Pandas之数据清洗
-
一、查看数据基本信息
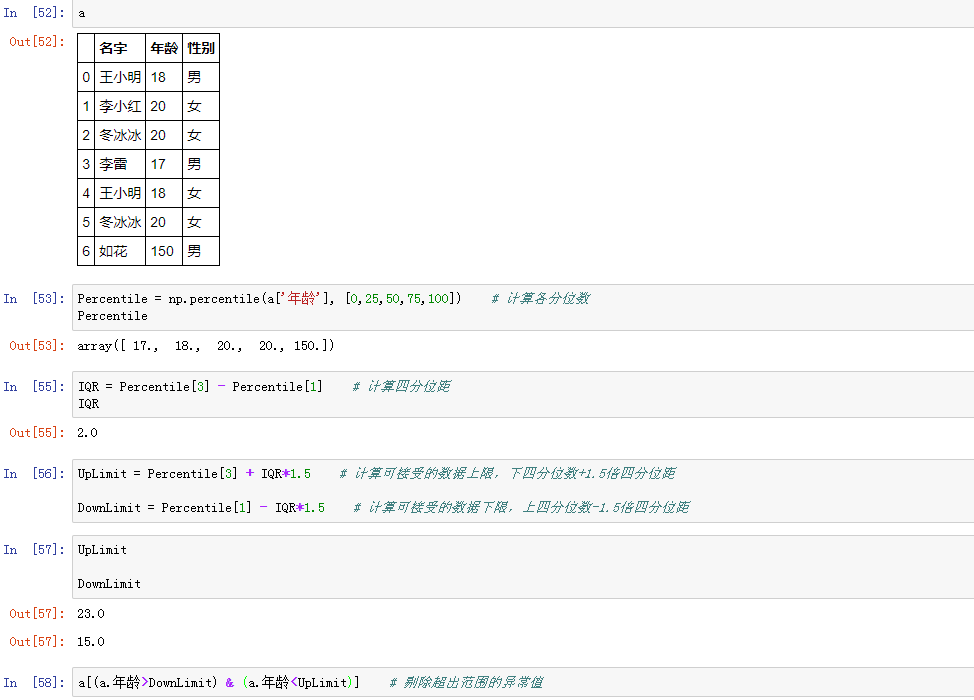
一般拿到数据,我们第一步需要做的是了解数据的整体情况,例如以下数据:
-
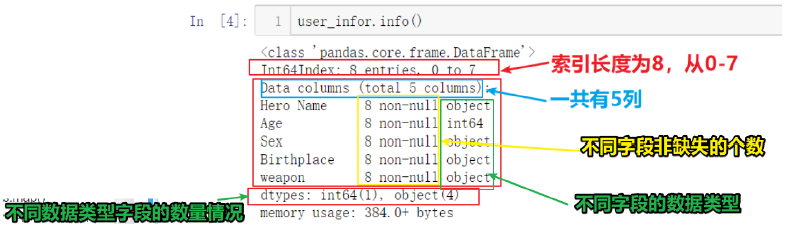
1、df.info()
-
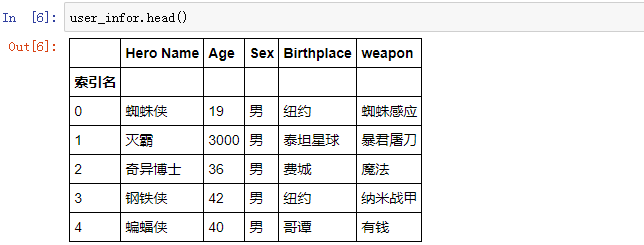
2、df.head() 和 df.tail()
查看头部的 n 条数据可以使用 head 方法,查看尾部的 n 条数据可以使用 tail 方法
-
3、df.shape
通过 .shape 获取数据的形状

-
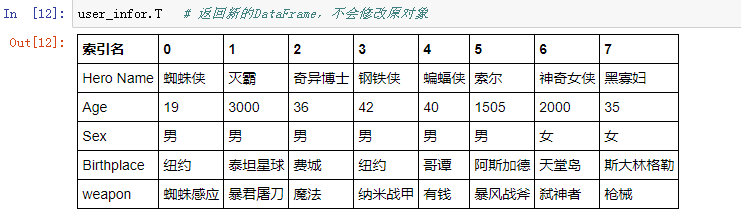
4、df.T 或 df.transpose()
通过 .T 获取数据的转置
-
5、df.values
通过 DataFrame 来获取它包含的原有数据,可以通过 .values 来获取,获取后的数据类型是一个 ndarray

-
二、描述与统计
-
1、常用描述性统计指标
获取到数据之后,想要查看下数据的简单统计指标(最大值、最小值、平均值、中位数等),DataFrame中有两种方法可以实现:
-
方法一:直接通过DataFrame抽取出来的单列series使用series的相应统计方法或函数
-
方法二:通过使用numpy对应的方法或函数,处理目标也是DataFrame抽出来的series
DataFrame 和 Series 均支持以下方法:


通过调用 min、mean、quantile、sum 方法可以实现最小值、平均值、中位数以及求和,可以看到,对一个 Series 调用 这几个方法之后,返回的都只是一个聚合结果
-
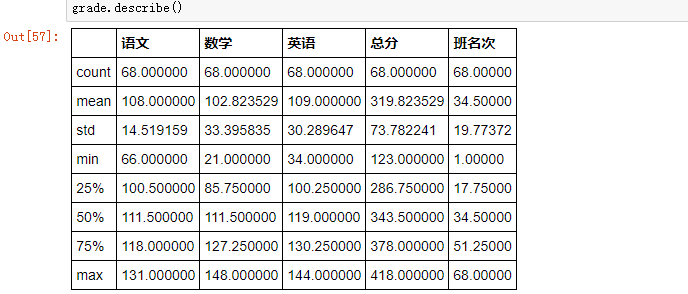
2、df.describe()
调用 .describe() 方法后,会显示出数字类型的列的一些统计指标,如 总数、平均数、标准差、最小值、最大值、25%/50%/75% 分位数:
如果想要查看非数字类型的列的统计指标,可以设置 include = ["object"] 来获得:

也可以数字和非数字类型的数据都展示:


-
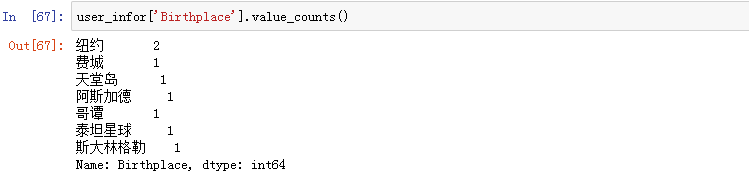
3、Series.value_counts()
统计某个字段不同数值出现的频次,可以使用 .value_counts() 方法
快速查看各列数据的分布,可以使用循环:
for i in user_infor.columns: print(user_infor[i].value_counts(),"\n")
-
三、数据离散化
-
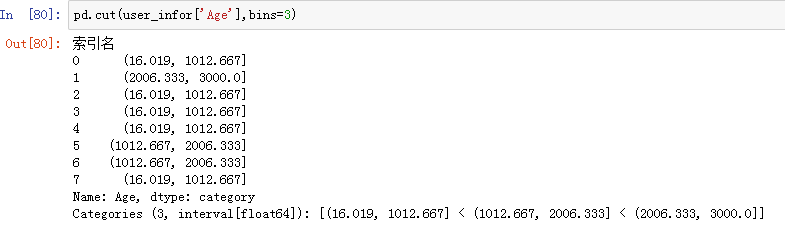
1、pd.cut()
想要将数据进行离散化(分箱),就是将数据分成几个区间,例如想要将年龄分成 3 个区间段,就可以使用 pd.cut() 方法来完成,返回的也是 Series
cut 默认自动生成等距的离散区间:
自定义区间:

离散化之后,想要给每个区间起个名字,可以在 pd.cut() 中使用参数 labels 来指定:
-
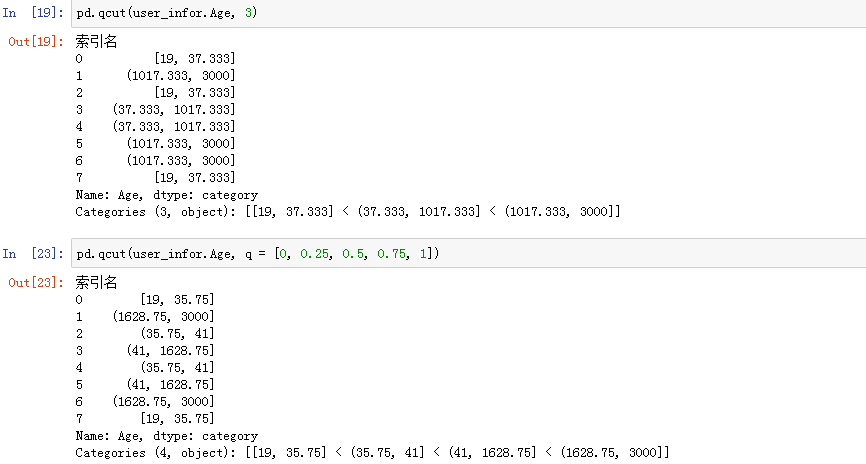
2、pd.qcut()
cut 是根据每个值的大小来进行离散化,qcut 是根据每个值出现的次数来进行离散化,也就是基于分位数的离散化功能
-
3、np.percentile():计算分位数

-
四、排序功能
Pandas 支持两种排序方式:按轴(索引或列)排序 和 按实际值排序
-
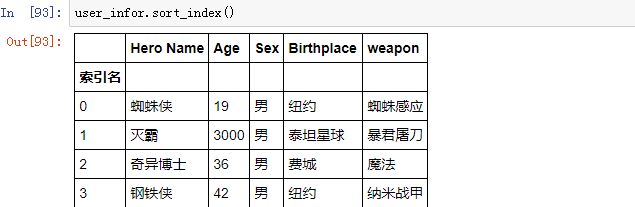
1、df.sort_index()
sort_index() 方法默认是按照索引进行升序排的
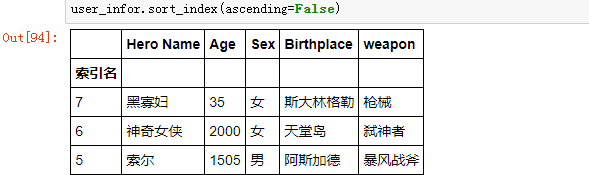
如果想要进行降序排,可以设置 ascending=False ,对列名进行排序,可以设置 axis=1
-
2、df.sort_values()
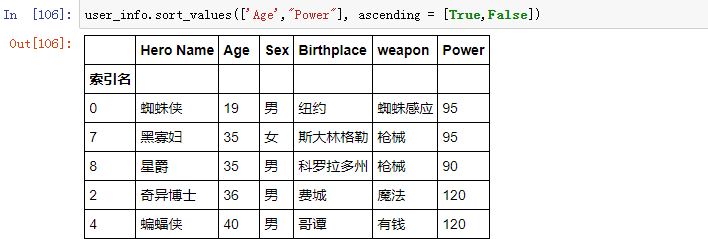
实现按照实际值来排序,需要使用 sort_values() 方法
有时候可能需要按照多个值来排序,例如:按照年龄和城市来一起排序,可以设置参数 by 为一个 list 即可
注意:list 中每个元素的顺序会影响排序优先级
-
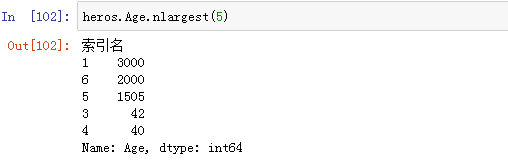
3、series.nlargest()
一般在排序后,可能需要获取最大的n个值或最小值的n个值,使用 nlargest() 和 nsmallest() 方法来完成,比先排序再使用 head() 方法快得多
-
五、函数应用及映射方法
虽说 Pandas 为我们提供了非常丰富的函数,有时候可能需要自己使用高级函数来实现自定义功能,并将它应用到 DataFrame 或 Series中,常用到的函数有:
-
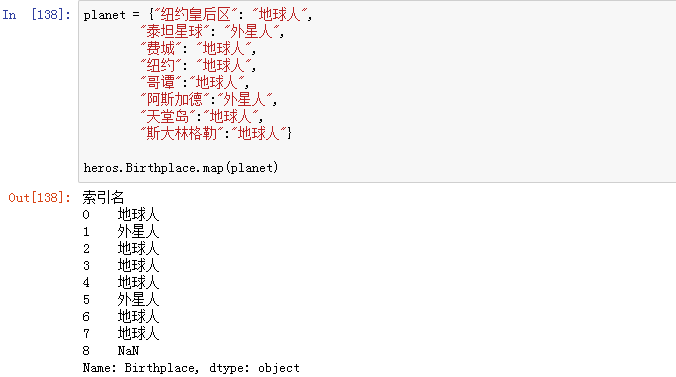
1、Series.map()
map 是 Series 中特有的方法,通过它可以对 Series 中的每个元素实现转换
-
(1)通过字典进行映射转换
-
(2)通过自定义函数来进行映射转换

-
2、Series.apply() 和 df.apply()
apply 方法既支持 Series,也支持 DataFrame,在对 Series 操作时会作用到每个值上,在对 DataFrame 操作时会作用到所有行或所有列(通过 axis 参数控制)
-
(1)对 Series 来说,如果使用自定义函数映射的方法,apply 方法 与 map 方法区别不大,但是 apply 不能支持对字典的映射转换

-
(2)对 DataFrame 来说,apply 方法的作用对象是每一行或每一列数据(整个 Series)
-
axis为 0或 columns:将函数应用于每列
-
axis为 1或 index:将函数应用于每行

-
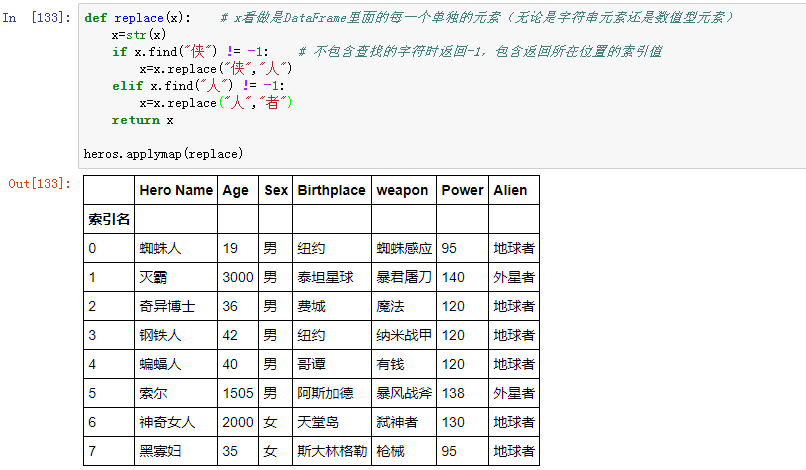
3、df.applymap()
applymap 方法针对于 DataFrame,它作用于 DataFrame 中的每个元素,它对 DataFrame 的效果类似于 apply 对 Series 的效果
总结:pandas 中 map()、apply()、applymap() 的区别
-
map() 方法适用于 Series 对象,可以通过字典或函数类对象来构建映射关系对 Series 对象进行转换
-
apply() 方法适用于 Series 对象、DataFrame对象、Groupby对象,处理的是行或列数据(本质上处理的是单个 Series ),用函数类对象来构建映射关系对 Series 对象进行转换
-
applymap() 方法用来处理 DataFrame 对象里的单个元素值,也是使用函数类对象映射转换
-
六、缺失值的处理
-
1、什么是缺失值
在了解缺失值如何处理之前,首先要知道的就是什么是缺失值?直观上理解,缺失值表示的是"缺失的数据"
造成的缺失值有很多原因,实际生活中可能由于有的数据不全所以导致数据缺失,也有可能由于误操作导致数据缺失,又或者人为地造成数据缺失
在 DataFrame 中被当作是缺失值来处理的有:
-
Python 对象中的 None
-
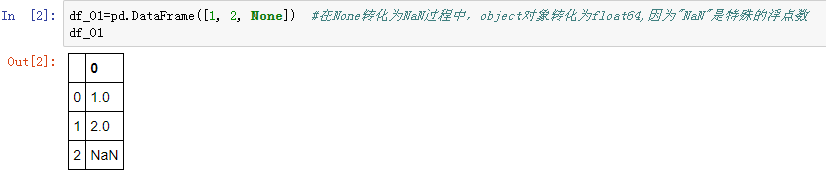
numpy 中的 np.nan,显示标签是 "NaN","NaN" 是特殊的浮点数
其实如果 DataFrame 中存在 Python 中的 None 对象,一旦转化为 dtype 类型数据(object类型除外),None 对象都会转换成 np.nan
-
2、发现缺失值
-
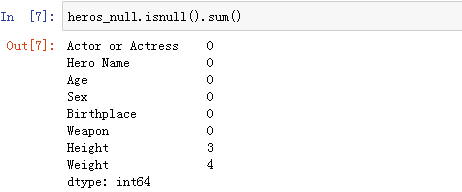
(1)df.isnull()
判断是否为空值
快速统计每个字段缺失值的数量:
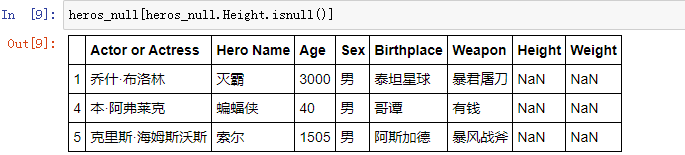
一般是对单列变量的缺失值进行观察,并利用返回的布尔型 Series 对 DataFrame 进行筛选:
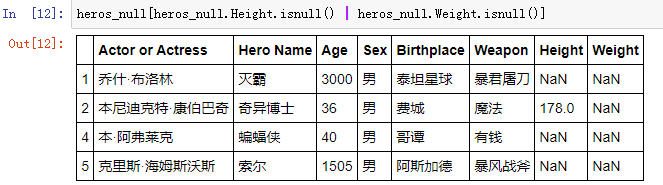
-
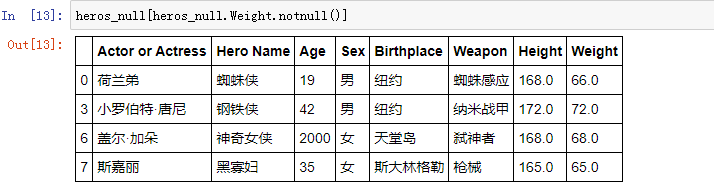
(2)df.notnull()
判断是否不为空值
-
3、df.dropna() 剔除缺失值
直接对DataFrame对象使用 .dropna() 方法会删除掉所有带有缺失值的行(返回新表,并不是改变原表):
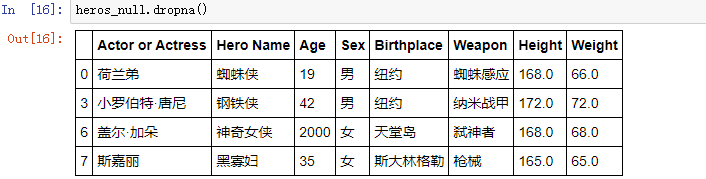
如果里面增加axis参数,指定第二坐标轴,就会默认删掉出现缺失值的列:
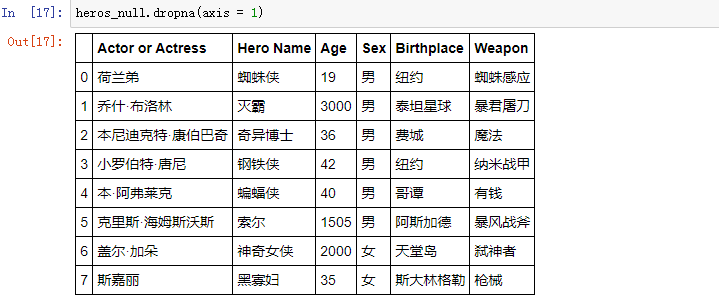
df.dropna() 中的参数 how 和 thresh 是设置删除行列标准的参数:
-
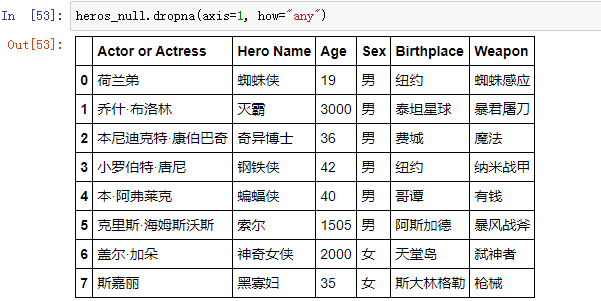
参数how
how = "all":只有当该列(或行)全都为缺失值时,才会将该列(或行)删除
how = "any":只有当该列(或行)有一个缺失值时,就会将该列(或行)删除
-
参数thresh
thresh参数设置的是:至少留下包含多少个非缺失值的列(或行)
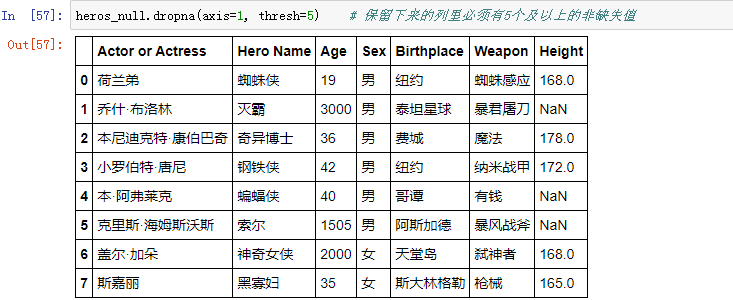
示例:

4、df.fillna() 填充缺失值
填充缺失值的思路:
-
根据业务知识填充
-
连续性变量缺失值的填充:均值、中位数
-
分类型变量缺失值的填充:众数
-
预测值填充
固定值填充:


填充均值容易受到异常值的影响,可以使用:
- 中位数:Series.median()
- 众数:Series.mode(),但并不是所有数据集都有众数,如[1,2,3,4,5]
同时对多列进行填充:
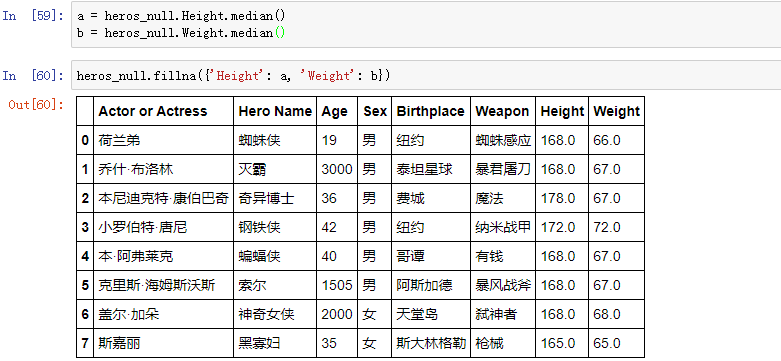
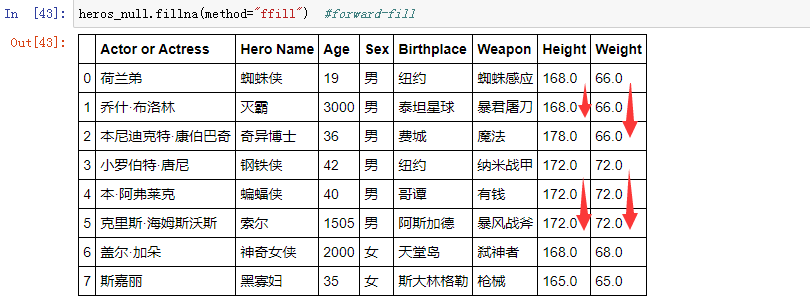
前向填充:
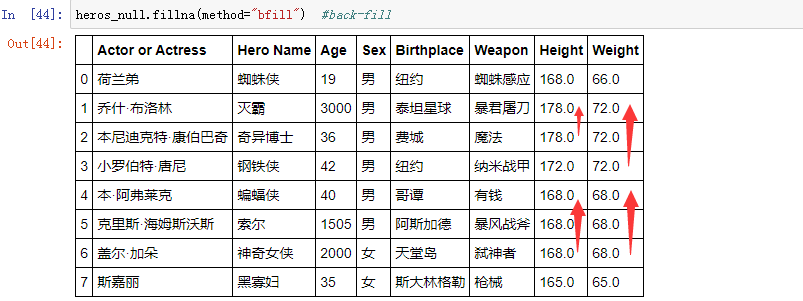
后向填充:
-
5、df.replace()
None、np.nan、NaT(时间数据类型的缺失值) 这些都是 Pandas 眼中的缺失值,可以用上面的处理缺失值的方法进行操作,但是有时候在我们人类的眼中,某些异常值也会当做缺失值来处理,例如,在我们的存储的用户信息中,假定我们限定用户都是青年,年龄字段出现了80,我们就可以认为这是一个异常值,再比如,我们都知道性别分为男性(male)和女性(female),在记录用户性别的时候,对于未知的用户性别都记为了 “unknown”,很明显,我们也可以认为 “unknown” 是缺失值,此外,有的时候会出现空白字符串,这些也可以认为是缺失值。
对于上面的这些特殊情况,我们可以使用 replace 方法来替换成缺失值,进而可以使用 Pandas 的处理缺失值的方法进一步处理数据:
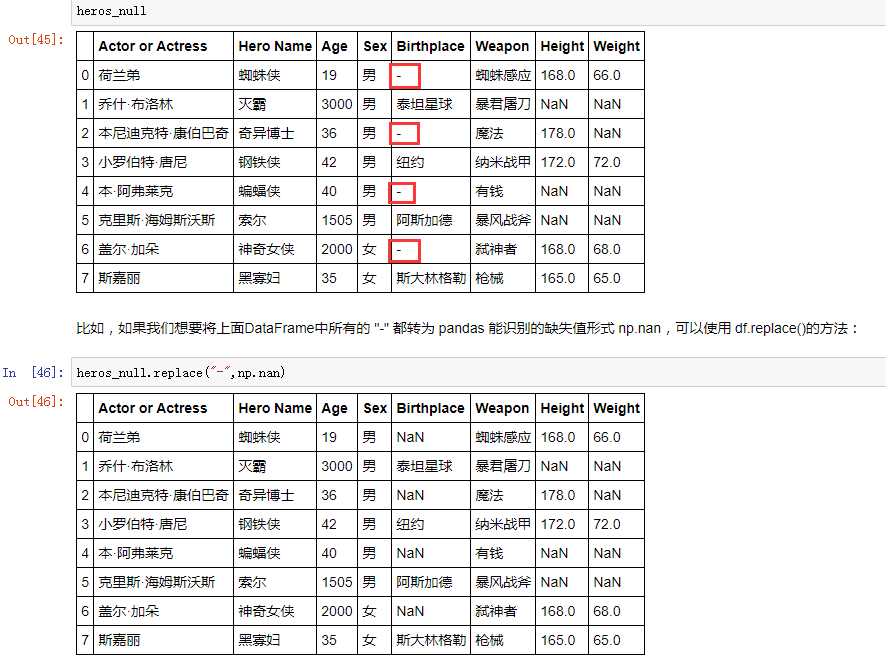

可以传入一个字典,进行不同规则的同时替换:

七、重复值的处理
df.drop_duplicates(subset=None, keep='first', inplace=False)
-
subset:设置用哪些列来标识重复项
-
keep:
-
"first":保留第一个重复项,其余删除
-
"last":保留最后一个重复项,其余删除
-
False:删除所有重复项
-
DataFrame 实例调用 .drop_duplicates() 方法会默认直接删除所有数值都一模一样的多余数据,用参数 keep 决定究竟保存哪个重复值,可以用 subset 参数来决定以哪些字段作为判断依据
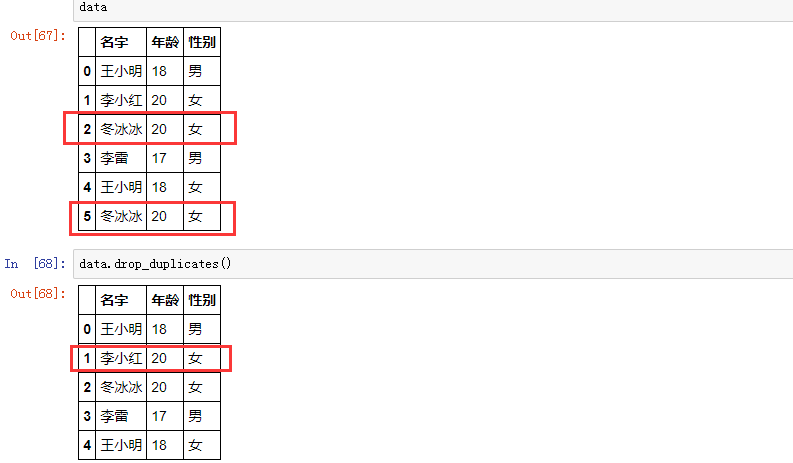

-
八、异常值的处理
检测到了异常值,我们需要对其进行一定的处理,而一般异常值的处理方法可大致分为以下几种:
-
删除含有异常值的记录:直接将含有异常值的记录删除
-
视为缺失值:将异常值视为缺失值,利用缺失值处理的方法进行处理
-
平均值修正:可用前后两个观测值的平均值修正该异常值
-
不处理:如果异常值具有实际价值,直接在具有异常值的数据集上进行数据挖掘