个键分组
如果想依据多个键进行分割,groupby() 中设定多个字段名的列表即可:

-
三、多级索引对象
-
1、多级索引的 Series
依据多个键进行分组,返回了有多级索引的 Series 对象:
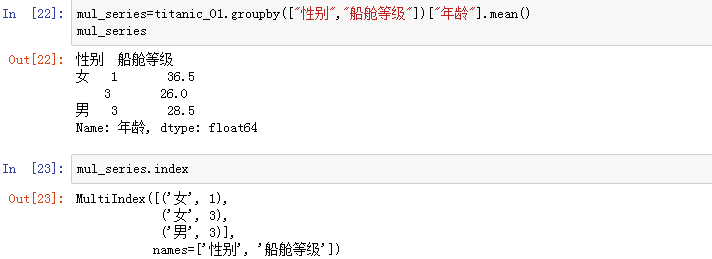
这种对象的取值方法:
-
(1)通过 Series 自带的索引值
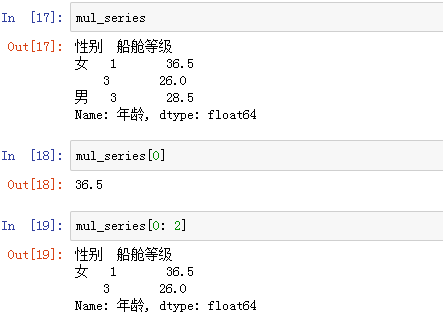
-
(2)通过一级索引标签

-
(3)通过二级或以上索引标签

-
2、多级索引的 DataFrame
按照多个字段进行分组,从上面会发现,以 Series 对象呈现出来的结果,索引有点“不整齐”,把上面的 Series 转化成 DataFrame:

索引分为两级,一级是“性别”,第二级是“船舱等级”,把上面的 DataFrame 中的两级索引单独提取出来:

-
(1)通过一级索引


-
(2)通过二级或以上索引:
-
<1> 使用 IndexSlice对象(索引切片器) —> idx = pd.IndexSlice
创建索引切片器:

使用索引切片器进行多级索引筛选:


- <2> 使用元组
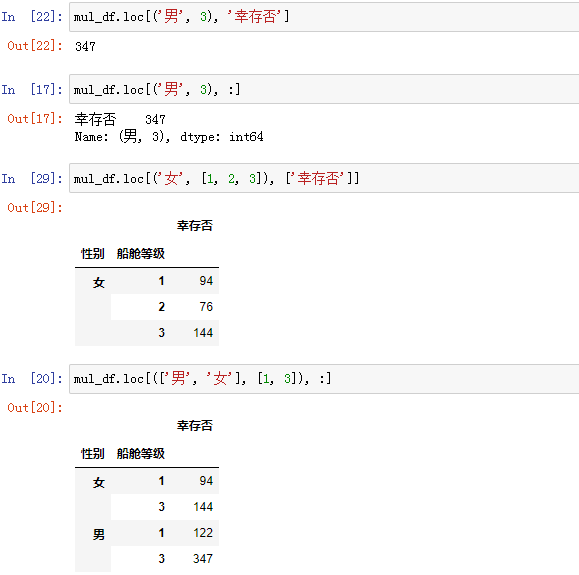
-
四、索引的重置与设置
-
1、.reset_index() 方法:重置索引

把上面的多级索引全部转化为一列列单独的字段,然后用序列数字重新变成新表的索引:
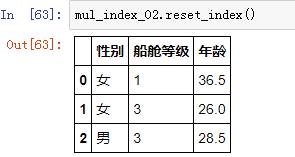
如果想保留索引“船舱等级”,只是把索引“性别”变成单独的一列字段,可以在 .reset_index() 方法中用参数 level 指定要转化成字段的索引名:

-
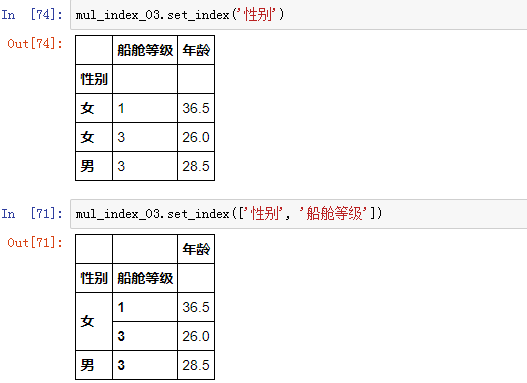
2、.set_index() 方法:设置索引
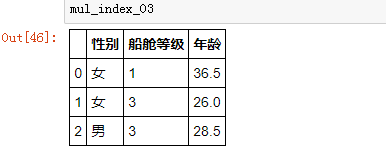
把上面的性别和船舱等级两列字段,指定作为索引:
-
五、索引的 .stack() 与 .unstack()
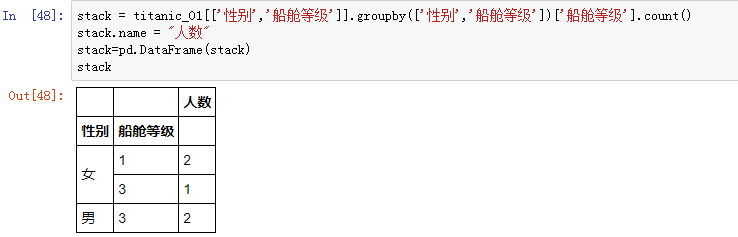
如果有上面这样的两级索引的 DataFrame 对象(或 Series 对象),如果想要把行索引“性别”,挪到列索引中,可以用 .unstack() 方法,同样也是使用参数 level 指定索引“性别”:
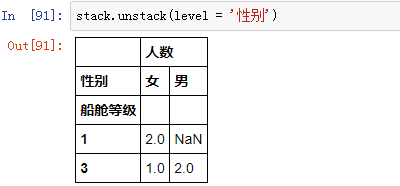
这样,可以直观地看出一等舱中没有男性
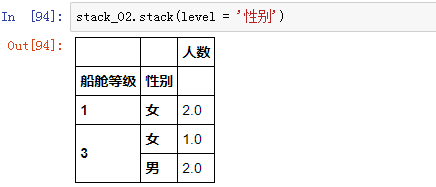
要是把上面的表“复原”,同理使用 .stack() 方法就可以:
-
六、分组后统计、过滤、转换、应用
-
1、分组后统计:aggregate() 针对多个字段多个规则的统计
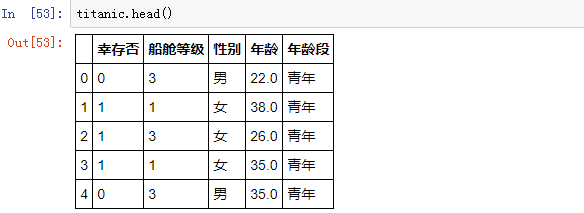
如果想看不同性别乘客的:船舱等级的众数、年龄的均值,此时可以使用 groupby 对象的 aggregate() 方法,填入带映射关系的字典即可:
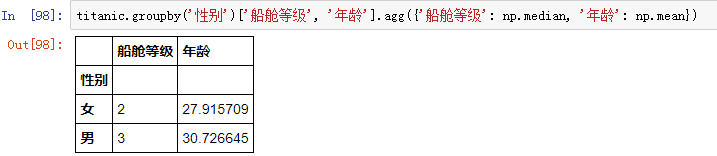
还可以对同一个字段应用多个统计方法:
-
2、分组后过滤:filter()
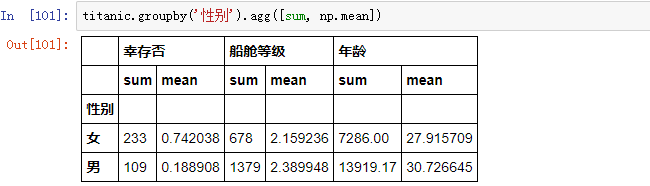
如果分组之后,想要对小组数据聚合情况进行组筛选(将属于某类组的数据都删除),这时,分组之后可以用 filter() 方法:
使用 filter() 方法,将年龄标准差小于2的年龄组删除,只保留标准差大于等于2的年龄组:

3、分组后转换:transform()
groupby 对象的 transform() 方法在数据转换之后的形状和原来的形状是一样的,但是并不是单纯地将一列数据转换,而对是分组之后不同小组的数据内部按照相同的逻辑和组内指标来转换,常见的例子是实现数据组内的标准化:
如果我们想以年龄分组,对每个人的年龄进行组内标准化(每个人的年龄减去自己年龄组的年龄均值):

-
4、分组后应用:apply()
如果你想在分组后对小组使用任意方法,可以使用apply():
- 输入一个分组数据的 DataFrame 进 apply(),可以返回一个 DataFrame 或 一个Series 或一个标量
- groupby() 和 apply() 的组合操作可以适应 apply() 返回的结果类型,因此非常灵活

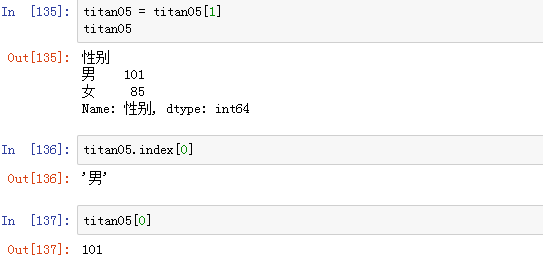
以“船舱等级”分组,如果这个船舱等级的男性多,则将该船舱等级改为“男性多的船舱等级,人数为xx”,反之亦然:

注:其中以船舱等级为1的分组在上述函数中的解析:
-
七、数据透视表
-
pd.pivot_table() 或 df.pivot_table()
语法:pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
- values:要聚合的列,可选
- index:在数据透视表索引上分组的键
- columns:在数据透视表列上分组的键
- aggfunc:function,function of list,dict,default numpy.mean
- 如果传递的函数列表,则生成的数据透视表将具有分层列
- 如果传递了dict,则键是要聚合的列,值是函数或函数列表
- fill_value:标量,默认无,用于替换缺失值的值。
- margin:boolean,默认为False,添加所有行/列(例如,对于小计/总计)
- dropna:布尔值,默认为True,不包括条目全部为NaN的列
- margins_name:string,默认为'All',当边距为真时,将包含总计的行/列的名称

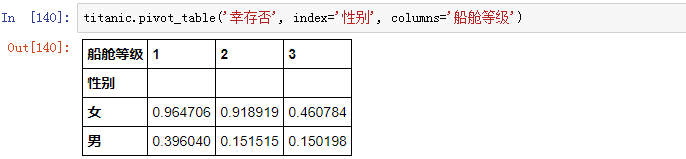
如果想要查看乘客的生存率状况,从性别和船舱等级两个维度观察(默认多维分析的对象是均值):
-
参数 aggfunc
如果多维分析"幸存否"的不是均值,而是总人数,这时候就需要用 aggfunc 参数指定聚合函数:

对同一个字段进行多种聚合函数操作:

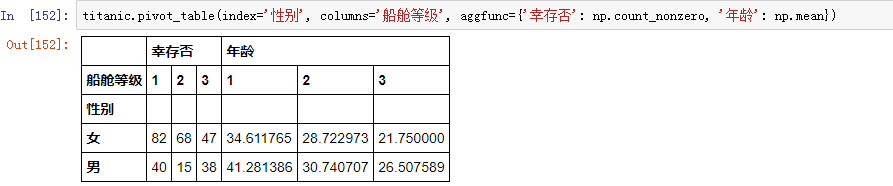
如果对不同字段进行多种聚合函数操作,例如既想求幸存者的总人数,也想求平均年龄:
-
参数margins
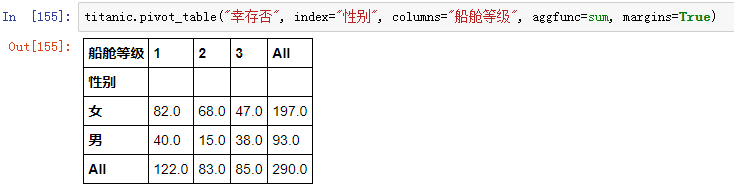
-
多级透视表



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!